论文摘要
LiDAR 收集的数据通常表现出稀疏和不规则的分布。
3D 空间中的 LiDAR 扫描并不均匀。近处和远处的物体之间存在巨大的分布差距。
CasA(Cascade Attention) 由 RPN(Region proposal Network)和 CRN(cascade refinement Network)组成。
RPN 使用 3-D backbone 网络将体素编码为 3-D 特征 volumes。然后采用二维检测头来生成区域 proposal。与大多数使用单个子网络细化区域建议的最先进的两级 3D 检测器不同, CRN 逐步细化和补充来自一系列子网工作的预测,形成高质量的预测。此外,论文设计了一种新的级联注意力模块(CAM)来聚合来自不同阶段的特征以进行全面的区域提议细化。
CasA 集成了 part-aided 评分,将 parts 的目标完整性视为 structure-aware 单级 3D 目标检测 [structure-aware 单级检测器 (SA-SSD)],以更好地估计 proposal confidence。
论文背景
3D 目标检测是场景理解的关键任务之一。
现有方法主要遵循单级或两级检测框架。
单阶段方法直接使用点云的编码特征执行目标检测。
两阶段方法遵循 region-based 卷积神经网络(RCNN)框架。首先生成一组候选边界框,然后使用感兴趣区域(RoI)池化方法提取提案的区域特征,最后使用提取的特征细化 proposal。
多阶段(两阶段之外)的方法已经被广泛探索,并在2D 目标检测中被证明是有效的。但在点云上进行完全监督的 3-D 目标检测的多阶段方法仍未得到充分探索。当前的多阶段方法和级联结构使用一系列独立的子网络来细化目标 proposal。一般来说,这些方法可以学习各种困难下的对象特征,但在后面的阶段衡量所有先前阶段 proposal 质量的能力有限。
论文工作

CasA 是一个多级检测框架,可以集成到各种两阶段 3D 检测器中。目的是以级联注意力方式聚合来自所有阶段的特征。
CasA 由一个 RPN 和一个 CRN 组成:RPN 首先使用 3-D 主干网络和 2-D 检测头来生成区域提案。CRN 由多个子网络组成,该方案聚合不同阶段的提案特征以进行更全面的边界框预测。
Cascade Attention for Proposal Refinemen
普通级联结构
Cascade R-CNN [1] 使用普通级联结构,该结构使用一系列单独的子网络并提高 IoU 阈值来细化区域提案。
[1] Z. Cai and N. Vasconcelos, “Cascade R-CNN: Delving into high quality object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 6154–6162.
这样一个普通级联结构包括 N r N_r Nr 个refiner。 第 j j j 个 refiner 将来自前一阶段的 region proposal B j − 1 B^{j-1} Bj−1 作为输入,并利用特征提取器 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 来提取目标特征 F j F^{j} Fj。然后,对 F j F^{j} Fj 进行置信度预测 S ( ⋅ ) \mathcal {S(\cdot)} S(⋅) 以及 box 回归 R ( ⋅ ) \mathcal R(\cdot) R(⋅),输出为一个新的置信分数 C j C^j Cj 和 新的 box B j B^j Bj。公式如下: F j = ϕ j ( B j − 1 ) , C j = S j ( F j ) , B j = R j ( F j ) (1) \tag 1 F^{j}=\phi^{j}(B^{j-1}),C^{j} = \mathcal S^{j}(F^j),B^{j}=\mathcal R^{j}(F^{j}) Fj=ϕj(Bj−1),Cj=Sj(Fj),Bj=Rj(Fj)(1)其中 j = 1 , 2 , . . . , N r j = 1,2,...,N_r j=1,2,...,Nr。
这种设计已在二维物体检测中被证明是有效的。然而,直接在 3D 中应用这种普通级联结构并不能带来理想的改进。例如,在 KITTI 验证集上,使用具有普通级联结构的 Voxel-RCNN 检测器,检测性能(在中等汽车类别上),如表 1 所示,没有改善。

改进不理想的原因有:
1.忽略了远处的目标
在多阶段方法中,由于缺乏负训练样本,后期阶段往往会过度拟合。2-D 方法建立不断上升的 IoU 阈值来重新采样平衡样本。然而,在 3D 点云中,这种重采样会导致附近和远处对象之间的训练不平衡,因为点云通常是非均匀分布的。 具有密集点的附近物体可以产生被选为正样本的高质量提案,而远处的物体往往是负样本。
在这种不平衡的训练下,后期会准确地预测附近的物体,而忽略远处的物体。
应对措施:在前面阶段中增加更多的目标 appearance 来确保后面阶段中仍然有足够的 evidence 来恢复被忽略的远处目标
2.误差传播问题
由于需要物体高度和非轴对齐角度估计,3D 检测更具挑战性。Small errors 可能会沿着下游多级框架传播,从而导致检测失败。
应对措施: 在阶段之间建立更多的连接,并且单个阶段的 errors 可以由其他阶段以互补的方式修复。
论文在这些 refiner 之间建立有效的连接,以组成有效的精炼。最后,设计了特征提取器 CAM 来聚合不同阶段的目标特征。
通过级联注意力进行特征聚合
给出一个 region proposal B j − 1 B^{j-1} Bj−1,大部分已知的检测器使用一个 region pooling module 来提取提议特征 F ^ j ∈ R 1 × C \hat F^j \in \R^{1 \times C} F^j∈R1×C 来做 box 回归以及置信度预测,其中 C C C 是特征维度。
然而在级联结构中,这样的策略只能捕捉到当前阶段的 proposal 特征,忽略了先前的其他阶段。一个简单的方法是直接拼接来自不同阶段的特征。但是这很难学习到阶段与阶段之间的特征重要性,并且它带来的性能提升有限。
论在对于每个编码的特征 F ^ j \hat F^j F^j ,首先连接了一个阶段的 的位置 embedding P j P^j Pj。 F ^ j = [ F ^ j , P j ] \hat F^j = [\hat F^j,P^j] F^j=[F^j,Pj]。在第 j j j 个 refinement 阶段,收集来自其他所有先前阶段的 F j = [ F ^ 0 , F ^ 1 , . . . , F ^ j ] \boldsymbol F^j=[\hat F^0,\hat F^1,...,\hat F^j] Fj=[F^0,F^1,...,F^j]。然后有 Q j = F ^ j W q j , K j = F ^ j W k j , V j = F ^ j W v j \boldsymbol Q^j = \hat F^j \boldsymbol W_q^j,\boldsymbol K^j = \hat F^j \boldsymbol W_k^j\boldsymbol, V^j = \hat F^j \boldsymbol W_v^j Qj=F^jWqj,Kj=F^jWkj,Vj=F^jWvj,其中 W q j , W k j , W v j \boldsymbol {W_q^j,W_k^j,W_v^j} Wqj,Wkj,Wvj 都是线性投影。 Q j , K j , V j \boldsymbol {Q^j,K^j,V^j} Qj,Kj,Vj 分别是 Query、Key 和 value embedding。为了增强 representational ability,采取了多头设计。来自第 i i i 个头的 embeding 为 Q i j , K i j , V i j \boldsymbol {Q_i^j,K_i^j,V_i^j} Qij,Kij,Vij。一个头的注意力为: F ^ i j = softmax ( Q i j ( K i j ) T C ′ ) V i j . (2) \tag2 \hat F_i^j = \text{softmax} \Big( \frac{ \boldsymbol {Q_i^j} (\boldsymbol K_i^j)^T} {\sqrt{C^{'}}} \Big) \boldsymbol V_i^j . F^ij=softmax(C′Qij(Kij)T)Vij.(2) 其中 C ′ C^{'} C′ 是多头注意力中的特征维度。直观上,现阶段的特征对 proposal refinement 贡献更大。因此,我们还将特征 F ^ j \hat F^j F^j 与 H H H 多头注意力特征连接起来,以制定用于框回归和置信度预测的特征向量 F j F^j Fj: F j = Concat ( F ^ j , F 1 j , F 2 j , . . . , F H j ) . (3) \tag3 F^j = \text{Concat}(\hat F^j,\boldsymbol F^j_1,\boldsymbol F^j_2,...,\boldsymbol F^j_H). Fj=Concat(F^j,F1j,F2j,...,FHj).(3)对于第一个细化阶段,实际上执行自注意力操作。对于其他阶段,我们执行 cross-attention 操作,聚合来自不同阶段的特征。通过采用这样的级联注意力设计,CasA可以更好地估计所有阶段的 proposal 质量,这有助于提高提案细化的准确性。
Box Regression and Part-Aided Scoring
对相对于输入 3D proposal 的 box size,位置,方向残差进行回归。论文受到 part-sensitive warping[2] 对部分分数图中的目标分数进行平均的启发设计了一个 part-Aided score a j a^j aj 来增强置信度预测。
C. He, H. Zeng, J. Huang, X.-S. Hua, and L. Zhang, “Structure aware single-stage 3D object detection from point cloud,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 11873–11882.
在 pipeline 中,从 局部(part-based) 和全局视角进行 part-aided score 的计算。具体来说, α j \alpha^j αj 由置信度预测分支 S ( ⋅ ) \mathcal S(\cdot) S(⋅) 和 part-sensitive warping W ( ⋅ ) \mathcal W(\cdot) W(⋅) 来计算: α j = S j ( F j ) + W ( B j , X ) (4) \tag4 \alpha^j=\mathcal S^j(F^j)+\mathcal W(B^j,\boldsymbol X) αj=Sj(Fj)+W(Bj,X)(4)其中 X \boldsymbol X X 是由 RPN 预测的 part score map。通过这样调制,新的 part-aided scoring 使 检测器可以更加精确的估计每个阶段的对象置信度。
在训练中,类似于级联的 R-CNN,设置 3-D IoU 阈值 u = { u 1 , u 2 , . . . , u N r } u =\{ u^1,u^2,...,u^{N_r}\} u={u1,u2,...,uNr} 来定义在不同精细化阶段的正负。
在测试中,对所有细化阶段的框和分数进行平均生成最终检测结果。
Boxes Voting
由于需要物体高度和非轴对齐角度估计,3D 检测更具挑战性。错误倾向于沿着下游多级框架传播。为了进一步解决这个问题,在测试过程中,提出了 Boxes Voting,以建立更多的阶段之间的连接。每个阶段都会输出弱预测和强预测,这些预测可以集成在一起以生成更准确的预测。每个阶段都会输出弱预测和强预测,这些预测可以集成在一起以生成更准确的预测。
一种简单的方法是直接对所有框进行非极大值抑制(Nonmaximum Suppression,NMS),并通过选择置信度最高的框来 assemble 结果。然而,它忽略了低置信度的框,这些框有可能可以检测出未被检测出的目标。
应对措施:论文采用加权 Boxes Voting,直接平均检测置信度,并将按检测置信度加权的框合并为 C = 1 N r ∑ j C j (5) \tag 5 C=\frac{1}{N_r}\sum_jC^j C=Nr1j∑Cj(5) B = 1 ∑ j C j ∑ j C j ⋅ B j (6) \tag6 B = \frac{1}{\sum_jC^j}\sum_jC^j \cdot B^j B=∑jCj1j∑Cj⋅Bj(6) 其中 C C C 和 B B B 分别是合并的置信度和框。
经过 Boxes Voting,得到了一组 refined 高品质 boxes。尽管如此,仍然存在很多冗余 boxes,因为每个目标都有许多 refined proposal。为了删除冗余框,最终对投票结果执行 NMS 以产生检测输出。
通过采用投票机制,不同精炼者产生的各种预测(置信度较低、视角/尺度不同)可以以互补的方式组合成更准确/可靠的最终预测。
Backbone Network
首先将原始点云 P 分割成小体素。对于每个体素,使用所有内部点的原始特征的平均值来计算原始特征。采用 3-D 稀疏卷积 S ( ⋅ ) \mathcal S(·) S(⋅) 将 3-D 点云编码为特征 volumes。这里, S ( ⋅ ) \mathcal S(·) S(⋅) 由一系列 3 × 3 × 3 3×3×3 3×3×3 的 3-D 稀疏卷积核组成,它们将空间特征下采样到 1 × 、 2 × 、 4 × 1×、2×、4× 1×、2×、4×,最终得到 8 × 8× 8× 下采样的张量。最后一层中的 3D 特征沿着高度维度被压缩为 BEV 特征,用于生成目标 proposal。
区域提议网络 RPN
通过在 BEV 特征图上应用一系列二维卷积来生成 目标 proposal ,并从 BEV 图生成目标 proposal。
首先在 BEV 地图的最后一层上预定义称为锚点的 N p N_p Np 个目标模板。通过对锚点进行分类并回归相对于真实框的对象大小、位置和方向角的残差来生成目标 proposal。通过基于 IoU 的匹配将真实边界框分配给锚点。对于第 i i i 个锚点,描述得分预测,得分目标以及残差预测和残差目标为 a i , a ^ i , δ i , δ ^ i j a_i,\hat a_i,\delta_i,\hat \delta_i^j ai,a^i,δi,δ^ij。Proposal network的损失定义为: L R P N = 1 N p [ ∑ i L s c o r e ( α , α ^ i ) + I ( I o U > u ) ∑ i L r e g ( δ i , δ ^ i ) ] (7) \tag7 \mathcal L_{RPN} = \frac{1}{N_p} \Big[ \sum_i \mathcal L_{score}(\alpha,\hat \alpha_i)+ \mathcal I(IoU > u) \sum_i{\mathcal L_{reg}(\delta_i,\hat \delta_i)} \Big] LRPN=Np1[i∑Lscore(α,α^i)+I(IoU>u)i∑Lreg(δi,δ^i)](7)其中 I ( I o U i > u ) \mathcal I(IoU_i > u) I(IoUi>u) 表示只有 I o U i > u IoU_i > u IoUi>u 的目标 proposal 才会产生回归损失, L r e g \mathcal L_{reg} Lreg 和 L s c o r e \mathcal L_{score} Lscore 分别是平滑 L1 和二元交叉熵损失。
总体训练损失
CasA 可以通过 RPN 损失 L R P N L_{RPN} LRPN 和 CRN 损失 L C R N L_{CRN} LCRN 进行端到端训练。将两个损失以相同的权重结合起来,即 L = L R P N + L C R N L = L_{RPN} + L_{CRN} L=LRPN+LCRN。
CRN 损失是多个阶段的多个细化损失的总和。在每个细化阶段,采用框回归损失 L r e g L_{reg} Lreg 和得分损失 L s c o r e L_{score} Lscore。对于第 j j j 个细化阶段的第 i i i 个提案, a i j , a ^ i j , δ i j , δ ^ i j a_i^j,\hat a_i^j,\delta_i^j,\hat \delta_i^j aij,a^ij,δij,δ^ij 表示分数预测、分数目标、残差预测、残差目标。
CRN 的 loss 被定义为: L = 1 N b [ ∑ i ∑ j L s c o r e ∗ ( α i j , α ^ i j ) + I ( I o U i j > u j ) ∑ i ∑ j L r e g ( δ i j , δ ^ i j ) ] (8) \tag 8 \mathcal L = \frac{1}{N_b} \Big[ \sum_i \sum_j \mathcal L_{score}*(\alpha_i^j,\hat \alpha_i^j)+\mathcal I\Big( IoU_i^j > u^j \Big) \sum_i \sum_j \mathcal L_{reg} \Big( \delta_i^j, \hat\delta_i^j \Big) \Big] L=Nb1[i∑j∑Lscore∗(αij,α^ij)+I(IoUij>uj)i∑j∑Lreg(δij,δ^ij)](8) 其中, I ( I o U i j > u j ) \mathcal I\Big( IoU_i^j > u^j \Big) I(IoUij>uj)表示只有 I o U i j > u j IoU^j_i > u^j IoUij>uj 的 object proposals 才会产生回归损失。
论文总结
论文提出了一种多级 3-D 目标检测器 CasA,它通过级联注意力结构逐步细化区域建议。 CasA 通过聚合多个阶段的物体特征,解决了多阶段 3D 物体检测中忽略远处物体和错误传播的问题。
计算成本和性能改进之间存在权衡。
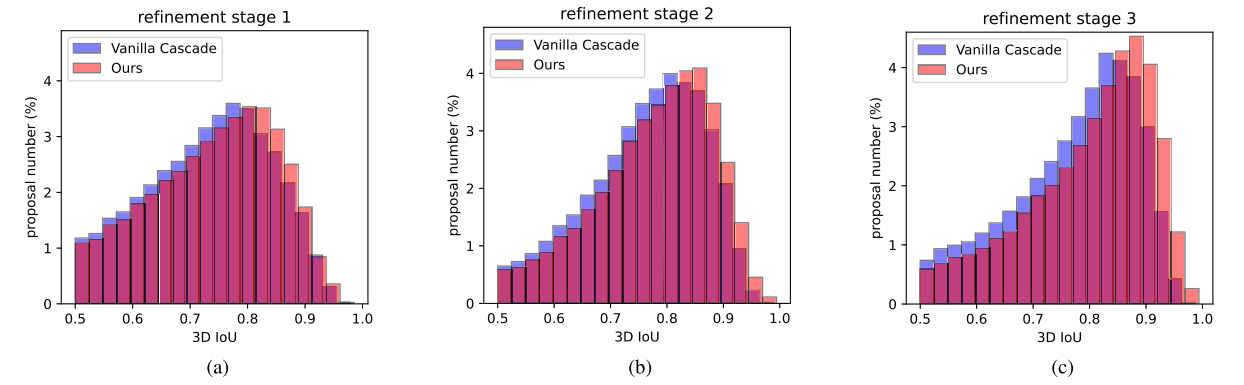 在三阶段细化的情况下明显更好。
在三阶段细化的情况下明显更好。