目录
性能测试流程编辑性能相关概念
什么是新能测试
性能测试思维
性能测试环境要求
负载测试
压力测试
可靠性测试
稳定性测试
压力测试
容量测试
性能指标
并发用户数
响应时间
TPS
吞吐量
吞吐率
QPS
性能测试流程
测试准备
性能测试环境搭建
性能测试脚本开发
性能测试执行
性能测试结果分析与调优
性能测试报告与问题跟踪
性能的相关知识
性能环境搭建
java环境
jmeter
jmeter工具的使用
jmeter的图像界面
http取样器
协议
方法
路径
编码
自动重定向
跟随重定向
使用 keepalive
jmeter中的变量
用户定义的变量
用户参数
属性
定义一个变量
迭代 vs 循环
JMeter函数
“${__BeanShell(,)}”
${__counter(,)} 累加函数
${__CSVRead(,)} 读取csv文件函数
${__dateTimeConvert(,,,)} 时间格式转换函数
${__timeShift(,,,,)} 时间偏移函数
${__RandomDate(,,,,)} 随机日期
${__digest(,,,,)} 加密
${__setProperty(,,)} 设置属性
${__V(,)}拼接函数
关联
第1步: 提取响应的信息
json提取式的写法
正则提取器
边界提取器
第2步:引用变量
DDT数据驱动
CSV数据文件设置
事务控制器
聚合报告
元件作用域与优先级
1、取样器
2、配置元件
3、逻辑控制器
4、前置处理器
5、后置处理器
6、监听器
7、断言
8、定时器
特殊脚本写法
JDBC协议接口(操作数据库的协议)
JMeter中使用jdbc协议连接数据库
性能环境搭建
性能测试场景
CLI和分布式
CLI命令
分布式
性能持续集成CICD
性能测试流程

性能相关概念
什么是新能测试
使用工具, 找出或验证 系统在不同的工况下的 性能指标
性能测试思维
模拟多人使用公司产品 主要关注多人使用有没有bug,服务器资源,项目稳定情况,错误率,网络等。
性能测试环境要求
性能测试环境要求:局域网 、有线连接
负载测试
负载测试:逐步增加并发用户数,产生更大压力,测试服务器能承受的并发用户数区间。
压力测试
在一定量的并发用户数下,持续运行一段比较长的时间, 看服务器的稳定性。
可靠性测试
只要与服务器稳定性相关的测试,都算可靠性测试范围。
稳定性测试
压力测试
容量测试
数据库数据量级不同时候的测试,在不同数据量级的时候的性能指标。
性能指标
并发用户数
并发用户数: 同一时间发起请求的人
响应时间
从发起请求的这个时刻开始, 经过网络传输,到达服务器,服务器内部处理,通过网络返回响应数据,发起方收到全部响应信息为止,这样一个时间差。
TPS
服务器每秒处理的事务数。
吞吐量
网络中每秒通过的事务数
(在没有网络瓶颈的情况下, tps数值 会 等于 吞吐量的数值。有网络瓶颈, 吞吐量的数值 不会等于 tps的数值。)
吞吐率
网络中,每秒通过的字节数 单位 KB/s 1B=8b 1024x8 b/s
带宽: 300Mbps = 300 * 1024Kbps 37.5 * 1024KB/s = 37.5MB/s
QPS
这个概念不是性能测试中的概念,这个概念的来源是服务器监控中概念。服务器每秒的查询率
一个接口请求一次,只有1次查询吗? ----不确定,但是,觉得是大于等于1的
1tps = n qps (n>=1) 所以 qps大 tps就会大, qps大趋势和tps的趋势是吻合的,所以,就出现在工
作中,通过监控看到qps值,当作 tps值。但是,实际上他们存在一个 n倍关系(n>=1)
性能测试流程
性能测试的时间会比功能测试的时间 要长。 经验: 相同的需求,性能测试的时间大概是 功能测试时间的 2.5倍。
测试准备
性能测试 一定要明确目的
性能测试环境搭建
要独立环境,不能用测试环境、生产环境
性能测试环境,硬件配置,要与生产的一致,数量可以少一些。
性能测试环境,要准备测试数据。
- mysql数据库 ,数据量级 一定在十万级别以上
监控环境
性能测试脚本开发
接口测试的脚本,不能直接用于性能测试。
- 性能测试脚本,关注自身脚本性能。
- Beanshell 脚本性能就是非常差的,所以 性能测试,不用Beanshell写代码
- 断言
- 控制器、定时器----人为的控制性能测试请求的压力
性能测试执行
不能用接口测试的脚本直接用于性能测试
性能场景设计
- 至少有两个场景: 负载测试、性能测试场景
开启性能监控
性能测试结果分析与调优
分析思路:
- 自身脚本有没有问题
- 硬件问题
- 网络问题
- 服务器机器参数、服务参数分析
- 应用项目性能、数据库性能
性能测试,反复执行 与分析过程
性能测试报告与问题跟踪
性能测试会生成 性能测试报告
- 手写汇总的报告
- JMeter工具生成HTML报告
- 聚合表格,只是我们HTML报告中的一部分。
性能的相关知识
不得不知的 HTTP 状态码知识
性能环境搭建
java环境
jmeter运行环境
jmeter
语言设置
1、选项options > 选择语言 choose language > chinese 简体中文 临时变为 简体中文
2、 jmeter.properties 文件中 language的属性值 为 zh_CN
jmeter工具的使用
jmeter文件目录
bin文件夹:启动的文件\配置文件
docs文件夹:api文档,二次开发就要用这个文档
printable_docs文件夹:帮助文档JMeter使用的离线帮助文档
extras文件夹:在持续集成的时候需要使用
lib文件夹:JMeter自身的源码包
- ext文件夹: 放拓展包
jmeter的图像界面
右上角 00:00:00 运行的时间
三角图标:打开日志面板,如果JMeter工具使用了有问题 后面会有红色是数字
机器使用JMeter做性能测试,一台机器, HTTP协议的脚本 大概只能产生 2000以内的并发用户数。
工作中的测试计划
在测试计划中使用用户定义的变量是可以在整个脚本中被使用
测试计划 > 右键 > 添加
线程(线程组): 用于性能测试中的性能场景设计
线程组上右键才能添加取样器
取样器: 一类 根据协议编写脚本的元件,执行体,只有取样器才会向服务器发起请求。其他所有元件,都不会向服务器发起请求。
逻辑控制器: 控制取样器的执行逻辑
前置处理器: 在取样器执行前进行数据处理。
后置处理器: 对取样器的执行结果进行处理。
定时器: 控制取样器的执行节奏
配置原件: 为取样器做的前期准备工作,优先级也是JMeter元件中最高的。
监听器: 展示取样器的执行结果
对于一个JMeter的接口测试脚本,包括: 测试计划+线程组+取样器+监听器
内容编码 这个只能控制请求体的编码格式不能控制响应编码格式
http取样器
http取样器的使用注意点
协议
当 http协议 可以不写,https协议就要写
服务器的名称或ip: 千万不要写 / 千万不要写 http://
方法
选择方法 千万不要手写
- 如果方法选择不正确: 要么就报错, 要么就会重定向。
路径
http请求中的 URI
前后千万不要有空格
编码
内容编码: utf8
- 只能控制 http请求的编码,不能控制http响应的编码
请求编码有三个地方可以控制:
- 1、内容编码 控制项中填写
- 2、消息头管理器 Content-Type:application/json;charset=utf8
- 3、请求体为表单参数时, 参数有一个 编码 功能可以控制是内容进行 urlencoded
因为表单参数,这些参数和值,会跟在url地址后面,成为url地址的一部分
http响应编码控制:
- JMeter图形界面在windows中文编码是 GBK 编码
- 因为windows中文版字符集编码就是 GBK编码
mac系统 中文版,字符集编码 UTF8
被测项目,字符集编码, 不确定是什么字符集
如果被测项目,项目内容的中文编码,不兼容GBK,响应就会出现中文乱码。
解决:
- 修改jmeter.properties文件中 “encoding”
- sampleresult.default.encoding=修改为你项目的中文编码
- 修改了这个配置文件,保存后,重启JMeter再请求
自动重定向
不会在 查看结果树中,显示中间的过程,也无法提取到中间重定向的信息。
跟随重定向
默认勾选。 当http请求,响应码为3xx时候,就会是重定向
会在查看结果树中,显示 重定向 过程,而且JMeter也能提取重定向过程中的数据
使用 keepalive
默认勾选
现在用 http协议 是1.1版本, 这个版本是长连接协议
长连接 vs 短连接
- 长连接: 客户端 与 服务端 建立连接之后,会保持比较长的时间处于连接状态
- 短连接 :客户端 与 服务端 建立连接之后 一旦数据传输完成,就会快速断开连接状态
勾选了, 就会在 http请求头中,自动带有 Connection: keep-alive
性能测试时,会把 使用keepalive的勾去掉
jmeter中的变量
用户定义的变量
用户参数
属性
定义一个变量
- 用户定义的变量: 配置原件中 找到 用户定义的变量; 测试计划这个元件中找到
- 变量的名称: 英文字母、数字、下划线 (java变量的命名规则)
- 变量引用: ${变量的名称}
- 前置处理器 > 用户参数
用户定义的变量 vs 用户参数
- 用户定义的变量, 在启动时候获取一次值,在运行过程中不会再动态获取。 所以在运行过程中值永远不会变的。
- 用户参数, 在启动时候会获取值,在运行过程中也会动态获取值。 所以在运行过程 中,用户参数的值是可能发生变化的。
- 用户定义的变量,相当于 “全局变量”, 可以跨线程组被引用。
- 用户参数,相当于“局部变量”, 只能在当前线程组中被引用,不能直接跨线程组被引用。
用户参数中: 每次迭代更新一次
做性能测试,要造数据。
有一个注册接口,一个登录接口,要对登录接口来做性能测试(要对登录接口 进行反复执行请求), 怎么做到每次登录账号不一样,但是都能登录成功。
使用用户定义变量: 第1次注册成功,后面所有的注册,都是重复注册。 登录用的账号都是相 同的,所有的 登录都能成功。
使用用户参数: --把用户参数,放在线程组中
- 没有勾选每次迭代更新一次(默认): 注册和登录 账号不相同,所以所有的注册都能成功, 但是所有的登录都登录失败。
- 勾选每次迭代更新一次: 注册和登录,账号是相同的, 所以注册登录都能成功。
迭代 vs 循环
- 所有的请求执行完一轮,才算一个迭代
- 用户参数 勾选 每次迭代更新一次, 就是在一轮迭代中,值不会变的,迭代结 束,再次开始新的迭代时候,值 又会变
- 循环,请求重复的执行
JMeter中多个线程组默认是并行运
JMeter函数
-
“${__BeanShell(,)}”
- 主要用于写执行代码, 在性能测试中不用。 性能测试中,如果要写代码,用 “${__groovy(,)}”或 “${__jexl3(,)}”
-
${__counter(,)} 累加函数
- 累加1的函数
- 如果想要,不是累加1,加2, 就用配置元件中计数器元件
- 计数器元件,可以实现自定义步长相加,有最大值,当运行过程中,超过最大值时,又会从起始值开始
-
${__CSVRead(,)} 读取csv文件函数
- 读取csv文件函数,但是 不要用
- 要读文件,请使用配置元件中的 csv数据文件设置 这个元件
-
${__dateTimeConvert(,,,)} 时间格式转换函数
- 时间格式转换函数 ${__time(,)} 只能获取当前时间戳
-
${__timeShift(,,,,)} 时间偏移函数
- 时间偏移函数, 可以进行时间的加减
-
${__RandomDate(,,,,)} 随机日期
- 随机日期 时间转换
-
${__digest(,,,,)} 加密
- 加密 ${__P(,)} ${__property(,,)} 获取属性函数 P是 property的缩写
-
${__setProperty(,,)} 设置属性
- 函数 jmeter的配置文件中, 所有以 properties结尾的文件都是属性配置文件
-
${__V(,)}拼接函数
先定义几个变量,变量名称是有规则,前缀相同,后缀连续递增数字
value_1=111 value_2=222 value_3=333 value_4=444
使用这些变量的时候: ${value_1} 循环使用4次, 一直使用 value_1的值
想: ${value_${___counter(,)}} 想法: 循环使用时候,第1次 counter函数 值1,第2次 counter函 数值变成2。 这个是 变量中引入函数,JMeter不支持这种用法的。 变量套函数不可以 ${__V(value_${__counter(,)},)} 就是 函数套函数 可以正常运行的 ${__V(value_${d},)} 就是 函数套变量 也是可以运行的
关联
前面接口响应信息中的某个值要提取出来,最后后续接口的传入参数。 这个时候两个接口之间 有关联关系,这个时候就要用到关联。
Meter中的关联,非常简单。
第1步: 提取前面接口的响应信息中,想要内容,自定义一个变量名来接收。
第2步: 直接引用 我上面的定义的变量名 就可以了。
第1步: 提取响应的信息
1、如果我们想要提取的内容,在响应体中且响应体为 json格式。 优先选择 json提取器
2、如果我们想要提取的内容不在响应体中, 或者 响应体,不是标准的json格式, 就用 正则提取 器 可以提取 请求 和 响应头、响应体中的内容。
3、如果,我们想要提取的内容,不在响应体中, 或者 响应体,不是标准的json格式, 你对于 正则 还不熟练, 这个时候用边界提取器
提取器: 对响应、对请求的返回的内容来提取,这类元件肯定是在 取样器之后被执行。 属于 后置 处理器。
json提取式的写法
- 绝对路径: $. 开头,后面跟上从根节点开始的节点名称,多个节点之间用 点号
- 相对路径: $.. 开头, 后面跟上 末梢节点名称
使用一个json提取器,提取多个值
自定义的变量名称_matchNr 这个变量 返回 匹配的结果。 是在值有多个时候 才会出现
Math No. 填负数,代表返回所有的匹配结果
- 一个json提取器,提取多个想要的信息
- 写两个json提取器
- 一个json提取器,写多个提取式, 多个之间用分号, 一定要填写 默认值,默认值也要用分号分割,数量一定要一致
后置处理器的使用,一定是加在具体某个 取样器上面,作为取样器的子集来使用。
jmeter中的变量: 用户定义的变量、用户参数。
使用后置处理器,自己定义的变量名称,这种变量是: 用户参数
正则提取器
使用正则提取式
格式: 左边界(正则式)右边界 这个括号 是 英文小括号
正则式: 使用java正则式、perl语言正则式。 这种正则 运用范围 非常广泛。
常用:
. 匹配除换行符之外的任意内容
* 匹配0次或多次
? 匹配0次或1次
+ 匹配1次或多次
\d 配置数字
\w 匹配英文字母或数字的字符串 [a-zA-Z0_9]
[a-zA-Z] 匹配字母 []范围
[0-9] 匹配数字
^ 非JMeter中的万能 (.*?)
正则提取器:
模板: 固定写法 $数字$ 在正则提取器中,
不建议 一个正则提取器写多个正则提取式 这种用法可以用但是理解的难度要大很多。
边界提取器
与 正则提取器是类似, 区别就是不用写正则式
第2步:引用变量
固定写法:${变量名}
DDT数据驱动
性能测试,需要用到数据的地方很多,方法也很多。
在自己运行的脚本中,要读取数据; 还有就是造数据(前期准备、数据库存放到数据)
CSV数据文件设置
这个元件是 配置元件, 优先级是最高的,最新被执行一类元件。
文件名: 必须要有的、文件必须存在且可读
- 文件名可以使用 绝对路径 -------当脚本 位置改变,绝对路径取不到文件时,脚本又运行不了,所 以,绝对路径的用户,不建议用到。
- 建议使用 相对路径:
- 相对的起始点在哪?
- 1、相对你的脚本jmx保存位置
- 2、相对JMeter的bin文件夹
- 我们把 脚本和读取的文件放在同一个路径下, 使用相对路径,直接填写 文件名称带后缀, 其他人可以直接运行你的脚本。
- 相对的起始点在哪?
csv文件名,支持所有的文本格式文件(txt, csv)
csv是以逗号分割列的文本,只是我们日常中打开csv文件,用到软件是 office软件 建议,使用 txt 文本文件。而不是csv格式的。
csv格式的文件,编辑的软件,一般是用Excel,保存的时候,文件编码不是utf8,所以在JMeter中 来使用的时候,可能会因为文件编码问题导致 乱码。
csv文件设置 元件中的 文件编码,选择的时候是根据 文件名这个文件的文件编码格式来选择。
用Excel编辑的csv文件,为了防止中文编码问题导致的乱码,一般还需要使用 文本编辑器,打开,切 换为utf8编码,确认内容没有乱码之后再保存。
- 变量名: 自己定义一个变量名, =======用户参数
- 定义多个时候,用英文逗号分割
注意: csv数据文件设置,这个元件,读取数据,每次运行,都是从头开始取值
- 分割符: 根据我们读取的文件中 列与列的分割符来写
- 是否允许带有引号? : 引号必须是 英文双引号
- 遇到文件结束符再循环? 循环是循环读取值
- false: 不会循环读值
- true: 会继续循环读值 默认
- 遇到文件结束符停止线程?
- false: 不会停止JMeter的运行 默认
- true: 会停止JMeter的运行
JMexter做性能测试,使用 线程 来模拟多用户
JMeter默认用到内存 1g
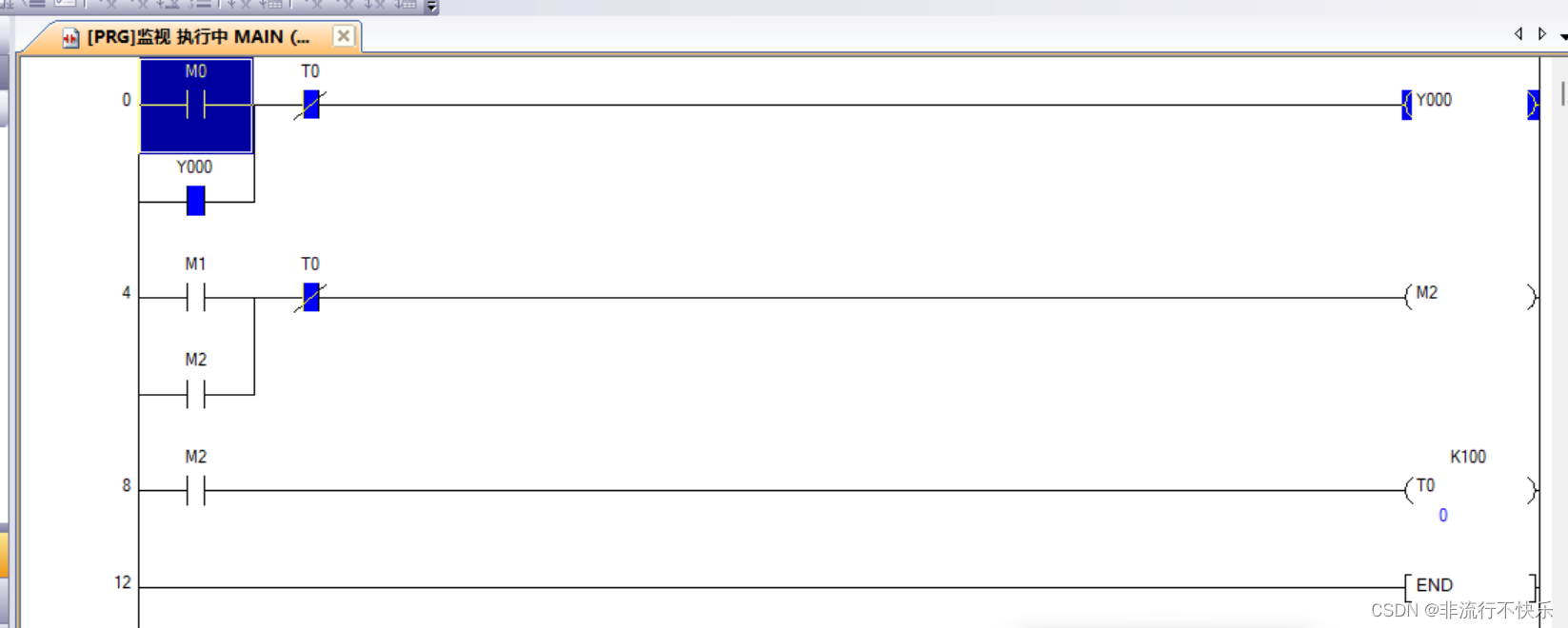
事务控制器
JMeter中有 ,一个取样器的完整请求,就是一个事务
JMeter中,也可以用 事务控制器,把多个完整的请求合并为一个事务
- 添加事务控制器, + 勾选 Generate parent sample
做性能测试: 先做单接口的性能测试。再做业务的性能测试。
单接口性能测试: 一个线程组下面,只会有一个接口。(如果有多个接口,其他的接口,也会放在 仅一 次控制下面)
业务: 一般都是多个接口才完成一个业务。多个接口都要放在 事务控制器下面 勾选 合并样本
聚合报告
性能测试, 真正执行 用到是 CLI(命令行模式),不是用图形界面GUI模式,用cli模式是,根本看不到 JMeter的界面,所以你加了监听器中 聚合报告,也没用。 ===真正做性能测试时,不用监听器中聚合报告。 真正做性能测试时任何的监听器 都不要加。
聚合报告,是一个非常非常初级报告表格。只有刚开始做性能测试的人员使用。
聚合报告,只适用于 并发用户数不变,且 没有网络瓶颈的时候,看。 如果是做 负载测试,并发用户数逐步增加的,聚合报告是完全不能看。
聚合报告中的表格:
- 行: 每一行,是一种 事务名( 不是取样器 )
- 列:
- 样本: 总的请求次数
- 平均数、中位数、90% 95% 99% 最小值、最大值 都是响应时间,单位 ms 毫秒
- 异常:
- 默认: 使用所有样本中http协议,响应码为 4xx 5xx 的数量占比
- 如果你加了断言,就这个数据,分子就会加上你断言失败的,但是http响应码为2xx 3xx 的一些数据
- 吞吐量:
- 在没有网络瓶颈,且并发用户数不变的时候, 会把这个数值 当做TPS
- 接收\发送KB/s:
- 吞吐率, 判断网络是否有瓶颈。
这个聚合报告中,不体现: 并发用户数, 执行时长。
并发用户数 x 每个用户的请求频率 x 执行时长 = 总样本数
元件作用域与优先级
1、取样器
- 作用域: 元件自身
- 优先级: 执行体(其他任何元件的优先级,都是以取样器作为比较对象)
2、配置元件
- 优先级: 最高
- 作用域:放在什么位置
- 1、放在测试计划下
- 作用域: 作用于整个测试计划
- 2、放在某个线程组中
- 作用域: 当前这个线程组
- 3、放在某个取样器下作为子集
- 作用域: 当前这个取样器
- 1、放在测试计划下
3、逻辑控制器
- 优先级:肯定比 取样器高
- 作用域: 逻辑控制器下面挂载取样器,逻辑控制器才有意义。
- 作用域: 就是他下面的所有的子集取样器。
-
4、前置处理器
- 优先级:在取样器临近执行的时候,先执行, 优先级比取样器高。
- 作用域:前置处理器放置的位置
- 1、放置在 测试计划 下
- 作用域: 整个测试计划
- 2、放置在 某个线程组中
- 作用域: 当前这个线程组
- 3、 放置在 某个取样器下作为子集
- 作用域:这个取样器及之下的所有取样器
- 1、放置在 测试计划 下
5、后置处理器
- 优先级:低于取样器
- 作用域:放置位置
- 1、放置在 测试计划中
- 没有意义
- 2、放置在 某个线程组中
- 没有意义
- 3、放置在某个取样器下作为子集
- 作用域: 当前这个取样器
- 1、放置在 测试计划中
6、监听器
- 优先级: 最低
- 作用域:放置位置
- 1、放置在 测试计划中
- 作用域: 整个测试计划
- 2、放置在 某个线程组中
- 作用域: 当前这个线程组
- 3、放置在某个取样器下作为子集
- 作用域:当前这个取样器
- 1、放置在 测试计划中
7、断言
- 优先级:肯定比取样器要低,比 后置处理器 要低
- 作用域: 放置位置 在某个取样器下作为子集
- 作用域: 当前这个取样器
8、定时器
- 优先级:比取样器要高
- 作用域: 放在线程组中,作用于整个线程组
在同一个线程组中,有多个相同的元件,相同类型的元件,执行顺序:
- 相同类型元件有多个,执行顺序是 从上往下执行。
- 在多用户并发的时候,(每个线程)依然是 从上往下执行
特殊脚本写法
JDBC协议接口(操作数据库的协议)
JMeter的取样器是根据不同的协议有不同的取样器。
操作数据库,先要连接到数据库。
数据库的连接信息:数据库的ip、端口、账户、密码、库名称。
JMeter中使用jdbc协议连接数据库
1、先要获取数据库类型对应的驱动jar包。
- 去maven的仓库中找
- mysql是5.7的,找jar包,可以找任何大于等于5.7的jar包,
- 下载jar包 把jar包 ,放到 JMeter的lib/ext文件夹中,重启JMeter
2、JMeter中配置连接数据库的信息
- JMeter中添加 JDBC Connection Configuration 配置元件
- create pool 连接池,需要自己定义
- database connection Configuration
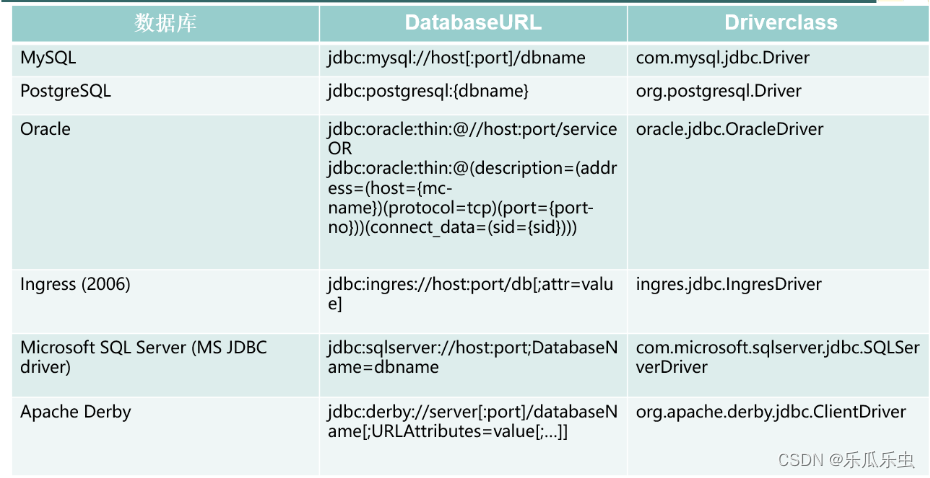
- URL
- Driver: 选择 com.mysql.jdbc.Driver
注意: 现在用的 mysql是5.7, 如果是mysql8的版本, 选择的jar包,就要与 数据库的版本一致, Driver也得改,改成 com.mysql.cj.jdbc.Driver
JDBC request中,连接池就要填你自定义的连接池的名称
常用Maven的仓库地址
jdbc数据库jar
注意:对应jmeter版本
JDBC连接数据库详看这里
性能环境搭建
性能环境搭建详看这里
性能测试场景
性能场景详看这里
CLI和分布式
CLI命令
JMeter的运行
有两种运行模式
- GUI: 图形界面模式, 使用jmeter.bat jmeter.sh jmeter
- GUI模式,仅用于,脚本开发,调试。
- CLI: 无图形界面模式 non GUI
- CLI模式, 使用命令行来运行jmeter,在执行性能测试时,使用这种模式
在Windows系统中,使用的CLI命令是`jmeter.bat`。常用的参数包括:
- `-n`:非GUI模式运行,无需图形界面。
- `-t <测试计划文件路径>`:指定要执行的测试计划文件。
- `-l <结果文件路径>`:指定结果文件的输出路径。
- `-e`:在测试完成后生成HTML报告。
- `-o <报告文件夹路径>`:指定HTML报告的输出文件夹路径。
在Linux系统中,使用的CLI命令是`jmeter.sh`。常用的参数与Windows系统中的相同。
Windows
jmeter -n -t 测试脚本.jmx -l 测试报告名.jtl -e -o 报告文件夹名
linux
./jmeter.sh -n -t 测试脚本.jmx -l results.jtl -e -o report_folder
分布式
分布式详看这里
性能持续集成CICD
性能持续集成CICD详看这里