pyppeteer仓库地址:https://github.com/miyakogi/pyppeteer
puppeteer仓库地址:https://github.com/search?q=puppeteer&type=repositories
因为有些网页是可以检测到是否是使用了selenium。并且selenium所谓的保护机制不允许跨域cookies保存以及登录的时候必须先打开网页然后后加载cookies再刷新的方式很不友好。所以采用谷歌chrome官方无头框架puppeteer的python版本pyppeteer。
Pyppeteer 简介
1.Chrome 浏览器和 Chromium 浏览器
在 Pyppetter 中,实际上它背后也是有一个类似 Chrome 浏览器的 Chromium 浏览器在执行一些动作进行网页渲染,首先说下 Chrome 浏览器和 Chromium 浏览器的渊源。
Chromium 是谷歌为了研发 Chrome 而启动的项目,是完全开源的。二者基于相同的源代码构建,Chrome 所有的新功能都会先在 Chromium 上实现,待验证稳定后才会移植,因此 Chromium 的版本更新频率更高,也会包含很多新的功能,但作为一款独立的浏览器,Chromium 的用户群体要小众得多。两款浏览器“同根同源”,它们有着同样的 Logo,但配色不同,Chrome 由蓝红绿黄四种颜色组成,而 Chromium 由不同深度的蓝色构成。
Pyppeteer 就是依赖于 Chromium 这个浏览器来运行的。那么有了 Pyppeteer 之后,我们就可以免去那些繁琐的环境配置等问题。如果第一次运行的时候,Chromium 浏览器没有安装,那么程序会帮我们自动安装和配置,就免去了繁琐的环境配置等工作。另外 Pyppeteer 是基于 Python 的新特性 async 实现的,所以它的一些执行也支持异步操作,效率相对于 Selenium 来说也提高了。
注意:本来chrome就问题多多,puppeteer也是各种坑,加上pyppeteer是基于前者的改编python版本,也就是产生了只要前两个有一个有bug,那么pyppeteer就会原封不动的继承下来,本来这没什么,但是现在遇到的问题就是pyppeteer这个项目从18年9月份之后就没更新过了,前两者都在不断的更新迭代,而pyppeteer一直不更新,导致很多bug根本没人修复。
2.asyncio
asyncio是Python的一个异步协程库,自3.4版本引入的标准库,直接内置了对异步IO的支持,号称是Python最有野心的库,官网上有非常详细的介绍:
Pyppeteer快速上手
1.安装
在第一次使用pyppeteer的时候也会自动下载并安装chromium浏览器,效果是一样的。总的来说,pyppeteer比起selenium省去了driver配置的环节。
当然,出于某种原因,也可能会出现chromium自动安装无法顺利完成的情况,这时可以考虑手动安装:首先,从下列网址中找到自己系统的对应版本,下载chromium压缩包;
'linux': 'https://storage.googleapis.com/chromium-browser-snapshots/Linux_x64/575458/chrome-linux.zip'
'mac': 'https://storage.googleapis.com/chromium-browser-snapshots/Mac/575458/chrome-mac.zip'
'win32': 'https://storage.googleapis.com/chromium-browser-snapshots/Win/575458/chrome-win32.zip'
'win64': 'https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/575458/chrome-win32.zip'
2.2 初始化设置
import asyncio, time
from pyppeteer import launchasync def main():browser = await launch(headless=False, dumpio=True, autoClose=False,args=['--no-sandbox', '--window-size=1920,1080', '--disable-infobars']) # 进入有头模式page = await browser.newPage() # 打开新的标签页await page.setViewport({'width': 1920, 'height': 1080}) # 页面大小一致await page.goto('https://www.baidu.com/?tn=99669880_hao_pg') # 访问主页# evaluate()是执行js的方法,js逆向时如果需要在浏览器环境下执行js代码的话可以利用这个方法# js为设置webdriver的值,防止网站检测await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')# await page.screenshot({'path': './1.jpg'}) # 截图保存路径page_text = await page.content() # 获取网页源码print(page_text)time.sleep(1)
asyncio.get_event_loop().run_until_complete(main()) #调用
参数参考:Pyppeteer:比selenium更高效的爬虫界的新神器
launch可接收的参数非常多,其中
ignoreHTTPSErrors(bool):是否忽略 HTTPS 错误。默认为 False
headless指定浏览器是否以无头模式运行,默认是True。
args 指定给浏览器实例传递的参数,
--disable-infobars 代表关闭浏览上方的“Chrome 正受到自动测试软件的控制”,
--window-size=1920,1080是设置浏览器的显示大小,
--no-sandbox 是 在 docker 里使用时需要加入的参数。
关闭提示条:”Chrome 正受到自动测试软件的控制”,这个提示条有点烦,那咋关闭呢?这时候就需要用到 args 参数了,禁用操作如下:browser = await launch(headless=False, args=['--disable-infobars'])
其他很多参数可以参考puppeteer的文档:https://zhaoqize.github.io/puppeteer-api-zh_CN/#?product=Puppeteer&version=v2.1.1&show=api-class-puppetee
绕过 webdriver 检测
检测地址:https://intoli.com/blog/not-possible-to-block-chrome-headless/chrome-headless-test.html
import asyncio
from pyppeteer import launch# 测试检测webdriver
async def main():browser = await launch(headless=False, args=['--disable-infobars'])page = await browser.newPage()await page.setUserAgent("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5")await page.setViewport(viewport={'width': 1536, 'height': 768})await page.goto('https://intoli.com/blog/not-possible-to-block-chrome-headless/chrome-headless-test.html')await asyncio.sleep(25)await browser.close()
asyncio.get_event_loop().run_until_complete(main())
Pyppeteer 开启 Chromium 照样还是能被检测到 WebDriver 的存在:
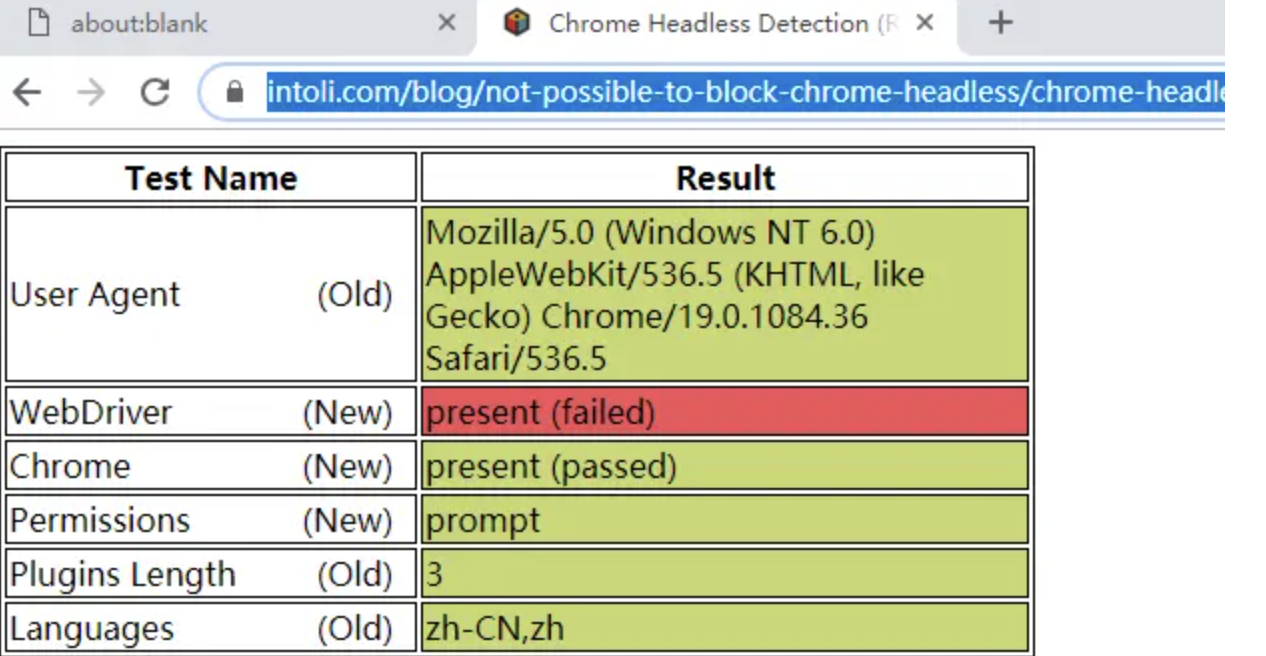
无论是 selenium 的 execute_script() 方法,还是 pyppeteer 的 evaluate() 方法执行下面代码都能临时修改浏览器属性中的 webdriver 属性,当页面刷新或者跳转之后该值就会原形毕露。
await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')但是 pyppeteer 的最底层是封装的puppeteer,是 js 库,是和网站源码交互最深的方式。
在 pyppeteer 中提供了一个方法:evaluateOnNewDocument(),该方法是将一段 js 代码加载到页面文档中,当发生页面导航、页面内嵌框架导航的时候加载的 js 代码会自动执行,那么当页面刷新的时候该 js 也会执行,这样就保证了修改网站的属性持久化的目的:
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,''{ webdriver:{ get: () => false } }) }') 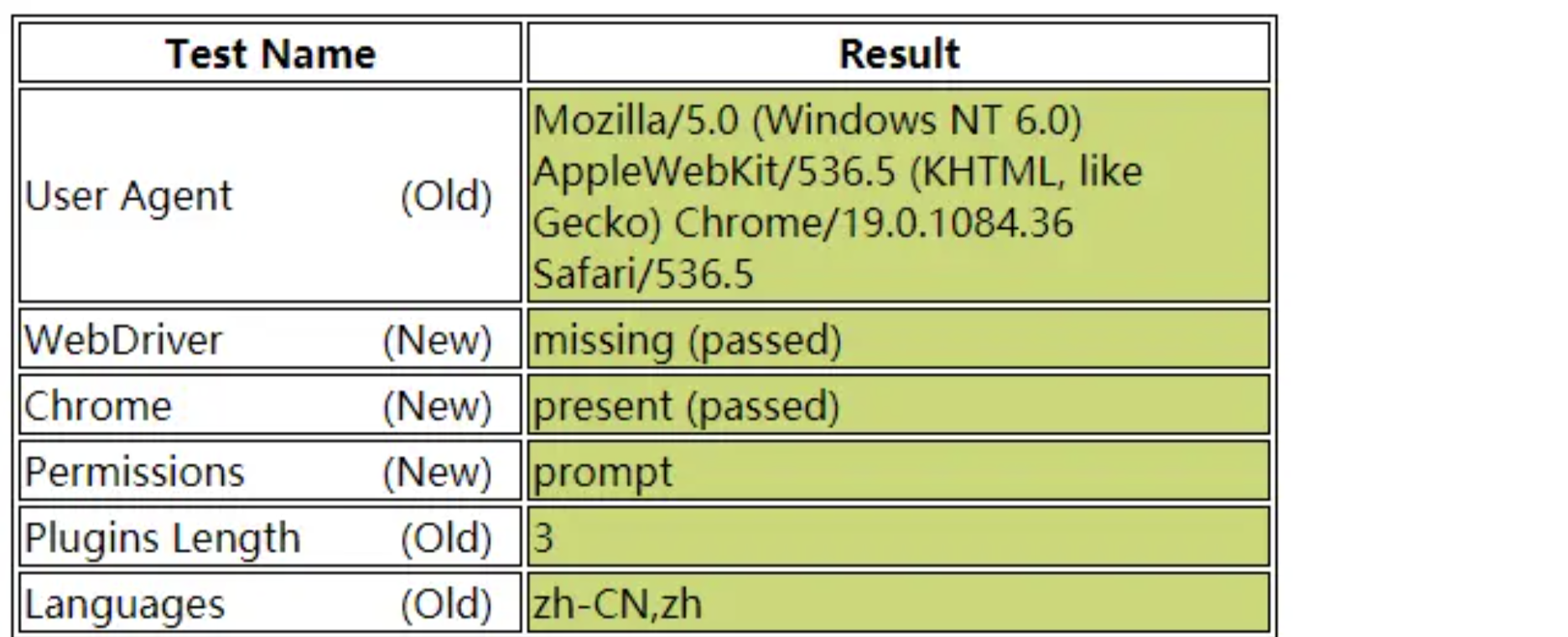
基本使用,支持的选择器有
# 在页面内执行 document.querySelector。如果没有元素匹配指定选择器,返回值是 None
J = querySelector
# 在页面内执行 document.querySelector,然后把匹配到的元素作为第一个参数传给 pageFunction
Jeval = querySelectorEval
# 在页面内执行 document.querySelectorAll。如果没有元素匹配指定选择器,返回值是 []
JJ = querySelectorAll
# 在页面内执行 Array.from(document.querySelectorAll(selector)),然后把匹配到的元素数组作为第一个参数传给 pageFunction
JJeval = querySelectorAllEval
# XPath表达式
Jx = xpath
快速入门
import asyncio
from pyppeteer import launchasync def main():# headless参数设为False,则变成有头模式# Pyppeteer支持字典和关键字传参,Puppeteer只支持字典传参# 指定引擎路径# exepath = r'C:\Users\Administrator\AppData\Local\pyppeteer\pyppeteer\local-chromium\575458\chrome-win32/chrome.exe'# browser = await launch({'executablePath': exepath, 'headless': False, 'slowMo': 30})browser = await launch(# headless=False,{'headless': False})page = await browser.newPage()# 设置页面视图大小await page.setViewport(viewport={'width': 1280, 'height': 800})# 是否启用JS,enabled设为False,则无渲染效果await page.setJavaScriptEnabled(enabled=True)# 超时间见 1000 毫秒res = await page.goto('https://www.toutiao.com/', options={'timeout': 1000})resp_headers = res.headers # 响应头resp_status = res.status # 响应状态# 等待await asyncio.sleep(2)# 第二种方法,在while循环里强行查询某元素进行等待while not await page.querySelector('.t'):pass# 滚动到页面底部await page.evaluate('window.scrollBy(0, document.body.scrollHeight)')await asyncio.sleep(2)# 截图 保存图片await page.screenshot({'path': 'toutiao.png'})# 打印页面cookiesprint(await page.cookies())""" 打印页面文本 """# 获取所有 html 内容print(await page.content())# 在网页上执行js 脚本dimensions = await page.evaluate(pageFunction='''() => {return {width: document.documentElement.clientWidth, // 页面宽度height: document.documentElement.clientHeight, // 页面高度deviceScaleFactor: window.devicePixelRatio, // 像素比 1.0000000149011612}}''', force_expr=False) # force_expr=False 执行的是函数print(dimensions)# 只获取文本 执行 js 脚本 force_expr 为 True 则执行的是表达式content = await page.evaluate(pageFunction='document.body.textContent', force_expr=True)print(content)# 打印当前页标题print(await page.title())# 抓取新闻内容 可以使用 xpath 表达式"""# Pyppeteer 三种解析方式Page.querySelector() # 选择器Page.querySelectorAll()Page.xpath() # xpath 表达式# 简写方式为:Page.J(), Page.JJ(), and Page.Jx()"""element = await page.querySelector(".feed-infinite-wrapper > ul>li") # 纸抓取一个print(element)# 获取所有文本内容 执行 jscontent = await page.evaluate('(element) => element.textContent', element)print(content)# elements = await page.xpath('//div[@class="title-box"]/a')elements = await page.querySelectorAll(".title-box a")for item in elements:print(await item.getProperty('textContent'))# <pyppeteer.execution_context.JSHandle object at 0x000002220E7FE518># 获取文本title_str = await (await item.getProperty('textContent')).jsonValue()# 获取链接title_link = await (await item.getProperty('href')).jsonValue()print(title_str)print(title_link)# 关闭浏览器await browser.close()asyncio.get_event_loop().run_until_complete(main())ascyncio 同步与异步执行 Pyppeteer
1.同步
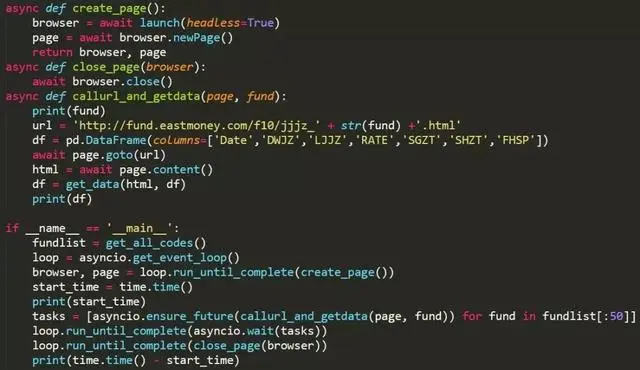
基本思路是新建一个browser浏览器和一个页面page,依次访问每个基金的净值数据页面并爬取数据。核心代码如下:
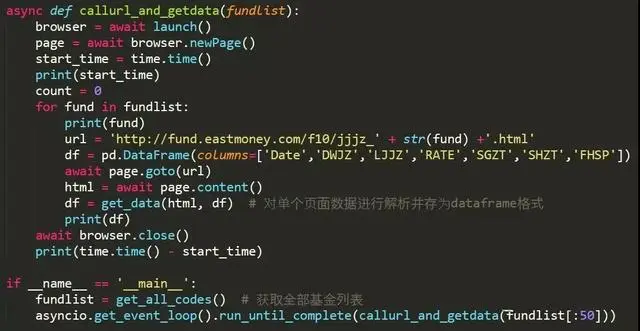
get_data()函数 用于净值数据页面解析和数据的转化,
get_all_codes()函数 用于获取全部开放式基金的基金代码(共6000余个)。
虽然程序也使用了async/await的结构,但是对多个基金的净值数据获取都是在callurl_and_getdata()函数中顺序执行的,之所以这样写是因为pyppeteer中的方法都是coroutine对象,必须以这种形式构建程序。
为了排除打开浏览器的耗时干扰,我们仅统计访问页面和数据抓取的用时,其结果为:12.08秒。
2. 异步
主要是把对fundlist的循环运行改装成async的task对象
3. 获取标签的文本、值
# 获取a标签
title_elements = await page.Jx('//*[@class="result c-container "]/h3/a')for item in title_elements:# 获取文本:方法一,通过getProperty方法获取title_str1 = await (await item.getProperty('textContent')).jsonValue()print(title_str1)# 获取文本:方法二,通过evaluate方法获取title_str2 = await page.evaluate('item => item.textContent', item)print(title_str2)# 获取链接:通过getProperty方法获取title_link = await (await item.getProperty('href')).jsonValue()常见的bug
1. pyppeteer.errors.NetworkError: Protocol error Network.getCookies: Target close
方法1:控制访问指定url之后await page.goto(url),会遇到上面的错误,如果这时候使用了sleep之类的延时也会出现这个错误或者类似的time out。
这个问题是puppeteer的bug,但是对方已经修复了,而pyppeteer迟迟没更新,就只能靠自己了,搜了很多人的文章,例如:https://github.com/miyakogi/pyppeteer/issues/171 ,但是我按照这个并没有成功。
也有人增加一个函数,但调用这个参数依然没解决问题。
async def scroll_page(page):cur_dist = 0height = await page.evaluate("() => document.body.scrollHeight")while True:if cur_dist < height:await page.evaluate("window.scrollBy(0, 500);")await asyncio.sleep(0.1)cur_dist += 500else:break
方法2:可以把python第三方库websockets版本7.0改为6.0就可以了,亲测可用。
pip uninstall websockets #卸载websockets
pip install websockets==6.0 #指定安装6.0版本2. chromium浏览器多开页面卡死问题
方法:解决这个问题的方法就是浏览器初始化的时候添加’dumpio’:True。
3. 浏览器窗口很大,内容显示很小
上面的问题是需要设置浏览器显示大小,默认就是无法正常显示。可以看到页面左侧右侧都是空白,网站内容并没有完整铺满chrome.
browser = await launch({'headless': False,'dumpio':True, 'autoClose':False,'args': ['--no-sandbox', '--window-size=1366,850']})
await page.setViewport({'width':1366,'height':768})方法:通过上面设置Windows-size和Viewport大小来实现网页完整显示。
但是对于那种向下无限加载的长网页这种情况如果浏览器是可见状态会显示不全,针对这种情况的解决方法就是复制当前网页新开一个标签页粘贴进去就正常了
4. Execution context was destroyed, most likely because of a navigation.

因为页面发生了跳转导致 page 丢失
方法:
// 在登录页跳转之后添加
await page.waitForNavigation(); // 等待页面跳转5.登录出现 滑块 和cookies获取
import asyncio
from pyppeteer import launchasync def main():browser = await launch({'headless': False, 'args': ['--disable-infobars', '--window-size=1920,1080']})page = await browser.newPage()await page.setViewport({'width': 1920, 'height': 1080})await page.goto('https://login.taobao.com/member/login.jhtml')await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')await page.waitForSelector('#J_QRCodeLogin > div.login-links > a.forget-pwd.J_Quick2Static', {'timeout': 3000})await page.click('#J_QRCodeLogin > div.login-links > a.forget-pwd.J_Quick2Static')await page.type('#TPL_username_1', '') # 账号await page.type('#TPL_password_1', '') # 密码await asyncio.sleep(5)slider = await page.Jeval('#nocaptcha', 'node => node.style') # 是否有滑块,ps:试了好多次都没出滑块if slider:print('出现滑块')await page.click('#J_SubmitStatic')await asyncio.sleep(5)cookie = await page.cookies()print(cookie)await browser.close()asyncio.get_event_loop().run_until_complete(main())6. pyppeteer.errors.TimeoutError: Navigation Timeout Exceeded: 30000 ms exceeded
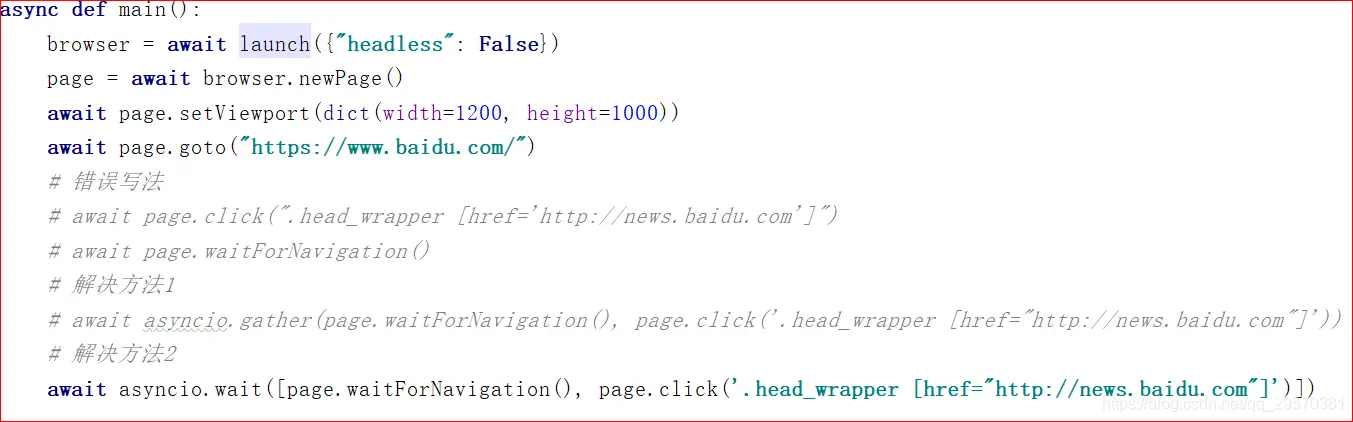
由于点击事件执行很快已跳转到新的页面,导致程序运行到导航等待的时候,一直处于新的页面等待触发,直到30秒超时报错,所以,正确的做法应该是把点击和导航等待视为一个整体进行操作,以下为两种正确的写法,了解协程并发的朋友应该知道,在此不做详细说明





![【例子】webpack配合babel实现 es6 语法转 es5 案例 [通俗易懂]](https://img-blog.csdnimg.cn/direct/60f0f5c8ae274c05ac49ea480c76c872.png)