文章目录
- 分组
- 去重
不出意外的话,这应该是stata有关数据处理的最后一篇。emmm,其实我一开始只打算写数据处理部分的stata教程,因为我觉得对于我来说,数据处理才是最头疼的部分。不过关于后面回归,还是有些东西想跟大家分享一下(开始挖坑),后面能写多少,就看造化吧,这里还是说一句,数据处理部分完结撒花~~
分组
Stata中分组命令其实有by和bysort两个,但根据官方文档:“by and bysort are really the same command; bysort is just by with the sort option.” 所以此处只介绍bysort命令。
直接上代码:
* 官方代码 *
bysort varlist: stata_command
bysort后接用于分组的变量名(可以有多个),再接要进行的stata操作。举个例子:
* 使用系统数据库 *
sysuse auto
* 生成国产车和进口车分别的均价 *
bys foreign :egen avg_price = mean(price)
* 根据foreign以及headroom进行分类生成均价 *
bys foreign headroom :egen avg_price1 = mean(price)
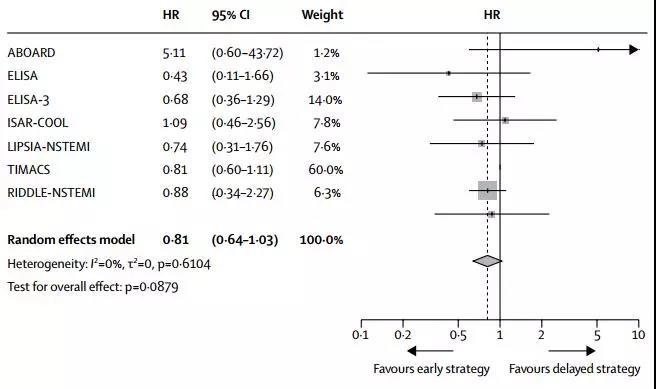
如果大家运行了这段代码,可以看到bysort命令不仅仅根据变量进行分组计算,同时还对数据进行了排序,排序依据就是我们分组所用的变量。(图一为使用bysort命令前,图二为使用命令后)


去重
有时我们数据有重复,我们就可以使用duplicates命令进行去重,我比较常用的duplicates用法有两种:
* 计算重复的个数,并将这个计数生成新变量 *
duplicates tag variable_list, generate(new_variable)
* 根据指定变量找出重复值,并去重 *
duplicates drop varable_list, force
这里可以看出,duplicates tag的功能有点类似于bysort后生成一个计数变量。这里对该命令两种用法依然举个例子,使用之前的数据库:
sysuse auto,clear
* 根据汽车的headroom进行分类,并生成变量count*
duplicates tag headroom, g(count)
* 根据汽车的headroom以及foreign变量进行去重 *
duplicates drop headroom foreign, force
注意这里duplicates drop后记得加上", force",否则会报错。
References
bysort 官方文档
duplicates 官方文档









![152.网络安全渗透测试—[Cobalt Strike系列]—[会话管理/派生]](https://img-blog.csdnimg.cn/3aec4ac726fa4500bf86c52386e0cd27.png)