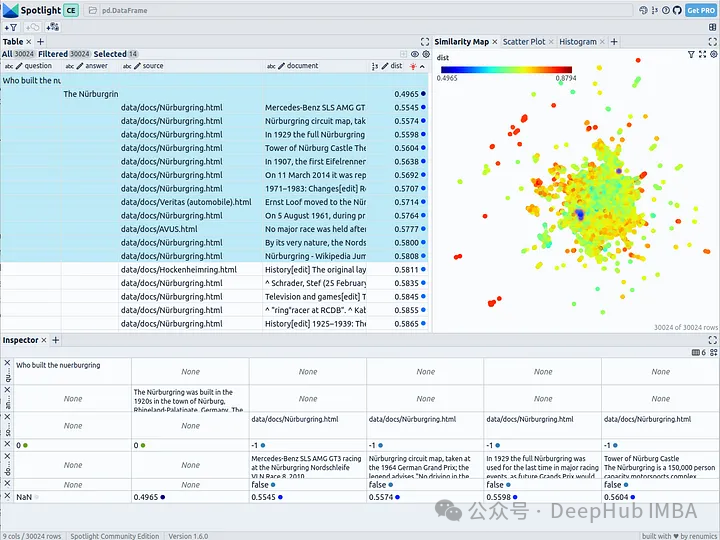
最近关于大型语言模型的奇迹()已经说了很多LLMs。这些荣誉大多是当之无愧的。让 ChatGPT 描述广义相对论,你会得到一个非常好(且准确)的答案。然而,归根结底,ChatGPT 仍然是一个盲目执行其指令集的计算机程序(和所有其他LLMs程序一样)。它对广义相对论的理解并不比你最喜欢的宠物好。不幸的是,我们使用“类似人类”的词来描述工程师用来创建它们的技术——例如,“机器学习”和“训练”。这是误导性的,因为一个人LLM没有像人类那样的思想。
最近关于大型语言模型的奇迹()已经说了很多LLMs。这些荣誉大多是当之无愧的。让 ChatGPT 描述广义相对论,你会得到一个非常好(且准确)的答案。然而,归根结底,ChatGPT 仍然是一个盲目执行其指令集的计算机程序(和所有其他LLMs程序一样)。它对广义相对论的理解并不比你最喜欢的宠物好。不幸的是,我们使用“类似人类”的词来描述工程师用来创建它们的技术——例如,“机器学习”和“训练”。这是误导性的,因为一个人LLM没有像人类那样的思想。
这里有一定的讽刺意味——一个不思考的聊天机器人怎么能正确地总结有史以来最聪明的人的发现?为了理解 LLMs的这种矛盾性质,让我们从优势、劣势和危险的角度进一步探索它们,看看我们如何利用数据和像 MinIO 这样的存储解决方案来利用前者并缓解其他两个。这些是每个工程师在为组织进行培训、测试和部署LLMs时都应该牢记的技术。
优势
其LLMs优势在于,他们经过训练,可以理解用于创建单词的训练集中单词的概率分布。如果训练集足够大(即维基百科文章的语料库或GitHub上的公共代码),那么模型将具有词汇表和相应的概率分布,这将使它们的结果看起来好像它们对输出的文本具有真实世界的理解。让我们更详细地研究另一个例子——这次来自哲学。问 ChatGPT 一个问题,“'cogito, ergo sum' 是什么意思,是谁写的?”,你会得到类似于下面文字的内容。
“Cogito, ergo sum”是一个拉丁哲学命题,在英语中翻译为“我思故我在”。这句话与法国哲学家、数学家和科学家勒内·笛卡尔(René Descartes)有关。笛卡尔在1637年出版的著作《论方法》中表达了这一观点。这句话反映了笛卡尔试图建立一个不容置疑的基本真理——一个人作为一个有思想的存在者的确定性。
LLMs使用概率分布产生这样的结果。它的工作原理是这样的,他们首先查看问题中的文本,并确定“Cogito”这个词最有可能成为答案的第一个单词。从那里,他们查看问题和答案的第一个单词,以确定最有可能成为下一个单词的单词。这种情况一直持续到一个特殊的“答案结束”字符被确定为具有最高概率。
这种基于数十亿个概率生成自然语言响应的能力并不可怕,相反,它应该被利用来创造商业价值。当您使用现代技术时,结果会变得更好。例如,使用检索增强生成 (RAG) 和微调等技术,您可以了解LLM您的特定业务。实现这些类似人类的结果将需要数据,而您的基础设施将需要强大的数据存储解决方案。
这些下一个代币预测功能不仅可用于为您的聊天机器人或营销文案生成出色的文本,而且还可用于在您的应用程序中实现自动决策。给定包含问题陈述和可调用的 API(“函数”)信息的巧妙构造的提示,对语言的理解将使其能够生成一个答案,LLM解释应该调用什么“函数”。例如,在对话式天气应用程序上,用户可能会问:“如果我今晚要去芬威球场,我需要一件雨衣吗?通过一些巧妙的提示,可以从LLM查询(马萨诸塞州波士顿)中提取位置数据,并可以确定如何制定对 Weather.com Precipitation API的请求。
在很长一段时间里,构建软件最困难的部分是自然语言和语法系统(如API调用)之间的接口。现在,具有讽刺意味的是,这可能是最简单的部分之一。与文本生成类似,LLM函数调用行为的质量和可靠性可以通过使用微调和强化学习与人类反馈 (RLHF) 来辅助。
现在我们了解了什么是LLMs擅长的,为什么,让我们来研究一下什么LLMs不能做。
弱点
LLMs不能思考、理解或推理。这是 的根本限制LLMs。语言模型缺乏对用户问题进行推理的能力。它们是概率机器,可以对用户的问题产生非常好的猜测。无论猜测有多好,它仍然是一个猜测,无论产生这些猜测什么,最终都会产生一些不真实的东西。在生成式人工智能中,这被称为“幻觉”。
如果训练得当,幻觉可以保持在最低限度。微调和 RAG 也大大减少了幻觉。底线 - 要正确训练模型,对其进行微调并为其提供相关上下文 (RAG),需要数据和基础设施来大规模存储它并以高性能的方式提供它。
让我们再看一个方面LLMs,我将其归类为危险,因为它会影响我们测试它们的能力。
危险
最流行的用途LLMs是生成式 AI。生成式 AI 不会产生可以与已知结果进行比较的特定答案。这与其他 AI 用例形成鲜明对比,后者做出的特定预测可以轻松测试。测试模型的图像检测、分类和回归非常简单。但是,如何以公正、忠实于事实和可扩展的方式测试LLMs用于生成式 AI 的用途?如果您自己不是专家,您如何确定生成的复杂答案LLMs是正确的?即使您是专家,人工审阅者也不能参与 CI/CD 管道中发生的自动化测试。
业内有一些基准可以提供帮助。GLUE(General Language Understanding Evaluation,通用语言理解评估)用于评估和衡量 LLMs.它由一组任务组成,用于评估模型处理人类语言的能力。SuperGLUE 是 GLUE 基准测试的扩展,它引入了更具挑战性的语言任务。这些任务涉及共指解析、问答和更复杂的语言现象。
虽然上面的基准很有帮助,但解决方案的很大一部分应该是你自己的数据收集。请考虑记录所有问题和答案,并根据自定义结果创建自己的测试。这还需要一个能够扩展和执行的数据基础设施。
你有它。的优点、缺点和危险LLMs。如果您想利用第一个问题并缓解其他两个问题,那么您将需要数据和可以处理大量数据的存储解决方案。