深度学习自然语言处理 原创
作者:wkk
单位:亚利桑那州立大学
paper:Insights into Alignment:Evaluating DPO and its Variants Across Multiple Tasks
Link:https://arxiv.org/pdf/2404.14723
今天,我要带大家深入了解一项关于大型语言模型(LLMs)的研究,这是由亚利桑那州立大学的Amir Saeidi、Shivanshu Verma和Chitta Baral三位专家带来的前沿成果。他们的最新论文《Insights into Alignment: Evaluating DPO and its Variants Across Multiple Tasks》为我们揭开了直接偏好优化(DPO)及其衍生方法的神秘面纱,这些方法在优化模型以符合人类偏好方面展现出了巨大潜力。
引言
LLM在一系列任务中表现出了卓越的性能。直接偏好优化(DPO)作为一种RL-free的优化人类偏好的策略模型的方法出现了。然而,一些限制阻碍了这种方法的广泛采用。为了解决这些缺点,引入了各种版本的DPO。然而,在不同的任务中对这些变量的综合评估仍然缺乏。
在本研究中,通过研究三种不同场景下对齐方法的性能来弥合这一差距:
场景一:保留监督微调(SFT)部分。
场景二:跳过SFT部分。
场景三:跳过SFT部分并利用指令微调调整模型。
此外,还探讨了不同训练规模对其性能的影响。本文的评估涵盖了一系列任务,包括对话系统、推理、数学问题解决、问题回答、真实性和多任务理解,包括MT-Bench、Big Bench和Open LLM Leaderboard等13个基准。
简介
LLM引发了一场解决现实世界挑战的革命,展示了跨不同领域令人印象深刻的能力,需要推理和专业知识。这些模型擅长数学推理/解决问题、代码生成/编程、文本生成、摘要和创造性写作等其他任务。
其中,基于监督微调(SFT)和来自人类反馈的强化学习(RLHF)的对齐方法,LLM在人类偏好方面取得了显着的性能。虽然与SFT相比,RLHF表现出显著的性能,但它面临着reward hacking等限制。相比之下,直接偏好优化(DPO)是一种最先进的离线强化学习方法,已被提出在不需要RL过程的情况下优化人类偏好。
对齐方法的局限性包括过度拟合、低效的学习和内存使用、偏好排名等问题,以及对对话系统等各种场景的偏好的依赖、摘要、情感分析、有用和有害的问答和机器翻译。尽管这些研究很重要,但都没有彻底研究对齐中的关键歧义,例如没有SFT出现的对齐方法的可学习性、这些方法之间的公平比较、SFT后对其性能的评估、数据量对性能的影响以及这些方法固有的弱点。它们在语言推理和推理中起着至关重要的作用。
研究创新
本文深入研究了基于无RL算法的对齐方法,如DPO、IPO、KTO和CPO的性能。这些方法通常包括两个步骤:
策略模型的监督微调,
使用对齐算法(如DPO)优化SFT模型。
本文实验涵盖了各种任务,包括对话系统、推理、数学问题解决、问题回答、真实性和多任务理解。并在13个基准上评估了这些对齐方法。
本文的贡献可以分为以下几点:
探索对齐方法的学习能力,旨在减轻DPO框架内的过拟合挑战。研究结果表明,在MT-Bench中跳过SFT部分,CPO和KTO表现出相当的性能。
在三种不同的场景中广泛地研究了跨对话系统、推理、数学问题解决、问答、真实性和多任务理解的对齐方法的有效性。
综合评估表明,对齐方法在推理任务中表现出缺乏性能,但在解决数学问题和真实性方面表现出令人印象深刻的性能。
在标准对齐过程中,使用一小部分训练数据对具有所有对齐算法的SFT模型进行微调可以产生更好的性能。
相关工作
随着预训练LLM的发展,在各种任务的零样本和少样本场景中取得了出色的性能。然而,当应用于下游任务时,LLM的性能往往会下降。虽然使用人工微调模型有助于对齐和性能提升,但获得人类对响应的偏好通常更可行。因此,最近的研究转向使用人类偏好微调LLM。以下是各种任务的对齐方法:
人类反馈的强化学习(RLHF):提出通过使用近端策略优化(PPO)等强化算法,使用Bradley-Terry(BT)模型训练的奖励模型来优化最大奖励操作。虽然RLHF增强了模型的性能,但它要应对强化学习中固有的不稳定性、reward hacking和可扩展性等挑战。
序列似然校准(SLiC):引入了一种新的方法来对监督微调(SFT)模型产生的偏好进行排名,在训练期间使用校准损失和正则化微调损失。同时,假设每个输入有多个排序响应,使用零边际似然对比损失训练SFT模型。
统计拒绝抽样优化(RSO):结合了SLiC和DPO的方法,同时引入了一种通过统计拒绝抽样收集偏好对的增强方法。
KTO:受到Kahneman和Tversky关于前景理论的开创性工作的启发,旨在直接最大化LLM的效用,而不是最大化偏好的对数可能性。这种方法消除了对同一输入的两个偏好的需要,因为它专注于辨别一个偏好是可取的还是不可取的。
Self-Play fIne tuNing(SPIN):一种使用SFT步骤中使用的数据集来增强DPO的自我训练方法。这种方法的关键思想是利用生成的合成数据作为拒绝响应,并利用来自SFT数据集的gold response作为chosen response。同时,收缩偏好优化(CPO)提出了一种将最大似然损失和DPO损失函数相结合的有效学习偏好方法,旨在提高记忆和学习效率。
上述工作缺乏对完成和偏好学习的对齐方法的比较研究。虽然这些研究解决了DPO需要SFT步骤,但有必要进一步探索替代方法。尽管高质量偏好的重要性已被广泛认可,但仍然需要探索数据量对对齐方法性能的影响。此外,泛化的关键方面仍未得到探索。虽然对齐模型旨在增强所有类别的性能,但改进对齐方法通常以牺牲其他领域的性能为代价。
对齐方法
通常RL调整过程分为三个阶段:
使用监督微调(SFT)微调策略模型,
训练奖励模型,
使用强化学习(RL)进一步微调初始策略模型,其中奖励模型提供反馈机制。
DPO最近的研究引入了一种RL-free的方法,旨在通过优化首选和非首选响应的可能性来对齐策略模型。DPO损失函数数学方式表述如下:
尽管DPO通过RTL-free的方法超越了RLHF,但它面临着过度拟合和需要大量正则化等约束,这可能会阻碍策略模型的有效性。为了解决这些限制,研究学者引入了IPO算法,该算法定义了DPO的一般形式并重新制定它以解决过度拟合和正则化。IPO损失函数如下式所示:
IPO算法解决了过度拟合的问题和DPO中存在的需要广泛正则化的缺陷,但基于两种偏好的对齐方法有不同的复杂性。KTO研究旨在通过实施仅利用单一偏好的策略来提高DPO方法的有效性。KTO损失函数表达式如下所示:
IPO和KTO增强了DPO模型的性能并解决了其中部分缺点。然而,当两个模型的同时加载时,会导致DPO算法的学习效率低下。为了改进这一点,研究学者开发了CPO方法,提高了DPO方法的效率。研究表明,在训练期间不需要加载参考策略模型。通过省略内存的参考模型,CPO提高了操作效率,与DPO相比,能够以更低的成本训练更大的模型。CPO损失函数表达式如下所示:
实验
研究团队设置了三个不同的实验场景,以评估DPO和其他几种对齐方法(如IPO、KTO、CPO)的性能:
监督微调(SFT):首先训练一个SFT模型,然后使用对齐方法进行进一步的优化。
预训练模型微调:绕过SFT阶段,直接在预训练模型上应用对齐方法。
指令调整模型微调:跳过SFT阶段,使用指令调整的模型作为基础,再进行对齐方法的微调。这些实验覆盖了对话系统、推理、数学问题解决、问答、真实性和多任务理解等13个基准测试,包括MT-Bench、Big Bench和Open LLM Leaderboard。
方法
为了评估推理方法,实验利用ARC、HellaSwag、Winogrande、Big Bench体育理解(BBsports)、Big Bench因果判断(BB-casual)、Big Bench形式谬误(BB-formal)和PIQA。为了评估各种方法的数学问题解决能力,使用GSM8K基准。使用TruthfulQA基准评估真实性。此外,使用MLU基准来衡量它们在多任务理解方面的表现。OpenBookQA和BoolQ基准用于评估它们在问答任务中的表现。最后,为了评估它们在对话系统中的有效性,利用MT-Bench 基准,它由八个知识领域的 160 个问题组成,GPT-4在0到10的范围内对模型生成的答案进行评分。
实验结果
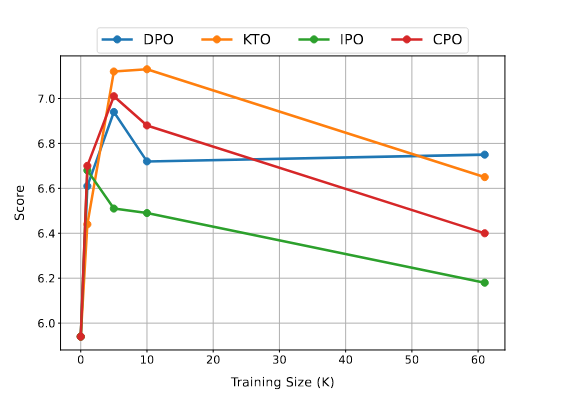
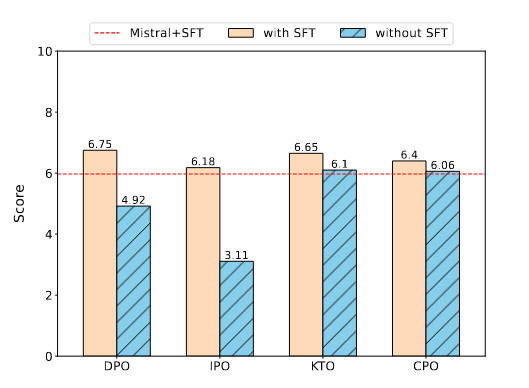
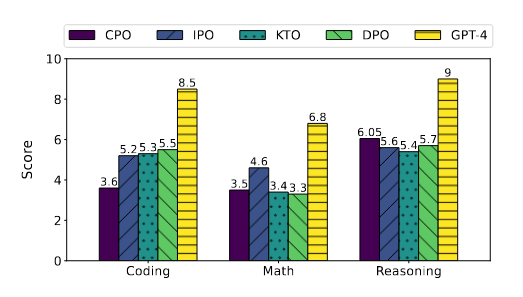
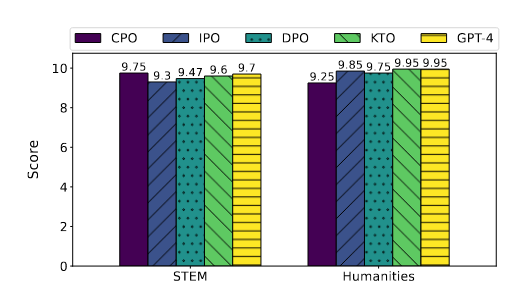
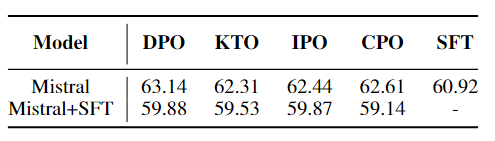

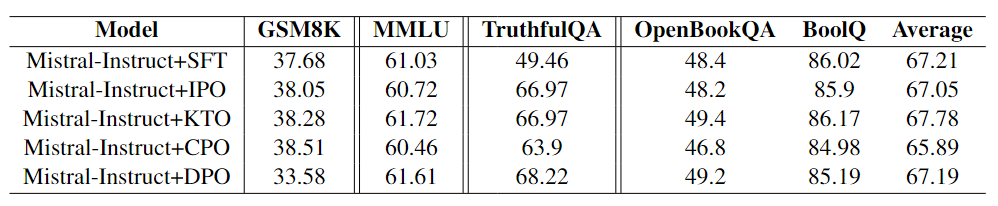
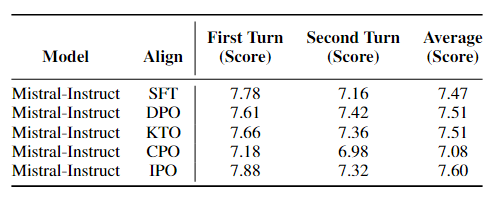
| 场景 | 结论 |
|---|---|
| 场景一:监督微调 | 结合图1-2和表1中,可以看出,除了MLU之外,KTO在MT-Bench中超越了其他对齐方法,并且在所有学术基准测试中都表现出卓越的性能。特别值得注意的是KTO在GSM8K上的卓越性能,突出了其解决数学问题的强大能力。另外,没有采用任何对齐方法在MMLU中优于SFT。这表明SFT仍然优于其他多任务理解方法。此外,除了推理、真实性和问答中的KTO算法外,SFT表现出相当的性能。这表明对齐方法难以在这些任务中取得显著的性能改进。 |
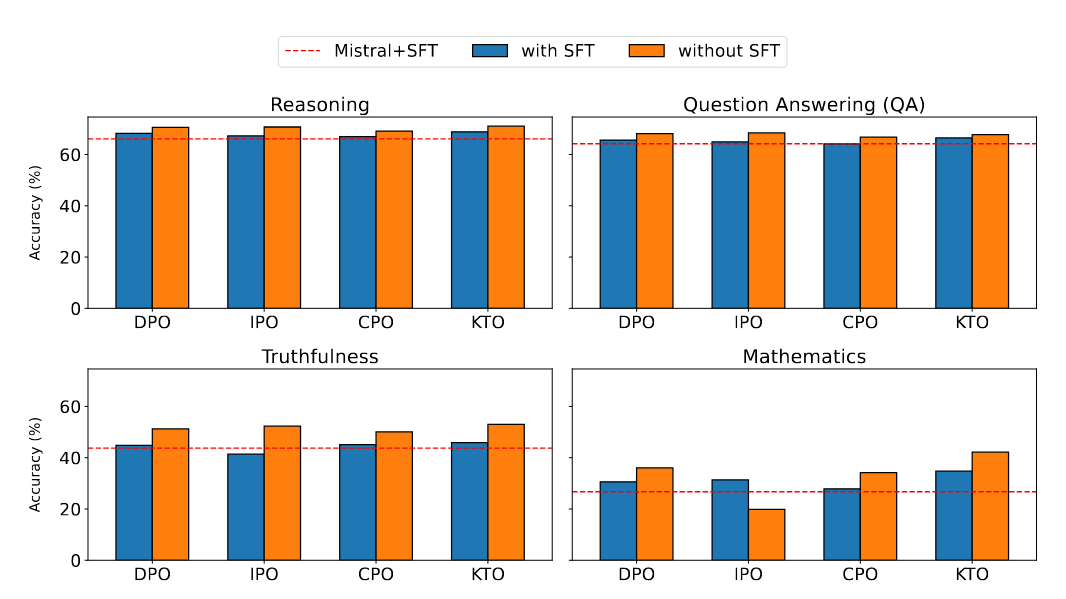
| 场景二:预训练模型微调 | 图3中的研究结果表明,跳过SFT阶段导致Mistral+IPO和Mistral+TPO在对话系统中表现不佳,因为与SFT相比,它们的得分较低。然而,Mistral+KTO和Mistral+CPO的得分与Mistral+SFT相当。图1所示的结果揭示了几个关键发现。首先,跳过SFT阶段会导致推理性能的边际提高,而不会产生显著影响。其次,除了GSM8K的IPO之外,GSM8K和TruthfulQA基准中的所有比对方法都有显著且一致的改进。此外,在MMLU基准中,跳过SFT阶段不仅提高了性能,而且导致所有对齐方法都优于SFT基准。 |
| 场景三:指令调整模型微调 | 表3中显示的结果表明,KTO和IPO在 TruthfulQA 上的表现优于SFT,而基于预训练模型的KTO在TruthfulQA上的表现优于SFT。这强调了指令调整模型的高有效性,尤其是在真实性方面。此外,表4显示,IPO在MT-Bench中优于其他方法。表2和表3中显示的结果表明,SFT在推理、数学、问答和多任务理解基准上表现出相当的性能。虽然对齐方法表现出比 SFT 更好的性能,但准备偏好数据集的挑战仍然很重要,在大多数情况下使用SFT更可取。值得注意的是,在MT-Bench中,与SFT相比,CPO的性能更差,这表明与使用SFT进行微调的模型相比,使用CPO微调的模型在对话系统中表现出较弱的性能。图4显示,虽然提高了整体性能,但模型在某些领域的能力有所下降。图5中另一个有趣的发现是,不仅KTO在人文方面与GPT-4实现了相同的分数,而且CPO在STEM领域也优于GPT-4。这一发现突出了对齐方法与GPT-4等最先进模型相媲美的能力。 |
总结
本文评估了RL-free在各种任务上的性能,包括推理、数学问题解决、真实性、问答和多任务理解三个不同的场景。结果表明,在大多数情况下,KTO优于其他对齐方法。然而,这些技术在常规对齐过程中并没有显着提高推理和问答中的模型性能,尽管它们显着提高了数学问题解决。研究还表明,对齐方法对训练数据量特别敏感,在较小的数据子集下表现最佳。值得注意的是,与DPO不同,KTO和CPO可以绕过SFT部分并在MT-Bench上实现相当的性能。
这项研究不仅为LLMs的对齐方法提供了一个全面的评价框架,还为未来的研究方向——如何开发出更加健壮的模型来应对对齐挑战——提供了宝贵的见解。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦