选型
大数据平台选型有三种选择:
1、使用云平台,优点是建设周期短、运维成本低,缺点费用贵、数据安全性;
2、使用商业化的大数据平台,优点搭建部署方便、稳定性好,缺点是成本高、不够灵活;
3、自己造轮子,优点就是根据需要定制部署,缺点周期长、成本高、坑特别多。
公司高层视数据如命,使用公有云平台是不可能的,大数据团队刚建成、预算不足,只能走向自主建设这条艰辛路。经历了大数据平台从有到无,功能越来越完善,稳定性和性能逐步提升,支持的业务越来越多。体会到自主建设一个生产级别的大数据平台,要踩了很多坑。所以记录一下大数据平台的技术演进历程,一来用于总结经验,二来也给其他正准备自己建设大数据平台的同学提供参考。
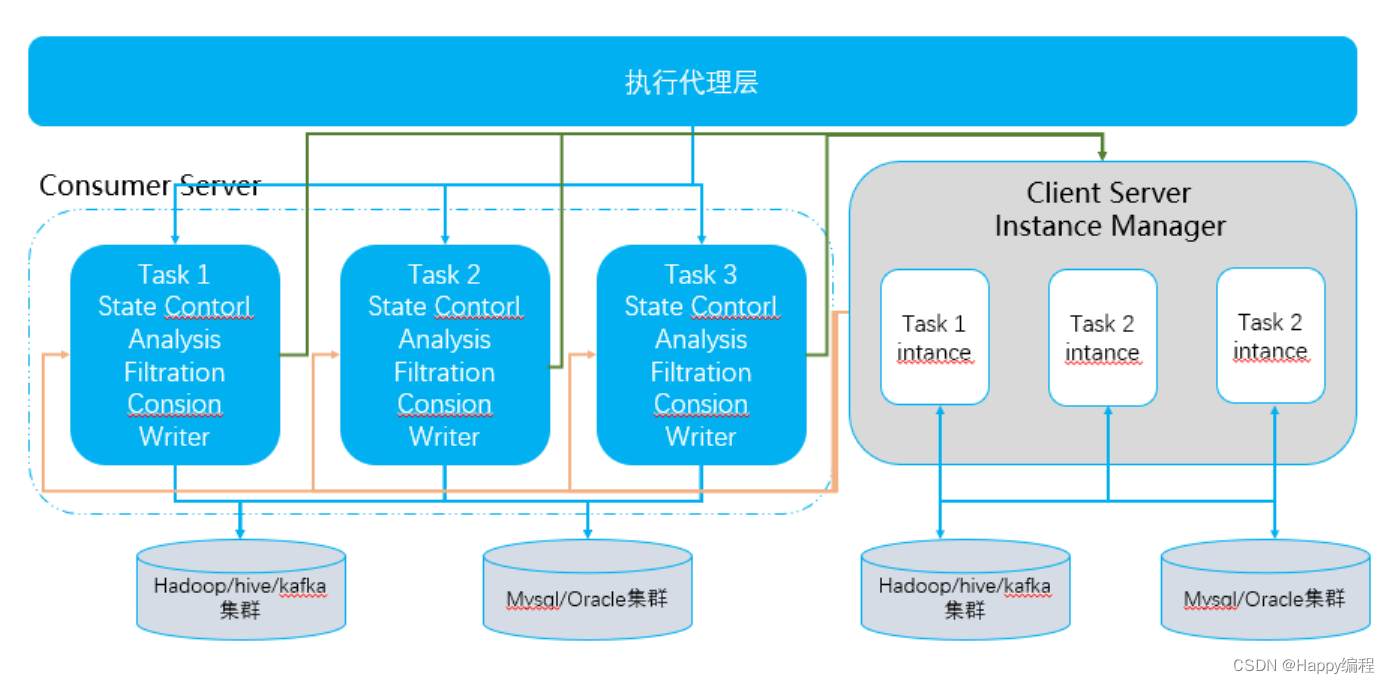
总体架构

- 数据源,支持多种数据源,可以实现对公司的各个业务线的数据进行接入整合;
- 接入层,业务mysql数据库定时同步和基于canel的实时同步结合,日志数据实时接入,互联网海量数据实时爬取清洗;
- 存储层,hdfs分布式文件系统实现海量数据存储,hbase提供数据实时读写,kafka消息队列实现数据缓存;
- 计算层,离线计算引擎用于数据挖掘和机器学习模型训练,实时计算引擎实现日志的实时分析和处理,深度学习引擎用于人工智能算法的运行;
- 分析层,实时SQL用于探索性分析和多维分析,机器学习算法用于商机的分类和推荐,NLP分析实现自然语言处理,深度学习算法用于图片水印和违禁图片识别;
- 数据服务层,对外提供数据服务;
- 数据应用层,个性推荐为PC端和单品通app端提供推荐服务;用户画像可以抽象出标签化的用户模型是提升会员质量的基础;用户行为分析对用户访问网站的规律进行分析可用于智能推荐;统计报表对数据进行挖掘分析,提供报表作为决策的依据,实现商业智能;运营支持对运营部门的需求提供大数据支持;数据大屏方便用户直观的了解运营情况,包括实时交易图、统计大屏和基地大屏。
数据采集
需要采集的数据有三类:- 业务数据,主要存储是关系型数据;
- 日志类,主要存储是文件;
- 爬虫抓取类,主要存储是文件。
业务数据
Sqoop阶段
公司业务数据库使用的mysql,最初业务数据同步使用sqoop定时同步,主要问题有三个:数据同步有延时,同步后的数据有串行、对业务库压力大。所以想找到更好替代方案。
Kafka Connect阶段
这个时候confluent 的kafka connect 进入我们的视野,看完官网的介绍和原理,设计理念特别好,支持各种数据源,完全满足我们的需求,经过部署测试,稳定性太差,根本无法用到生产环境。
Sqoop+canal阶段
最后又把目光又回到了sqoop上,利用sqoop的job实现增量同步,同时对并行度进行优化基本可以满足要求。对业务数据库压力大的问题并没有解决,考虑专门创建一个mysql备库用于我们同步数据,这时候闪现了一个想法可以考虑直接读取mysql的binlog日志进行同步,先在github上找找有没有开源的轮子,在万能的github上找到了canal。最后的方案就是通过sqoop+canal的方案,sqoop用于第一次全量同步,canal用于增量同步。
日志数据
可选的方案有三个:flume、logstash、filebeat。最后的选择的是filebeat直接接入kafka,没有使用logstash原因是对服务器压力太大,flume更侧重数据传输。
爬虫抓取类
爬虫抓取集群和大数据集群网络环境差,爬取的文件格式复杂,这种情况是flume最擅长的。
平台管理
平台建设开始就要考虑的数据资源和计算资源的管理,避免使用混乱,否则后患无穷。
数据资源管理
hdfs、hive、hbase启用安全策略,开发了专门的元数据管理平台,对数据进行管理,包括数据所属人,数据的用途。
计算资源管理
引用账号和队列,每个产品线对应一个用户组,每个用户对应一个队列,针对队列设置配额。
性能优化
硬件环境
- 系统盘和数据盘分开。避免使用一个磁盘的两个分区作为系统盘和数据盘,这样可以避免数据盘负载太高导致系统变卡。
- 数据盘不需要做raid,直接使用单个磁盘。使用raid0虽然性能高,但是单个磁盘损坏会导致整个raid磁盘不能使用,使用raid5数据可靠性高,但是性能不高。更重要的是,我们数据的安全性靠的是软件保证。
- 每台机器的磁盘数和磁盘空间尽可能一样。
- 系统盘一定要是使用单独的磁盘,最少200G空间以上
- 使用高转速磁盘,至少1000转以上,避免磁盘成为瓶颈。
- 集群机器之间至少10Gigabit(万兆)以太网。
- 内存、CPU、磁盘、带宽和磁盘io要保持一个合理的性价比。例如正常情况下内存越大越好,但是内存大到一定阶段,cpu和带宽就会成为瓶颈,如果加大cpu和带宽,最后磁盘io就有可能是瓶颈。
操作系统
- 禁用swap,使用交换分区会严重影响程序的性能。现在的内存已经不是很稀缺了,而且内存和磁盘速度相差太大。
- 增大操作系统的最大打开文件数。
- 设置数据盘的noatime属性。
- 文件系统选择ext4
部署建议
hdfs
Namenode节点不要和datanode节点部署在一起
Yarn
- yarn分配的内存是机器总内存的75%,剩余的内存用于操作系统、系统缓存、程序等使用。
- nm节点和datanode节点部署到同样的机器上。
- RM节点选择和namenode节点部署到同一个机器。
Zookeeper
- zookeeper节点选择负载比较少的机器部署,不要和nodemanager部署到同一台机器上
- zookeeper节点数3个
- zookeeper数据最好存储到单独的磁盘上,不要和数据盘用同一个盘
spark
- 计算节点尽快能接近数据节点
- 配置多个磁盘作为spark的本地目录,最好能和datanode的数据目录用同一个,spark-on-yarn由yarn.nodemanager.local-dirs确定
kafka
- kafka最好单独部署一个集群,如果机器资源不够也需要有单独的磁盘
- kafka尽可能部署到负载比较小的机器上
其它优化
shuffle相关参数调优hdfs小文件合并
任务隔离
大数据集群的规模是随着业务发展逐渐增大,导致集群机器配置不一致,主要是有一批配置低的机器最初用来跑MR任务,一批配置高的机器使用跑spark任务,最好不同的任务能提交到指定的机器运行,所以引入了对NodeManager打标签。将配置低的机器打标签为MR任务,配置高分为spark离线任务和spark Streaming任务。同时对队列也设置相应的标签。