👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——循环神经网络RNN
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
RNN的从零开始实现与简洁实现
- RNN的从零开始实现
- 读取数据集
- 独热编码
- 初始化模型参数
- 循环神经网络模型
- 返回初始化隐状态
- 计算隐状态和输出
- 包装
- 检查
- 预测
- 梯度裁剪
- 训练
- 小结
- RNN的简洁实现
- 读取数据集
- 定义模型
- 训练与预测
- 小结
RNN的从零开始实现
读取数据集
我们将在之前所说的《时光机器》数据集上训练,先读取数据集:
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
独热编码
回想一下,在train_iter中,每个词元都表示为一个数字索引,将这些索引直接输入神经网络可能会使学习变得困难。我们通常将每个词元表示为更具表现力的特征向量。而之前讲过的独热编码就可以使用。
简言之,将每个索引映射为相互不同的单位向量: 假设词表中不同词元的数目为N(也就是len(vocab)),词元索引范围为0~N-1。若词元的索引是整数i, 那么我们将创建一个长度为N的全0向量,再将第i处的元素位置置1。
例如索引为0和2的独热向量分别为:
print(F.one_hot(torch.tensor([0, 2]), len(vocab)))
运行结果:
tensor([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]])
我们每次采样的小批量数据形状是二维张量:(批量大小,时间步数)。而我们的one_hot函数会将这样的小批量数据转换为三维向量(最后一个维度为词表大小N)。我们也经常转换输入的维度,以便获得形状为 (时间步数,批量大小,词表大小)的输出。 这将使我们能够更方便地通过最外层的维度, 一步一步地更新小批量数据的隐状态。例如:
X = torch.arange(10).reshape((2, 5))
print(F.one_hot(X.T, 28).shape)
输出结果:
torch.Size([5, 2, 28])
初始化模型参数
需要注意,隐藏单元数num_hiddens是一个可调的超参数。
当训练语言模型时,输入和输出来自相同的词表。 因此,它们具有相同的维度,即词表的大小。
def get_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_sizedef normal(shape):return torch.randn(size=shape, device=device) * 0.01# 隐藏层参数W_xh = normal((num_inputs, num_hiddens))W_hh = normal((num_hiddens, num_hiddens))b_h = torch.zeros(num_hiddens, device=device)# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xh, W_hh, b_h, W_hq, b_q]for param in params:param.requires_grad_(True)return params
循环神经网络模型
返回初始化隐状态
init_rnn_state在初始化时返回隐状态。这个函数的返回是一个张量,张量全用0填充, 形状为(批量大小,隐藏单元数)。
def init_rnn_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device), )
计算隐状态和输出
rnn函数定义了如何在一个时间步内计算隐状态和输出。循环神经网络模型通过inputs最外层的维度实现循环,以便逐时间步更新小批量数据的隐状态H。这里使用tanh函数作为激活函数:
def rnn(inputs, state, params):# inputs的形状:(时间步数量,批量大小,词表大小)W_xh, W_hh, b_h, W_hq, b_q = paramsH, = stateoutputs = []# X的形状:(批量大小,词表大小)for X in inputs:H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H,)
包装
定义了所有需要的函数之后,接下来我们创建一个类来包装这些函数, 并存储从零开始实现的循环神经网络模型的参数。
class RNNModelScratch: #@save"""从零开始实现的循环神经网络模型"""def __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device)self.init_state, self.forward_fn = init_state, forward_fndef __call__(self, X, state):X = F.one_hot(X.T, self.vocab_size).type(torch.float32)return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device):return self.init_state(batch_size, self.num_hiddens, device)
检查
检查输出是否具有正确的形状(隐状态的维数是否保持不变):
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
print(Y.shape, len(new_state), new_state[0].shape)
运行结果:
torch.Size([10, 28]) 1 torch.Size([2, 512])
输出形状是(时间步数×批量大小,词表大小),隐状态形状保持不变,即(批量大小,隐藏单元数)。
预测
首先定义一个预测函数来生成prefix之后的新字符(prefix是一个用户提供的包含多个字符的字符串)。
在循环遍历prefix中的开始字符时, 我们不断地将隐状态传递到下一个时间步,但是不生成任何输出,这叫作预热期,因为这个期间的模型会自我更新(隐状态),但是不会进行预测。等到预热期结束后,开始预测字符并输出。
def predict_ch8(prefix, num_preds, net, vocab, device): #@save"""在prefix后面生成新字符"""state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])
我们指定前缀prefix为time traveller,基于这个前缀生成后序10个连续字符,代码如下:
print(predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu()))
因为还没有训练网络,所以会生成奇怪的结果
time traveller srbmtd srb
梯度裁剪
一个长度为T的序列,我们在迭代计算这T个时间步上的梯度,将会在反向传播过程中产生长度为O(T)的矩阵乘法链。T太大就会数值不稳定,可能会造成梯度爆炸或梯度消失。
我们的解决方案是将梯度投影回给定半径(例如θ)的球来裁剪梯度g:
g ← m i n ( 1 , θ ∣ ∣ g ∣ ∣ ) g g←min(1,\frac{θ}{||g||})g g←min(1,∣∣g∣∣θ)g
这样做,梯度范数永远不会超过θ,并且更新后的梯度完全和g原始方向对其。
梯度裁剪提供了一个快速修复梯度爆炸的方法,虽然它并不能完全解决问题(无法应对梯度消失),但它是众多有效的技术之一。
下面定义一个函数来裁剪模型(可能是从零开始实现的模型,可能是API构建的模型)的梯度:
def grad_clipping(net, theta): #@save"""裁剪梯度"""if isinstance(net, nn.Module): # 高级API构建的模型params = [p for p in net.parameters() if p.requires_grad]else: # 从零开始实现的模型params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))if norm > theta:for param in params:param.grad[:] *= theta / norm
训练
在训练之前,我们依旧是定义一个函数在一个迭代周期内训练模型,这与之前的有以下不同:
1、序列数据的不同采样方法(随机采样和顺序分区)将导致隐状态初始化的差异。
2、我们在更新模型参数之前裁剪梯度。 这样的操作的目的是,即使训练过程中某个点上发生了梯度爆炸,也能保证模型不会发散。
3、我们使用困惑度来评价模型(确保了不同长度的序列具有可比性)。
当使用顺序分区时,我们只在每个迭代周期的开始位置初始化隐状态。由于下一个小批量数据中的第i个子序列样本与当前第i个子序列样本相邻,因此当前小批量数据最后一个样本的隐状态,将用于初始化下一个小批量数据第一个样本的隐状态。 这样,存储在隐状态中的序列的历史信息可以在一个迭代周期内流经相邻的子序列。
但是在任何一点隐状态的计算,都会依赖前一个迭代周期中前面所有的小批量数据,梯度计算就会很复杂。要降低计算量,我们需要在处理任何一个小批量数据前分离梯度,使得隐状态的梯度计算总是限制在一个小批量数据的时间步内。
当使用随机抽样时,因为每个样本都是在一个随机位置抽样的,因此需要为每个迭代周期重新初始化隐状态。
剩下的部分都和之前的思想相同:
#@save
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):"""训练网络一个迭代周期"""state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)else:if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * y.numel(), y.numel())return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
接下来我们定义RNN模型的训练函数:
#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):"""训练模型"""loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 初始化if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)# 训练和预测for epoch in range(num_epochs):ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:print(predict('time traveller'))animator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict('time traveller'))print(predict('traveller'))
现在,我们训练循环神经网络模型。因为我们在数据集中只使用了10000个词元,所以模型需要更多的迭代周期来更好地收敛。
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
d2l.plt.show()
运行结果:
困惑度 1.1, 20920.1 词元/秒 cpu
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filby
运行图片:
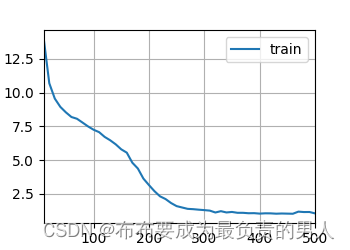
上面的内容从零开始实现,可以更好的看看底层,但是不太方便。下面会给出如何改进RNN模型和简单实现,且运行的速度会更快。
小结
1、我们可以训练一个基于循环神经网络的字符级语言模型,根据用户提供的文本的前缀生成后续文本。
2、一个简单的循环神经网络语言模型包括输入编码、循环神经网络模型和输出生成。
3、循环神经网络模型在训练以前需要初始化状态,不过随机抽样和顺序划分使用初始化方法不同。
4、当使用顺序划分时,我们需要分离梯度以减少计算量。
5、在进行任何预测之前,模型通过预热期进行自我更新(例如,获得比初始值更好的隐状态)。
6、梯度裁剪可以防止梯度爆炸,但不能应对梯度消失。
RNN的简洁实现
简洁实现的思想大致还是和之前一样的,但是有些细节上还是不太一样,主要还是要学会用这个就好了。
读取数据集
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
定义模型
高级API提供了RNN的实现。我们构造一个具有256个隐藏单元的单隐藏层的循环神经网络层rnn_layer。
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
我们使用张量来初始化隐状态,它的形状是(隐藏层数,批量大小,隐藏单元数)。
state = torch.zeros((1, batch_size, num_hiddens))
可以输出查看一下:
print(state.shape)
运行结果:
torch.Size([1, 32, 256])
通过一个隐状态和一个输入,我们就可以用更新后的隐状态计算输出(其中rnn_layer的输出Y并不涉及输出层的计算,它是指每个时间步的隐状态,这些隐状态可以用作后序输出层的输入):
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
我们可以输出一下Y和state_new的形状:
print(Y.shape, state_new.shape)
运行结果:
torch.Size([35, 32, 256]) torch.Size([1, 32, 256])
和之前一样,我们为一个完整的循环神经网络模型定义了一个RNNModel类(与之前不同的是,rnn_layer只包含了隐藏循环层,所以我们要单独创建一个单独的输出层Linear):
#@save
class RNNModel(nn.Module):"""循环神经网络模型"""def __init__(self, rnn_layer, vocab_size, **kwargs):super(RNNModel, self).__init__(**kwargs)self.rnn = rnn_layerself.vocab_size = vocab_sizeself.num_hiddens = self.rnn.hidden_size# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1if not self.rnn.bidirectional:self.num_directions = 1self.linear = nn.Linear(self.num_hiddens, self.vocab_size)else:self.num_directions = 2self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)def forward(self, inputs, state):X = F.one_hot(inputs.T.long(), self.vocab_size)X = X.to(torch.float32)Y, state = self.rnn(X, state)# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)# 它的输出形状是(时间步数*批量大小,词表大小)。output = self.linear(Y.reshape((-1, Y.shape[-1])))return output, statedef begin_state(self, device, batch_size=1):if not isinstance(self.rnn, nn.LSTM):# nn.GRU以张量作为隐状态return torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens),device=device)else:# nn.LSTM以元组作为隐状态return (torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device),torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device))
训练与预测
接下来我们使用之前定义的超参数调用train_ch8,并使用高级API训练模型:
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
d2l.plt.show()
运行结果:
perplexity 1.3, 58549.5 tokens/sec on cpu
time travellery a curfonty is and why cabnglwed of his fecupry h
travelleryou can show black is white by ard whing to verint
运行图片:
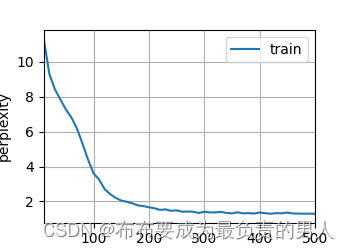
可以看出,使用高级API后,该模型在较短时间内达到较低的困惑度。
小结
1、深度学习框架的高级API提供了循环神经网络层的实现。
2、高级API的循环神经网络层返回一个输出和一个更新后的隐状态,我们还需要计算整个模型的输出层。
3、相比从零开始实现的循环神经网络,使用高级API实现可以加速训练。
![Javascript 数据结构[入门]](https://img-blog.csdnimg.cn/083e22ef77cd4326a05791a0b41e9c51.png)