文章目录
- 前言
- 一、WinHTTrack Website Copier是什么?
- 二、WinHTTrack Website Copier使用步骤
- 三、什么是Python?
- 四、Python实现的功能
前言
实现快速统计网站所有页面的文本字数,需要具备两个条件:
1.获取该网站的所有页面的html文件
2.提取html文件中的文本内容
实现如上两个条件,这里我们需要用到两个工具WinHTTrack Website Copier和python
一、WinHTTrack Website Copier是什么?
WinHTTrack Website Copier是一款离线浏览工具,使用它可以很容易地做站点镜像,可以将你指定的网站完整地保存到本地硬盘,能递归创建与源网站完全一样的组织结构,离线镜像创建后,你可以在断网的情况下任意浏览这个网站的所有内容。
二、WinHTTrack Website Copier使用步骤
- 打开WinHTTrack Website Copier,下一步

- “Project name”可以使用网站名称命名,“base path”选择一个路径用来保存下载的文件,点击“下一步”。

- 在“web addresses”中输入当前网站的URL地址。

- 点击“Set options”按钮,在“Scan Rules”选项的文本框中根据需要添加相应的规则,这里我添加的是
-.css -.js
-.gif -.jpg -.jpeg -.png -.tif -.bmp
-.zip -.tar -.tgz -.gz -.rar -.z -.exe
-.mov -.mpg -.mpeg -.avi -.asf -.mp3 -.mp2 -.rm -.wav -.vob -.qt -.vid -.ac3 -.wma -.wmv

- 在“Limits”选项中,“Maximum mirroring depth”根据需要进行设置,这里我设置的数值为10

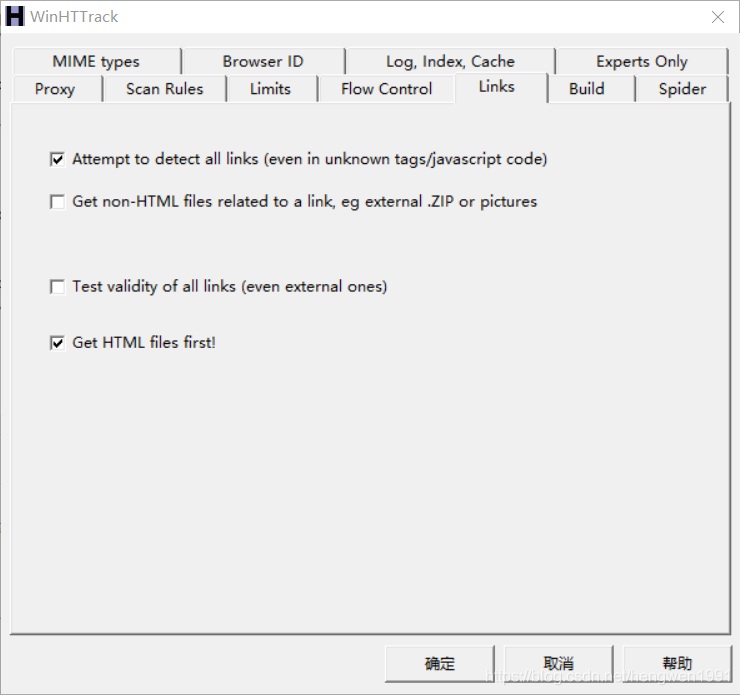
- 在“Links”选项中,勾选“Get HTML files first!”选项,点击“下一步”选择“完成”即可开始下载。
- 需要实现的功能是统计整站网页的字数,因此我们这里只需要下载html文件即可。html文件所在位置为:[base path][Project name][Project name],该路径下的index.html和index文件夹下的所有文件为整站中的所有html。
三、什么是Python?
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
版本:Python3。
四、Python实现的功能
如下代码实现的主要功能是解析下载到的html文件,将html文件中的文本内容进行提取,并按照字符长度计算文本字数。
# -*- coding: utf-8 -*-import os
import re
from lxml import etreedef traverse_file(read_path, save_path):"""遍历目录下所有文件:param read_path: 读取文件路径:param save_path: 存储结果路径:return:"""for base_path, folder_list, file_list in os.walk(read_path):print('开始遍历{}目录下的html文件'.format(base_path))for file_name in file_list:file_path = os.path.join(base_path, file_name)file_ext = file_path.rsplit('.', maxsplit=1)if file_ext[1] == 'html': # 判断文件是否为htmlwith open(file_path, 'rb') as f:data = f.read().decode('utf-8', 'ignore')html = etree.HTML(data)pending_html = html.xpath("//body//*[not(self::style)]") # 不提取style标签中的内容pending_text = pending_html[0].xpath(" //body//*[not(self::script)]/text()") # 不提取script标签中的内容text = ''.join(pending_text)text_new = text.replace(' ', '')result = text_new.replace('\n', '')print('该网站文本字数为:', len(result))with open(save_path, 'a', encoding='utf-8') as f:f.write(result)def main():# 读取html文件路径read_path = r'D:\data\..'# 结果文件存储目录save_path = r'D:\result\...\result.txt'traverse_file(read_path, save_path)if __name__ == '__main__':main()