说明
记录一下 5月11日晚,做的海康威视的一场笔试。分享给需要的IC人。
岗位:数字逻辑设计工程师(浙江 杭州)
转载需要本人同意!
我的见解不一定都是准确的,欢迎评论区交流指正~~
单选题
1、(3分)在Verilog中,下列语句哪个不是分支语句?
A、case
B、if-else
C、casez
D、repeat
一眼见,D
2、(3分)对于 reg[0:31] ,表达式 hik[0:+8]指的是 ?
IEEE的 Verilog 标准对此的原文表述:
示例:
来看一个仿真:
// ======================================================================== // 功能描述:-1- 验证Verilog 语法部分位选择 // 作者:Xu Y. B. // 时间:2023-05-12 // ========================================================================`timescale 1ns / 1psmodule TB_PART_SEL_BIT(); // 小端数据 wire [0:31] W_DATA = {8'd1,8'd2,8'd3,8'd4};wire [7:0] W_1 = W_DATA[0+:8]; //W_DATA[0:7] wire [7:0] W_2 = W_DATA[31-:8];//W_DATA[24:31] wire [8:0] W_3 = W_DATA[0:+8]; //W_DATA[0:8] wire [8:0] W_4 = W_DATA[+1:+8]; //W_DATA[1:8]// 大端数据 wire [31:0] W_DATA_2 = {8'd1,8'd2,8'd3,8'd4};wire [7:0] W_5 = W_DATA_2[31-:8]; //W_DATA[31:24] wire [7:0] W_6 = W_DATA_2[0+:8]; //W_DATA[7:0] wire [7:0] W_7 = W_DATA_2[+8:+8]; //W_DATA[8] wire [7:0] W_8 = W_DATA_2[+8:0]; //W_DATA[8:0]// 索引号为非正 wire [0:-31] W_DATA_3 = {8'd1,8'd2,8'd3,8'd4}; wire [7:0] W_9 = W_DATA_3[0-:8]; //W_DATA[0:-7] wire [7:0] W_10 = W_DATA_3[-31+:8]; //W_DATA[-24:-31] wire [7:0] W_11 = W_DATA_3[-8:-8]; //W_DATA[-8]// 简单总结: // -1- 数字前面的 + - 符号表示正负,与其后的数字组成 位的索引号; // -2- 数字后面的 + - 符号表示位选择的方向,±符号前的数字表示起始比特,:后面的数字表示位宽endmodule看下仿真的结果:




3、(3分)如果a=4'b0101,则表达式^a= ?
了解 Verilog 规约运算的都知道,结果应该是 1’b0。不再赘述
4、(3分)netlist(网表)一般通过什么手段进行验证与其RTL一致性?
A、RTL验证
B、网表验证
C、形式验证
D、随机验证
形式验证是为了验证RTL代码与综合后的门级网表之间的逻辑等价性。功能是否等价,与时序无关。
此题我选择 C
5、(3分)已知在电路设计过程中,某性能需求弱但时序收敛难度大的乘法器最多需要5个时钟周期才能完成计算,若考虑对其设置multicyc采优化时序,则下方约束中应当如何设置。
set multicycle path ()-setup-from start point-to end point
set multicycle_path ()-hold-from start point-to end point
A、4,4
B、5,4
C、5,5
D、5,1
对于多周期约束,建立时间约束应为 5个时钟周期,保持时间约束由于1个时钟周期的时间抵消,所以约束4个时钟周期即可。所以此题我会选择 B
《Static Timing Analysis for Nanometer Designs A Practical Approach》一书中也给出了答案。

6、(3分)假设一个模块完成任务1,需要依次进行A、B、C三个步骤,完成任务2,需要依次进行A、B、C、D四个步骤。A、B、C、D四个步骤分别耗时2clk,3clk,4clk,5clk。如果任务1需要先于任务2开始,那么该模块完成任务1和任务2最短需要()clk:
我认为需要14个clk。
由于二者的步骤存在交集,任务2可以在任务1的 A或B或C 步骤结束后开始任务2后的其他步骤,故共需要 2+3+4+5 = 14个clk。
7、(3分)芯片工作中,会经历多次断电和上电,在最后一次上电复位后,片上SRAM的内部存储空间的值是什么?
此题我觉得是随机值,SRAM具有断电易失特性。上电后的数据为随机值。
8、(3分)十进制数+127、-127的8-bt有符号数二进制补码表示为 ?
这个是基本的常识,+127的二进制补码:8‘b01111111;-127的二进制补码:8’10000001
9、(3分)仅使用以下一种路基,能够实现逻辑(A XOR B)OR(C AND D) 的是()
A、NAND
B、XOR
C、NOR
D、AND
根据上面的推导结果,该逻辑可以只通过与非门实现。所以我觉得是 NAND
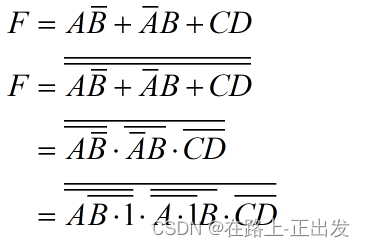
10、(3分)shell脚本中,可以使用什么关键字进行变量值打印到terminal?
echo
多选题
1、验证结束的前提条件描述正确的是?
A、缺陷曲线收敛
B、验证报告完成评审
C、覆盖率达到100%
D、多轮随机测试完成
覆盖率达到 100% 不是必要条件。
我觉得选择:ABD
2、(5分)关于存储器层次结构,下面哪些表述通常是正确的
A、在一次读操作中,返回的值取决于哪些块在cache中
B、cache利用了时间局部性
C、存储器层次结构的大部分成本在于最高一层
D、存储器层次结构的大部分容量处于最低一层
cache利用了时间局部性和空间局部性
cache中分成大小相同的块——cache块;当CPU需从内存中读写数据时,发送主存地址cache中查看有没有相应块,若没有则需要从内存中查找并替换cache中某块,再读取,此时便会造成缺失。
此题全选。
3、(5分)下面的AMBA总线,支持Burst传输的有()
A、APB
B、AXI
C、AXI-Lite
D、AHB
APB是高级外设总线,不支持突发传输。
AXI,高级扩展接口,支持突发传输。
AXI-Lite,轻量级的AXI协议,不支持突发传输。
AXI-Stream,支持无限制的突发传输。
AHB主要用于高性能模块(如CPU、DMA和DSP等)之间的连接,作为SoC的片上系统总线,它包括以下一些特性:单个时钟边沿操作;非三态的实现方式;支持突发传输;支持分段传输;支持多个主控制器;可配置32位~128位总线宽度;支持字节、半字和字的传输。
所以此题我觉得选:B D
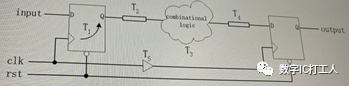
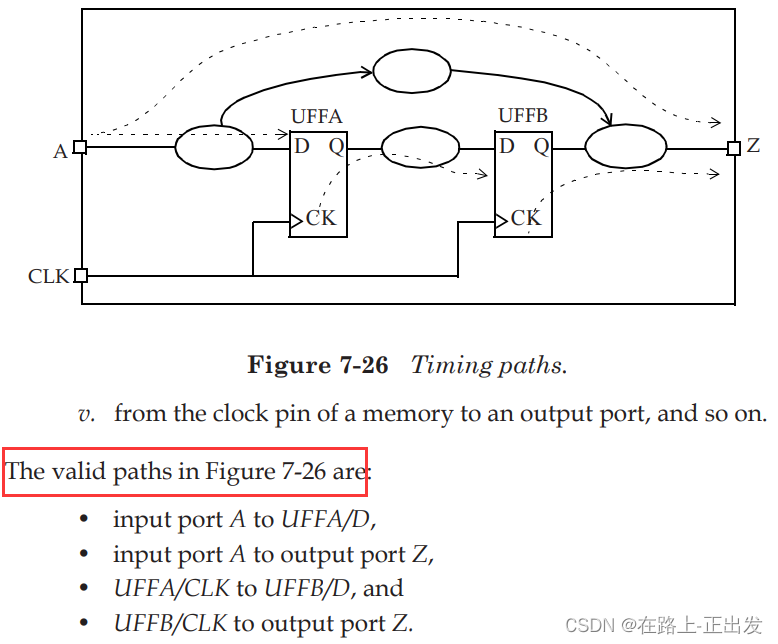
4、(5分)下图中4条路经属于时序路径的是:

此题4条路经均为时序路径。
静态时序分析的圣经:《Static Timing Analysis for Nanometer Designs A Practical Approach》一书中对此有说明:

5、下面的变量命名,在Verilog中合法的有:
A、233
B、define
C、for
D、HikVision
此题选,BD,相信你肯定对B有疑问,自己动手写下代码看看。可以再看看诸如:
include
timescale
的关键字作为信号名是否出现语法错误。
6、下面代码与设计预期不符或者功能有问题的有哪些?
A、assign a = din ^ n;//求指数B、parameter WIDTH;assign WIDTH = 8;C、reg [7:0] dat;
always @ (*) dat = 'd100;D、assign a = b&c;
assign b = (~a) & d;Verilog 运算符中 ^ 表示两个操作时按位异或运算。
parameter 型参数在定义时必须给默认值。
D选项我觉得语句有问题。
C选项可以一直保持常量。
所以我觉得选 ABD
7、(5分)下面说法正确的是
A、信号的有效区间需要>=信号需要使用的区间
B、信号的语义不变的情况下,可以通过修改实现方案来扩展它的有效区间
C、信号的有效区间类型可分为:当前时刻有效、一段区间内有效、任意时刻有效,fifo的empty信号都是任意时刻有效
D、信号的有效区间需要<=信号名副其实的区间
fifo的empty信号应该不是一直有效的,主要是由于异步FIFO存在CDC问题。
我觉得除了C都又可以选。
8、(5分)验证的层次?
A、芯片系统级(chiplevel)
B、IP集成级(IPIntergration level)
C、模块单元级(blocklevel/unitlevel)
D、子系统级(sub-system level)
此题很明显,全选
问答题
(15分)CPU都是基于某一具体指令集架构而设计的,如基于x86指令集的英特尔处理器是典型的CISC,而基于risc-V指令集的开源rocket处理器是典型的RISC。那么,在计算机系统中,引入指令集架构有什么好处?
引入指令集架构具有以下好处:
1.简化硬件设计:指令集架构定义了一组标准的指令集,使得CPU的硬件设计可以按照这些指令集完成,减少了硬件设计的复杂度和难度。
2.提高代码可移植性:由于不同的CPU都遵循同一种指令集架构,因此编写的程序可以在不同的CPU上运行,提高了程序的可移植性。
3.提高编译器和优化程序的开发效率:指令集架构可以提供一些标准的指令格式和编码规则,使得编译器和优化程序的开发更加方便和高效。
4.降低软件开发成本:由于不同的CPU都遵循同一种指令集架构因此软件开发者只需要编写一份代码,就可以在不同的CPU上运行,减少了软件开发的成本和难度。
5.提高系统性能:指令集架构可以针对特定的应用场景进行优化,从而提高系统的性能。
总之,引入指令集架构可以提高硬件设计的简化程度、软件的可移植性、编译器和优化程序的开发效率、降低软件开发成本,并且可以针对特定的应用场景进行优化,从而提高系统的性能。
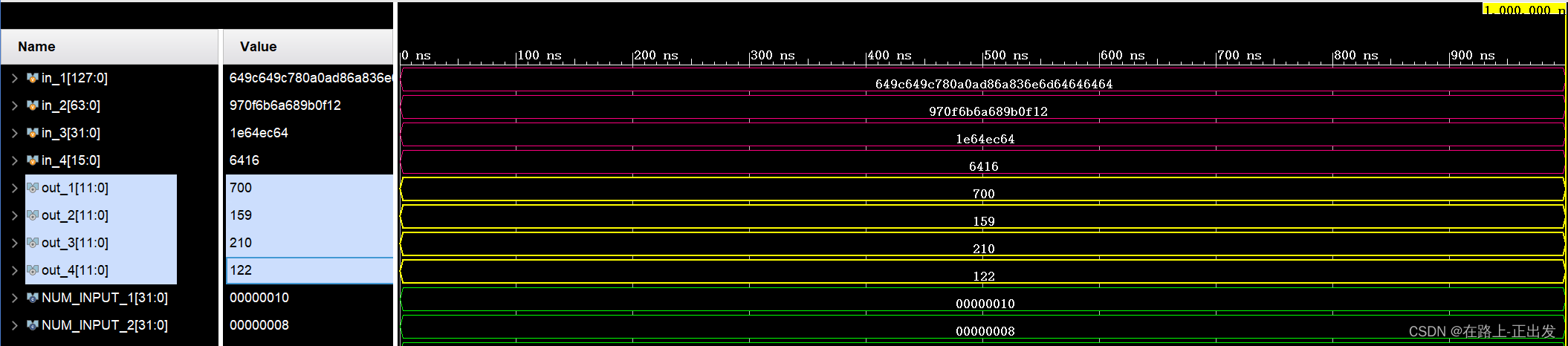
(15分)[N个8bit加法]请编写一个NUM INPUT个int8输入的加法模块,其中NUM INPUT的取值为2,4,8,16.
模块接口定义如下:
module #(
parameter NUM_INPUT=8
) add_n8bit(
input [NUM_INPUT*8-1:0] in,
output [12-1:0] out
);
此题我采用加法树的结构实现。由于输入数据最多有16个,所以按最多的输入来编程。
设计代码:
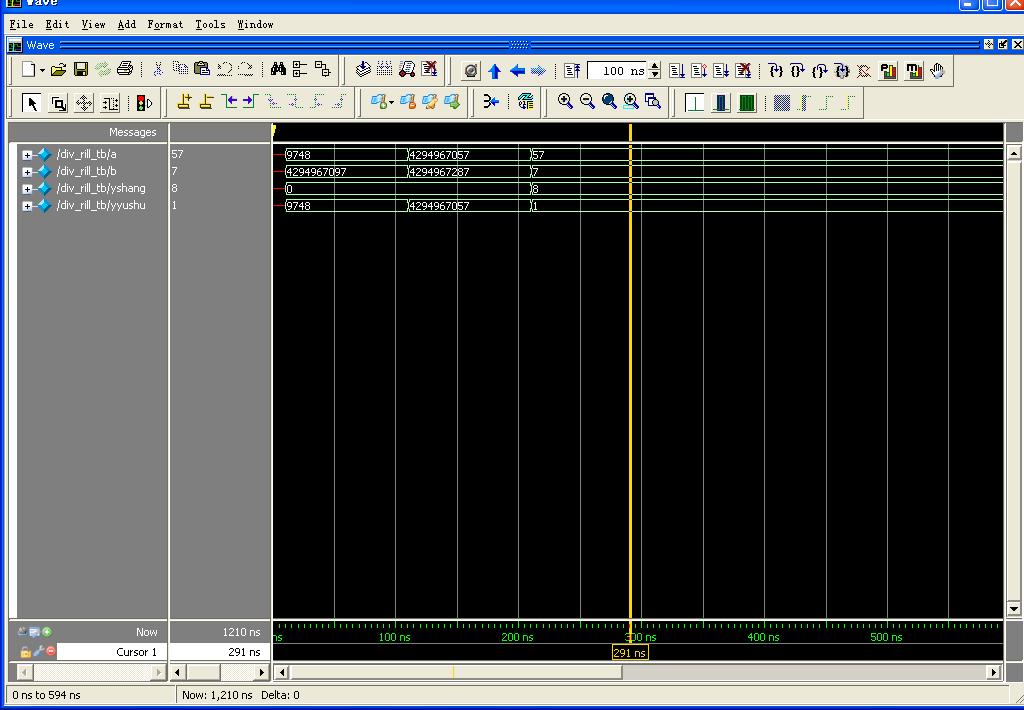
// n个8位宽数据相加模块。n可取值 2 4 8 16 // Xu Y. B. // 2023 05 13module add_n8bit #( parameter NUM_INPUT = 8 )( input [NUM_INPUT*8-1:0] in, output [12-1:0] out ); wire [16*8-1:0] W_ALL_IN = {{((16-NUM_INPUT)*8){1'b0}},in};wire [8:0] W_ADD_L1[7:0]; wire [9:0] W_ADD_L2[3:0]; wire [10:0] W_ADD_L3[1:0]; // wire [11:0] W_ADD_L4;genvar GV_1; generate for(GV_1 = 0;GV_1 < 8;GV_1 = GV_1 + 1)begin//扩展符号位并相加assign W_ADD_L1[GV_1] = {W_ALL_IN[GV_1*8+8-1],W_ALL_IN[GV_1*8+:8]} + {W_ALL_IN[(GV_1+8)*8+8-1],W_ALL_IN[(GV_1+8)*8+:8]};end endgenerategenvar GV_2; generatefor(GV_2 = 0;GV_2 < 4;GV_2 = GV_2 + 1)beginassign W_ADD_L2[GV_2] = {W_ADD_L1[GV_2][8],W_ADD_L1[GV_2]} + {W_ADD_L1[GV_2+4][8],W_ADD_L1[GV_2+4]};end endgenerategenvar GV_3; generatefor(GV_3 = 0;GV_3 < 2;GV_3 = GV_3 + 1)beginassign W_ADD_L3[GV_3] = {W_ADD_L2[GV_3][9],W_ADD_L2[GV_3]} + {W_ADD_L2[GV_3+2][9],W_ADD_L2[GV_3+2]};end endgenerateassign out = {W_ADD_L3[0][10],W_ADD_L3[0]} + {W_ADD_L3[1][10],W_ADD_L3[1]};endmodule仿真代码:
// 仿真验证模块 add_n8bit 功能 // Xu Y. B. // 2023 05 13 // 输入有符号数 范围 -128~127`timescale 1ns / 1ps module tb_add_n8bit(); parameter NUM_INPUT_1 = 16; parameter NUM_INPUT_2 = 8; parameter NUM_INPUT_3 = 4; parameter NUM_INPUT_4 = 2;reg [NUM_INPUT_1*8-1:0] in_1; reg [NUM_INPUT_2*8-1:0] in_2; reg [NUM_INPUT_3*8-1:0] in_3; reg [NUM_INPUT_4*8-1:0] in_4;wire [12-1:0] out_1; wire [12-1:0] out_2; wire [12-1:0] out_3; wire [12-1:0] out_4;add_n8bit #(.NUM_INPUT(NUM_INPUT_1)) inst_add_n8bit_1 (.in(in_1), .out(out_1)); add_n8bit #(.NUM_INPUT(NUM_INPUT_2)) inst_add_n8bit_2 (.in(in_2), .out(out_2)); add_n8bit #(.NUM_INPUT(NUM_INPUT_3)) inst_add_n8bit_3 (.in(in_3), .out(out_3)); add_n8bit #(.NUM_INPUT(NUM_INPUT_4)) inst_add_n8bit_4 (.in(in_4), .out(out_4));initial beginin_1 = {8'd100,-8'd100,8'd100,-8'd100,8'd120,8'd10,8'd10,-8'd40,8'd106,-8'd125,8'd110,8'd109,8'd100,8'd100,8'd100,8'd100};in_2 = {-8'd105,8'd15,8'd107,8'd106,8'd104,-8'd101,8'd15,8'd18};in_3 = {8'd30,8'd100,-8'd20,8'd100};in_4 = {8'd100,8'd22}; end endmodule仿真结果:
以上就是本次分享的所有题目,鉴于本人能力有限,有异议的地方请在评论区指正,谢谢!