数据分析案例
- 明确分析的目的
- 数据处理
- 原始数据
- 数据清洗
- 选择子集
- 重复数据处理
- 缺失数据处理
- 数据转化
- 数据提取-字段分割
- 异常值处理
- 数据分析
- 1.需求在哪里?
- 2.需要什么样的人才?
- 3.什么阶段需求最旺?
- 结论
明确分析的目的
• Where——需求在哪里?
• What——需要什么样的人才?
• When——什么阶段需求最旺?
数据处理
原始数据

数据清洗
选择子集
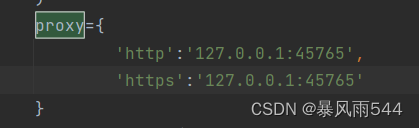
职位ID是该职位唯一标识,隐藏公司ID
公司全名和公司简称重复,隐藏简称
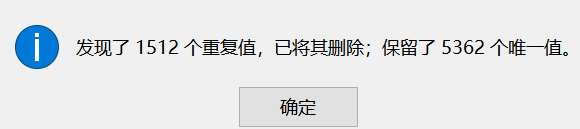
重复数据处理
操作对象:根据职位ID来删除重复数据
操作方法:选择职位ID列,数据->数据工具->删除重复值
缺失数据处理
操作对象:由城市列和职位ID列的计数可以看出城市列存在2个空值
操作方法:开始->查找选择->定位条件->补充空值
数据转化
操作对象:薪水这一列显示的是一个范围,是文本格式,之后不能用于计算
操作方法:增加最低薪水,最高薪水,平均薪水三列。
最低薪水计算方法:=LEFT(L2,FIND(“k”,L2)-1)
最高薪水计算方法:=MID(L2,FIND(“-”,L2)+1,LEN(L2)-FIND(“-”,L2)-1)
平均薪水计算方法:=(最高薪水+最低薪水)/2
操作对象:对数据进行筛选,发现最低薪水有数值显示错误

原因是薪水文本的K是大写
操作方法:选中薪水列 开始->查找和选择->替换
操作对象:对数据进行筛选,发现最高薪水有数值显示错误
看到薪水列中显示的是多少以上,导致不能计算出来,这里可以将最高薪水=2*最低薪水

数据提取-字段分割
操作对象:公司所属领域按照分隔符进行分列操作,之后将原来的公司所属领域隐藏。
操作方法:选中公司所属领域列,数据->数据工具->分列
异常值处理
对数据做透视表,对职位名称计数项降序排列,发现有些职位不属于数据分析
 通过=IF(COUNT(FIND({“数据分析”},N2)),“是”,“否”)将属于数据分析师的职位标记为"是",不属于的标记为"否"。将数据分析师的职位筛选出来,复制到新的工作簿中
通过=IF(COUNT(FIND({“数据分析”},N2)),“是”,“否”)将属于数据分析师的职位标记为"是",不属于的标记为"否"。将数据分析师的职位筛选出来,复制到新的工作簿中

数据分析
1.需求在哪里?
1.1不同城市的岗位需求

结论:
- 全国数据分析师的人才需求量将近一半集中在北京
- 北上深杭广提供91.8%的工作机会
1.2不同城市岗位需求和薪资水平

结论:
发现北京是平均薪水是最高的,也是需求量最大的,其次是上海和深圳。
2.需要什么样的人才?
2.1对学历的需求

结论:
- 74%的数据分析职位要求本科学历
- 数据分析师薪资随学历增加不显著,本科与硕士薪资水平无显著差异
2.2对工作年限的需求
结论:
- 70.6%职位要求1-5年经验
- 数据分析师薪资随工作经验增加显著,3-5年比1年以下翻倍
- 招聘数据分析师非常看重工作经验
2.3对职位类别的需求

结论: - 技术类招聘比占一半以上,薪资最高
3.什么阶段需求最旺?

结论:
- 150人以上公司对数据分析师招聘需求占74.5%
- 随着公司发展,数据分析师重要性愈加凸
结论
- 按城市来看,全国数据分析师的人才需求量将近一半集中在北京,排在前五的分别
是北京、上海、深圳、杭州、广州。 - 按工作年限来看,工作3-5年经验的人才需求量最大,其次是1-3年工作经验的人才; 随着工作经验的提升,数据分析师平均薪水不断提升,是一个长期的发展方向。
- 按学历来看,74%的数据分析职位要求本科学历 ,数据分析师薪资随学历增加不显著,本科与硕士薪资水平无显著差异。
- 按公司规模来看,150人以上公司对数据分析师招聘需求占74.5%;随着公司发展,数据分析师重要性愈加凸
- 按职位类别来看,技术类招聘比占一半以上,薪资最高
- 数据分析师总体平均薪水是17.3k,按城市来看,北京平均薪水最高为18.8k,其次为深圳17.7k,上海17.3k; 按工作年限来看,数据分析师薪资随工作经验增加显著,3-5年(20.2k)比1年以下(8.5k)翻倍 。
数据下载地址