python知识点总结十
- 1、装饰器的理解、并实现一个计时器记录执行性能,并且将执行结果写入日志文件中
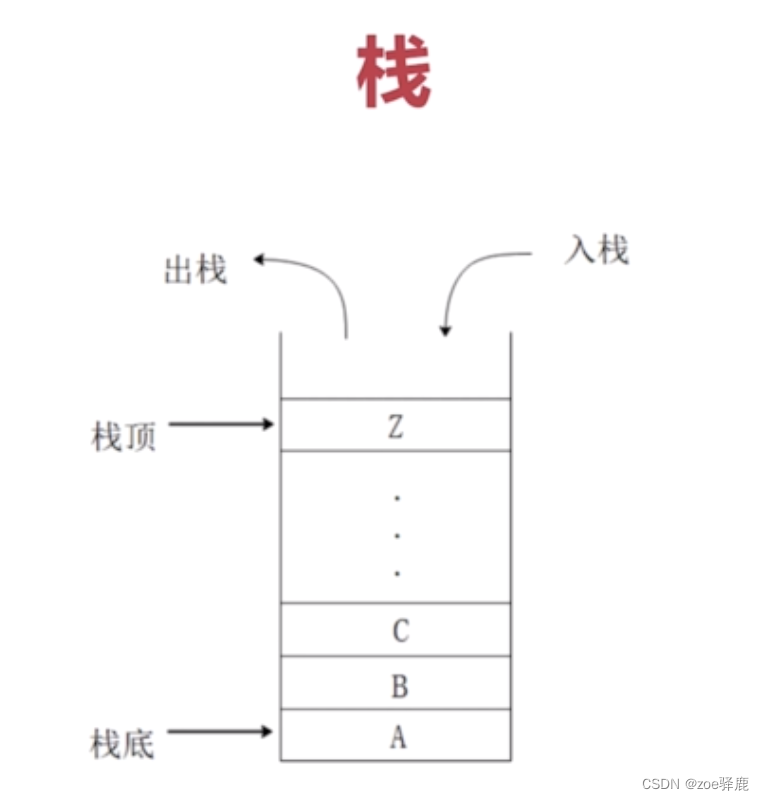
- 2、队列和栈的区别,并且用python实现
- 3、设计实现遍历目录与子目录
- 4、CPU处理进程最慢的情况通常发生在以下几种情况下:
- 5、CPU处理线程最慢的情况通常发生在以下几种情况下:
- 6、如何做到线程同步?
- 7、手写代码:对于字符串bdackmkdbb,输出第二个只出现一次的字符, 输出c
- 8、按按照题目要求写出对应的装饰器。
1、装饰器的理解、并实现一个计时器记录执行性能,并且将执行结果写入日志文件中
函数装饰器
def decator(file):def outer(func):def inner(*args, **kwargs):start = time.time()time.sleep(3)res = func(*args, **kwargs)with open(file,encoding='utf-8',mode='w') as f:f.write(str(res))end = time.time()print('执行时间:', end - start)return resreturn innerreturn outer@decator(file='1.txt')
def func(a, b):return a + ba = 2
b = 3
print(func(a, b))类装饰器
class A:def __init__(self,file):self.file=filedef __call__(self, func, *args, **kwargs):def wrapper(*args,**kwargs):start = time.time()time.sleep(3)res = func(*args, **kwargs)with open(self.file, encoding='utf-8', mode='w') as f:f.write(str(res))end = time.time()print('执行时间:', end - start)return resreturn wrapper@A(file='a.txt')
def f(a,b):return a+ba=3
b=6
print(f(a, b))
2、队列和栈的区别,并且用python实现
队列(Queue)和栈(Stack)是两种常见的数据结构,它们之间的主要区别在于数据的存取方式:
队列(Queue):
先进先出(FIFO):队列是按照先进先出的原则存取数据的,即先进入队列的数据会先被取出。
操作:在队列中,数据的插入是在队尾进行(enqueue),数据的删除是在队头进行(dequeue)。
应用:队列常用于实现广度优先搜索(BFS)等算法,如消息队列、任务调度等。
栈(Stack):
后进先出(LIFO):栈是按照后进先出的原则存取数据的,即最后压入栈的数据会最先被弹出。
操作:在栈中,数据的插入和删除都是在栈顶进行,压入数据称为入栈(push),弹出数据称为出栈(pop)。
应用:栈常用于实现递归函数、表达式求值、回溯算法等。
队列的实现:
from collections import deque# 创建一个空队列
queue = deque()# 入队
queue.append(1)
queue.append(2)
queue.append(3)# 出队
while queue:front = queue.popleft()print("出队:", front)
栈的实现:
# 创建一个空栈
stack = []# 入栈
stack.append(1)
stack.append(2)
stack.append(3)# 出栈
while stack:top = stack.pop()print("出栈:", top)
3、设计实现遍历目录与子目录
import os
def get_files(dir,suffix): res = [] for root,dirs,files in os.walk(dir): for filename in files: name,suf = os.path.splitext(filename) if suf == suffix: res.append(os.path.join(root,filename)) print(res) get_files("./",'.pyc')
4、CPU处理进程最慢的情况通常发生在以下几种情况下:
1、cpu负载过高:
当系统中的CPU负载达到极限或者过载时,CPU处理进程的速度就会变慢。这是因为系统资源不足,导致CPU长时间无法及时处理进程造成的。
2、竞争资源:
当多个进程竞争同一资源,如内存、硬盘或者网络宽带等,会导致CPU处理进程变慢。因为CPU需要需要等待资源的释放。
3、I/O操作:
当进程需要进行大量的输入输出操作时,CPU处理进程的速度会变慢,这是因为I/O操作相比于CPU处理速度较慢。
5、系统调度:系统调度算法不当或者优先级设置不合理可能会导致 CPU 处理进程的速度变慢,造成进程长时间等待。
5、CPU处理线程最慢的情况通常发生在以下几种情况下:
-
CPU密集型任务:当系统中存在大量的 CPU 密集型任务,会导致 CPU 处理线程变慢。因为 CPU 需要不断执行这些耗时的任务,占用大量计算资源。
-
资源竞争:当多个线程竞争同一资源,如共享内存、文件、数据库连接等,会导致 CPU 处理线程变慢。因为线程需要等待资源的释放或者合适时机才能继续执行。
-
I/O操作:和处理进程类似,线程进行大量的 I/O 操作也会导致 CPU 处理线程变慢,因为线程需要等待 I/O 操作完成才能继续执行。
-
死锁:当线程之间出现死锁情况时,CPU 处理线程会陷入等待状态,无法继续执行。这也会导致 CPU 处理线程变慢,直到死锁解除。
-
线程调度:系统调度算法或线程优先级设置不当可能会导致 CPU 处理线程变慢,造成线程长时间等待。
-
线程处于阻塞状态。
6、如何做到线程同步?
-
互斥锁(Mutex):互斥锁是一种最基本的线程同步机制,用于保护共享资源不被多个线程同时访问。在访问共享资源之前,线程需要先锁定互斥锁,访问完成后再释放锁。这样可以确保在同一时刻只有一个线程可以访问共享资源。
-
信号量(Semaphores):信号量是一种用于线程同步的计数器,可以阻塞或唤醒线程。通过信号量实现同步操作,控制多个线程对共享资源的访问。可以实现信号量来控制资源的访问数量,从而保证线程同步。
-
读写锁(Read-Write Locks):读写锁允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。通过读写锁,可以提高共享资源的并发访问性能。
-
屏障(Barriers):屏障用于多个线程需要在某个点同步,等待所有线程都到达后才能继续执行。屏障可以保证多个线程在执行过程中按一定顺序同步,实现前后依赖关系。
-
原子操作(Atomic Operations):原子操作是一种不可分割的操作,可以保证操作的完整性和线程安全性。在需要对共享资源进行简单操作时,可以使用原子操作来保证线程同步。
7、手写代码:对于字符串bdackmkdbb,输出第二个只出现一次的字符, 输出c
def test(s):dic={}res=[]for i in s:if i not in dic:dic[i]=1else:dic[i]+=1for key,value in dic.items():if value==1:res.append(key)return res[1]s="bdackmkdbb"
res=test(s)
print(res)
8、按按照题目要求写出对应的装饰器。
要求:有一个通过网络获取数据的函数(可能会因为网络原因出现异常),写一个装饰器让这个函数在出现指定异常时可以重试指定的次数,并在每次重试之前随机延迟一段时间,最长延迟时间可以通过参数进行控制。
点评:LeetCode上的企业面试题目,我们不止一次强调过,装饰器几乎是Python面试必问内
容,这个题目比之前的题目稍微复杂一些,它需要的是一个参数化的装饰器。
from functools import wraps
from random import randomdef retry(retry_time=3, max_wait_sec=5, error=(Exception,)):def decorate(fn):@wraps(fn)def wrapper(*args, **kwargs):for _ in range(retry_time):try:return fn(*args, **kwargs)except error:time.sleep(random() * max_wait_sec)return Nonereturn wrapperreturn decorate@retry(retry_time=4, max_wait_sec=4)
def request_():return '6666'print(request_())