豆瓣电影 Top 250 榜单是豆瓣网站上列出的评分最高、受观众喜爱的电影作品。这个榜单包含了一系列优秀的影片,涵盖了各种类型、不同国家和时期的电影。 使用python爬取top250电影,获取相应电影排名,电影名,星级, 打分和评论人数信息,将信息输出到Excel表格中。 def download_all_htmls ( index = list ( range ( 0 , 250 , 25 ) ) ) : htmls = [ ] for idx in index: url = f"https://movie.douban.com/top250?start= { idx} &filter=" print ( "craw html:" , url) headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36' } r = requests. get( url, headers = headers) if r. status_code != 200 : raise Exception( "error" ) htmls. append( r. text) return htmls
def parse_single_heml ( html) : soup = BeautifulSoup( html, 'html.parser' ) article_items = soup. find( 'div' , class_= 'article' ) \. find( 'ol' , class_= 'grid_view' ) \. find_all( 'div' , class_= 'item' ) datas = [ ] for article_item in article_items: rank = article_item. find( 'div' , class_= 'pic' ) . find( 'em' ) . get_text( ) info = article_item. find( 'div' , class_= 'info' ) title = info. find( 'div' , class_= 'hd' ) . find( 'span' , class_= 'title' ) . get_text( ) stars = info. find( 'div' , class_= 'bd' ) . find( 'div' , class_= 'star' ) . find_all( 'span' ) rating_star = stars[ 0 ] [ "class" ] [ 0 ] rating_num = stars[ 1 ] . get_text( ) comments = stars[ 3 ] . get_text( ) datas. append( { 'rank' : rank, 'title' : title, 'rating_star' : rating_star. replace( "rating" , "" ) . replace( "-t" , "" ) , 'rating_num' : rating_num, 'comments' : comments. replace( "人评价" , "" ) } ) return datas
import requests
from bs4 import BeautifulSoup
import pandas as pd
import pprint
import jsonhtmls = download_all_htmls( )
all_datas = [ ]
for html in htmls: all_datas. extend( parse_single_heml( html) )
df = pd. DataFrame( all_datas)
df. to_excel( "practice03_豆瓣电影top250.xlsx" , index= False )
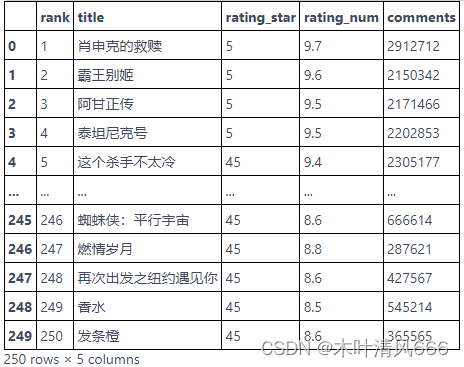
结果展示