论文学习——VideoGPT: Video Generation using VQ-VAE and Transformers
原文链接:https://arxiv.org/abs/2104.10157
1. 设计思路
不同种类的生成模型在一下多个维度各有权衡:采样速度、样本多样性、样本质量、优化稳定性、计算需求、评估难易程度等等。
这些模型,除分数匹配模型(score-matching models)之外,广义上可以分为基于似然的模型(PixelCNNs, iGPT, NVAE, VQ-VAE, Glow)和对抗生成模型(GANs)。那么哪一类的模型适于研究和视频生成任务呢?
首先,从两大类模型中进行选择。基于似然的模型训练更为方便,因为目标是很容易理解的,在不同的batch size上都很容易优化,相对于GANs的判别器来讲,也十分易于评估。考虑到由于数据的性质,对视频任务建模已经是一个较大的挑战,因此我们任务基于似然的模型在优化和评估过程中存在的困难较少,因此可以关注于结构的改进上。
其次,在许多基于似然的模型中,我们选择了自回归模型,仅因为其在离散数据上运行良好,在样本质量上表现优异,且训练方法和模型架构上较为乘数,可以利用transformer中的最新改进。
在自回归模型中,考虑如下问题:自回归模型是在没有时空冗余的下采样潜空间内进行建模更好,还是在时空领域的所有帧、所有像素上训练好呢?考虑到自然视频的时空上的冗余度,作者选择了前者,通过将高维输入编码乘一个去噪后的下采样编码的方式去除冗余度。如在时空上进行4倍下采样,总分辨率就是64倍下采样,因此生成模型就能在更少更有用的信息上倾注计算量。如在VQ-VAE上,即使一个残缺的decoder也能将潜向量转化为足够真实的样本。并且在潜空间内建模也提升了计算速度。
上述三个原因促使VideoGPT的产生,这是一款使用基于似然的生成式模型,生成对象是自然视频。VideoGPT主体上有两个结构:VQ-VAE和GPT。
VQ-VAE中的autoencoder,通过3d卷积和轴向的注意力机制(axial self.attention)来从视频中学习其下采样潜空间的离散表征。
而类似于GPT的架构(强大的自回归先验)可以使用时空位置编码来为(VQ-VAE获得的)离散潜向量自回归地建模。
上述过程得到的潜向量再通过VQ-VAE的解码器,恢复为原像素规模的视频
后续在消融实验中,作者研究了axial attention blocks的优点、VQ-VAE潜空间大小、codebooks的输入、自回归先验的容量(模型大小)的影响。
2. 具体实现
VideoGPT的整体结构如下图所示:
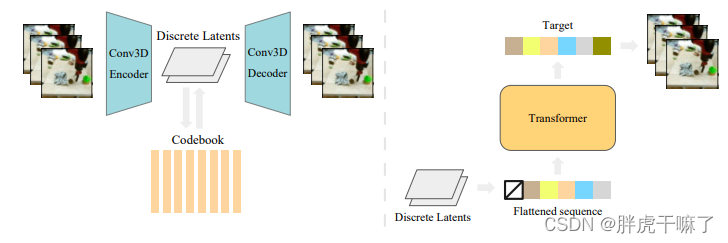
将模型分为两个部分进行讲解:
2.1 学习潜编码——VQ-VAE
为了学习到离散的latent code,首先在视频数据上训练VQ-VAE。编码器在时空维度使用3d卷积进行下采样,然后是残差注意力模块,该模块的结构如下所示,在模块中使用layernorm和轴向注意力机制。
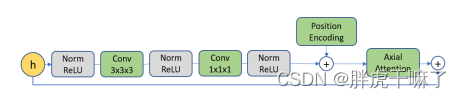
解码器的结构则是编码器的反向,先通过残差注意力模块,再通过3d转置卷积,在时空维度上进行上采样。位置编码是学习到的时间+空间上的嵌入,它们可以在encoder和decoder之间,所有轴向注意力层中共享。
关于VQ-VAE的轴向注意力,下面对其代码进行展示:
(1)需要注意的是VQ-VAE分为encoder和decoder,两部分对称。
class VQVAE(pl.LightningModule):def __init__(self, args):super().__init__()self.args = args# codebooks 中embedding的维度self.embedding_dim = args.embedding_dim# codebook中code 的数目self.n_codes = args.n_codes# n_hiddens: 残差块儿中隐藏特征的数目# n_res_layers: 残差块儿的数目# downsample: T, H, W三个维度下采样倍数self.encoder = Encoder(args.n_hiddens, args.n_res_layers, args.downsample)self.decoder = Decoder(args.n_hiddens, args.n_res_layers, args.downsample)(2)以encoder为例,其残差层数目n_res_layers取值为4,故而其self.res_stack部分共有4层
class Encoder(nn.Module):def __init__(self, n_hiddens, n_res_layers, downsample):super().__init__()n_times_downsample = np.array([int(math.log2(d)) for d in downsample])self.convs = nn.ModuleList()max_ds = n_times_downsample.max()for i in range(max_ds):in_channels = 3 if i == 0 else n_hiddensstride = tuple([2 if d > 0 else 1 for d in n_times_downsample])conv = SamePadConv3d(in_channels, n_hiddens, 4, stride=stride)self.convs.append(conv)n_times_downsample -= 1self.conv_last = SamePadConv3d(in_channels, n_hiddens, kernel_size=3)self.res_stack = nn.Sequential(*[AttentionResidualBlock(n_hiddens)for _ in range(n_res_layers)],nn.BatchNorm3d(n_hiddens),nn.ReLU())
(3)对于其中的每一层AttentionResidualBlock,即之前图中所提的残差注意力模块,模块的末端各对应一个AxialBlock,每个AxialBlock中对应时空三个维度的多头注意力机制
class AxialBlock(nn.Module):def __init__(self, n_hiddens, n_head):super().__init__()kwargs = dict(shape=(0,) * 3, dim_q=n_hiddens,dim_kv=n_hiddens, n_head=n_head,n_layer=1, causal=False, attn_type='axial')self.attn_w = MultiHeadAttention(attn_kwargs=dict(axial_dim=-2),**kwargs)self.attn_h = MultiHeadAttention(attn_kwargs=dict(axial_dim=-3),**kwargs)self.attn_t = MultiHeadAttention(attn_kwargs=dict(axial_dim=-4),**kwargs)
(4)对于每一个多头注意力,其注意力部分对应一个AxialAttention机制
class AxialAttention(nn.Module):def __init__(self, n_dim, axial_dim):super().__init__()# encoder 里4个attentionResidualBlock,对应4组axial-attention,每组3个# decoder 结构上与encoder对称,故也有4个attrntionResidualBlock# print(n_dim, axial_dim) # 如下内容,共8组,应该是共8个attention block# 3 -2# 3 -3# 3 -4if axial_dim < 0:axial_dim = 2 + n_dim + 1 + axial_dimelse:axial_dim += 2 # account for batch, head, dimself.axial_dim = axial_dimdef forward(self, q, k, v, decode_step, decode_idx):q = shift_dim(q, self.axial_dim, -2).flatten(end_dim=-3)k = shift_dim(k, self.axial_dim, -2).flatten(end_dim=-3)v = shift_dim(v, self.axial_dim, -2)old_shape = list(v.shape)v = v.flatten(end_dim=-3)# scaled dot-product attention,计算分类结果out = scaled_dot_product_attention(q, k, v, training=self.training)out = out.view(*old_shape)out = shift_dim(out, -2, self.axial_dim)return out
以上
2.2 学习到先验
模型的第二阶段是在VQ-VAE第一阶段的latent code的基础上学习一个先验。先验网络遵循Image-GPT的结构,另外还在feedforward layer和注意力块儿后面加入了dropout,以实现正则化。
以上过程是无条件限制的情况下进行训练的。可以通过训练带条件的先验(conditional prior)来生成conditional samples。条件限制有两种方法:
- 交叉注意力(Cross Attention):作为视频帧的限制,在先验网络的训练过程中,我们首先向3d的resnet中喂入有条件限制的帧,然后再resnet的输出上使用cross attention。
- 条件正则(Conditional Norms):与GANs中使用的限制方法相似,我们在transformer的Layer Normalization层上参数化gain和bias,作为条件张量(conditional vector)的放射函数。这种方法适用于对动作和类别进行限制的模型