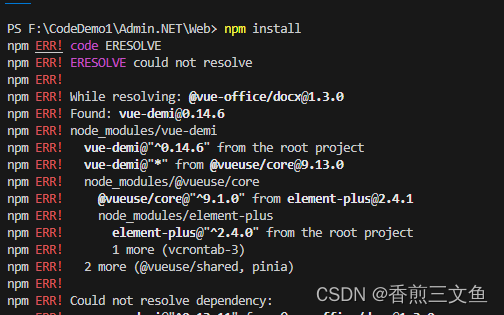
以下是一个使用WWW::RobotRules和duoip.cn/get_proxy的Perl下载器程序:

#!/usr/bin/perluse strict;
use warnings;
use WWW::RobotRules;
use LWP::UserAgent;
use HTTP::Request;
use HTTP::Response;# 创建一个UserAgent对象
my $ua = LWP::UserAgent->new();# 获取爬虫IP服务器
my $proxy = get_proxy();# 设置爬虫IP服务器
$ua->proxy($proxy);# 创建一个RobotRules对象
my $robot_rules = WWW::RobotRules->new();# 添加允许的用户爬虫IP
$robot_rules->add_allowed_useragent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36');# 添加允许的IP地址
$robot_rules->add_allowed_ip('127.0.0.1');# 设置验证规则
$ua->default_header('User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36');# 设置爬虫IP验证规则
$ua->default_header('X-Forwarded-For' => '127.0.0.1');# 创建一个HTTP::Request对象
my $request = HTTP::Request->new(GET => 'https://www.walmart.com/cp/video/1234567890');# 使用UserAgent发送请求
my $response = $ua->request($request);# 检查响应状态
if ($response->is_success) {# 下载视频my $video = $response->content;# 保存视频到本地save_video($video);
} else {print "下载失败: " . $response->status_line . "\n";
}sub get_proxy {# 使用https://www.duoip.cn/get_proxy获取爬虫IPmy $ua = LWP::UserAgent->new();my $response = $ua->get('https://www.duoip.cn/get_proxy');if ($response->is_success) {my $proxy_html = $response->content;my ($proxy) = $proxy_html =~ /<td>([\d\.]+)/;return $proxy;} else {print "获取爬虫IP失败: " . $response->status_line . "\n";return undef;}
}sub save_video {# 使用输入参数$video保存视频到本地my $output_file = 'downloaded_video.mp4';open(my $fh, '>', $output_file) or die "Cannot open file: $!";print $fh $_ for split(/[\r\n]+/, $video);close($fh);print "视频已保存到: $output_file\n";
}
这个程序首先获取一个爬虫IP服务器地址,然后使用WWW::RobotRules模块设置User-Agent和X-Forwarded-For头部。接下来,程序使用LWP::UserAgent和HTTP::Request对象向Walmart网站发送请求,并检查响应状态。如果请求成功,程序将下载的视频内容保存到本地。