所有的 Kubernetes 组件,都提供了 /metrics 接口用来暴露监控数据,Kube-Proxy 也不例外。通过 ss 或者 netstat 命令可以看到 Kube-Proxy 监听的端口,一个是 10249,用来暴露监控指标,一个是 10256 ,作为健康检查的端口,一般我们只关注前一个端口。
1、Kube-Proxy 关键指标
1、通用的 Go 程序相关的指标
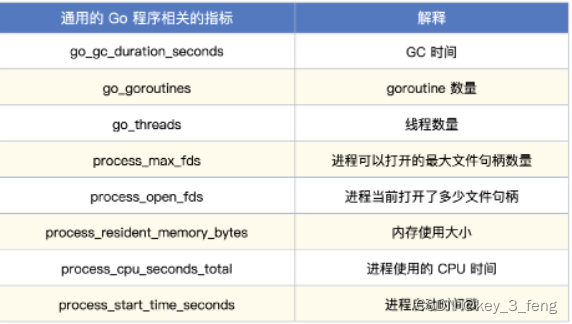
以上指标,只要是通过 Prometheus Go SDK 埋点的程序都会有,包括Kube-Proxy, Kubelet、APIServer、Scheduler 等。
2、请求 APIServer 的指标
Kubernetes 中多个组件都要调用 APIServer 的接口,每秒调用多少次、有多少成功多少失败、耗时情况如何,这些指标也比较关键。比如:
- rest_client_request_duration_seconds:请求 APIServer 的耗时统计
- rest_client_requests_total:请求 APIServer 的调用量统计
3、规则同步类指标
Kube-Proxy 的核心职能,就是去 APIServer 获取转发规则,修改本地的 iptables 或者 ipvs 的规则,所以这些规则同步相关的指标,就至关重要了。

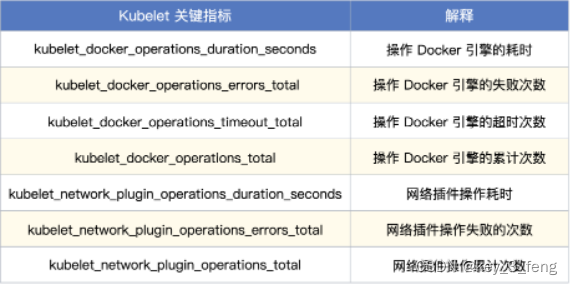
2、Kubelet 关键指标
Kubelet 也会吐出 Go 进程相关的通用指标以及和 APIServer 通信相关的度量指标,和 Kube-Proxy 类似。Kubelet 核心职能是管理 Pod,操作各种 CNI、CSI 相关的接口,和容器引擎打交道,度量这类操作的指标就显得尤为关键。
3、容器负载指标
CPU 指标
sum(
irate(container_cpu_usage_seconds_total[3m])
) by (pod,id,namespace,container,ident,image)
/
sum(
container_spec_cpu_quota/container_spec_cpu_period
) by (pod,id,namespace,container,ident,image)这是计算 CPU 使用率,整体是一个除法运算,分子部分是容器每秒耗费的 CPU 时间,分母部分是每秒分配给容器的 CPU 时间。
increase(container_cpu_cfs_throttled_periods_total[1m])
/
increase(container_cpu_cfs_periods_total[1m]) * 100这是在计算 CPU 被限制的时间比例,如果这个值很高,说明容器在使用 CPU 资源的时候经常被限制,需要提高这个容器的 CPU Quota。延迟敏感型的应用,需要特别关注这个指标。
内存指标
container_memory_working_set_bytes
/
container_spec_memory_limit_bytes
and
container_spec_memory_limit_bytes != 0计算内存使用率的时候,核心也是一个除法运算,分子是容器的内存占用,分母是内存 Limit 大小。当然,有些容器没有指定内存 Limit,所以还需要有个 and 语句来做限制,只有 limit_bytes 不等于 0,这个除法运算才有意义。
Pod 网络流量
irate(container_network_transmit_bytes_total[1m]) * 8
irate(container_network_receive_bytes_total[1m]) * 8这个指标名字非常清晰,transmit 是出向,receive 是入向,这两个指标都是 Counter 类型的值,单调递增,所以使用 irate 计算每秒速率。因为网络流量一般都是用 bit 作为单位,所以最后乘以 8,把 byte 换算成 bit。
Pod 硬盘 IO 读写流量
irate(container_fs_reads_bytes_total[1m])
irate(container_fs_writes_bytes_total[1m])这个指标名字一看就知道是 Counter 类型,我们不关心当前值是多少,而是关心最近一段时间每秒的速率是多少,所以使用 irate 做了二次计算。
此文章为8月Day10学习笔记,内容来源于极客时间《运维监控系统实战笔记》,推荐该课程。



![[C++ 网络协议编程] UDP协议](https://img-blog.csdnimg.cn/4499b0d74c334829aaea2cd55e5b9670.png)