😀前言
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。
🏠个人主页:尘觉主页
文章目录
- 数据结构面试常见问题之串的模式匹配(KMP算法)系列-大师改进实现以及原理
- KMP-3. KMP 算法实现
- KMP算法实现
- KMP-4. BuildMatch 的实现原理
- KMP-5. BuildMatch的编程实现
- 😄总结
数据结构面试常见问题之串的模式匹配(KMP算法)系列-大师改进实现以及原理
KMP-3. KMP 算法实现
#include<stdio.h>
#include<string.h>
typedef int Position;//Position对应的是一个整型变量,指的是数组的下标
#define NotFound -1//NotFound就应该定义成一个不可能是数组下标的东西
int main()
{char string[] = "This is a simple example.";//默认指字符串,但这个串可以是任何类型的char pattern[] = "simple";Position p = KMP(string,pattern);//返回的是一个字符指针的话就只能处理字符串,如果返回的是数组下标的话那可以处理任何字符的串if (p == NotFound ) printf("Not Found.\n");else printf("%s\n",string+p);//因为这里返回的是整数,这个整数就没办法被当作字符串的头指针了。如果我们要打印整个字符串的话,我们这里就只能写成string+p这样的形式return 0;
}
KMP算法实现

一直走到指针不匹配

Position KMP(char *string, char *pattern) {int n = strlen(string);//strlen得到string的长度,下方也是一样 复杂度:O(n)int m = strlen(pattern);//复杂度:O(m)int s, p,*match;//声明两个指针if (n < m) return NotFound;//找的n不可能比m短match = (int *) malloc(sizeof(int) * m);BuildMatch(pattern, match);//Tm = O(?)s = p = 0;while (s < n && p < m) { //当这两个指针一起往前飞,任何一个指针先指到自己指的串的末尾的时候结束,复杂度O(n)if (string[s] == pattern[p]) {s++;p++;}//p有时候加加有时候回退,但s永远加加else if (p > 0) p = match[p - 1] + 1;//为了防止得到段错误,这里加上条件p>0//如果p = 0的话,意味着pattern从第一个字符就不匹配,这个时候p不动,s向前走一格else s++;//当string[s] == pattern[p]不匹配,我们s++,继续下一轮匹配}//在我们跳出while循环的时候,p指针已经碰到pattern的末尾(p==m),那就是完全的匹配上了//反之p还没有到结尾,而string已经到p的结尾了,就意味着我们找不到这个模式return (p == m) ? (s - m) : NotFound;
}
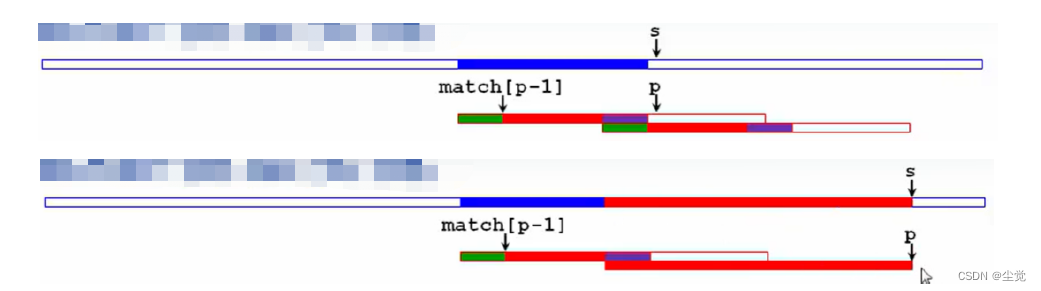
KMP的整体时间复杂度:T = O(n+m+Tm)
KMP-4. BuildMatch 的实现原理
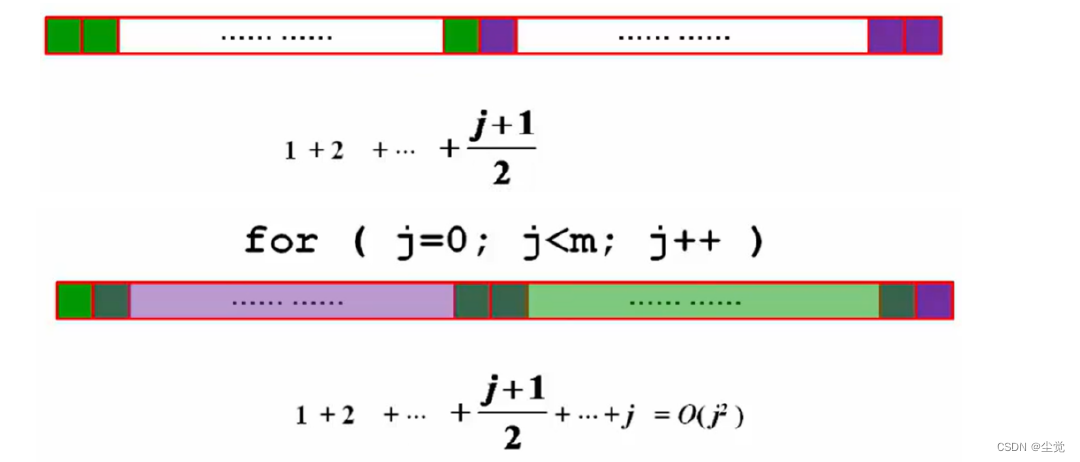
如果采用这种方法实现的话,时间复杂度将会达到Tm = O(m³)
新想法:如果我们要算j的match值的话先考虑他跟j-1的match值有什么关系
假如我们这是从0到j-1的字段
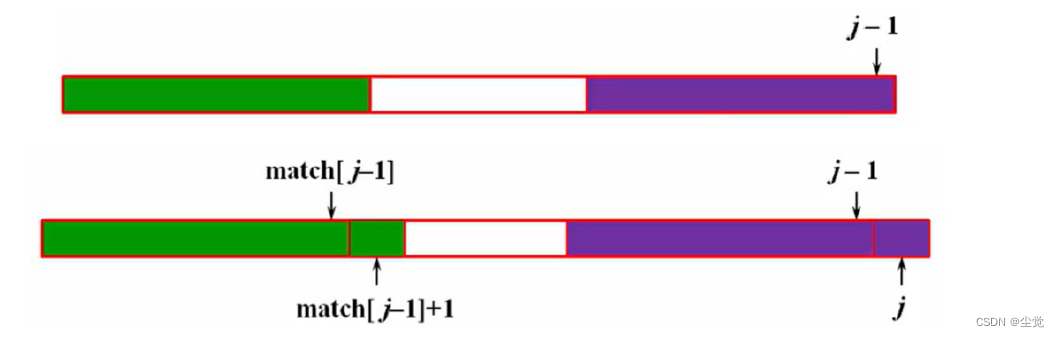
match[j] >= match[j-1] + 1(是否正确?)
如果 match[j-1]+1 这个位置上的字符与 j 位置上的字符相等,match[j] 会有可能比 match[j-1]+1 更大吗?没可能
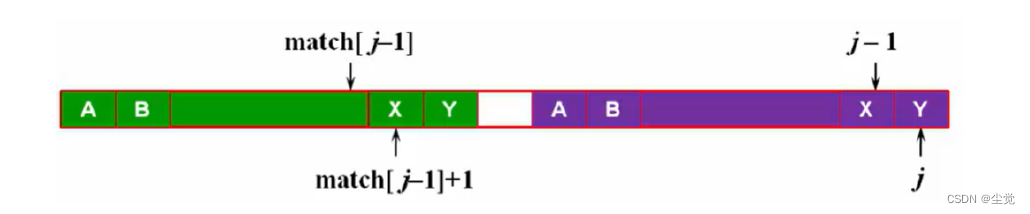
match[j] = match[j-1] + 1 (最多持平啦,利用反证法证明)
且能得到这个结果的前提是运行很好
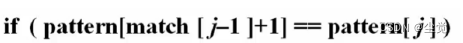
当 pattern[match[j-1]+1] != pattern[j] 时,下一个待与 pattern[j] 比较的元素下标是:match[match[j-1]]+1

KMP-5. BuildMatch的编程实现
void BuildMatch(char *pattern,int *match)
{int i,j;int m = strlen(pattern);//复杂度O(m)match[0] = -1;for(j=1;j<m;j++){//复杂度O(m)i = match[j-1];//把这个值存入i里面,后面就可以直接用i来表示,不至于显得很长很啰嗦,怎么感觉像数学的换元法啊哈哈while((i>=0) && (pattern[i+1] != pattern[j]))//每次都考虑最坏情况的话复杂度可能就为O(j)了,每次都退到底的话i = match[i];//让i做了一个回退,回退到while条件两者有其中之一不发生的时候if(pattern[i+1]==pattern[j])match[j] = i+1;//i回退总次数不会超过i增加的总次数else match[j] = -1;}
}
整个算法复杂度: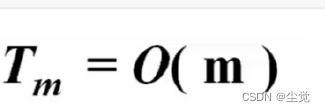
第一篇–>数据结构面试常见问题之串的模式匹配(KMP算法)系列-简单解决方案
第二篇–>数据结构面试常见问题之串的模式匹配(KMP算法)系列-大师改进
😄总结
KMP算法的核心思想是利用部分匹配表来记录模式串中每个字符之前部分匹配的最大长度。在匹配过程中,如果主串和模式串的某个字符不匹配,则可以根据部分匹配表直接跳转到模式串中下一个可能匹配的位置,从而避免重复比较。
BuildMatch函数用于计算模式串的部分匹配表。该函数的核心思想是利用前缀和后缀的匹配关系来计算部分匹配表。
KMP算法具有广泛的应用,例如文本编辑、生物信息学、数据挖掘等。
😁热门专栏推荐
想学习vue的可以看看这个
java基础合集
数据库合集
redis合集
nginx合集
linux合集
手写机制
微服务组件
spring_尘觉
springMVC
mybits
等等等还有许多优秀的合集在主页等着大家的光顾感谢大家的支持
🤔欢迎大家加入我的社区 尘觉社区
文章到这里就结束了,如果有什么疑问的地方请指出,诸佬们一起来评论区一起讨论😁
希望能和诸佬们一起努力,今后我们一起观看感谢您的阅读🍻
如果帮助到您不妨3连支持一下,创造不易您们的支持是我的动力🤞