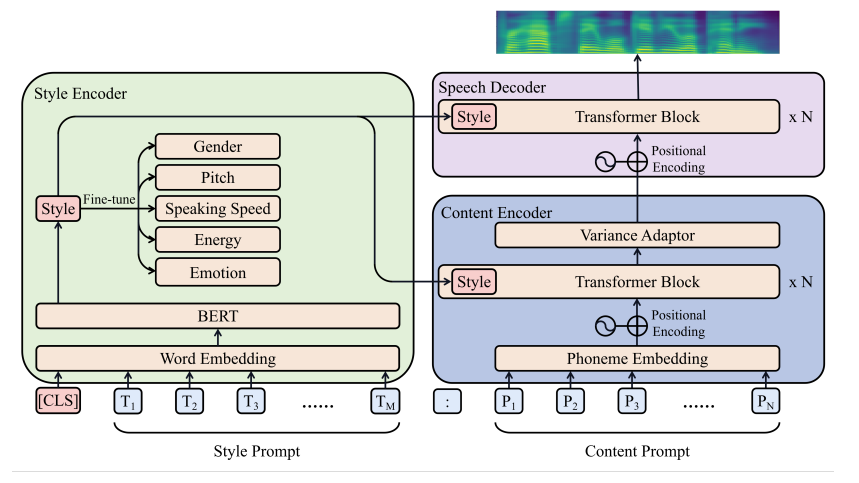
String 为什么不可变?
1线程安全
2支持hash映射和缓存。因为String的hash值经常会使用到,比如作为 Map 的键,不可变的特性使得 hash 值也不会变,不需要重新计算。
3出于安全考虑。网络地址URL、文件路径path、密码通常情况下都是以String类型保存,
4.字符串常量池优化
String, StringBuffer 和 StringBuilder区别
1. 可变性String 不可变StringBuffer 和 StringBuilder 可变
2. 线程安全String 不可变,因此是线程安全的
StringBuilder 不是线程安全的 效率最高
StringBuffer 是线程安全的,内部使用 synchronized 进行同步
Java 反射是指在运行时获取和使用类的内部信息的能力。反射可以用来获取类的名称、方法、属性、构造方法等信息,也可以用来调用类的方法、设置属性的值等。
Arraylist 和 Vector 的区别
*ArrayList在内存不够时扩容为原来的1.5倍,Vector是扩容为原来的2倍。
*Vector(淘汰1.2)属于线程安全级别的,但是大多数情况下不使用Vector,因为操作Vector效率比较低。
CopyOnWriteArrayList: 线程安全的 List,在读多写少的场合性能非常好,远远好于 Vector.
HashMap和HashTable的区别?
*HashMap和Hashtable都实现了Map接口。
*HashMap可以接受为null的key和value,key为null的键值对放在下标为0的头结点的链表中,而Hashtable则不行。
*HashMap是非线程安全的,HashTable是线程安全的。Jdk1.5提供了ConcurrentHashMap,它是HashTable的替代。
*Hashtable很多方法是同步方法,在单线程环境下它比HashMap要慢。
*哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
LinkedHashMap是*HashMap的子类 非线程安全
TreeMap是有序的key-value集合,通过红黑树实现。根据键的自然顺序进行排序或根据提供的Comparator进行排序
HashMap、 HashTable、 LinkedHashMap TreeMap区别
非线程安全 | 线程安全 | 非线程安全 | 非线程安全
无序 | 按照键的插入顺序 | 按照键的插入顺序 | 按照键的升序或降序
扩容:根据负载因子 | 固定的 | 根据负载因子 | 固定的 |
性能 | 高 | 低 | 高 | 低 |
Con cu rrentHashMap 高效线程安全 替代HashMap、 性能低一点点
扩容:
固定:简单粗暴 浪费空间
负载因子:合理利用空间 ,加强并发 动态适应 0.72
ConcurrentHashMap理解
ConcurrentHashMap是Java中的线程安全的哈希表实现,它是HashMap的线程安全版本。ConcurrentHashMap具有以下特点和原理:
1. 线程安全性:ConcurrentHashMap使用了锁分段技术,将整个哈希表分成多个段(Segment),每个段都有自己的锁。这样不同的线程可以同时访问不同的段,提高了并发性能。相比于使用全局锁的方式,ConcurrentHashMap能够支持更高的并发度。
2. 分段锁:ConcurrentHashMap中的每个段都是一个独立的哈希表,具有自己的锁。当一个线程对某个段进行操作时,只需获取该段的锁,而不会影响其他段的访问。这样可以减小锁的粒度,提高并发性能。
3. 原子操作:ConcurrentHashMap中的一些操作是原子的,比如putIfAbsent、remove、replace等。这些操作可以保证在多线程环境下的原子性,避免了竞态条件。
4. 读操作的无锁优化:ConcurrentHashMap在读操作上进行了优化,读操作不需要获取锁。这样可以实现读写分离,提高并发性能。
5. 扩容机制:ConcurrentHashMap在扩容时,只需对部分段进行扩容,而不是整个哈希表。这样可以减小扩容的开销和影响。
总的来说,ConcurrentHashMap通过分段锁和一些优化措施,实现了高效的线程安全哈希表。它适用于多线程环境下的高并发操作,能够提供较好的性能和可靠性。

集合学习
list单列集合,map双列集合
list系列集合:有序,可重复,又索引
set系列集合:无序,不重复,无索引
数据结构
*长什么样子
*怎么添加数据
*怎么删除数据
常见结构
1,栈:后进先出,先进后出
2,队列:先进先出,后进后出
3,数组:(查询快,增删慢)
*查询速度快,根据地址和索引,快速点位,(内存是连续的)
*增删慢:从新排序
4,链表(查询慢,增删快)
*链表中节点是一个独立的对象,在内存不连续,每个节点包含数据和下一个节点的地址-单向
*无论查询哪个数据都要从 头开始
*添加和删除 - 只要断开链表重写前后地址就好
双向链表(每个节点包含数据和下一个节点的地址,前一个地址)-(可以两边查找,可以提高查找效率,例如查询第几个时,先判断从头还是尾,比较近)
5,树,节点()
二叉树:最多两个节点,没有什么规则
二叉查找树:最多两个节点,左小右大,一样的不存(set的不重复)
内容包含:(父左右节点地址,和值)没有就null
1前序遍历:当前-左-右
2中序遍历:左-当前-右(从左到右,就是从小到大)
3后续遍历:左-右-当前
4层序遍历:一层层
弊端:不平衡,树太高查询慢
平衡二叉树:任意节点左右高度查不超过1
旋转机制:(左旋,右旋,触发:当添加节点后,不是一颗平衡二叉树就旋)
左旋:1从添加的节点,往父节点找不平衡的节点当作支点
左左和右右 旋转一次就好(整体旋转)
左右和右左。要旋转两次(先局部旋转 ,在整体旋转)
6,红黑树
是一个自平衡二叉树,不是高度平衡,特右的红黑规则:
*根节点 必须黑色
*连个红节点不能相连
*没有值的为nil
*每个节点的简单路径上黑节点相同
添加默认元素为红(效率比黑的高)
增删查改效率都很高
ArrayList集合底层原理
*底层是数组结构
1,利用空参是时候 低层创建的数据长度默认为0
2,添加第一个元素的时候,底层新建一个长度为10的数组
size:(元素的个数,下次存入的位置)
3,存满的时候,会扩容原理的1.5倍(一个个添加的时候)
4,如果一次性添加多个元素,新建长度以实际为准
LinkedList集合底层原理
*底层是双向链表,查询慢。头尾操作极快
迭代器
*iterator生成一个迭代器对象,默认指向0索引
*hasNext 判断是否有元素
*next获取元素,移动指针
在使用迭代器的时候 不要并发的添加或者删除元素 否则异常
泛型
List<String>
*JDK5引用的
*统一数据类型
*把运行期问题提前到编译期
java是伪泛型,编译的时候 底层还是存object,
泛型类public class Mycalss<E>{} 所有的方法都可以使用
泛型方法 public <E> void test(E e)
泛型接口:1给出实现类型,2延续泛型
泛型不支持继承性,但数据支持继承性
通配符 可以指定类型的范围(指定某一类)
Java的集合框架中的泛型参数不能是基本类型,而只能是引用类型。这是由Java泛型的设计决策所决定的。 Java的泛型是在编译期进行类型检查的,编译器会对泛型进行类型擦除(Type Erasure),将泛型类型转换为其对应的原始类型。原始类型是指不带泛型参数的类型,如 List 、 Map 等。 基本类型(如 int 、 char 、 boolean 等)是不具备对象特性的,无法作为泛型参数使用。因此,为了实现泛型的类型安全性和一致性,Java要求泛型参数必须是引用类型。
set系列集合
无序 ,不重复,无索引
HashSet ,无序
LinkedHashset,有序
TreeSet,可排序
哈希值:*根据hashcode计算出来的int整数
*没有重写就默认用地址值计算,所有一般情况会重写hashcode和equals方法
HashSet底层原理()
*创建一个默认16的数组名字叫table,默认扩展因子为0.75(条件)-扩2倍
*根据元素hash值和数组长度计算存入位置
*存入前判断是否为null,如果是null就直接存入
*如果不是,就调用equals方法比较属性值
1,一样:不存
2,不一样:jdk8以前:老元素挂在新元素下面,jdk8后新元素直接挂在老元素后面
(要和链表的每个元素equals方法比较,相同不存)
jdk18前:数组+链表
jdk18前:数组+链表+红黑树(链表和数组的长度达到阈值触发链表转红黑树)
LinkedHashSet底层原理()
*是HashSet的子类
*多加了:在每个元素额外多了一个双向链表机制,记录存储顺序
TreeSet底层原理
*可排序(默认从小到大)
*底层是红黑树结构实现的排序,增删查改性能较好
排序:
1,int ,double,默认从小到大
2,字符按照ASCII码表的数字排序
3,多字符,依次按照每一个字母比较 不看长度
4,对象:
4.1默认排序(自然排序)比较的java对象实现comparable,重写compareTo方法
4.2比较器排序 (结果负数小,正数大,0不存)(可以lambad)(优先级高)
TreeSet<String> set = new TreeSet<>(new MyComparator());
双列集合Map
hashMap
*是map的实现类
*特点都是由键值决定的 :无序,不重复,无索引
*底层根hashSet 一模一样
LikedhashMap
*底层和Likedhashset一模一样,多了双向链表
*有序
TreeMap
*底层和Treeset一模一样,
*可排序