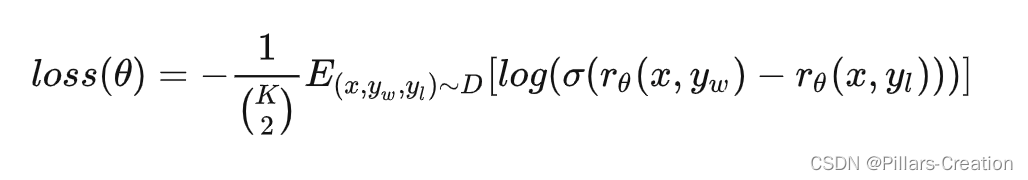目录
- PTQ与QAT
- 注意事项
- 一、2023/5/8更新
- 二、2023/5/12更新
- 前言
- 1. TensorRT量化
- 2. PTQ
- 3. QAT
- 4. QAT实战
- 4.1 环境配置
- 4.2 pytorch_quantization简单示例
- 4.3 自动插入QDQ节点
- 4.4 手动插入QDQ节点
- 4.5 自定义层量化
- 4.6 官方案例
- 总结
PTQ与QAT
注意事项
一、2023/5/8更新
新增手动插入 QDQ 节点即 4.4 小结内容
二、2023/5/12更新
新增自定义层量化即 4.5 小结内容以及官方案例分析即 4.6 小结内容
前言
手写AI推出的全新TensorRT模型量化课程,链接。记录下个人学习笔记,仅供自己参考。
本次课程为第四课,主要讲解PTQ与QAT。这里推荐一篇文章 量化番外篇-TensorRT-8的量化细节 以下大部分内容都是 copy 自它,强烈建议阅读原文!!!
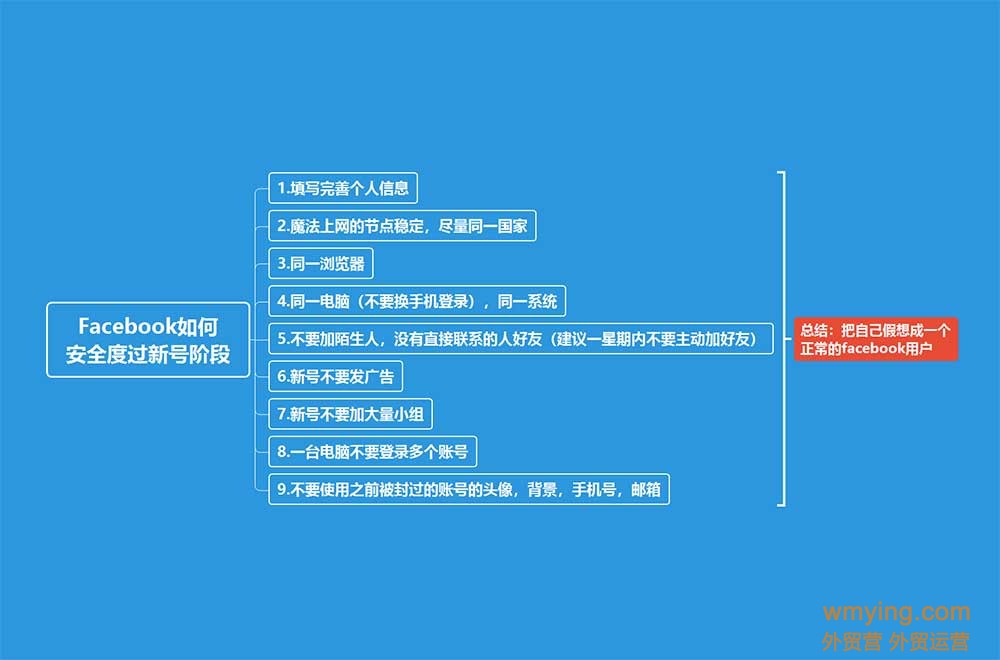
课程大纲可看下面的思维导图

1. TensorRT量化
TensorRT有两种量化模式,分别是 implicitly 以及 explicitly 量化。前者是隐式量化,在 trt7 版本之前用的比较多。而后者是显示量化,在 trt8 版本后才完全支持,具体就是可以加载带有 QDQ 信息的模型然后生成对应量化版本的 engine。
2. PTQ
PTQ(Post-Training Quantization) 即训练后量化也叫隐式量化,tensorRT 的训练后量化算法第一次公布在 2017 年,NVIDIA 放出了使用交叉熵量化的一个 PPT,简单说明了其量化原理和流程,其思想集中在 tensorRT 内部可供用户去使用。对用户是闭源的,我们只能通过 tensorRT 提供的 API 去量化。
PTQ 量化不需要训练,只需要提供一些样本图片,然后在已经训练好的模型上进行校准,统计出来需要的每一层的 scale 就可以实现量化了,大概流程如下:
- 在准备好的校准数据集上评估预训练模型
- 使用校准数据来校准模型(校准数据可以是训练集的子集)
- 计算网络中权重和激活的动态范围用来算出量化参数(q-params)
- 使用 q-params 量化网络并执行推理

具体使用就是我们导出 ONNX 模型,转换为 engine 的过程中使用 tensorRT 提供的 Calibration 方法去校准,这个使用起来比较简单。可以直接使用 tensorRT 官方提供的 trtexec 工具去实现,也可以使用它提供的 Python 或者 C++ 的 API 接口去实现。
目前 tensorRT 提供了多种校准方法,分别适合于不同的任务:
- EntropyCalibratorV2
- 适合于基于 CNN 的网络
Entropy calibration chooses the tensor’s scale factor to optimize the quantized tensor’s information-theoretic content, and usually suppresses outliers in the distribution. This is the current and recommended entropy calibrator and is required for DLA. Calibration happens before Layer fusion by default. It is recommended for CNN-based networks.
- MinMaxCalibrator
- 适合于 NLP 任务,如BERT
This calibrator uses the entire range of the activation distribution to determine the scale factor. It seems to work better for NLP tasks. Calibration happens before Layer fusion by default. This is recommended for networks such as NVIDIA BERT (an optimized version of Google’s official implementation).
- EntropyCalibrator
- 老版的 entropy calibrator
This is the original entropy calibrator. It is less complicated to use than the LegacyCalibrator and typically produces better results. Calibration happens after Layer fusion by default.
- LegacyCalibrator
This calibrator is for compatibility with TensorRT 2.0 EA. This calibrator requires user parameterization and is provided as a fallback option if the other calibrators yield poor results. Calibration happens after Layer fusion by default. You can customize this calibrator to implement percentile max, for example, 99.99% percentile max is observed to have best accuracy for NVIDIA BERT.
通过上述这些校准算法进行 PTQ 量化时,tensorRT 会在优化网络的时候尝试 INT8 精度,假设某一层在 INT8 精度下速度优于默认精度(FP32或者FP16),则有限使用 INT8。
值得注意的是,PTQ 量化中我们无法控制某一层的精度,因为 tensorRT 是以速度优化为优先的,很可能某一层你想让它跑 INT8 结果却是 FP16。当然 PTQ 优点是流程简单,速度快。
3. QAT
QAT(Quantization Aware Training) 即训练中量化也叫显式量化。它是 tensorRT8 的一个新特性,这个特性其实是指 tensorRT 有直接加载 QAT 模型的能力。而 QAT 模型在这里是指包含 QDQ 操作的量化模型,而 QDQ 操作就是指量化和反量化操作。
实际上 QAT 过程和 tensorRT 没有太大关系,tensorRT 只是一个推理框架,实际的训练中量化操作一般都是在训练框架中去做,比如我们熟悉的 Pytorch。(当然也不排除之后一些推理框架也会有训练功能,因此同样可以在推理框架中做)
tensorRT-8 可以显式地加载包含有 QAT 量化信息的 ONNX 模型,实现一系列优化后,可以生成 INT8 的 engine。
QAT 量化需要插入 QAT 算子且需要训练进行微调,大概流程如下
- 准备一个预训练模型
- 在模型中添加 QAT 算子
- 微调带有 QAT 算子的模型
- 将微调后模型的量化参数即 q-params 存储下来
- 量化模型执行推理

带有 QAT 量化信息的模型如下图所示:

从上图中我们可以看到带 QAT 量化信息的模型中有 QuantizeLinear 和 DequantizeLinear 模块,也就是对应的 QDQ 模块,它包含了该层和该激活值的量化 scale 和 zero-point。什么是 QDQ 呢?QDQ 其实就是 Q(量化) 和 DQ(反量化)两个 op,在网络中通常作为模拟量化的 op,如下图所示:

QDQ 模块会参与训练,负责将输入的 FP32 张量量化为 INT8,随后再进行反量化将 INT8 的张量再变为 FP32。值得注意的是,实际网络中训练使用的精度还是 FP32,只不过这个量化算子在训练中可以学习到量化和反量化的尺度信息,这样训练的时候就可以让模型权重和量化参数更好地适应量化过程(scale参数也是可以学习的),量化后地精度也相对更高一些。
QAT 量化中最重要的就是 FQ(Fake-Quan) 量化算子即 QDQ 算子,它负责将输入该算子的参数先进行量化操作然后进行反量化操作,记录其中的 scale,具体可见下图3-4
假设现在我们有一个网络,其精度是 FP32 即输入和权重是 FP32:

我们可以在模型中插入 FQ 算子,它会将 FP32 精度的输入和权重转化为 INT8 再转回 FP32,并记住转换过程中的尺度信息:

而这些 FQ 算子在 ONNX 模型中可以表示为 QDQ 算子:

那么 QDQ 算子到底做了什么事情呢?其实就是我们之前提到的量化和反量化过程,假设输入为 3x3,其 QDQ 算子会做如下计算:

QDQ 的用途主要体现在两方面:
- 第一个是可以存储量化信息,比如 scale 和 zero_point,这些信息可以放在 Q 和 DQ 操作中
- 第二个是可以当作是显示指定哪一层是量化层,我们可以默认认为包在 QDQ 操作中间的 op 都是 INT8 类型的 op,也就是我们需要量化的 op
比如下图,可以通过 QDQ 的位置来决定每一层 op 的精度:

因此对比显式量化(explicitly),tensorRT的隐式量化(implicitly)就没有那么直接,在 tensorRT-8 版本之前我们一般都是借助 tensorRT 的内部量化算法去量化(闭源),在构建 engine 的时候传入图像进行校准,执行的是训练后量化(PTQ)的过程。
而有了 QDQ 信息,tensorRT 在解析模型的时候会根据 QDQ 的位置找到可量化的 op,然后与 QDQ 融合(吸收尺度信息到 op 中):

融合后的算子就是实打实的 INT8 算子,经过一系列的融合优化后,最终生成量化版的 engine:

总的来说,tensorRT 加载 QAT 的 ONNX 模型并进行优化的总体流程如下:

因为 tensorRT8 可以直接加载通过 QAT 量化后导出为 onnx 的模型,官方也提供了 Pytorch 量化配套工具,可谓是一步到位。
tensorRT 的量化性能是非常好的,可能有些模型或者 op 已经被其他库超越(比如openppl或者tvm),不过tensorRT 胜在支持的比较广泛,用户很多,大部分模型都有前人踩过坑,经验相对较多些,而且支持动态 shape,适用的场景也较多。
不过 tensorRT 也有缺点,就是自定义的 INT8 插件支持度不高,很多坑要踩,也就是自己添加新的 op 难度稍大一些。对于某些层不支持或者有 bug 的情况,除了在 issue 中催一下官方尽快更新之外,也没有其它办法了。
4. QAT实战
4.1 环境配置
本次代码参考自https://github.com/NVIDIA/TensorRT/tree/release/8.6/tools/pytorch-quantization
需要安装 pytorch-quantization 包来用于后续的工作,安装指令如下:
pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com
4.2 pytorch_quantization简单示例
我们利用 pytorch-quantization 第三方库来写一个简单的示例,其代码如下:
from pytorch_quantization import tensor_quant
import torchtorch.manual_seed(123456)
x = torch.rand(10)
fake_x = tensor_quant.fake_tensor_quant(x, x.abs().max()) # FQ算子
print(x)
print(fake_x)
其输出如下:
tensor([0.5043, 0.8178, 0.4798, 0.9201, 0.6819, 0.6900, 0.6925, 0.3804, 0.4479,0.4954])
tensor([0.5071, 0.8187, 0.4782, 0.9201, 0.6810, 0.6883, 0.6955, 0.3840, 0.4492,0.4927])
上述示例代码利用 tensor_quant 模块中的 fake_tensor_quant 函数对输入的 tensor 进行 FQ 操作,即 QDQ 操作,其内部的具体实现就是我们之前课程中提到的对称量化.
4.3 自动插入QDQ节点
我们使用 pytorch-quantization 的 API 来实现对 resnet 网络所有节点的 QDQ 算子插入,其示例代码如下:
import torch
import torchvision
from pytorch_quantization import tensor_quant, quant_modules
from pytorch_quantization import nn as quant_nnquant_modules.initialize()model = torchvision.models.resnet18()
model.cuda()inputs = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant = True
torch.onnx.export(model, inputs, 'quant_resnet18.onnx', opset_version=13)
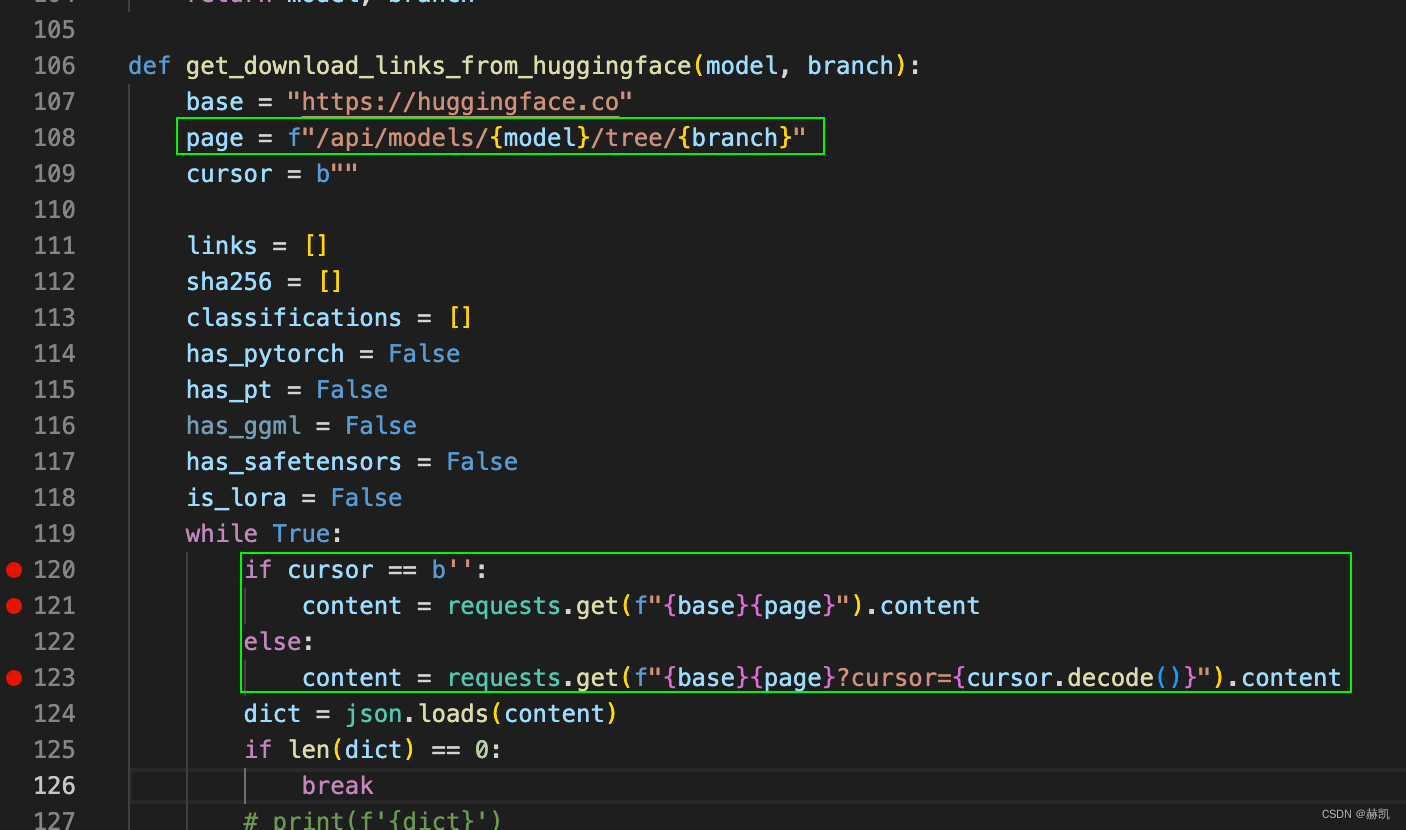
上述示例代码通过指定 quant_nn.TensorQuantizer.use_fb_fake_quant 来将 resnet18 模型中的所有节点替换为 QDQ 算子,并导出为 ONNX 格式的模型文件,实现了模型的量化。值得注意的是:
quant_modules.initialize()函数会把 PyTorch-Quantization 库中所有的量化算子按照数据类型、位宽等特性进行分类,并将其保存在全局变量_DEFAULT_QUANT_MAP中- 导出的带有 QDQ 节点的 ONNX 模型中,对于输入 input 的整个 tensor 是共用一个 scale,而对于权重 weight 则是每个 channel 共用一个 scale
- 导出的带有 QDQ 节点的 ONNX 模型中,
x_zero_point是之前量化课程中提到的偏移量,其值为0,因为整个量化过程是对称量化,其偏移量 Z 为0
4.4 手动插入QDQ节点
在上节课中我们讲到了 PTQ 与 QAT 的介绍,手写了一个程序利用 pytorch-quantization 对 resnet50 网络自动插入 QDQ 节点,并导出 ONNX。这节课我们来学习定制化的操作,根据我们的需求手动插入 QDQ 节点。
在学习本课之前,我们先来对 TensorRT 量化方式做一个总结,TensorRT 量化可分为隐式量化和显示量化两种
隐式量化
- trt7 版本之前
- 只具备 PTQ 一种量化形式
- 各层精度不可控
显示量化
- trt8 版本之后
- 支持带 QDQ 节点的 PTQ 以及 支持带 QDQ 节点的 QAT 两种量化形式
- 带 QDQ 节点的 PTQ 是没有进行 Finetune 的,只是插入了对应的 QDQ 节点
- 带 QDQ 节点的 QAT 是进行了 Finetune 的
- 显示量化是必须带 QDQ 节点的
- 各层精度可控
如果某些层量化后对整体精度影响大,我们不希望该层插入 QDQ 节点,而是正常用 FP16 去跑,我们应该如何去做控制呢?
在上节课中使用 quant_modules.initialize() 自动插入 QDQ 节点,如何使能某些层插入 QDQ 节点,某些层不插入 QDQ 节点呢?在代码层面我们通过 disable_quantization 以及 enable_quantization 两个类来进行控制。示例代码如下:
import torch
import torchvision
from pytorch_quantization import tensor_quant
from pytorch_quantization import quant_modules
from pytorch_quantization import nn as quant_nn
from pytorch_quantization.nn.modules import _utils as quant_nn_utils
from pytorch_quantization import calib
from typing import List, Callable, Union, Dictclass disable_quantization:def __init__(self, model):self.model = modeldef apply(self, disabled=True):for name, module in self.model.named_modules():if isinstance(module, quant_nn.TensorQuantizer):module._disabled = disableddef __enter__(self):self.apply(True) def __exit__(self, *args, **kwargs):self.apply(False)class enable_quantization:def __init__(self, model):self.model = modeldef apply(self, enabled=True):for name, module in self.model.named_modules():if isinstance(module, quant_nn.TensorQuantizer):module._disabled = not enableddef __enter__(self):self.apply(True)return selfdef __exit__(self, *args, **kwargs):self.apply(False)def quantizer_state(module):for name, module in module.named_modules():if isinstance(module, quant_nn.TensorQuantizer):print(name, module)quant_modules.initialize() # 对整个模型进行量化
model = torchvision.models.resnet50()
model.cuda()disable_quantization(model.conv1).apply() # 关闭某个节点的量化
# enable_quantization(model.conv1).apply() # 开启某个节点的量化
inputs = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant = True
torch.onnx.export(model, inputs, 'quant_resnet50_disabelconv1.onnx', opset_version=13)
上述示例代码演示了如何在 Pytorch 中开启或禁用量化器(Quantizer)对指定节点的量化过程。
我们对模型的 conv1 模块禁用量化器对该模块的量化,在导出的 ONNX 模型中可以看到该节点没有被插入 QDQ 节点量化
以 Conv 层为例,量化前后模型的属性会发生变化。量化后的 Conv 层会在原有属性的基础上新增两个属性即 input_quantizer 以及 weight_quantizer,用于记录输入和权重的量化信息。而量化后的 Conv 层属于 quant_nn.TensorQuantizer 类型,表示这个层被量化了。而在 TensorQuantizer 类中是通过 _disabled 这个属性来控制是否进行量化的,因此我们就可以利用这个属性来控制某些层是否插入 QDQ 节点。
之前我们提到对整个模型插入 QDQ 节点我们是通过 quant_modules.initialize() 来实现的,我们能否自定义实现整个模型的 QDQ 节点插入呢?而不用上述方法,官方提供的接口可控性、灵活度较差,我们自己来实现整个过程。示例代码如下:
import torch
import torchvision
from pytorch_quantization import tensor_quant
from pytorch_quantization import quant_modules
from pytorch_quantization import nn as quant_nn
from pytorch_quantization.nn.modules import _utils as quant_nn_utils
from pytorch_quantization import calib
from typing import List, Callable, Union, Dictdef transfer_torch_to_quantization(nninstace : torch.nn.Module, quantmodule):quant_instance = quantmodule.__new__(quantmodule)for k, val in vars(nninstace).items():setattr(quant_instance, k, val) # 继承所有的属性def __init__(self):if isinstance(self, quant_nn_utils.QuantInputMixin): # 只有input,没有weightquant_desc_input = quant_nn_utils.pop_quant_desc_in_kwargs(self.__class__, input_only=True)self.init_quantizer(quant_desc_input)# Turn on torch hist to enable higher calibration speedsif isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):self._input_quantizer._calibrator._torch_hist = Trueelse:quant_desc_input, quant_desc_weight = quant_nn_utils.pop_quant_desc_in_kwargs(self.__class__)self.init_quantizer(quant_desc_input, quant_desc_weight)# Turn on torch_hist to enable higher calibration speedsif isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):self._input_quantizer._calibrator._torch_hist = True # 提速self._weight_quantizer._calibrator._torch_hist = True #__init__(quant_instance)return quant_instancedef replace_to_quantization_module(model : torch.nn.Module, ignore_policy : Union[str, List[str], Callable] = None):module_dict = {}for entry in quant_modules._DEFAULT_QUANT_MAP:module = getattr(entry.orig_mod, entry.mod_name)module_dict[id(module)] = entry.replace_moddef recursive_and_replace_module(module, prefix=""):for name in module._modules:submodule = module._modules[name]path = name if prefix == "" else prefix + "." + namerecursive_and_replace_module(submodule, path)submodule_id = id(type(submodule))if submodule_id in module_dict:module._modules[name] = transfer_torch_to_quantization(submodule, module_dict[submodule_id])recursive_and_replace_module(model)# quant_modules.initialize() # 如何实现自定义QDQ节点插入?
model = torchvision.models.resnet50()
model.cuda()replace_to_quantization_module(model)
inputs = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant = True
torch.onnx.export(model, inputs, 'quant_resnet50_replace_to_quantization.onnx', opset_version=13)
上述示例代码实现了自定义整个模型的 QDQ 节点插入。主要包括两个函数即 transfer_torch_to_quantization 和 replace_to_quantization_module。(from chatGPT)
其中,replace_to_quantization_module 函数的作用是将原始模型中的指定层替换成对应的量化层,并返回替换后的模型。具体来说,该函数遍历整个模型的层,如果当前层是被替换层,则调用 transfer_torch_to_quantization 函数将其转换为量化层。
transfer_torch_to_quantization 函数的作用是将原始模型的一个层转换成对应的量化层。该函数首先创建一个新的量化层实例 quant_instance,然后将原始层的所有属性复制到这个实例中。接着根据不同的 OP 算子类型来进行初始化,具体根据原始层是否有 weight,来初始化 quant_instance 的 input_quantizer 和 weight_quantizer 两个属性。最后,将 quant_instance 返回。
这两个函数的组合实现了一个自定义的 QDQ 节点插入函数,它不依赖于 quant_modules.initialize() 接口,而是通过遍历模型层并替换成对应的量化层来实现。如果你想只让某些层进行量化,则可以加入一些过滤条件,通过这样的方式灵活控制,实现手动插入 QDQ 节点。
上述代码中将 self._weight_quantizer._calibrator._torch_hist 设置为 True 是为了提高权重量化时的校准速度。当使用直方图来确定数据分布时,由于直方图的计算量较大,所以开启 _torch_hist 可以使用 PyTorch 内置的直方图函数来提高校准速度。因此,当使用 HistogramCalibrator 进行校准时,将 _torch_hist 设置为 True 可以提高校准速度。(from chatGPT)
完整的示例代码如下:
import torch
import torchvision
from pytorch_quantization import tensor_quant
from pytorch_quantization import quant_modules
from pytorch_quantization import nn as quant_nn
from pytorch_quantization.nn.modules import _utils as quant_nn_utils
from pytorch_quantization import calib
from typing import List, Callable, Union, Dictclass disable_quantization:def __init__(self, model):self.model = modeldef apply(self, disabled=True):for name, module in self.model.named_modules():if isinstance(module, quant_nn.TensorQuantizer):module._disabled = disableddef __enter__(self):self.apply(True) def __exit__(self, *args, **kwargs):self.apply(False)class enable_quantization:def __init__(self, model):self.model = modeldef apply(self, enabled=True):for name, module in self.model.named_modules():if isinstance(module, quant_nn.TensorQuantizer):module._disabled = not enableddef __enter__(self):self.apply(True)return selfdef __exit__(self, *args, **kwargs):self.apply(False)def quantizer_state(module):for name, module in module.named_modules():if isinstance(module, quant_nn.TensorQuantizer):print(name, module)# 48
def transfer_torch_to_quantization(nninstace : torch.nn.Module, quantmodule):quant_instance = quantmodule.__new__(quantmodule)for k, val in vars(nninstace).items():setattr(quant_instance, k, val) # 继承所有的属性def __init__(self):if isinstance(self, quant_nn_utils.QuantInputMixin): # 只有input,没有weightquant_desc_input = quant_nn_utils.pop_quant_desc_in_kwargs(self.__class__, input_only=True)self.init_quantizer(quant_desc_input)# Turn on torch hist to enable higher calibration speedsif isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):self._input_quantizer._calibrator._torch_hist = Trueelse:quant_desc_input, quant_desc_weight = quant_nn_utils.pop_quant_desc_in_kwargs(self.__class__)self.init_quantizer(quant_desc_input, quant_desc_weight)# Turn on torch_hist to enable higher calibration speedsif isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):self._input_quantizer._calibrator._torch_hist = True # 提速self._weight_quantizer._calibrator._torch_hist = True #__init__(quant_instance)return quant_instance# 76
def replace_to_quantization_module(model : torch.nn.Module, ignore_policy : Union[str, List[str], Callable] = None):module_dict = {}for entry in quant_modules._DEFAULT_QUANT_MAP:module = getattr(entry.orig_mod, entry.mod_name)module_dict[id(module)] = entry.replace_moddef recursive_and_replace_module(module, prefix=""):for name in module._modules:submodule = module._modules[name]path = name if prefix == "" else prefix + "." + namerecursive_and_replace_module(submodule, path)submodule_id = id(type(submodule))if submodule_id in module_dict:module._modules[name] = transfer_torch_to_quantization(submodule, module_dict[submodule_id])recursive_and_replace_module(model)# quant_modules.initialize() # 如何自定义插入
model = torchvision.models.resnet50()
model.cuda()
disable_quantization(model.conv1).apply() # 关闭某个节点的量化
# quantizer_state(model)
replace_to_quantization_module(model)
inputs = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant = True
torch.onnx.export(model, inputs, 'quant_resnet50_replace_to_quantization.onnx', opset_version=13)
4.5 自定义层量化
上节课我们讲到了一些通用的层如 Conv、BN、ReLU 等手动插入 QDQ 节点,这节课我们来学习对自定义层手动插入 QDQ 节点
自定义层分为两种,一种是只有 input 另一种是包含 input 和 weight
下面是只包含 input 自定义层 MultiAdd 量化的示例代码:
import torch
from pytorch_quantization import nn as quant_nn
from pytorch_quantization.tensor_quant import QuantDescriptorclass QuantMultiAdd(torch.nn.Module):def __init__(self):super().__init__()self._input_quantizer = quant_nn.TensorQuantizer(QuantDescriptor(num_bits=8, calib_method="histgoram"))def forward(self, x, y, z):return self._input_quantizer(x) + self._input_quantizer(y) + self._input_quantizer(z)model = QuantMultiAdd()
model.cuda()
input_a = torch.randn(1, 3, 224, 224, device='cuda')
input_b = torch.randn(1, 3, 224, 224, device='cuda')
input_c = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant = True
torch.onnx.export(model, (input_a, input_b, input_c), 'quantMultiAdd.onnx', opset_version=13)
在上述示例代码中,首先定义了 QuantMultiAdd 自定义层,它包含一个输入量化器 _input_quantizer 基于 pytorch_quantization 库中的 TensorQuantizer 类来创建的,使用 8 位量化位数,并采用直方图作为校准方法进行模型量化,然后在前向传播过程中,将三个输入都通过输入量化器进行量化操作,并返回它们的量化结果之和。

4.6 官方案例
我们来对官方的案例进行一个分析,对整个 pipeline 有一个总体的把握
官方案例:https://github.com/NVIDIA/TensorRT/blob/release/8.6/tools/pytorch-quantization/examples/torchvision/classification_flow.py
该官方案例整体流程如下:
- 定义我们的模型
- 对模型插入 QDQ 节点
- 统计 QDQ 节点的 range 和 scale
- 做敏感层分析
- 需要知道,那个层对精度指标影响较大,关闭对精度影响较大的层
- 导出一个带有 QDQ 节点的 PTQ 模型
- 对模型进行 finetune
#
# SPDX-FileCopyrightText: Copyright (c) 1993-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#import datetime
import os
import sys
import time
import argparse
import warnings
import collectionsimport torch
import torch.utils.data
from torch import nnfrom tqdm import tqdmimport torchvision
from torchvision import transforms
from torch.hub import load_state_dict_from_urlfrom pytorch_quantization import nn as quant_nn
from pytorch_quantization import calib
from pytorch_quantization.tensor_quant import QuantDescriptor
from pytorch_quantization import quant_modulesimport onnxruntime
import numpy as np
import models.classification as modelsfrom prettytable import PrettyTable# The following path assumes running in nvcr.io/nvidia/pytorch:20.08-py3
sys.path.insert(0,"/opt/pytorch/vision/references/classification/")# Import functions from torchvision reference
try:from train import evaluate, train_one_epoch, load_data, utils
except Exception as e:raise ModuleNotFoundError("Add https://github.com/pytorch/vision/blob/master/references/classification/ to PYTHONPATH")def get_parser():"""Creates an argument parser."""parser = argparse.ArgumentParser(description='Classification quantization flow script')parser.add_argument('--data-dir', '-d', type=str, help='input data folder', required=True)parser.add_argument('--model-name', '-m', default='resnet50', help='model name: default resnet50')parser.add_argument('--disable-pcq', '-dpcq', action="store_true", help='disable per-channel quantization for weights')parser.add_argument('--out-dir', '-o', default='/tmp', help='output folder: default /tmp')parser.add_argument('--print-freq', '-pf', type=int, default=20, help='evaluation print frequency: default 20')parser.add_argument('--threshold', '-t', type=float, default=-1.0, help='top1 accuracy threshold (less than 0.0 means no comparison): default -1.0')parser.add_argument('--batch-size-train', type=int, default=128, help='batch size for training: default 128')parser.add_argument('--batch-size-test', type=int, default=128, help='batch size for testing: default 128')parser.add_argument('--batch-size-onnx', type=int, default=1, help='batch size for onnx: default 1')parser.add_argument('--seed', type=int, default=12345, help='random seed: default 12345')checkpoint = parser.add_mutually_exclusive_group(required=True)checkpoint.add_argument('--ckpt-path', default='', type=str,help='path to latest checkpoint (default: none)')checkpoint.add_argument('--ckpt-url', default='', type=str,help='url to latest checkpoint (default: none)')checkpoint.add_argument('--pretrained', action="store_true")parser.add_argument('--num-calib-batch', default=4, type=int,help='Number of batches for calibration. 0 will disable calibration. (default: 4)')parser.add_argument('--num-finetune-epochs', default=0, type=int,help='Number of epochs to fine tune. 0 will disable fine tune. (default: 0)')parser.add_argument('--calibrator', type=str, choices=["max", "histogram"], default="max")parser.add_argument('--percentile', nargs='+', type=float, default=[99.9, 99.99, 99.999, 99.9999])parser.add_argument('--sensitivity', action="store_true", help="Build sensitivity profile")parser.add_argument('--evaluate-onnx', action="store_true", help="Evaluate exported ONNX")return parserdef prepare_model(model_name,data_dir,per_channel_quantization,batch_size_train,batch_size_test,batch_size_onnx,calibrator,pretrained=True,ckpt_path=None,ckpt_url=None):"""Prepare the model for the classification flow.Arguments:model_name: name to use when accessing torchvision model dictionarydata_dir: directory with train and val subdirs prepared "imagenet style"per_channel_quantization: iff true use per channel quantization for weightsnote that this isn't currently supported in ONNX-RT/Pytorchbatch_size_train: batch size to use when trainingbatch_size_test: batch size to use when testing in Pytorchbatch_size_onnx: batch size to use when testing with ONNX-RTcalibrator: calibration type to use (max/histogram)pretrained: if true a pretrained model will be loaded from torchvisionckpt_path: path to load a model checkpoint from, if not pretrainedckpt_url: url to download a model checkpoint from, if not pretrained and no path was given* at least one of {pretrained, path, url} must be validThe method returns a the following list:[Model object,data loader for training,data loader for Pytorch testing,data loader for onnx testing]"""# Use 'spawn' to avoid CUDA reinitialization with forked subprocesstorch.multiprocessing.set_start_method('spawn')## Initialize quantization, model and data loadersif per_channel_quantization:quant_desc_input = QuantDescriptor(calib_method=calibrator)quant_nn.QuantConv2d.set_default_quant_desc_input(quant_desc_input)quant_nn.QuantLinear.set_default_quant_desc_input(quant_desc_input)else:## Force per tensor quantization for onnx runtimequant_desc_input = QuantDescriptor(calib_method=calibrator, axis=None)quant_nn.QuantConv2d.set_default_quant_desc_input(quant_desc_input)quant_nn.QuantConvTranspose2d.set_default_quant_desc_input(quant_desc_input)quant_nn.QuantLinear.set_default_quant_desc_input(quant_desc_input)quant_desc_weight = QuantDescriptor(calib_method=calibrator, axis=None)quant_nn.QuantConv2d.set_default_quant_desc_weight(quant_desc_weight)quant_nn.QuantConvTranspose2d.set_default_quant_desc_weight(quant_desc_weight)quant_nn.QuantLinear.set_default_quant_desc_weight(quant_desc_weight)if model_name in models.__dict__:model = models.__dict__[model_name](pretrained=pretrained, quantize=True)else:quant_modules.initialize()model = torchvision.models.__dict__[model_name](pretrained=pretrained)quant_modules.deactivate()if not pretrained:if ckpt_path:checkpoint = torch.load(ckpt_path)else:checkpoint = load_state_dict_from_url(ckpt_url)if 'state_dict' in checkpoint.keys():checkpoint = checkpoint['state_dict']elif 'model' in checkpoint.keys():checkpoint = checkpoint['model']model.load_state_dict(checkpoint)model.eval()model.cuda()## Prepare the data loaderstraindir = os.path.join(data_dir, 'train')valdir = os.path.join(data_dir, 'val')_args = collections.namedtuple("mock_args", ["model", "distributed", "cache_dataset"])dataset, dataset_test, train_sampler, test_sampler = load_data(traindir, valdir, _args(model=model_name, distributed=False, cache_dataset=False))data_loader_train = torch.utils.data.DataLoader(dataset, batch_size=batch_size_train,sampler=train_sampler, num_workers=4, pin_memory=True)data_loader_test = torch.utils.data.DataLoader(dataset_test, batch_size=batch_size_test,sampler=test_sampler, num_workers=4, pin_memory=True)data_loader_onnx = torch.utils.data.DataLoader(dataset_test, batch_size=batch_size_onnx,sampler=test_sampler, num_workers=4, pin_memory=True)return model, data_loader_train, data_loader_test, data_loader_onnxdef main(cmdline_args):parser = get_parser()args = parser.parse_args(cmdline_args)print(parser.description)print(args)torch.manual_seed(args.seed)np.random.seed(args.seed)## Prepare the pretrained model and data loadersmodel, data_loader_train, data_loader_test, data_loader_onnx = prepare_model(args.model_name,args.data_dir,not args.disable_pcq,args.batch_size_train,args.batch_size_test,args.batch_size_onnx,args.calibrator,args.pretrained,args.ckpt_path,args.ckpt_url)## Initial accuracy evaluationcriterion = nn.CrossEntropyLoss()with torch.no_grad():print('Initial evaluation:')top1_initial = evaluate(model, criterion, data_loader_test, device="cuda", print_freq=args.print_freq)## Calibrate the modelwith torch.no_grad():calibrate_model(model=model,model_name=args.model_name,data_loader=data_loader_train,num_calib_batch=args.num_calib_batch,calibrator=args.calibrator,hist_percentile=args.percentile,out_dir=args.out_dir)## Evaluate after calibrationif args.num_calib_batch > 0:with torch.no_grad():print('Calibration evaluation:')top1_calibrated = evaluate(model, criterion, data_loader_test, device="cuda", print_freq=args.print_freq)else:top1_calibrated = -1.0## Build sensitivy profileif args.sensitivity:build_sensitivity_profile(model, criterion, data_loader_test)## Finetune the modelcriterion = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.0001)lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, args.num_finetune_epochs)for epoch in range(args.num_finetune_epochs):# Training a single epchtrain_one_epoch(model, criterion, optimizer, data_loader_train, "cuda", 0, 100)lr_scheduler.step()if args.num_finetune_epochs > 0:## Evaluate after finetuningwith torch.no_grad():print('Finetune evaluation:')top1_finetuned = evaluate(model, criterion, data_loader_test, device="cuda")else:top1_finetuned = -1.0## Export to ONNXonnx_filename = args.out_dir + '/' + args.model_name + ".onnx"top1_onnx = -1.0if export_onnx(model, onnx_filename, args.batch_size_onnx, not args.disable_pcq) and args.evaluate_onnx:## Validate ONNX and evaluatetop1_onnx = evaluate_onnx(onnx_filename, data_loader_onnx, criterion, args.print_freq)## Print summaryprint("Accuracy summary:")table = PrettyTable(['Stage','Top1'])table.align['Stage'] = "l"table.add_row( [ 'Initial', "{:.2f}".format(top1_initial) ] )table.add_row( [ 'Calibrated', "{:.2f}".format(top1_calibrated) ] )table.add_row( [ 'Finetuned', "{:.2f}".format(top1_finetuned) ] )table.add_row( [ 'ONNX', "{:.2f}".format(top1_onnx) ] )print(table)## Compare resultsif args.threshold >= 0.0:if args.evaluate_onnx and top1_onnx < 0.0:print("Failed to export/evaluate ONNX!")return 1if args.num_finetune_epochs > 0:if top1_finetuned >= (top1_onnx - args.threshold):print("Accuracy threshold was met!")else:print("Accuracy threshold was missed!")return 1return 0def evaluate_onnx(onnx_filename, data_loader, criterion, print_freq):"""Evaluate accuracy on the given ONNX file using the provided data loader and criterion.The method returns the average top-1 accuracy on the given dataset."""print("Loading ONNX file: ", onnx_filename)ort_session = onnxruntime.InferenceSession(onnx_filename)with torch.no_grad():metric_logger = utils.MetricLogger(delimiter=" ")header = 'Test:'with torch.no_grad():for image, target in metric_logger.log_every(data_loader, print_freq, header):image = image.to("cpu", non_blocking=True)image_data = np.array(image)input_data = image_data# run the data through onnx runtime instead of torch modelinput_name = ort_session.get_inputs()[0].nameraw_result = ort_session.run([], {input_name: input_data})output = torch.tensor((raw_result[0]))loss = criterion(output, target)acc1, acc5 = utils.accuracy(output, target, topk=(1, 5))batch_size = image.shape[0]metric_logger.update(loss=loss.item())metric_logger.meters['acc1'].update(acc1.item(), n=batch_size)metric_logger.meters['acc5'].update(acc5.item(), n=batch_size)# gather the stats from all processesmetric_logger.synchronize_between_processes()print(' ONNXRuntime: Acc@1 {top1.global_avg:.3f} Acc@5 {top5.global_avg:.3f}'.format(top1=metric_logger.acc1, top5=metric_logger.acc5))return metric_logger.acc1.global_avgdef export_onnx(model, onnx_filename, batch_onnx, per_channel_quantization):model.eval()quant_nn.TensorQuantizer.use_fb_fake_quant = True # We have to shift to pytorch's fake quant ops before exporting the model to ONNXif per_channel_quantization:opset_version = 13else:opset_version = 12# Export ONNX for multiple batch sizesprint("Creating ONNX file: " + onnx_filename)dummy_input = torch.randn(batch_onnx, 3, 224, 224, device='cuda') #TODO: switch input dims by modeltry:torch.onnx.export(model, dummy_input, onnx_filename, verbose=False, opset_version=opset_version, enable_onnx_checker=False, do_constant_folding=True)except ValueError:warnings.warn(UserWarning("Per-channel quantization is not yet supported in Pytorch/ONNX RT (requires ONNX opset 13)"))print("Failed to export to ONNX")return Falsereturn Truedef calibrate_model(model, model_name, data_loader, num_calib_batch, calibrator, hist_percentile, out_dir):"""Feed data to the network and calibrate.Arguments:model: classification modelmodel_name: name to use when creating state filesdata_loader: calibration data setnum_calib_batch: amount of calibration passes to performcalibrator: type of calibration to use (max/histogram)hist_percentile: percentiles to be used for historgram calibrationout_dir: dir to save state files in"""if num_calib_batch > 0:print("Calibrating model")with torch.no_grad():collect_stats(model, data_loader, num_calib_batch)if not calibrator == "histogram":compute_amax(model, method="max")calib_output = os.path.join(out_dir,F"{model_name}-max-{num_calib_batch*data_loader.batch_size}.pth")torch.save(model.state_dict(), calib_output)else:for percentile in hist_percentile:print(F"{percentile} percentile calibration")compute_amax(model, method="percentile")calib_output = os.path.join(out_dir,F"{model_name}-percentile-{percentile}-{num_calib_batch*data_loader.batch_size}.pth")torch.save(model.state_dict(), calib_output)for method in ["mse", "entropy"]:print(F"{method} calibration")compute_amax(model, method=method)calib_output = os.path.join(out_dir,F"{model_name}-{method}-{num_calib_batch*data_loader.batch_size}.pth")torch.save(model.state_dict(), calib_output)def collect_stats(model, data_loader, num_batches):"""Feed data to the network and collect statistics"""# Enable calibratorsfor name, module in model.named_modules():if isinstance(module, quant_nn.TensorQuantizer):if module._calibrator is not None:module.disable_quant()module.enable_calib()else:module.disable()# Feed data to the network for collecting statsfor i, (image, _) in tqdm(enumerate(data_loader), total=num_batches):model(image.cuda())if i >= num_batches:break# Disable calibratorsfor name, module in model.named_modules():if isinstance(module, quant_nn.TensorQuantizer):if module._calibrator is not None:module.enable_quant()module.disable_calib()else:module.enable()def compute_amax(model, **kwargs):# Load calib resultfor name, module in model.named_modules():if isinstance(module, quant_nn.TensorQuantizer):if module._calibrator is not None:if isinstance(module._calibrator, calib.MaxCalibrator):module.load_calib_amax()else:module.load_calib_amax(**kwargs)print(F"{name:40}: {module}")model.cuda()def build_sensitivity_profile(model, criterion, data_loader_test):quant_layer_names = []for name, module in model.named_modules():if name.endswith("_quantizer"):module.disable()layer_name = name.replace("._input_quantizer", "").replace("._weight_quantizer", "")if layer_name not in quant_layer_names:quant_layer_names.append(layer_name)for i, quant_layer in enumerate(quant_layer_names):print("Enable", quant_layer)for name, module in model.named_modules():if name.endswith("_quantizer") and quant_layer in name:module.enable()print(F"{name:40}: {module}")with torch.no_grad():evaluate(model, criterion, data_loader_test, device="cuda")for name, module in model.named_modules():if name.endswith("_quantizer") and quant_layer in name:module.disable()print(F"{name:40}: {module}")if __name__ == '__main__':res = main(sys.argv[1:])exit(res)
在上面的示例代码中,首先利用 pytorch-quantization 对加载的预训练模型进行 QDQ 节点的插入,然后对模型进行校准,统计 QDQ 节点的 range 和 scale,通过调用 collect_stats 函数对模型的量化节点进行统计。该函数会遍历模型中的量化节点,并根据给定的数据加载器,对一定数量的批次数据进行前向传播,收集统计信息,包括最大值、最小值等。这些统计信息用于后续的量化参数计算
接下来我们会通过调用 build_sensitivity_profile 函数进行敏感层分析。该函数针对每个量化层,在模型中启动该层,然后再测试数据上进行评估。评估结果可以帮助判断哪些层对精度影响较大,从而可以选择关那些对精度影响较大的层
最后使用 SGD 优化器对进行微调,调用 export_onnx 函数将带有 QDQ 节点的模型导出为ONNX格式
总结
本次课程介绍了 tensorRT 中两种量化模式即 PTQ 和 QAT,其中 PTQ 为训练后量化,在 tensorRT-7 版本之前比较流行,它主要通过校准方法利用校准数据对预训练后的模型进行量化,其流程简单、速度快,但是我们无法控制某一层的精度。QAT 为训练后量化,是 tensorRT-8 的一个新特性,即通过在训练过程中插入 QDQ 节点,然后量化过程中使用 QDQ 节点的 scale 等信息完成量化过程,QAT 量化较为麻烦,需要插入 QDQ 节点还需要微调,但是它的精度损失小且能够控制每一层的精度。
接着我们利用 pytorch-quantization 第三方库实现了对 resnet 网络自动插入 QDQ 节点,其中内部的整个量化过程其实就是我们之前课程中讲到的知识,包括对称量化、非对称量化,动态范围的选取等等,掌握之前的知识有利于我们更快的理解其 API 原理的实现,而不是仅仅做一个调包侠😂
然后我们利用 _disabled 属性实现了控制某些层是否需要量化,并自定义实现了对整个模型的 QDQ 节点插入,而不去使用官方的 API
接下来我们对自定义层进行了量化,所有的自定义层可以分为只含义 input 以及 既包含 input 又包含 weight 两种,在前向传播过程中对 input 和 weight 分别进行量化即可。我们还对官方案例进行了分析,主要熟悉了解整个 pipeline,方便后续进行量化工作整个 pytorch 的 quantization 的介绍基本上就已经完成了,下次课程会对工程实际应用中存在的量化问题做一个总结,期待下次课程!!!😄