文章目录
- 版权声明
- 一 分布式存储缘起
- 二 分布式的基础架构
- 2.1 大数据架构模式
- 2.2 主从模式
- 三 HDFS的基础架构
- HDFS的角色组成
- 四 HDFS集群环境部署
- 4.1 安装包下载
- 4.2 Hadoop安装包目录结构
- 4.3 修改配置文件,应用自定义设置
- 4.4 分发Hadoop文件夹
- 4.5 配置环境变量
- 4.6 授权为hadoop用户
- 4.7 格式化整个文件系统
版权声明
- 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利人所有。本博客的目的仅为个人学习和交流之用,并非商业用途。
- 我在整理学习笔记的过程中尽力确保准确性,但无法保证内容的完整性和时效性。本博客的内容可能会随着时间的推移而过时或需要更新。
- 若您是黑马程序员或相关权利人,如有任何侵犯版权的地方,请您及时联系我,我将立即予以删除或进行必要的修改。
- 对于其他读者,请在阅读本博客内容时保持遵守相关法律法规和道德准则,谨慎参考,并自行承担因此产生的风险和责任。本博客中的部分观点和意见仅代表我个人,不代表黑马程序员的立场。
一 分布式存储缘起
- 数据量太大,单机存储能力有上限,需要靠数量来解决问题
- 数量的提升带来的是网络传输、磁盘读写、CPU、内存等各方面的综合提升。 分布式组合在一起可以达到1+1>2的效果
二 分布式的基础架构
2.1 大数据架构模式
大数据体系中,分布式的调度主要有2类架构模式:
- 去中心化模式
- 中心化模式

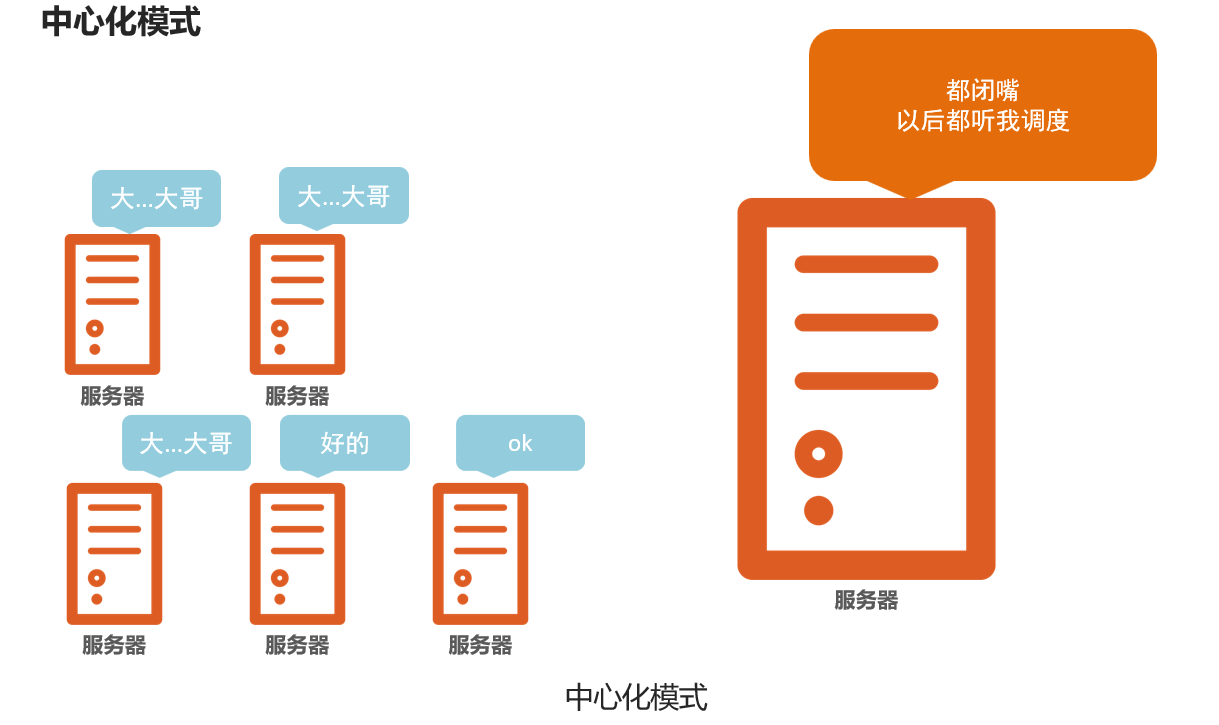
2.2 主从模式
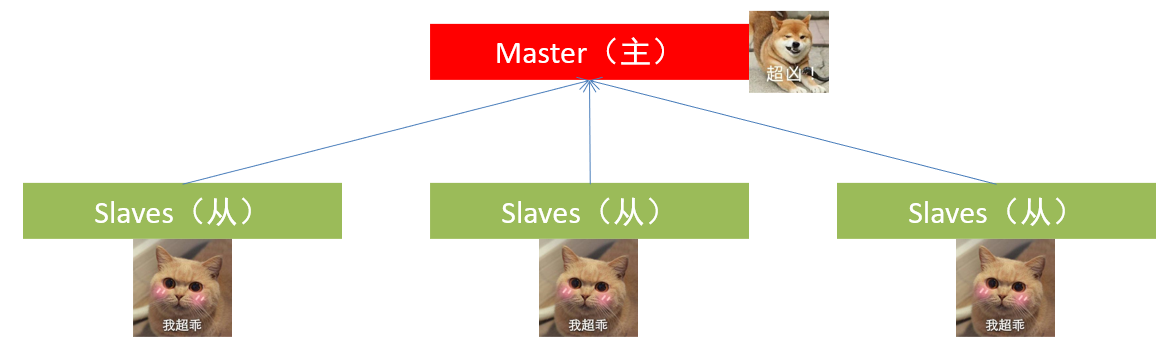
- 大数据框架,大多数的基础架构上,都是符合:中心化模式的。即:有一个中心节点(服务器)来统筹其它服务器的工作,统一指挥,统一调派,避免混乱。这种模式,也被称之为:一主多从模式,简称主从模式(Master And Slaves)
三 HDFS的基础架构

HDFS的角色组成
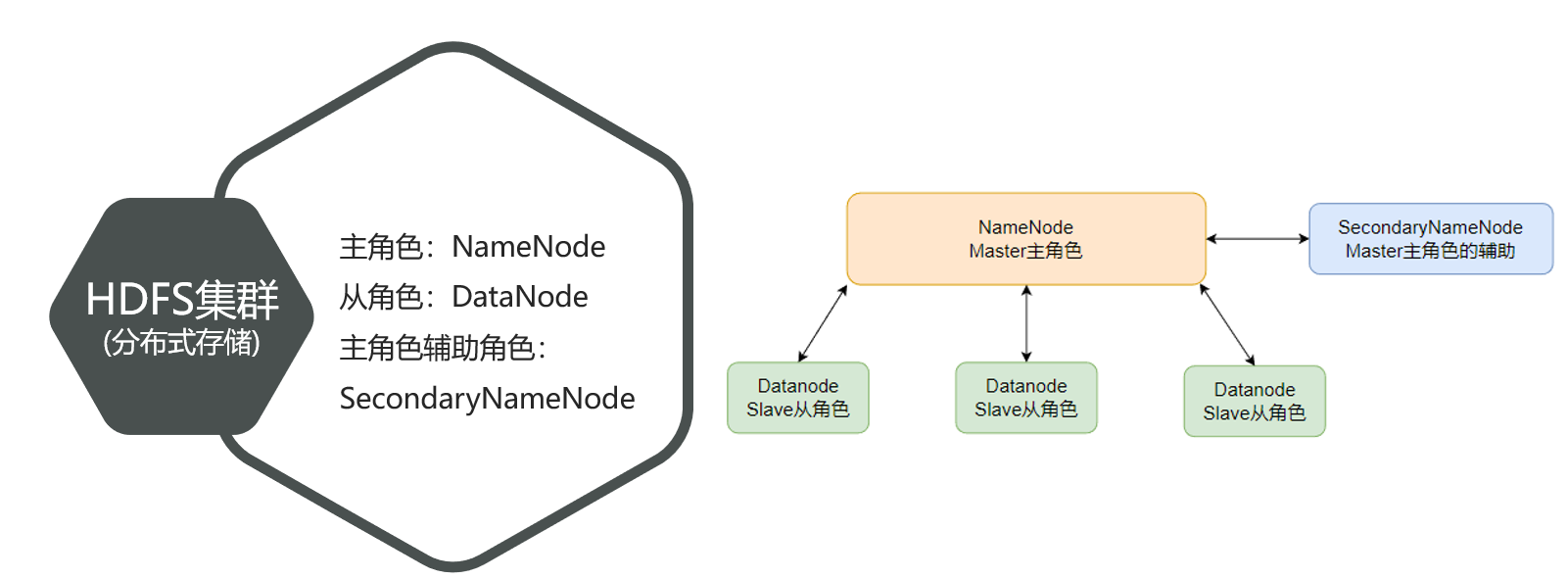
NameNode:
- HDFS系统的主角色,是一个独立的进程
- 负责管理HDFS整个文件系统
- 负责管理DataNode
SecondaryNameNode:
- NameNode的辅助,是一个独立进程
- 主要帮助NameNode完成元数据整理工作(打杂)
DataNode:
- HDFS系统的从角色,是一个独立进程
- 主要负责数据的存储,即存入数据和取出数据
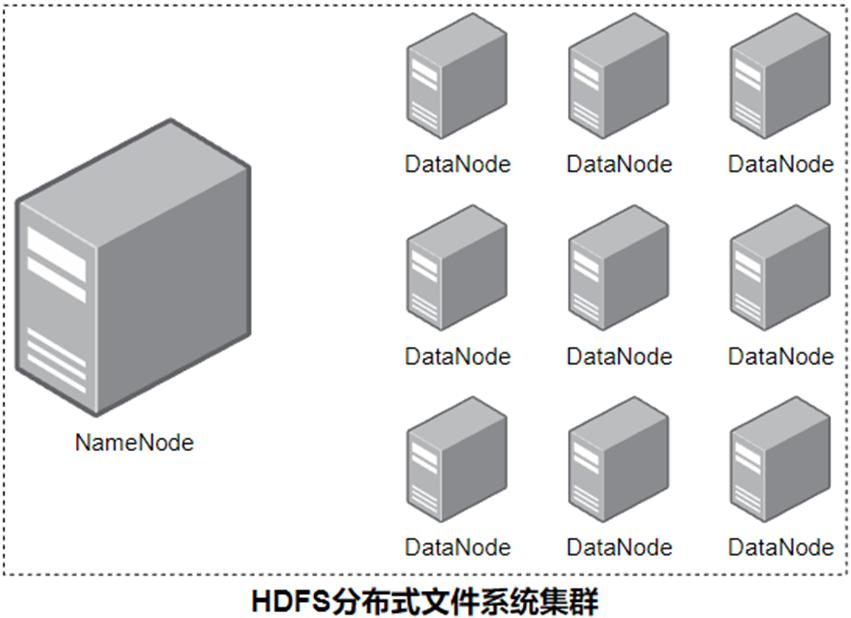
- 一个典型的HDFS集群,就是由1个DataNode加若干(至少一个)DataNode组成
四 HDFS集群环境部署
4.1 安装包下载
- 官方网址

- VMware的三台虚拟机环境准备
Hadoop HDFS的角色包含:
- NameNode,主节点管理者
- DataNode,从节点工作者
- SecondaryNameNode,主节点辅助


- 上传Hadoop安装包到node1节点中
- 解压缩安装包到
/export/server/中tar -zxvf hadoop-3.3.6.tar.gz -C /export/server - 构建软链接
cd /export/server
ln -s /export/server/hadoop-3.3.6 hadoop
- 进入hadoop安装包内
cd hadoop
4.2 Hadoop安装包目录结构
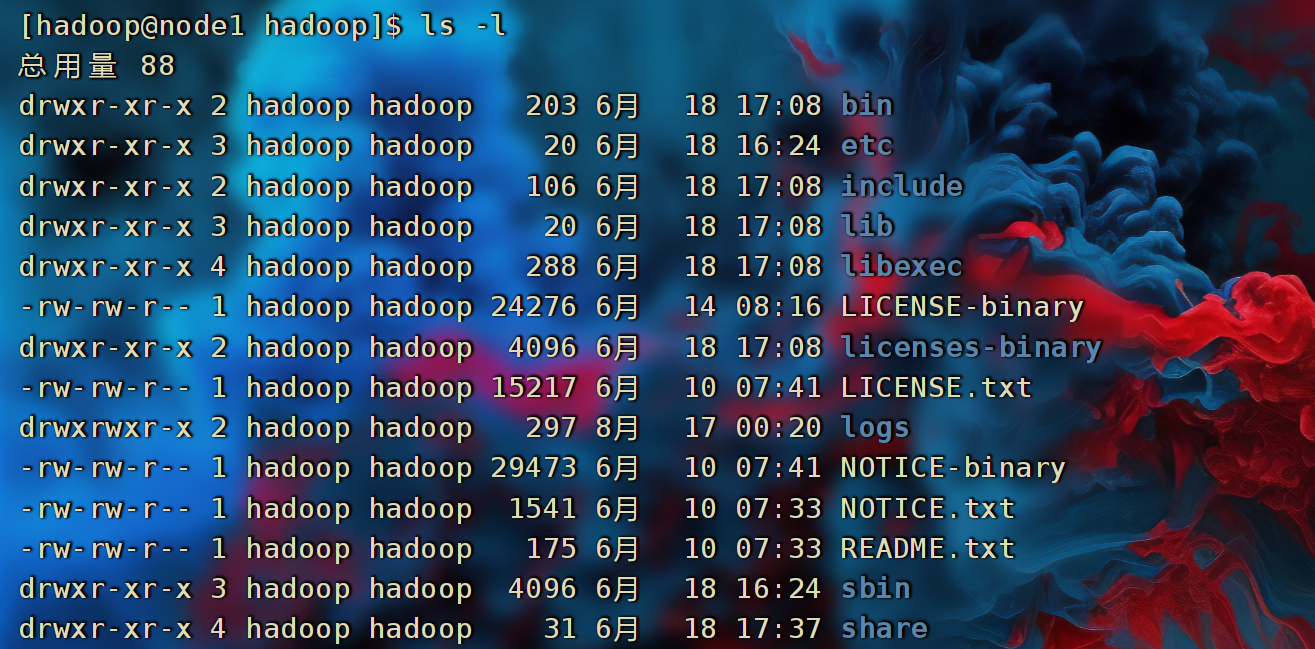
- cd 进入Hadoop安装包内,通过ls -l命令查看文件夹内部结构
4.3 修改配置文件,应用自定义设置
配置HDFS集群,主要涉及到如下文件(均在hadoop/etc/hadoop目录)的修改:
- workers: 配置从节点(DataNode)
- hadoop-env.sh:配置Hadoop的相关环境变量
- core-site.xml:Hadoop核心配置文件
- hdfs-site.xml:HDFS核心配置文件
这些文件均存在与$HADOOP_HOME/etc/hadoop文件夹中。
- ps:
$HADOOP_HOME是后续要设置的环境变量,其指代Hadoop安装文件夹即/export/server/hadoop
- 配置workers文件:填入的node1、node2、node3表明集群记录了三个从节点(DataNode)
# 进入配置文件目录
cd etc/hadoop
# 编辑workers文件
vim workers
# 填入如下内容
node1
node2
node3
- 配置
/export/server/hadoop/etc/hadoop/hadoop-env.sh文件
# 填入如下内容
export JAVA_HOME=/export/server/jdk8
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
- JAVA_HOME,指明JDK环境的位置在哪
- HADOOP_HOME,指明Hadoop安装位置
- HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
- HADOOP_LOG_DIR,指明Hadoop运行日志目录位置
- 配置core-site.xml文件,在文件内部填入如下内容
<configuration><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>
-
key:fs.defaultFS
-
含义:HDFS文件系统的网络通讯路径
-
值:hdfs://node1:8020
- 协议为hdfs://
- namenode为node1
- namenode通讯端口为8020
-
key:io.file.buffer.size
-
含义:io操作文件缓冲区大小
-
值:131072 bit
-
hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)
-
表明DataNode将和node1的8020端口通讯,node1是NameNode所在机器
-
此配置固定了node1必须启动NameNode进程
- 配置hdfs-site.xml文件
# 在文件内部填入如下内容
<configuration><property><name>dfs.datanode.data.dir.perm</name><value>700</value></property><property><name>dfs.namenode.name.dir</name><value>/data/nn</value></property><property><name>dfs.namenode.hosts</name><value>node1,node2,node3</value></property>
<property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.namenode.handler.count</name><value>100</value></property><property><name>dfs.datanode.data.dir</name><value>/data/dn</value></property>
</configuration>
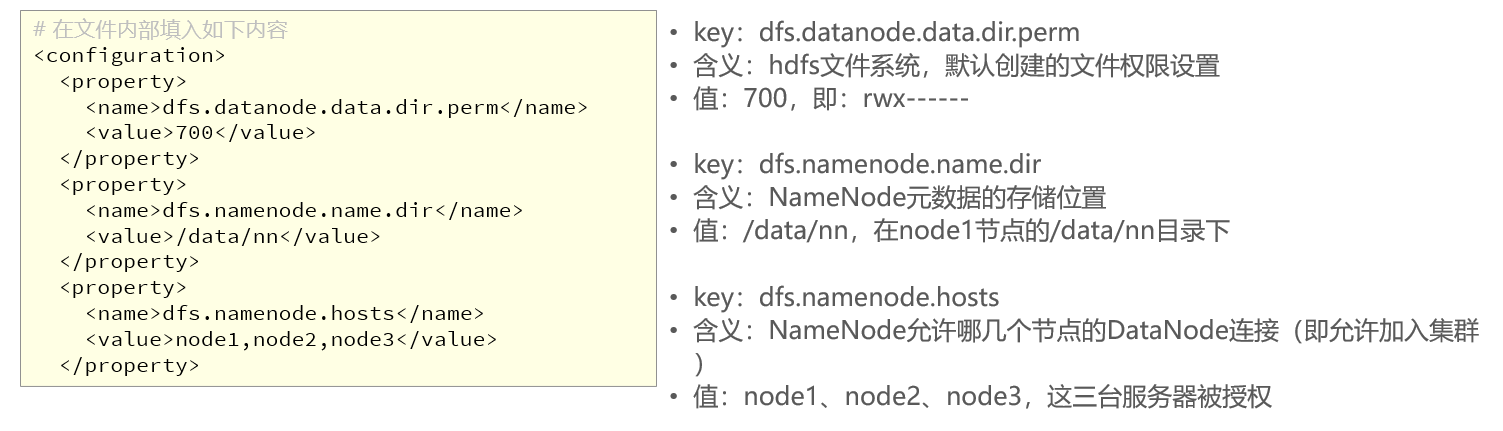


- 我们需要手动需要创建相关的目录
- 在node1节点:
mkdir -p /data/nn mkdir /data/dn - 在node2和node3节点:
mkdir -p /data/dn
4.4 分发Hadoop文件夹
- 至此已经基本完成Hadoop的配置操作,可以从node1将hadoop安装文件夹远程复制到node2、node3分发
# 在node1执行如下命令 cd /export/server scp -r hadoop-3.3.4 node2:`pwd`/ scp -r hadoop-3.3.4 node3:`pwd`/ - 在node2执行,为hadoop配置软链接
# 在node2执行如下命令 ln -s /export/server/hadoop-3.3.4 /export/server/hadoop - 在node3执行,为hadoop配置软链接
# 在node3执行如下命令 ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
4.5 配置环境变量
- 为了方便操作Hadoop,可以将Hadoop的一些脚本、程序配置到PATH中,方便后续使用
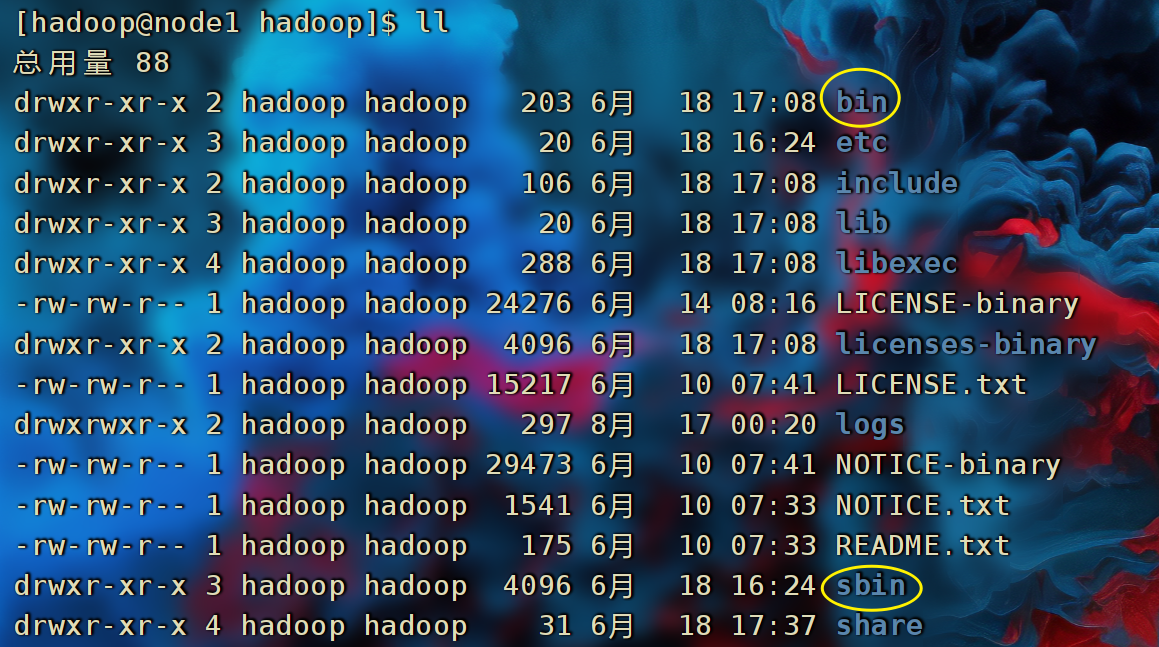
- 在Hadoop文件夹中的bin、sbin两个文件夹内有许多的脚本和程序,现在来配置一下环境变量
- 编辑环境变量配置文件
vim /etc/profile
# 在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 在node2和node3配置同样的环境变量
- 使环境变量生效
source /etc/profile
4.6 授权为hadoop用户
- hadoop部署的准备工作基本完成。为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务。所以,现在需要对文件权限进行授权。
- 以root身份,在node1、node2、node3三台服务器上均执行如下命令
# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
4.7 格式化整个文件系统
- 格式化namenode
# 确保以hadoop用户执行 su - hadoop # 格式化namenode hadoop namenode -format - 启动
# 一键启动hdfs集群 start-dfs.sh # 一键关闭hdfs集群 stop-dfs.sh # 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行 /export/server/hadoop/sbin/start-dfs.sh /export/server/hadoop/sbin/stop-dfs.sh - 查看三种角色的运行状态
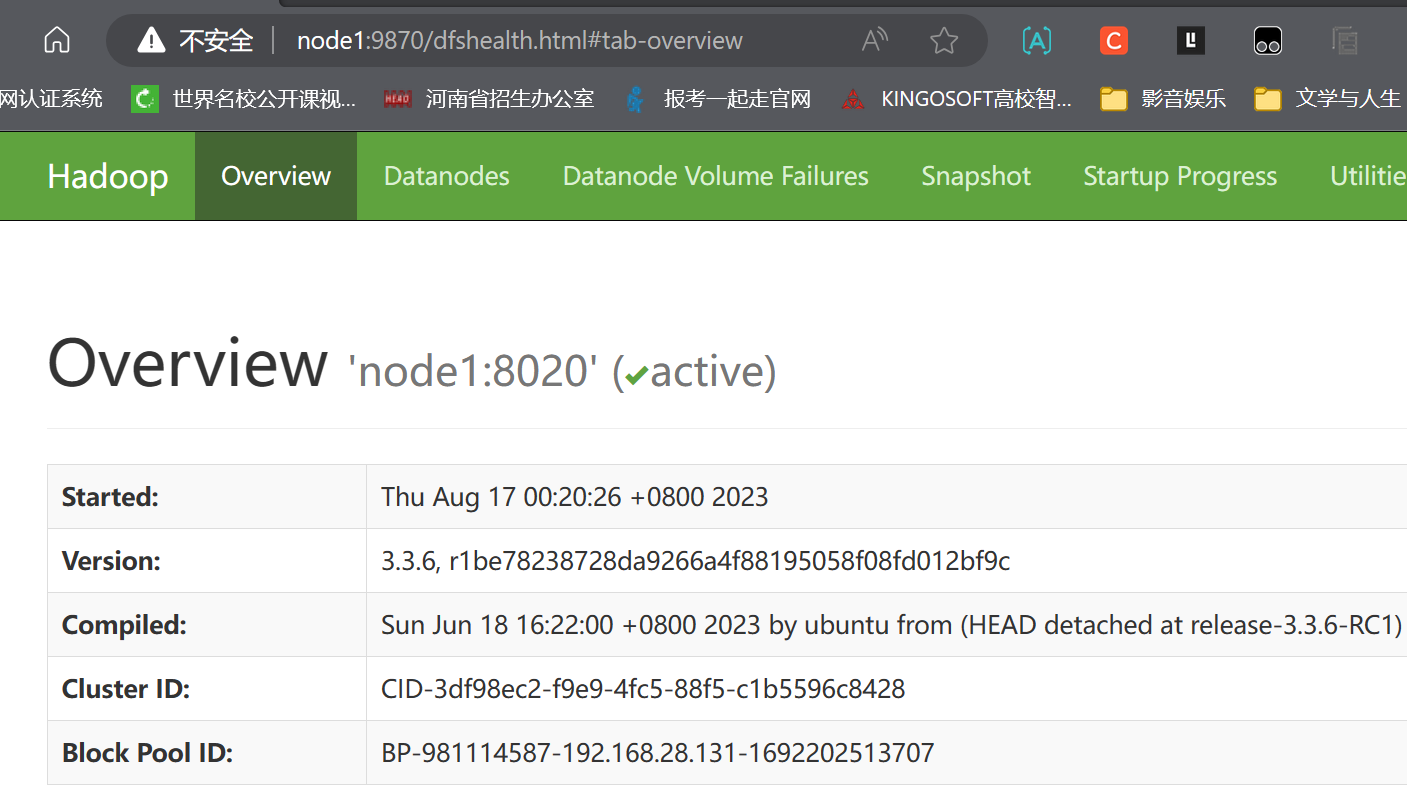
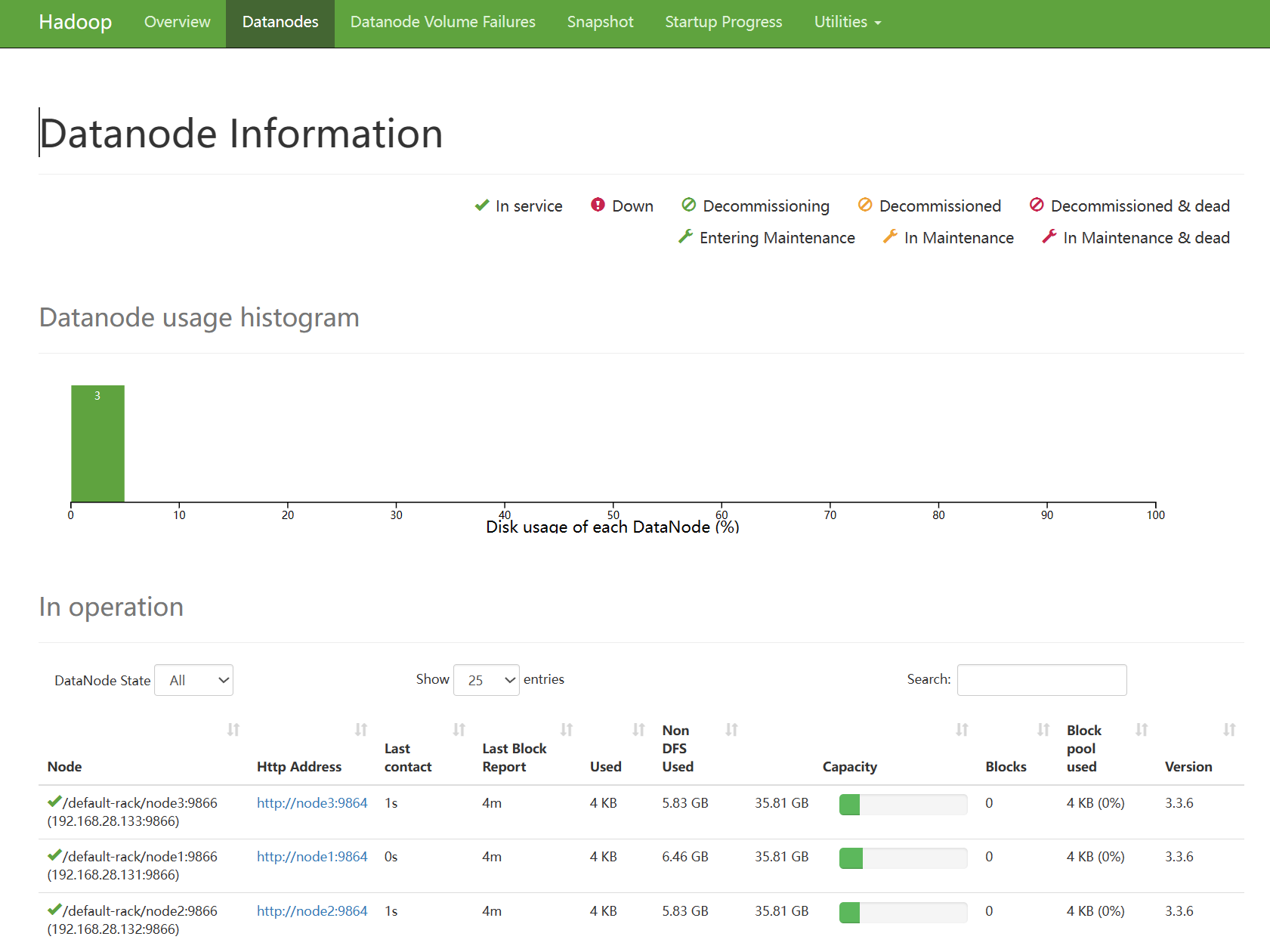
# node1的情况 [hadoop@node1 ~]$ jps 25937 Jps 25063 NameNode 25207 DataNode 25543 SecondaryNameNode - 查看HDFS WEBUI
![企望制造ERP系统 RCE漏洞[2023-HW]](https://img-blog.csdnimg.cn/28245cc051824be8a53585884add35df.png)