1.拉取官方镜像
地址: https://hub.docker.com/r/pytorch/torchserve/tags
docker pull pytorch/torchserve:0.7.1-gpu
2. docker启动指令
CPU
docker run --rm -it -d -p 8380:8080 -p 8381:8081 --name torch-server -v /path/model-server/extra-files:/home/model-server/extra-files -v /path/model-server/model-store:/home/model-server/model-store pytorch/torchserve:0.7.1-gpu
GPU
docker run --rm -it -d --gpus all -p 8380:8080 -p 8381:8081 --name torch-server -v /path/model-server/extra-files:/home/model-server/extra-files -v /path/model-server/model-store:/home/model-server/model-store pytorch/torchserve:0.7.1-gpu
/home/model-server/model-store 是docker映射地址,不能更改
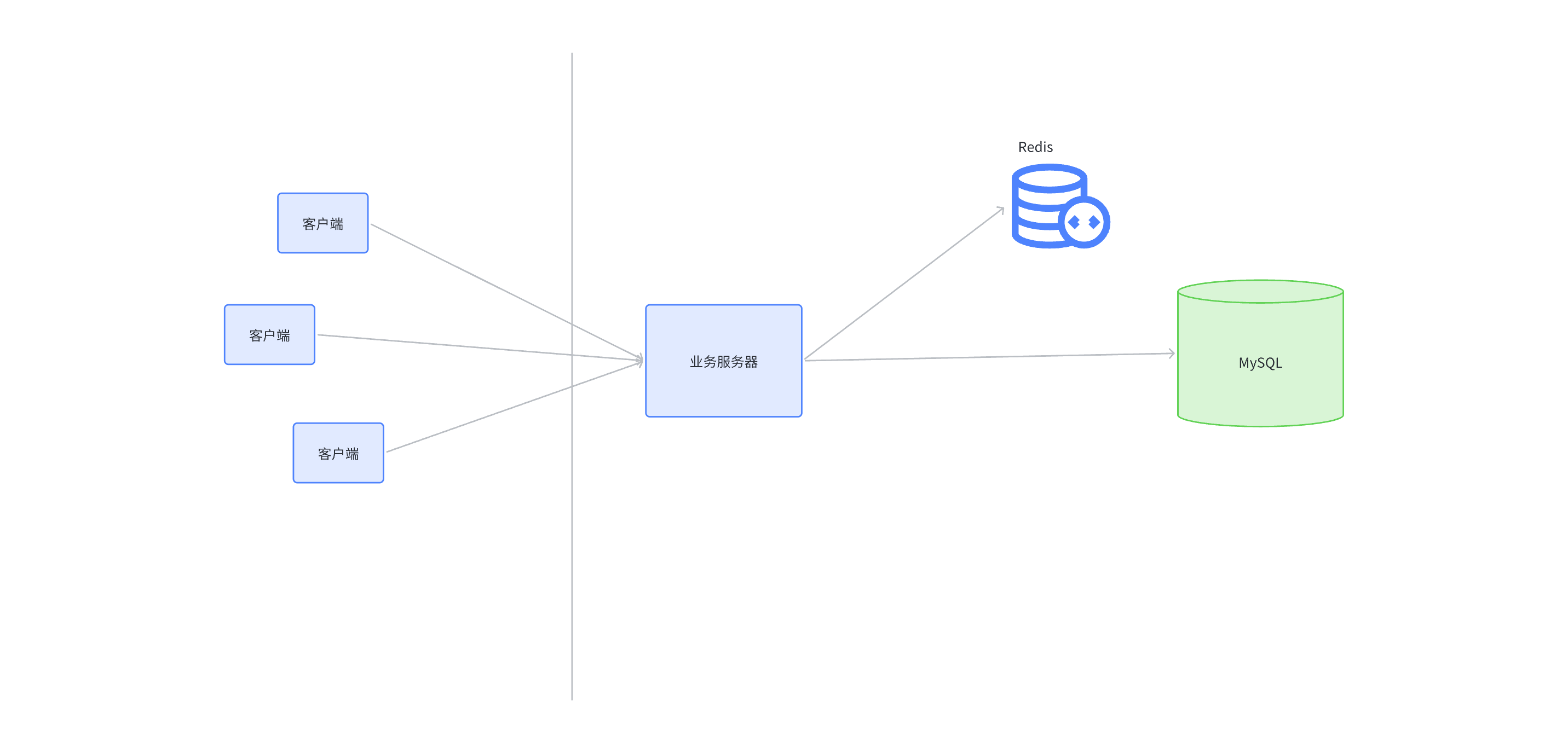
进入容器,可以发现各个端口的意义,8080是通信访问接口,8081是管理服务配置接口,8082是服务监控接口

3. 打包模型文件
3.1 使用框架中脚本或者自己写脚本将模型转为torchscript(.pt)
3.2 torchscript转.mar文件
(1) run_hander.py
from xx_model_handler import KnowHandler_service = KnowHandler()def handle(data, context):try:if not _service.initialized:print('ENTERING INITIALIZATION')_service.initialize(context)if data is None:return Nonedata = _service.preprocess(data)data = _service.inference(data)data = _service.postprocess(data)return dataexcept Exception as e:raise Exception("Unable to process input data. " + str(e))
(2) xx_model_handler.py
"""
ModelHandler defines a custom model handler.
"""
import torch
import os
import json
import logging
from transformers import BertTokenizerclass KnowHandler(object):"""A custom model handler implementation."""def __init__(self):super(KnowHandler, self).__init__()self.initialized = Falsedef initialize(self, ctx):"""Initialize model. This will be called during model loading time:param context: Initial context contains model server system properties.:return:"""self.manifest = ctx.manifestproperties = ctx.system_propertiesmodel_dir = properties.get("model_dir")serialized_file = self.manifest["model"]["serializedFile"]model_pt_path = os.path.join(model_dir, serialized_file)self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")config_path = os.path.join(model_dir, "config.json")with open(config_path,"r") as fr:setup_config = json.load(fr)self.model = torch.jit.load(model_pt_path, map_location=self.device)self.tokenizer = BertTokenizer(setup_config["vocab_path"])self.max_length = setup_config["max_length"]self.initialized = True# load the model, refer 'custom handler class' above for detailsdef preprocess(self, data):"""Transform raw input into model input data.:param batch: list of raw requests, should match batch size:return: list of preprocessed model input data"""# Take the input data and make it inference readypreprocessed_data = data[0].get("data")if preprocessed_data is None:preprocessed_data = data[0].get("body")inputs = preprocessed_data.decode('utf-8')inputs = json.loads(inputs) # {"text": []}return inputsdef inference(self, model_input):"""Internal inference methods:param model_input: transformed model input data:return: list of inference output in NDArray"""# Do some inference call to engine here and return outputtext = model_input["text"]inputs = self.tokenizer(text,max_length=self.max_length,truncation=True,padding='max_length',return_tensors='pt')#inputs = {k: torch.as_tensor(v, dtype=torch.int64) for k, v in inputs.items()}for key, value in inputs.items():if isinstance(value, torch.Tensor):inputs[key] = value.to(self.device)input_ids = inputs['input_ids']token_type_ids = inputs['token_type_ids']attention_mask = inputs['attention_mask']logits = self.model(input_ids,attention_mask,token_type_ids)return logitsdef postprocess(self, inference_output):"""Return inference result.:param inference_output: list of inference output:return: list of predict results"""# Take output from network and post-process to desired formatpostprocess_output = [inference_output.tolist()]return postprocess_output(3) config.json
{"threshold": 0.8,"max_length": 40
}
torch-model-archiver --model-name {name of model} --version {模型版本} --serialized-file {torchscript文件地址} --export-path {.mar文件存放地址} --handler run_handler.py --extra-files {其它文件如配置文件等} --runtime python3 -f
torch-model-archiver --model-name my_model --version 1.0 --serialized-file /path/mymodel.pt --export-path /home/model-server/model-store --handler run_handler.py --extra-files "xx_model_handler,utils.py,config.json,vocab.txt" --runtime python -f
–model-name: 模型的名称,后来的接口名称和管理的模型名称都是这个
–serialized-file: 模型环境及代码及参数的打包文件
–export-path: 本次打包文件存放位置
–extra-files: handle.py中需要使用到的其他文件
–handler: 指定handler函数。(模型名:函数名)
-f 覆盖之前导出的同名打包文件
4. torchserver配置接口
(1)查询已注册的模型
curl "http://localhost:8381/models"
(2)注册模型并为模型分配资源
将.mar模型文件注册,注意:.mar文件必须放在model-store文件夹下,即/path/model-server/model-store
curl -X POST "{ip:port}/models?url={.mar文件名}&model_name={model_name}&batch_size=8&max_batch_delay=10&initial_workers=1"curl -X POST "localhost:8381/models?url=my_model.mar&model_name=my_model&batch_size=8&max_batch_delay=10&initial_workers=1"
(3)查看模型状态
curl http://localhost:8381/models/{model_name}
(4)删除注册模型
curl -X DELETE http://localhost:8381/models/{model_name}/{version}
5. 模型推理
response = requests.post('http://localhost:8380/predictions/{model_name}/{version}',data = data)
# -*- coding: utf-8 -*-
import requests
import json
text = ['xxxxx']
data = {'data':json.dumps({'text':text})}
print(data)
response = requests.post('http://localhost:8380/predictions/my_model',data = data)
print(response)
if response.status_code==200:vectors = response.json()print(vectors)
参考:
https://blog.51cto.com/u_16213661/8750698
https://blog.csdn.net/wangzitaotao/article/details/131101852
https://pytorch.org/serve/index.html
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/deploy-models-frameworks-torchserve.html