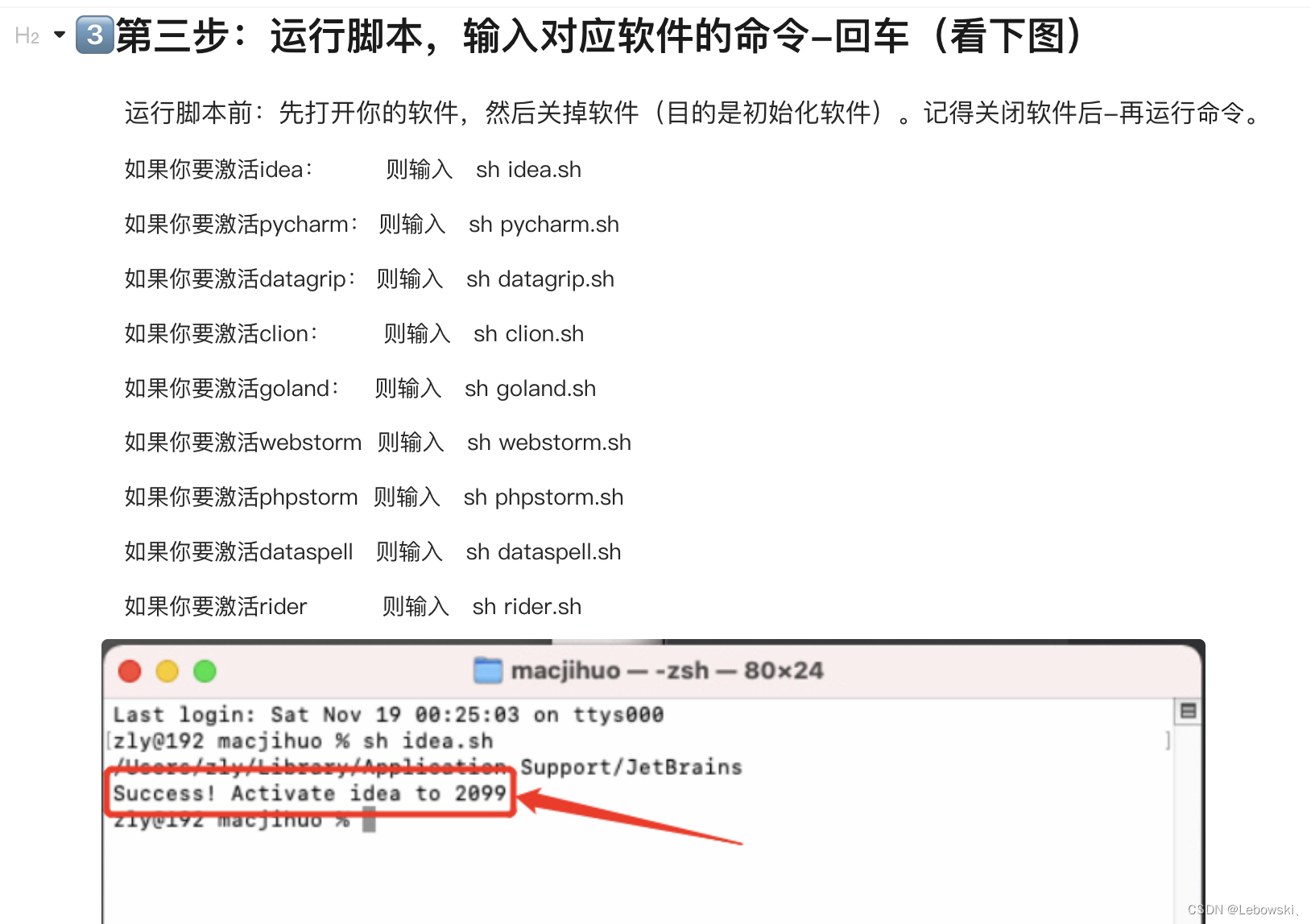
检查点触发时机
- 检查点间隔时间由checkpoint_timeout设置
- pg_xlog中wall段文件总大小超过参数max_WAL_size的值
- postgresql服务器在smart或fast模式下关闭
- 手动checkpoint
为什么需要检查点?
- 定期保持修改过的数据块
- 作为实例恢复时起始位置(问题:wal日志应该从哪开始重放?)
- 作为介质恢复时起始位置
示例
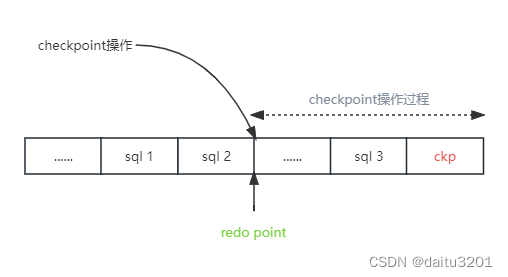
checkpoint过程描述
checkpoint操作首先记录下checkpoint的“开始”位置,记录为redo point(重做位点)
checkpoint将sharedbuffer中的数据刷到磁盘里面去
这时候数据库又来了一条SQL insert 3
checkpoint刷脏结束,redo point之前的数据均已被刷到磁盘存储(数据1和数据2)
这时候在wal日志里面记录checkpoint位点,表明checkpoint操作“结束”。checkpoint位点会记录相关信息,比如redo point的值(从哪开始重做)
将最新的checkpoint位点记录到pg_control文件
这个时候假如开始数据库恢复,那么数据库会从pg_control中文件中找到最新的checkpoint位置,再从checkpoint找到redo point的位置,开始重放日志。
不难看出,1和2这两个数据在checkpoint中已经持久化到磁盘存储,wal日志中也只有insert 3操作需要重放。
思考
为什么需要redo point?
redo point是记录本次开始刷脏数据的开始位点(即,redo point之前的数据都会被刷到磁盘存储),等到本次刷脏结束,会在wal日志中插入checkpoint位点,表明本次刷脏结束。
redo point和checkpoint位点之间逻辑上是一个时间段,在这个时间段内,由于写wal日志由walwriter进程完成,而刷脏由checkpoint进程完成,两个进程之间并行运行,在redo point和checkpoint位点之间,walwriter可能会插入新的wal日志记录(执行SQL),这样通过这两个位点就能够知道哪些数据已经刷到磁盘,哪些还没有,等到恢复的时候就能够准确定位到恢复的起点。