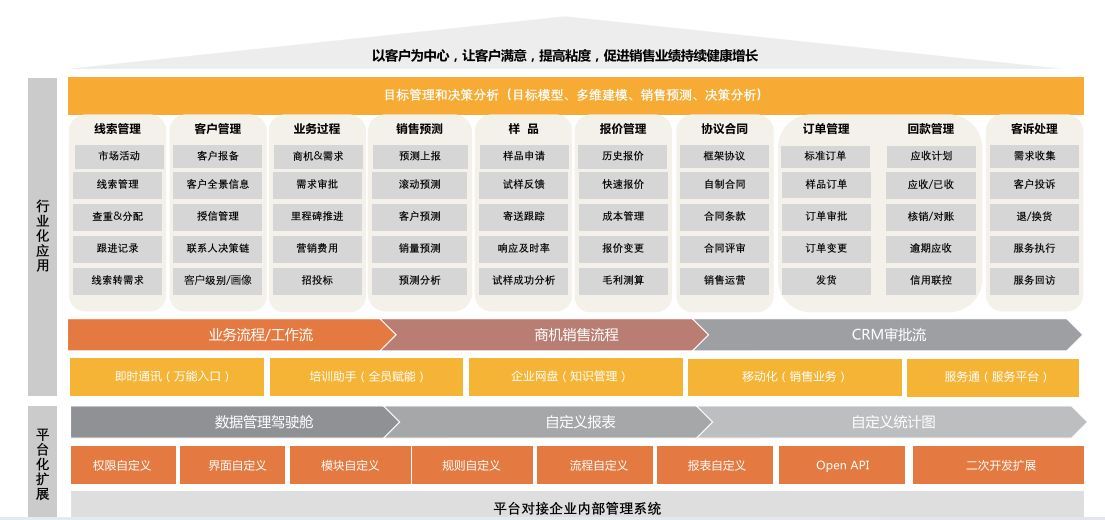
Redis,全称Remote Dictionary Server,是一个开源的高性能键值对数据库。它以其卓越的性能、丰富的数据结构和灵活的使用方式,在现代互联网应用中扮演着重要角色。本文将探讨Redis之所以快的原因,包括其数据结构、内存管理、IO多路复用等关键特性,并与其他数据库进行比较,结合实际代码案例展示Redis在实际应用中的表现,最后介绍Redis的适用场景和限制。
一、Redis的关键特性
1. 数据结构
Redis支持多种类型的数据结构,包括字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(Zset)等。每种数据结构都经过精心设计,以优化特定的操作场景。
- 字符串(String):Redis中的字符串类型不仅可以存储文本数据,还可以存储数字。字符串类型的操作包括设置值、获取值、自增、自减等,时间复杂度通常为O(1)。
- 哈希(Hash):哈希类型是一个键值对的集合,其中每个键值对都可以存储一个字符串值。哈希类型非常适合存储对象信息,如用户信息等。Redis根据哈希类型中元素的数量和大小,选择使用压缩列表(ziplist)或哈希表(hashtable)作为内部编码。[1]
- 列表(List):列表类型是一个有序的字符串列表,支持在列表的头部或尾部添加元素,也支持在列表任意位置插入或删除元素。列表类型常用于实现消息队列、排行榜等功能。Redis根据列表的大小和元素数量,选择使用压缩列表(ziplist)或双向链表(linkedlist)作为内部编码。[1]
- 集合(Set):集合类型是一个无序的字符串集合,其中每个元素都是唯一的。集合类型支持交集、并集、差集等操作,常用于实现标签系统、好友关系等功能。Redis根据集合中元素的数量和类型,选择使用整数集合(intset)或哈希表(hashtable)作为内部编码。[1]
- 有序集合(Zset):有序集合类型是一个有序的字符串集合,每个元素都关联一个双精度浮点数分数。有序集合类型常用于实现排行榜、范围查询等功能。Redis使用跳表(skiplist)和哈希表(hashtable)来实现有序集合。[1]
这些数据结构的设计使得Redis在处理特定操作时能够非常高效。
2. 内存管理
Redis将所有数据存储在内存中,因此能够非常快速地读取和写入数据。Redis的内存管理策略包括以下几个方面:
- 内存分配:Redis使用jemalloc作为内存分配器,jemalloc针对多线程场景进行了优化,能够减少内存碎片,提高内存分配和释放的效率。
- 内存回收:Redis提供了多种内存淘汰策略,如LRU(最近最少使用)、LFU(最不经常使用)等,当内存使用达到上限时,Redis会根据配置的淘汰策略自动删除部分数据以释放内存。
- 过期策略:Redis支持为键设置过期时间,当键过期时,Redis会自动删除该键。Redis采用惰性删除和定期删除相结合的方式来实现过期策略,以减少对CPU的占用。[11]
3. IO多路复用
Redis采用IO多路复用技术,允许单个线程处理多个网络连接。Redis使用epoll(在Linux系统上)作为IO多路复用的实现方式,能够高效地处理大量的并发连接。当某个连接上有数据可读或可写时,epoll会通知Redis进行相应的读写操作,从而避免了大量的无用操作。IO多路复用技术使得Redis能够充分利用CPU资源,提高并发处理能力。[3]
二、Redis与其他数据库的比较
性能比较
| 数据库类型 | Redis | MySQL | MongoDB |
|---|---|---|---|
| 数据存储方式 | 内存 | 硬盘 | 硬盘 |
| 读写速度 | 快 | 慢 | 中等 |
| 并发处理能力 | 高 | 中等 | 高 |
| 数据一致性 | 最终一致性 | 强一致性 | 最终一致性 |
Redis由于将数据存储在内存中,读写速度非常快,远超过将数据存储在硬盘上的MySQL和MongoDB。同时,Redis采用单线程模型和IO多路复用技术,能够高效地处理大量的并发连接。虽然Redis的数据一致性是最终一致性,但在很多应用场景下已经足够。[9]
扩展性比较
| 数据库类型 | Redis | MySQL | MongoDB |
|---|---|---|---|
| 水平扩展 | 支持 | 支持 | 支持 |
| 主从复制 | 支持 | 支持 | 支持 |
| 分片 | 支持 | 不支持 | 支持 |
Redis支持主从复制和分片,能够实现数据的水平扩展。通过增加从节点,可以提高系统的读性能和可用性;通过分片,可以将数据分布到多个节点上,提高系统的写性能和存储容量。MySQL也支持主从复制,但不支持分片;MongoDB天生具有良好的扩展性,支持自动分片功能。[9]
容错性比较
| 数据库类型 | Redis | MySQL | MongoDB |
|---|---|---|---|
| 数据持久化 | 支持 | 支持 | 支持 |
| 高可用部署 | 支持 | 支持 | 支持 |
| 数据备份 | 支持 | 支持 | 支持 |
Redis支持RDB快照和AOF日志两种持久化方式,能够将内存中的数据定期保存到硬盘上,防止数据丢失。同时,Redis支持主从复制和高可用部署,如使用Redis Sentinel实现自动故障转移。MySQL和MongoDB也支持数据持久化、高可用部署和数据备份功能。[8]
三、Redis在实际应用中的表现
1. 缓存
Redis最常用的场景之一就是作为缓存使用。通过将经常访问的数据缓存到Redis中,可以减少对后端数据库的访问压力,提高系统性能。
import redis.clients.jedis.Jedis;public class CacheExample {private static final String REDIS_HOST = "localhost";private static final int REDIS_PORT = 6379;private Jedis jedis;public CacheExample() {this.jedis = new Jedis(REDIS_HOST, REDIS_PORT);}public void addToCache(String key, String value) {jedis.set(key, value);}public String getFromCache(String key) {return jedis.get(key);}public static void main(String[] args) {CacheExample cacheExample = new CacheExample();// 添加数据到缓存cacheExample.addToCache("user:1:name", "Alice");cacheExample.addToCache("user:1:email", "alice@example.com");// 从缓存中获取数据String name = cacheExample.getFromCache("user:1:name");String email = cacheExample.getFromCache("user:1:email");System.out.println("Name: " + name); // 输出 Name: AliceSystem.out.println("Email: " + email); // 输出 Email: alice@example.com}
}
示例中,使用Jedis客户端连接到本地Redis服务器,并向缓存中添加用户的姓名和邮箱信息,然后从缓存中获取并打印这些信息。通过缓存,可以显著提高数据访问速度,减轻数据库负载。[10]
2. 消息队列
Redis的列表类型可以用来实现消息队列。生产者将消息压入列表尾部,消费者从列表头部取出消息进行处理。Redis的消息队列支持阻塞读取操作,当队列为空时,消费者可以阻塞等待直到有新消息到达。
import redis.clients.jedis.Jedis;public class MessageQueueExample {private static final String REDIS_HOST = "localhost";private static final int REDIS_PORT = 6379;private Jedis jedis;public MessageQueueExample() {this.jedis = new Jedis(REDIS_HOST, REDIS_PORT);}public void produceMessage(String queueName, String message) {jedis.lpush(queueName, message);}public String consumeMessage(String queueName) {return jedis.rpop(queueName);}public String blockConsumeMessage(String queueName, int timeout) {return jedis.brpop(timeout, queueName).get(1);}public static void main(String[] args) {MessageQueueExample messageQueueExample = new MessageQueueExample();// 生产者发送消息messageQueueExample.produceMessage("message_queue", "message1");messageQueueExample.produceMessage("message_queue", "message2");// 消费者消费消息String message1 = messageQueueExample.consumeMessage("message_queue");String message2 = messageQueueExample.consumeMessage("message_queue");System.out.println("Consumed message 1: " + message1); // 输出 Consumed message 1: message1System.out.println("Consumed message 2: " + message2); // 输出 Consumed message 2: message2// 阻塞消费消息String blockMessage = messageQueueExample.blockConsumeMessage("message_queue", 0);System.out.println("Blocked consumed message: " + blockMessage); // 如果有新消息,则输出新消息;否则阻塞等待}
}
在示例中,实现了一个简单的消息队列。生产者使用LPUSH命令将消息压入队列尾部,消费者使用RPOP命令从队列头部取出消息进行处理。展示了如何使用BRPOP命令实现阻塞读取操作。[10]
3. 分布式锁
在分布式系统中,为了保证数据的一致性,需要使用锁来避免并发访问。Redis提供了分布式锁的支持,通过设置一个唯一的键和值,并设置过期时间,来确保在分布式环境中只有一个客户端能够获取到锁。
import redis.clients.jedis.Jedis;public class DistributedLockExample {private static final String REDIS_HOST = "localhost";private static final int REDIS_PORT = 6379;private Jedis jedis;private static final String LOCK_KEY = "distributed_lock";private static final long LOCK_EXPIRE_TIME = 10000; // 锁过期时间,单位:毫秒public DistributedLockExample() {this.jedis = new Jedis(REDIS_HOST, REDIS_PORT);}public boolean acquireLock() {String clientId = String.valueOf(Thread.currentThread().getId());long expireTime = System.currentTimeMillis() + LOCK_EXPIRE_TIME;String lockValue = clientId + ":" + expireTime;return jedis.setnx(LOCK_KEY, lockValue) == 1;}public void releaseLock(String clientId) {String lockValue = clientId + ":" + System.currentTimeMillis();while (true) {String oldValue = jedis.get(LOCK_KEY);if (oldValue == null || oldValue.startsWith(clientId)) {if (jedis.getSet(LOCK_KEY, "") != null) {break;}} else {break;}}}public static void main(String[] args) {DistributedLockExample lockExample = new DistributedLockExample();boolean isLocked = lockExample.acquireLock();if (isLocked) {System.out.println("Lock acquired!");try {// 执行需要加锁的操作Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();} finally {lockExample.releaseLock(String.valueOf(Thread.currentThread().getId()));System.out.println("Lock released!");}} else {System.out.println("Failed to acquire lock!");}}
}
示例中,实现了一个简单的分布式锁。客户端尝试使用SETNX命令获取锁,如果成功则返回true,表示获取到锁;否则返回false,表示获取锁失败。获取到锁的客户端在执行完需要加锁的操作后,需要释放锁。释放锁时,客户端会检查当前锁的值是否为自己设置的值,如果是则删除锁;否则不做任何操作。[10]
四、Redis的适用场景和限制
适用场景
- 缓存:将经常访问的数据缓存到Redis中,减少数据库访问压力,提高系统性能。
- 会话存储:在Web应用中,使用Redis存储用户的会话信息,如登录状态、购物车内容等。
- 排行榜/计数器:利用Redis的有序集合和自增/自减操作,实现排行榜和计数器功能。
- 消息队列:使用Redis的列表类型实现消息队列,处理异步任务。
- 分布式锁:在分布式系统中使用Redis实现分布式锁,保证数据一致性。
- 实时分析:利用Redis的快速读写能力,实现实时数据分析功能。
- 地理位置信息存储:Redis支持地理位置信息的存储和查询,可以用于实现附近的人、附近的商家等功能。
限制
- 内存限制:Redis将所有数据存储在内存中,因此受到物理内存大小的限制。当数据量过大时,需要考虑数据淘汰策略或扩展Redis集群。
- 数据一致性:Redis的数据一致性是最终一致性,不适用于需要强一致性的场景。
- 复杂查询:Redis不支持复杂的SQL查询操作,对于需要复杂查询的场景可能不是最佳选择。
- 网络依赖:Redis是基于内存的数据库,一旦网络出现问题或Redis服务宕机,可能会导致数据丢失或服务中断。因此,在使用Redis时需要做好数据备份和容灾准备。
综上所述,Redis凭借其高性能、丰富的数据结构和灵活的使用方式,在现代互联网应用中发挥着重要作用。然而,Redis也存在一些限制和挑战,需要在使用过程中根据具体场景进行权衡和选择。