前言
在设计模式的系列文章中,我们前面已经写了工厂模式、单列模式、建造者模式,在针对创建型模式中,今天想跟大家分享的是原型模式,我觉的这种模式叫克隆模式会更佳恰当。原型模式的目的就是通过复制一个现有的对象来生成一个新的对象。
模式概述
原型模式
使用原型实例指定创建对象的种类,并且通过克隆这些原型创建新的对象,原型模式是一种对象的创建型模式
工作原理
将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求原型对象克隆自己来实现创建的过程,通过克隆方法所创建的对象是全新的对象,它们在内存中拥有新的地址;通常,对克隆产生的对象进行的修改不会对原型对象造成任何影响,每一个克隆的对象都是相互独立的。
原型模式的结构
原型模式模式分为两种,一种是不带管理类的原型模式,另一种是带管理类的原型模式。
下面这种是不带管理类的原型模式:
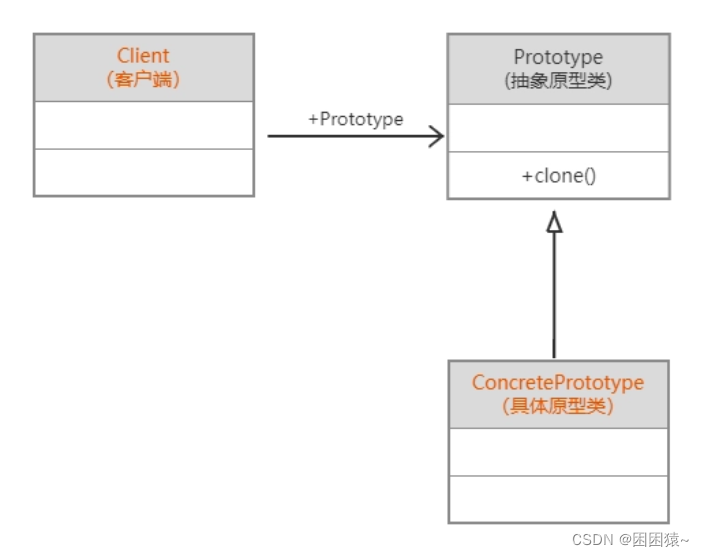
定义
原型模式包含了三个角色
- Prototype(抽象原型类):它是声明克隆方法的接口,是所有具体原型类的公共父类,可以是抽象类也可以是接口,甚至可以是具体的实现类
- ConcretePrototype(具体原型类):它实现在抽象原型类中声明的克隆方法,在克隆方法中返回一个自己的克隆对象
- Client(客户类):让一个原型对象克隆自己从而创建一个新的对象,在客户类中只需要直接实例化或通过工厂方法等方式创建一个原型对象,再通过该对象的克隆方法即可获得多个相同的对象
需要注意的点:
在 Java 中 能够克隆的 Java类 务必得 实现 Cloneable 接口,表示这个 类 能够被 “复制”,至于这个 复制的效果 则与我们的实现有关,通常 clone()方法满足以下的条件:
- 对任何的对象x,都有:x.clone()!=x 。换言之,克隆对象与元对象不是一个对象
- 对任何的对象x,都有:x.clone().getClass==x.getClass(),换言之,克隆对象与元对象的类型一样
- 对任何的对象x,如果 equals() 方法编写得当的话, 那么x.clone().equals(x)应该是成立的
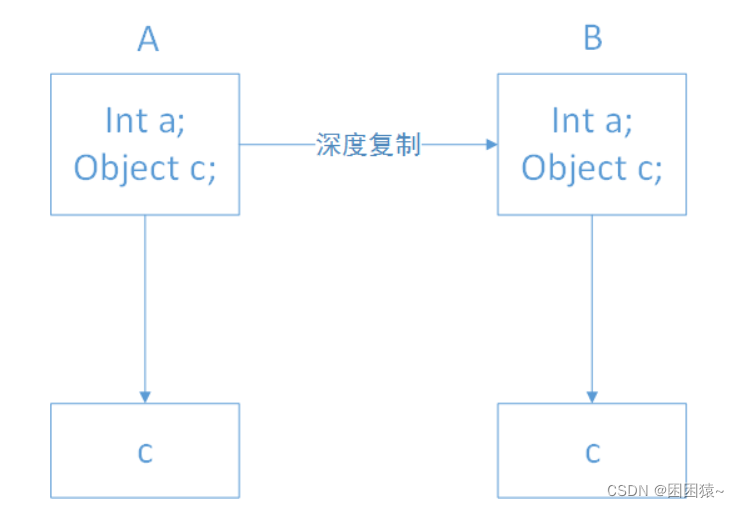
在正式开始原型模式之前,我们先了解两个概念浅克隆和深克隆,浅克隆和深克隆的主要区别在于是否支持引用类型的成员变量的复制
浅拷贝与深拷贝
A、浅拷贝
被拷贝对象的所有变量都含有与原对象相同的值,而且对其他对象的引用仍然是指向原来的对象。即浅拷贝只负责当前对象实例,对引用的对象不做拷贝。

B、深拷贝
被拷贝对象的所有的变量都含有与原来对象相同的值,除了引用其他对象的变量。引用其他对象的变量将指向一个被拷贝的新对象,而不再是原有被引用对象。即深拷贝把要拷贝的对象所引用的对象也都拷贝了一次。
深拷贝要深入到多少层,是一个不确定的问题。在决定以深拷贝的方式拷贝一个对象的时候,必须决定对间接拷贝的对象是采取浅拷贝还是深拷贝还是继续采用深拷贝。因此,在采取深拷贝时,需要决定多深才算深。此外,在深拷贝的过程中,很可能会出现循环引用的问题。
我们通过一个实例来看一下具体的使用过程。
我们举一个大学里常见的例子,一个班里有一个学霸的话整个班级的作业就不用愁了,大家可以拿学霸的作业去复制嘛。
这个类是作业的抽象父类,定义了一些作业都要实现的方法,这里只实现了一个数学作业类,将来可以能有编程作业等。
package com.designpattern.prototype1;public abstract class Homework implements Cloneable {public abstract Object clone();public abstract void show();
}
数学作业的类要实现自己的复制逻辑,因为数学作业和编程作业的抄袭的方法肯定是不一样的。
package com.designpattern.prototype1;import java.util.Date;public class MathHomework extends Homework{/*** 这里只是用一个日期类来表示一下深度复制*/private Date A = new Date();private int a = 1;public void show() {System.out.println("Math clone");}/*** 实现自己的克隆方法*/public Object clone(){MathHomework m = null;/*** 深度复制*/m = (MathHomework) this.clone();m.A = (Date)this.getA().clone();return m;}public Date getA(){return A;}}
客户端就可以使用学霸的作业抄袭了
package com.designpattern.prototype1;public class Main {public static void main(String[] args){/*** 建立一个学霸,全班同学的作业就靠他了*/MathHomework xueba = new MathHomework();/*** 学渣都是从学霸那复制来的*/MathHomework xuezha = (MathHomework)xueba.clone();xuezha.show();}
}
那如果一个班里有两个学霸呢,那肯定班里的同学有的会超A同学的,有的会抄B同学的,这样的话系统里就必须要保留两个原型类,这时候使用我们的带有管理类的原型模式就比较方便了。
此时的结构图是这样的:

新增加的管理类:
package com.designpattern.prototype1;import java.util.Map;public class Manager {private static Manager manager;private Map prototypes = null;private Manager() {manager = new Manager();}//使用了简单工厂模式public static Manager getManager() {if (manager == null)manager = new Manager();return manager;}public void put(String name,Homework prototype){manager.put(name, prototype);}public Homework getPrototype(String name){if(prototypes.containsKey(name)){return (Homework) ((Homework)prototypes.get(name)).clone();}else{Homework homework = null;try{homework = (Homework)Class.forName(name).newInstance();put(name, homework);}catch(Exception e){e.printStackTrace();}return homework;}}}
package com.designpattern.prototype1;public class MainManager {public static void main(String[] args){/*** 建立一个学霸,全班同学的作业就靠他了*/MathHomework xueba = new MathHomework();Manager.getManager().put("com.designpattern.prototype1.MathHomework", xueba);/*** 学渣都是从学霸那复制来的*/MathHomework xuezha = (MathHomework) Manager.getManager().getPrototype("com.designpattern.prototype1.MathHomework");xuezha.show();}
}
简单形式和登记形式的原型模式各有其长处和短处,如果需要创建的原型对象数目较少 而且比较固定的话可以采取简单形式,如果创建的原型对象数目不固定的话建议采取第二种形式。
原型模式优缺点
优点:
- 原型模式对客户隐藏了具体的产品类
- 运行时刻增加和删除产品: 原型模式允许只通过客户注册原型实例就可以将一个新的具体产品类并入系统。
- 改变值以指定新对象: 高度动态的系统允许通过对象复合定义新的行为。如通过为一个对象变量指定值并且不定义新的类。通过实例化已有类并且将实例注册为客户对象的原型,就可以有效定义新类别的对象。客户可以将职责代理给原型,从而表现出新的行为。
- 改变结构以指定新对象:许多应用由部件和子部件来创建对象。
- 减少子类的构造,Prototype模式克隆一个原型而不是请求一个工厂方法去产生一个新的对象。
- 用类动态配置应用 一些运行时刻环境允许动态将类装载到应用中。
- 使用原型模式创建对象比直接new一个对象在性能上要好的多,因为Object类的clone方法是一个本地方法,直接操作内存中的二进制流,特别是复制大对象时,性能的差别非常明显。
- 使用原型模式的另一个好处是简化对象的创建,使得创建对象很简单。
缺点:
原型模式的主要缺陷是每一个抽象原型Prototype的子类都必须实现clone操作,实现clone函数可能会很困难。当所考虑的类已经存在时就难以新增clone操作,当内部包括一些不支持拷贝或有循环引用的对象时,实现克隆可能也会很困难的。
适用场景
- 资源优化场景。
- 类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等。
- 性能和安全要求的场景。
- 通过 new 产生一个对象需要非常繁琐的数据准备或访问权限,则可以使用原型模式。
- 一个对象多个修改者的场景。
- 一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用。
- 在实际项目中,原型模式很少单独出现,一般是和工厂方法模式一起出现,通过 clone 的方法创建一个对象,然后由工厂方法提供给调用者。原型模式已经与 Java 融为浑然一体,大家可以随手拿来使用。
注意事项:与通过对一个类进行实例化来构造新对象不同的是,原型模式是通过拷贝一个现有对象生成新对象的。浅拷贝实现 Cloneable,重写,深拷贝是通过实现 Serializable 读取二进制流。