博主猫头虎的技术世界
🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能!
专栏链接:
🔗 精选专栏:
- 《面试题大全》 — 面试准备的宝典!
- 《IDEA开发秘籍》 — 提升你的IDEA技能!
- 《100天精通鸿蒙》 — 从Web/安卓到鸿蒙大师!
- 《100天精通Golang(基础入门篇)》 — 踏入Go语言世界的第一步!
- 《100天精通Go语言(精品VIP版)》 — 踏入Go语言世界的第二步!
领域矩阵:
🌐 猫头虎技术领域矩阵:
深入探索各技术领域,发现知识的交汇点。了解更多,请访问:
- 猫头虎技术矩阵
- 新矩阵备用链接

文章目录
- 摘要
- 引言
- 正文
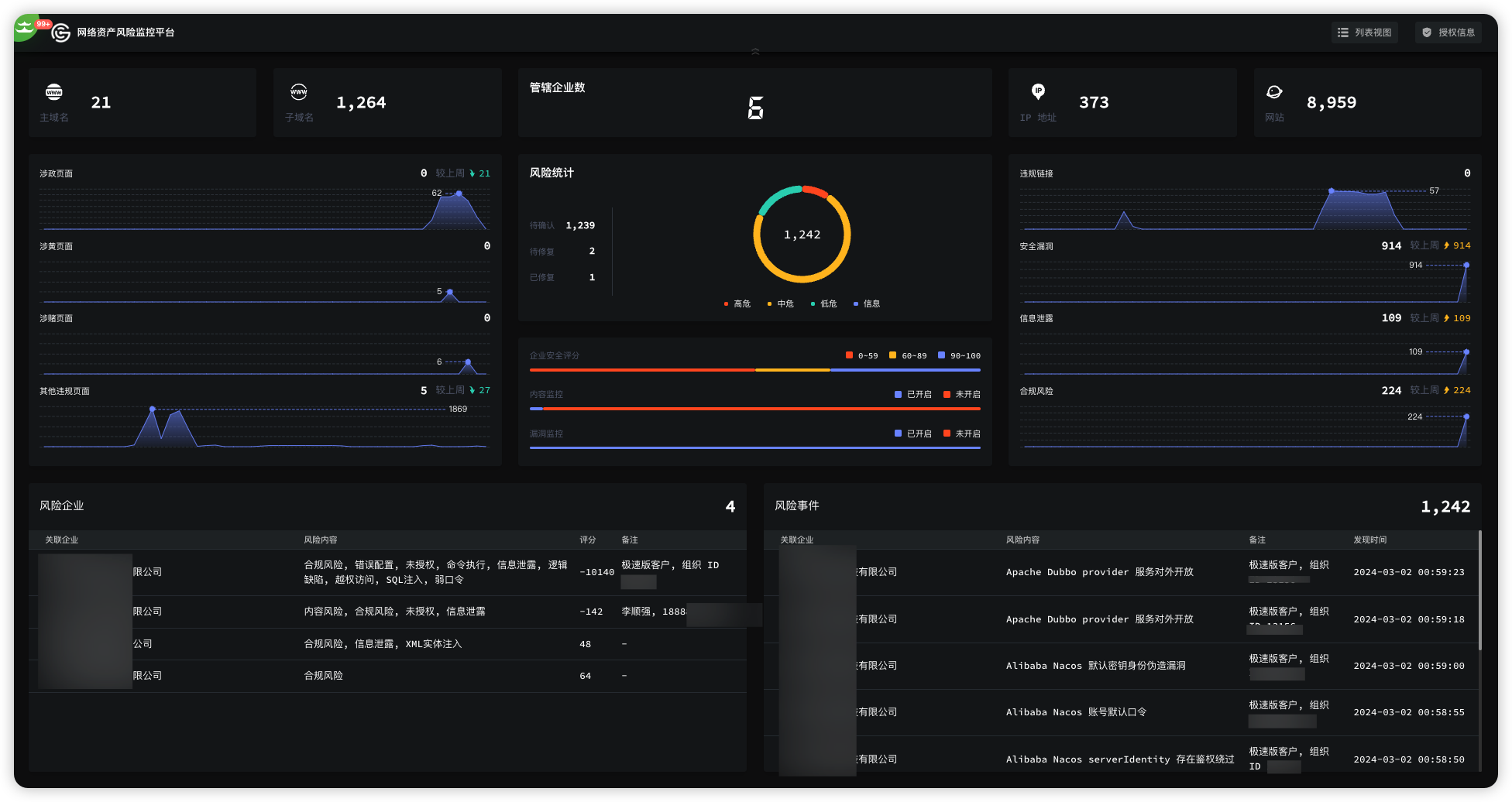
- IP代理与爬虫技术专栏介绍及技术概括
- IP代理(IP Proxy)
- 爬虫技术(Web Crawling Technology)
- 反爬虫技术(Anti-Scraping Techniques)
- 数据解析(Data Parsing)
- API抓取(API Scraping)
- 分布式爬虫(Distributed Crawling)
- 网络安全与隐私(Cybersecurity and Privacy)
- 机器学习在爬虫中的应用(Machine Learning in Web Scraping)
- 云代理服务(Cloud Proxy Services)
- JavaScript渲染(JavaScript Rendering)
- 未来展望
- 总结
摘要
本篇技术博客深入探讨了IP代理与爬虫技术的核心概念、应用策略及其在网络数据抓取和隐私保护领域的重要性。通过详细介绍IP代理的不同类型、爬虫技术的设计与实现、反爬虫策略、数据解析技巧、API抓取方法、分布式爬虫架构、网络安全与隐私保护措施、以及机器学习和JavaScript渲染在爬虫中的应用,本文旨在为读者提供一个全面的知识框架,从而帮助他们更好地理解和应用这些技术以解决实际问题。
引言
嗨,大家好,我是猫头虎博主,一个对技术充满无限热情的探索者。今天,我要带大家深入了解一个既神秘又充满挑战的世界——IP代理与爬虫技术。在这个信息爆炸的时代,如何有效地获取、处理和保护网络数据成为了一个重要议题。无论你是数据科学家、网络安全专家,还是仅仅是技术爱好者,我相信这篇博客都能为你开启一扇通往知识深渊的大门。让我们一起探索这些看似复杂但充满魅力的技术,解锁网络世界的无限可能。
正文

IP代理与爬虫技术专栏介绍及技术概括
欢迎来到IP代理与爬虫技术专栏,一个专注于最前沿网络技术、隐私保护及数据抓取技术的深度解析平台。本专栏旨在为技术爱好者、研究人员和开发者提供一系列深入浅出的技术文章,涵盖从IP代理到高级网络爬虫技术的全方位知识。接下来,让我们一起探索这个专栏的核心内容。
IP代理(IP Proxy)
IP代理技术是网络隐私和匿名性的基石。通过介绍透明代理、匿名代理、混淆代理和高匿名代理,本专栏揭示了如何有效使用IP代理绕过地理限制、增强网络安全,并保护个人隐私。
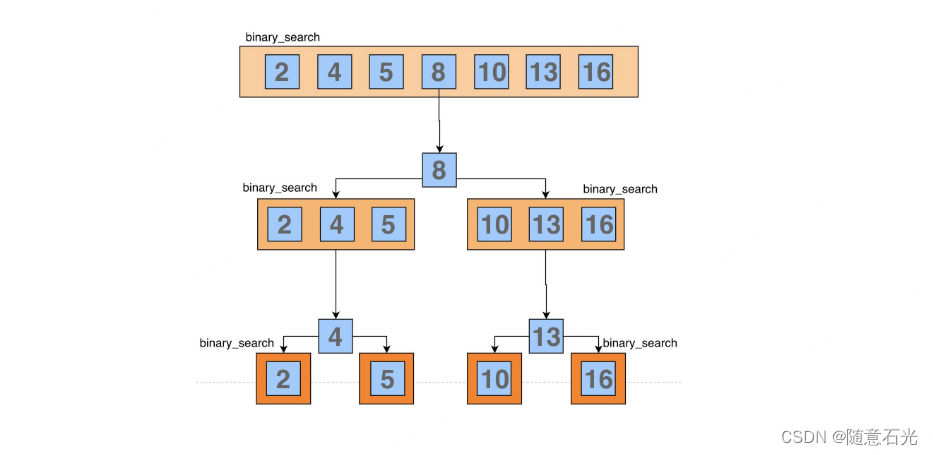
爬虫技术(Web Crawling Technology)
网络爬虫是互联网数据抓取的工作马,本栏目深入讨论了爬虫的设计原理,如何遵守robots.txt协议,以及爬虫在搜索引擎优化和数据挖掘中的应用。通过学习反爬虫技术和数据解析,读者可以掌握构建高效、遵守道德规范的爬虫系统的技能。
反爬虫技术(Anti-Scraping Techniques)
本专栏也着重介绍了网站如何通过各种技术防止数据被非法抓取,如动态页面、IP封锁和验证码,为开发者提供了设计出能够应对这些挑战的高效爬虫的策略。
数据解析(Data Parsing)
数据解析是从抓取的数据中提取有用信息的关键步骤。专栏通过介绍正则表达式、HTML/XML解析器等工具,帮助读者理解如何处理和分析网络数据。
API抓取(API Scraping)
利用公开API接口抓取数据是现代网络爬虫的另一种形式。本专栏探讨了如何合法有效地使用API,包括处理API限制和认证的策略。
分布式爬虫(Distributed Crawling)
对于大规模数据抓取项目,分布式爬虫技术是关键。本栏目详细介绍了构建分布式系统的方法,包括使用消息队列和多线程/多进程技术,以实现高效的数据抓取。
网络安全与隐私(Cybersecurity and Privacy)
在进行网络爬虫和IP代理活动时,确保合法性和道德性至关重要。本专栏提供了关于如何遵守数据保护法规和最佳实践的深入分析。
机器学习在爬虫中的应用(Machine Learning in Web Scraping)
机器学习技术可以显著提升爬虫的智能化水平。通过自动识别和解析网页结构,机器学习使数据抓取过程更加高效和准确。
云代理服务(Cloud Proxy Services)
云代理服务为爬虫提供了更高层次的匿名性和能力,以访问受限资源。本专栏评估了不同云代理服务的优劣,为读者选择合适的服务提供指导。
JavaScript渲染(JavaScript Rendering)
处理动态生成的内容是现代爬虫技术的一大挑战。本栏目探讨了如何使用无头浏览器等技术有效解析JavaScript生成的内容。
通过这些名词,本专栏旨在建立一个全面的知识体系,不仅支持技术专家的深入研究,也使初学者能够迅速掌握IP代理与爬虫技术的关键概念。欢迎加入我们,一起探索数字世界的无限可能。

未来展望
随着技术的不断进步,IP代理和爬虫技术也将迎来新的发展机遇和挑战。人工智能和机器学习的进一步融合预计将使爬虫技术更加智能化,能够更准确地识别和解析网页数据。同时,随着网络安全威胁的不断演化,如何在保护用户隐私和数据安全的前提下高效利用这些技术,将成为未来研究的重点。此外,随着云计算和边缘计算的发展,分布式爬虫技术将变得更加灵活和强大,能够更好地应对大规模数据抓取需求。未来,我们还将见证更多创新的应用场景,如深度网络数据分析、实时数据监控等,为各行各业带来革命性的变化。
总结
通过本篇博客的介绍,我们深入探讨了IP代理与爬虫技术的关键概念和应用策略。从IP代理的基本知识到复杂的爬虫技术实现,从反爬虫策略到数据解析技巧,再到网络安全和机器学习在爬虫中的应用,我们尝试构建了一个全面的知识体系,旨在帮助读者更好地理解和应用这些技术。作为猫头虎博主,我相信,通过不断学习和探索,我们能够更好地应对技术挑战,发掘数据的无限价值。让我们携手前进,共同探索数字世界的奥秘,解锁更多可能。

👉 更多信息:有任何疑问或者需要进一步探讨的内容,欢迎点击下方文末名片获取更多信息。我是猫头虎博主,期待与您的交流! 🦉💬
🚀 技术栈推荐:
GoLang, Git, Docker, Kubernetes, CI/CD, Testing, SQL/NoSQL, gRPC, Cloud, Prometheus, ELK Stack
💡 联系与版权声明:
📩 联系方式:
- 微信: Libin9iOak
- 公众号: 猫头虎技术团队
⚠️ 版权声明:
本文为原创文章,版权归作者所有。未经许可,禁止转载。更多内容请访问猫头虎的博客首页。
点击
下方名片,加入猫头虎领域社群矩阵。一起探索科技的未来,共同成长。