Java生成 word报告
- 一、方案比较
- 二、Apache POI 生成
- 三、FreeMarker 生成
在网上找了好多天将数据库信息导出到 word 中的解决方案,现在将这几天的总结分享一下。总的来说,Java 导出 word 大致有 5 种。
一、方案比较
1. Jacob
Jacob 是 Java-COM Bridge 的缩写,它在 Java 与微软的 COM 组件之间构建一座桥梁。通过 Jacob 实现了在 Java 平台上对微软 Office 的 COM 接口进行调用。
优点:调用微软 Office 的 COM 接口,生成的 word 文件格式规范。
缺点:服务器只能是 windows 平台,不支持 unix 和 linux,且服务器上必须安装微软 Office。
2. Apache POI
Apache POI 包括一系列的 API,它们可以操作基于 MicroSoft OLE 2 Compound Document Format的各种格式文件,可以通过这些API在Java中读写Excel、Word等文件。
优点:跨平台支持 windows、unix 和 linux。
缺点:相对与 word 文件的处理来说,POI 更适合 excel 处理,对于 word 实现一些简单文件的操作凑合,不能设置样式且生成的 word 文件格式不够规范。
3. Java2word
Java2word 是一个在 Java 程序中调用 MS Office Word 文档的组件(类库)。该组件提供了一组简单的接口,以便 Java 程序调用它的服务操作 word 文档。这些服务包括:打开文档、新建文档、查找文字、替换文字、插入文字、插入图片、插入表格,在书签处插入文字、插入图片、插入表格等。
优点:足够简单,操作起来要比 FreeMarker 简单的多。
缺点:没有 FreeMarker 强大,不能根据模板生成 word 文档,word 文档的样式等信息都不能够很好的操作。
4. FreeMarker
FreeMarker 生成 word 文档的功能是由 XML + FreeMarker 来实现的。先把 word 文件另存为 xml,在 xml 文件中插入特殊字符串占位符,将 xml 翻译为 FreeMarker 模板,最后用 Java 来解析 FreeMarker 模板,编码调用 FreeMarker 实现文本替换并输出 doc。
优点:比 Java2word 功能强大,也是纯 Java 编程。
缺点:生成的文件本质上是 xml,不是真正的 word 文件格式,有很多常用的 word 格式无法处理或表现怪异,比如:超链接、换行、乱码、部分生成的文件打不开等。
5. PageOffice
PageOffice 生成 word 文件。PageOffice 封装了微软 Office 繁琐的 vba 接口,提供了简洁易用的 Java 编程对象,支持生成 word 文件,同时实现了在线编辑 word 文档和读取 word 文档内容。
优点:跨平台支持 windows、unix 和 linux,生成 word 文件格式标准,支持文本、图片、表格、字体、段落、颜色、超链接、页眉等各种格式的操作,支持多 word 合并,无需处理并发,不耗费服务器资源,运行稳定。
缺点:必须在客户端生成文件(可以不显示界面),不支持纯服务器端生成文件
二、Apache POI 生成
| 基本概念 | |
|---|---|
| XWPFDocument | 代表一个 docx 文档 |
| XWPFParagraph | 代表文档、表格、标题等各种的段落,由多个XWPFRun组成 |
| XWPFRun | 代表具有同样风格的一段文本 |
| XWPFTable | 代表一个表格 |
| XWPFTableRow | 代表表格的一行 |
| XWPFTableCell | 代表表格的一个单元格 |
| XWPFChar | 表示.docx文件中的图表 |
| XWPFHyperlink | 表示超链接 |
| XWPFPicture | 代表图片 |
| XWPFComment | 代表批注 |
| XWPFFooter | 代表页脚 |
| XWPFHeader | 代表页眉 |
| XWPFStyles | 样式(设置多级标题的时候用) |
- 依赖:
<!--操作excel / docx合并-->
<dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>4.1.2</version>
</dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>4.1.2</version>
</dependency>
- 正文段落
一个文档包含多个段落,一个段落包含多个 Runs,一个 Runs 包含多个 Run,Run 是文档的最小单元
获取所有段落:List paragraphs = word.getParagraphs();
获取一个段落中的所有 Runs:List xwpfRuns = xwpfParagraph.getRuns();
获取一个 Runs 中的一个 Run:XWPFRun run = xwpfRuns.get( index );
XWPFRun 代表具有相同属性的一段文字
- 正文表格
一个文档包含多个表格,一个表格包含多行,一行包含多列(格),每一格的内容相当于一个完整的文档
获取所有表格:List xwpfTables = doc.getTable();
获取一个表格的行数:int rcount = xwpfTable.getNumberOfRows();
获取一个表格的第几行:XWPFTableRow row = table.getRow( i );
获取一个表格中的所有行:List xwpfTableRows = xwpfTable.getRows();
获取一行中的所有列:List xwpfTableCells = xwpfTableRow.getTableCells();
获取一格里的内容:List paragraphs = xwpfTableCell.getParagraphs();
注:
- 表格的一格相当于一个完整的 docx 文档,只是没有页眉和页脚。里面可以有表格,使用 xwpfTableCell.getTable() 获取等等
- 在 POI 文档中段落和表格是完全分开的,如果在两个段落中有一个表格,在 POI 中是没办法确定表格在段落中间的。只有文档的格式固定,才能正确的得到文档的结构。
- 页眉
一个文档可以有多个页眉,页眉里面可以包含段落和表格
获取文档的页眉:List headerList = doc.getHeaderList();
获取页眉里面的所有段落:List paras = header.getParagraphs();
获取页眉里的所有表格:List tables = header.getTables();
- 页脚
页脚和页眉基本类似,可以获取表示页数的角标
- 参考
(1) POI 创建 word 文档简单示例
XWPFDocument doc = new XWPFDocument();// 创建Word文件
XWPFParagraph p = doc.createParagraph();// 新建一个段落
p.setAlignment(ParagraphAlignment.CENTER);// 设置段落的对齐方式
p.setBorderBottom(Borders.DOUBLE);// 设置下边框
p.setBorderTop(Borders.DOUBLE);// 设置上边框
p.setBorderRight(Borders.DOUBLE);// 设置右边框
p.setBorderLeft(Borders.DOUBLE);// 设置左边框
XWPFRun r = p.createRun();// 创建段落文本
r.setText("POI创建的Word段落文本");
r.setBold(true);// 设置为粗体
r.setColor("FF0000");// 设置颜色
p = doc.createParagraph();// 新建一个段落
r = p.createRun();
r.setText("POI读写Excel功能强大、操作简单。");
XWPFTable table= doc.createTable(3, 3);// 创建一个表格
table.getRow(0).getCell(0).setText("表格1");
table.getRow(1).getCell(1).setText("表格2");
table.getRow(2).getCell(2).setText("表格3");
FileOutputStream out = new FileOutputStream("d:\\POI\\sample.doc");
doc.write(out);
out.close();

(2) POI 读取 word 文档里的文字
FileInputStream stream = new FileInputStream("d:\\POI\\sample.doc");
XWPFDocument doc = new XWPFDocument(stream); //创建Word文件
for(XWPFParagraph p : doc.getParagraphs()){ //遍历段落System.out.print(p.getParagraphText());
}
for(XWPFTable table : doc.getTables()){ //遍历表格for(XWPFTableRow row : table.getRows()){for(XWPFTableCell cell : row.getTableCells()){System.out.print(cell.getText());}}
}
(3) 代码示例
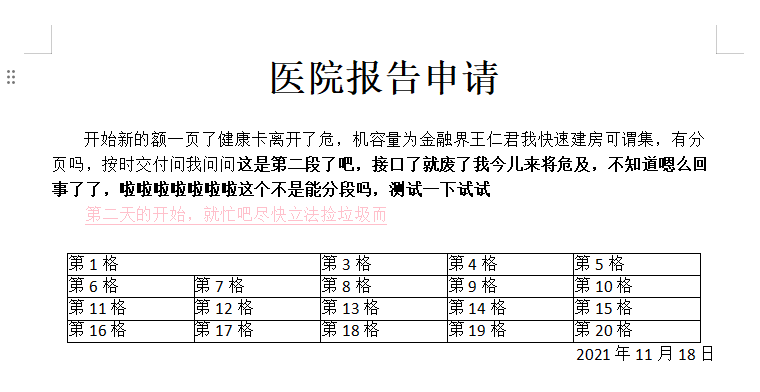
该代码示例只是一个 demo,简单生成了一个 word 文件,包括 word 文档常规的一些样式设置:文件字体、首行缩进、文字大小、段落对齐方式、换行。还有常见的表格创建,以及表格合并效果等。
代码:
public void createFile(HttpServletRequest request, HttpServletResponse response) throws IOException {//创建文本对象XWPFDocument docxDocument = new XWPFDocument();//创建第一段落XWPFParagraph firstParagraphX = docxDocument.createParagraph();firstParagraphX.setAlignment(ParagraphAlignment.CENTER);XWPFRun runTitle = firstParagraphX.createRun();runTitle.setText("医院报告申请"); //标题runTitle.setBold(true); //加粗runTitle.setFontSize(24); //文字大小runTitle.setFontFamily("宋体"); //字体runTitle.addCarriageReturn(); //回车键runTitle.setKerning(30); //字间距XWPFParagraph paragraphX = docxDocument.createParagraph();paragraphX.setAlignment(ParagraphAlignment.LEFT); //对齐方式paragraphX.setFirstLineIndent(400); //首行缩进//创建段落中的runXWPFRun run = paragraphX.createRun();run.setText("开始新的额一页了健康卡离开了危,机容量为金融界王仁君我快速建房可谓集,有分页吗,按时交付问我问问");//run.addCarriageReturn();//回车键XWPFRun run2 = paragraphX.createRun();run2.setText("这是第二段了吧,接口了就废了我今儿来将危及,不知道嗯么回事了了,啦啦啦啦啦啦啦");run2.setText("这个不是能分段吗,测试一下试试");run2.setBold(true);//加粗//创建第二段落XWPFParagraph paragraphX2 = docxDocument.createParagraph();paragraphX2.setIndentationFirstLine(420); //首行缩进XWPFRun secondRun = paragraphX2.createRun();secondRun.setText("第二天的开始,就忙吧尽快立法捡垃圾而");secondRun.setColor("FFC0CB");secondRun.setUnderline(UnderlinePatterns.SINGLE);secondRun.addCarriageReturn();//创建表格 4行*5列(创建table 时,会有一个默认一行一列的表格)XWPFTable table = docxDocument.createTable(4,5);table.setWidth("95%");table.setWidthType(TableWidthType.PCT); //设置表格相对宽度table.setTableAlignment(TableRowAlign.CENTER); //居中对齐//合并单元格XWPFTableRow row1 = table.getRow(0); //第一行XWPFTableCell cell1 = row1.getCell(0); //第一行的第一列CTTcPr cellCtPr = getCellCTTcPr(cell1);cellCtPr.addNewHMerge().setVal(STMerge.RESTART);XWPFTableCell cell2 = row1.getCell(1); //第一行的第二列CTTcPr cellCtPr2 = getCellCTTcPr(cell2);cellCtPr2.addNewHMerge().setVal(STMerge.CONTINUE);//给表格填充文本setTableText(docxDocument);XWPFParagraph endParagraphX = docxDocument.createParagraph();endParagraphX.setAlignment(ParagraphAlignment.RIGHT);XWPFRun endRun = endParagraphX.createRun();endRun.setText("2021年11月18日");String path="D://POI//docBoke.docx";File file = new File(path);FileOutputStream stream = new FileOutputStream(file);docxDocument.write(stream);stream.close();System.out.println("文件生成完成!");
}private void setTableText(XWPFDocument docxDocument) {//获取第一个表格XWPFTable table = docxDocument.getTableArray(0);List<XWPFTableRow> rows = table.getRows();int i=1;for(XWPFTableRow row :rows){List<XWPFTableCell> cells = row.getTableCells();for(XWPFTableCell cell: cells){cell.setText("第"+String.valueOf(i++)+"格");cell.setVerticalAlignment(XWPFTableCell.XWPFVertAlign.CENTER); //中心垂直对齐//cell.setWidthType(TableWidthType.PCT);//cell.setWidth("30%");}}
}public static CTTcPr getCellCTTcPr(XWPFTableCell cell) {CTTc cttc = cell.getCTTc();CTTcPr tcPr = cttc.isSetTcPr() ? cttc.getTcPr() : cttc.addNewTcPr();return tcPr;
}
运行之后,就会在指定目录下生成名为 “ docBoke.docx ” 的 word 报告文件
三、FreeMarker 生成
FreeMarker 是一个基于 Java 的模板引擎,最初专注于使用 MVC 软件架构生成动态网页。但是,它是一个通用的模板引擎,不依赖于 servlets 或 HTTP 或 HTML,因此它通常还用于生成源代码,配置文件或电子邮件。
此时,我们用它动态生成的 xml 文件,进而导出 word 文档。
- 流程图

- 模板制作
先用 word 做一个模板,如下图:

(注意,上面是有表格的,我设置了边框不可见)然后另存为 xml 文件,之后用工具打开这个 xml 文件,有人用 firstobject xml editor 感觉还不如 notePad++ ,我这里用 notePad++,主要是有高亮显示,和元素自动配对,效果如下:

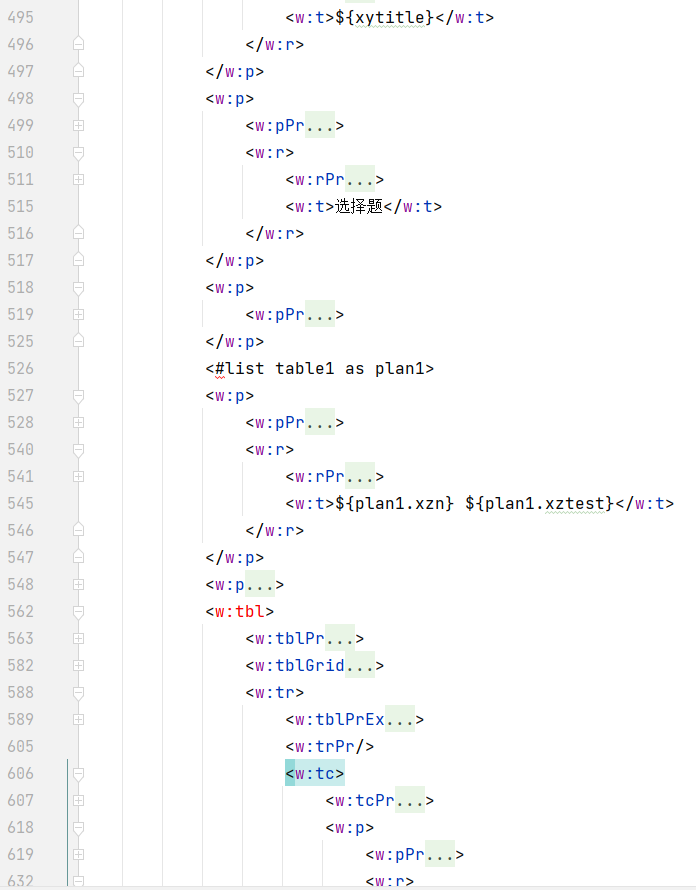
上面黑色的地方基本是我们之后要替换的地方,比如xytitle替换为${xytitle},对于表格要十分注意,比如选择题下面的表格,我们可以通过<w:tr>查找来定位,一对<w:tr></w:tr>代表一行,也就是一条记录(一道题),我们这里要用一对<#list></#list>来降其包括,以便后续填充数据,具体可以参照FreeMarker页面语法。
例如这里选择题,我们是两行为一条记录,所以要<#list></#list>包括两行,形如:
<#list table as plan1><w:tr>题号 题目</w:tr><w:tr>选项</w:tr></#list>,
然后在这其中找到对应的xzn,xztest,ans1,ans2,ans3,ans4替换为${plan1.xzn},${plan1.xztest},${plan1.ans1},${plan1.ans2},${plan1.ans3},${plan1.ans4},注意这里的table1及plan1命名,table1后续填充数据要用到,其他的替换同理操作,
将 xml 文件格式化:在线格式化

全部参数预设完成后保存,修改后缀名为ftl,至此模板制作完毕。
- 代码实现
依赖:
<!-- freemarker 用于动态写入word文档 -->
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.9</version>
</dependency>
代码:
public class DocumentHandler {private Configuration configuration = null;public DocumentHandler() {configuration = new Configuration();configuration.setDefaultEncoding("utf-8");}/** 转换成word*/public void createDoc(Map<String,Object> dataMap, String fileName) throws UnsupportedEncodingException {//dataMap 要填入模本的数据文件//设置模本装置方法和路径,FreeMarker支持多种模板装载方法。可以重servlet,classpath,数据库装载,//这里我们的模板是放在template包下面configuration.setClassForTemplateLoading(this.getClass(), "/templates");Template t=null;try {//.ftl文件为要装载的模板t = configuration.getTemplate("document.ftl");} catch (IOException e) {e.printStackTrace();}//输出文档路径及名称File outFile = new File(fileName);Writer out = null;FileOutputStream fos=null;try {fos = new FileOutputStream(outFile);OutputStreamWriter oWriter = new OutputStreamWriter(fos,"UTF-8");//这个地方对流的编码不可或缺,使用main()单独调用时,应该可以,但是如果是web请求导出时导出后word文档就会打不开,并且包XML文件错误。主要是编码格式不正确,无法解析。//out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"UTF-8"));out = new BufferedWriter(oWriter);} catch (FileNotFoundException e1) {e1.printStackTrace();}try {//将数据填入模板文件,并输出到目标地址t.process(dataMap, out);out.close();fos.close();} catch (TemplateException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}//System.out.println("---------------------------");}
}
public static void main(String[] args) throws UnsupportedEncodingException {Map<String, Object> dataMap = new HashMap<String, Object>();dataMap.put("xytitle", "试卷");int index = 1;// 选择题List<Map<String, Object>> list1 = new ArrayList<Map<String, Object>>();//题目List<Map<String, Object>> list11 = new ArrayList<Map<String, Object>>();//答案index = 1;for (int i = 0; i < 3; i++) {Map<String, Object> map = new HashMap<String, Object>();map.put("xzn", index + ".");map.put("xztest","( )操作系统允许在一台主机上同时连接多台终端,多个用户可以通过各自的终端同时交互地使用计算机。");map.put("ans1", "A" + index);map.put("ans2", "B" + index);map.put("ans3", "C" + index);map.put("ans4", "D" + index);list1.add(map);Map<String, Object> map1 = new HashMap<String, Object>();map1.put("fuck", index + ".");map1.put("abc", "A" + index);list11.add(map1);index++;}dataMap.put("table1", list1);dataMap.put("table11", list11);// 填空题List<Map<String, Object>> list2 = new ArrayList<Map<String, Object>>();List<Map<String, Object>> list12 = new ArrayList<Map<String, Object>>();index = 1;for (int i = 0; i < 2; i++) {Map<String, Object> map = new HashMap<String, Object>();map.put("tkn", index + ".");map.put("tktest","操作系统是计算机系统中的一个___系统软件_______,它管理和控制计算机系统中的___资源_________.");list2.add(map);Map<String, Object> map1 = new HashMap<String, Object>();map1.put("fill", index + ".");map1.put("def", "中级调度" + index);list12.add(map1);index++;}dataMap.put("table2", list2);dataMap.put("table12", list12);// 判断题List<Map<String, Object>> list3 = new ArrayList<Map<String, Object>>();List<Map<String, Object>> list13 = new ArrayList<Map<String, Object>>();index = 1;for (int i = 0; i < 3; i++) {Map<String, Object> map = new HashMap<String, Object>();map.put("pdn", index + ".");map.put("pdtest","复合型防火墙防火墙是内部网与外部网的隔离点,起着监视和隔绝应用层通信流的作用,同时也常结合过滤器的功能。");list3.add(map);Map<String, Object> map1 = new HashMap<String, Object>();map1.put("judge", index + ".");map1.put("hij", "对" + index);list13.add(map1);index++;}dataMap.put("table3", list3);dataMap.put("table13", list13);// 简答题List<Map<String, Object>> list4 = new ArrayList<Map<String, Object>>();List<Map<String, Object>> list14 = new ArrayList<Map<String, Object>>();index = 1;for (int i = 0; i < 2; i++) {Map<String, Object> map = new HashMap<String, Object>();map.put("jdn", index + ".");map.put("jdtest", "说明作业调度,中级调度和进程调度的区别,并分析下述问题应由哪一级调度程序负责。");list4.add(map);Map<String, Object> map1 = new HashMap<String, Object>();map1.put("answer", index + ".");map1.put("xyz", "说明作业调度,中级调度和进程调度的区别,并分析下述问题应由哪一级调度程序负责。");list14.add(map1);index++;}dataMap.put("table4", list4);dataMap.put("table14", list14);DocumentHandler mdoc = new DocumentHandler();mdoc.createDoc(dataMap, "E:/excel/考题.docx");}
- 注意上面 map 中的 key 必须和模板中的相对应,否则会报错。导出效果如下:

好事定律:每件事最后都会是好事,如果不是好事,说明还没到最后。