文章目录
- 一、数据介绍
- 二、数据预处理
- 2.1 数据抽样
- 2.2 缺失值处理
- 2.3 日期与时段处理
- 2.4 制作用户标签表
- 三、用户行为标签
- 3.1 用户浏览活跃时间段
- 3.2 用户购买活跃时间段
- 3.3 关于类目的用户行为
- 3.3.1 浏览最多的类目
- 3.3.2 收藏最多的类目
- 3.3.3 加购最多的类目
- 3.3.4 购买最多的类目
- 3.4 30天用户行为
- 3.4.1 近30天购买次数
- 3.4.2 近30天加购次数
- 3.4.3 近30天活跃天数
- 3.5 7天用户行为
- 3.5.1 近7天购买次数
- 3.5.2 近7天加购次数
- 3.5.3 近7天活跃天数
- 3.6 最后一次行为距今天数
- 3.6.1 上次浏览距今天数
- 3.6.2 上次加购距今天数
- 3.6.3上次购买距今天数
- 3.7 最近两次购买间隔天数
- 3.8是否浏览未下单
- 3.9 是否加购未下单
- 四、 用户属性标签
- 4.1 是否复购用户
- 4.2 访问活跃度
- 4.3 购买的品类是否单一
- 4.4 用户价值分组(RFM)
- 五、用户个性化标签
- 5.1 应用TF-IDF算法计算标签权重
- 5.2 建立行为类型权重维表
- 5.3 计算用户标签权重
- 六、用户偏好标签
- 6.1 计算两两标签共同对应的用户数
- 6.2 计算每个标签对应的用户数
- 6.3 计算两两标签之间的相似性
- 6.4 对每个用户的历史标签权重加总
- 6.5 计算推荐给用户的相关标签
- 七、群体用户画像标签
- 7.1 随机指定性别并划分群体
- 7.2 使用TF-IDF计算不同人群的标签偏好
一、数据介绍
数据集是淘宝一个月的用户行为数据,数据包括user_id,item_id,behavior_type,user_geohash,item_category,time六个字段,共有100多万条记录,考虑数据集太大,为了提高运行效率,只随机抽取20%的数据;另外,由于数据集的局限,此项目的画像标签只是庞大用户画像的一部分,基于已有的数据集进行制作。
#导入库
%matplotlib inline
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import gc
import warnings
warnings.filterwarnings('ignore')
from datetime import datetime
#导入数据集
df_orginal = pd.read_csv('/home/kesci/input/mydata9388/taobao_persona.csv')
二、数据预处理
2.1 数据抽样
#数据集太大,为了提高运行效率,只随机抽取20%的数据
df = df_orginal.sample(frac=0.2,random_state=None)
#回收内存
del df_orginal
gc.collect()
2.2 缺失值处理
df.info()
<class ‘pandas.core.frame.DataFrame’>
Int64Index: 4658205 entries, 13077081 to 21758719
Data columns (total 6 columns):
user_id int64
item_id int64
behavior_type int64
user_geohash object
item_category int64
time object
dtypes: int64(4), object(2)
memory usage: 248.8+ MB
df.shape
(4658205, 6)
#查看各字段的缺失值数量
df.isnull().sum()
user_id 0
item_id 0
behavior_type 0
user_geohash 3183516
item_category 0
time 0
dtype: int64
- 只有user_geohash有缺失值,且缺失的比例很高,无统计分析的意义,将此列删除
df.drop('user_geohash',axis=1,inplace=True)
2.3 日期与时段处理
#将time字段拆分为日期和时段
df['date'] = df['time'].str[0:10]
df['date'] = pd.to_datetime(df['date'],format='%Y-%m-%d')
df['time'] = df['time'].str[11:]
df['time'] = df['time'].astype(int)
#将时段分为'凌晨'、'上午'、'中午'、'下午'、'晚上'
df['hour'] = pd.cut(df['time'],bins=[-1,5,10,13,18,24],labels=['凌晨','上午','中午','下午','晚上'])
2.4 制作用户标签表
#生成用户标签表,制作好的标签都加入这个表中
users = df['user_id'].unique()
labels = pd.DataFrame(users,columns=['user_id'])
三、用户行为标签
3.1 用户浏览活跃时间段
#对用户和时段分组,统计浏览次数
time_browse = df[df['behavior_type']==1].groupby(['user_id','hour']).item_id.count().reset_index()time_browse.rename(columns={'item_id':'hour_counts'},inplace=True)#统计每个用户浏览次数最多的时段
time_browse_max = time_browse.groupby('user_id').hour_counts.max().reset_index()
time_browse_max.rename(columns={'hour_counts':'read_counts_max'},inplace=True)
time_browse = pd.merge(time_browse,time_browse_max,how='left',on='user_id')
#选取各用户浏览次数最多的时段,如有并列最多的时段,用逗号连接
time_browse_hour = time_browse.loc[time_browse['hour_counts']==time_browse['read_counts_max'],'hour'].groupby(time_browse['user_id']).aggregate(lambda x:','.join(x)).reset_index()
time_browse_hour.head()
| user_id | hour | |
|---|---|---|
| 0 | 492 | 晚上 |
| 1 | 3726 | 晚上 |
| 2 | 19137 | 晚上 |
| 3 | 36465 | 下午 |
| 4 | 37101 | 下午 |
#将用户浏览活跃时间段加入到用户标签表中
labels = pd.merge(labels,time_browse_hour,how='left',on='user_id')
labels.rename(columns={'hour':'time_browse'},inplace=True)
3.2 用户购买活跃时间段
#生成逻辑与浏览活跃时间段相同
time_buy = df[df['behavior_type']==4].groupby(['user_id','hour']).item_id.count().reset_index()
time_buy.rename(columns={'item_id':'hour_counts'},inplace=True)
time_buy_max = time_buy.groupby('user_id').hour_counts.max().reset_index()
time_buy_max.rename(columns={'hour_counts':'buy_counts_max'},inplace=True)
time_buy = pd.merge(time_buy,time_buy_max,how='left',on='user_id')
time_buy_hour = time_buy.loc[time_buy['hour_counts']==time_buy['buy_counts_max'],'hour'].groupby(time_buy['user_id']).aggregate(lambda x:','.join(x)).reset_index()
time_buy_hour.head()
| user_id | hour | |
|---|---|---|
| 0 | 38745 | 中午 |
| 1 | 45561 | 上午,中午 |
| 2 | 53394 | 晚上 |
| 3 | 59436 | 晚上 |
| 4 | 100605 | 凌晨 |
#将用户购买活跃时间段加入到用户标签表中
labels = pd.merge(labels,time_buy_hour,how='left',on='user_id')
labels.rename(columns={'hour':'time_buy'},inplace=True)
del time_browse
del time_buy
del time_browse_hour
del time_browse_max
del time_buy_hour
del time_buy_max
gc.collect()
168
3.3 关于类目的用户行为
df_browse = df.loc[df['behavior_type']==1,['user_id','item_id','item_category']]
df_collect = df.loc[df['behavior_type']==2,['user_id','item_id','item_category']]
df_cart = df.loc[df['behavior_type']==3,['user_id','item_id','item_category']]
df_buy = df.loc[df['behavior_type']==4,['user_id','item_id','item_category']]
3.3.1 浏览最多的类目
#对用户与类目进行分组,统计浏览次数
df_cate_most_browse = df_browse.groupby(['user_id','item_category']).item_id.count().reset_index()df_cate_most_browse.rename(columns={'item_id':'item_category_counts'},inplace=True)#统计每个用户浏览次数最多的类目
df_cate_most_browse_max = df_cate_most_browse.groupby('user_id').item_category_counts.max().reset_index()
df_cate_most_browse_max.rename(columns={'item_category_counts':'item_category_counts_max'},inplace=True)
df_cate_most_browse = pd.merge(df_cate_most_browse,df_cate_most_browse_max,how='left',on='user_id')
df_cate_most_browse['item_category'] = df_cate_most_browse['item_category'].astype(str)
#选取各用户浏览次数最多的类目,如有并列最多的类目,用逗号连接
df_cate_browse = df_cate_most_browse.loc[df_cate_most_browse['item_category_counts']==df_cate_most_browse['item_category_counts_max'],'item_category'].groupby(df_cate_most_browse['user_id']).aggregate(lambda x:','.join(x)).reset_index()
df_cate_browse.head()
| user_id | item_category | |
|---|---|---|
| 0 | 492 | 6344 |
| 1 | 3726 | 5027 |
| 2 | 19137 | 3695,3942 |
| 3 | 36465 | 12997 |
| 4 | 37101 | 1863 |
#将用户浏览最多的类目加入到用户标签表中
labels = pd.merge(labels,df_cate_browse,how='left',on='user_id')
labels.rename(columns={'item_category':'cate_most_browse'},inplace=True)
3.3.2 收藏最多的类目
#生成逻辑与浏览最多的类目相同
df_cate_most_collect = df_collect.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_collect.rename(columns={'item_id':'item_category_counts'},inplace=True)
df_cate_most_collect_max = df_cate_most_collect.groupby('user_id').item_category_counts.max().reset_index()
df_cate_most_collect_max.rename(columns={'item_category_counts':'item_category_counts_max'},inplace=True)
df_cate_most_collect = pd.merge(df_cate_most_collect,df_cate_most_collect_max,how='left',on='user_id')
df_cate_most_collect['item_category'] = df_cate_most_collect['item_category'].astype(str)
df_cate_collect = df_cate_most_collect.loc[df_cate_most_collect['item_category_counts']==df_cate_most_collect['item_category_counts_max'],'item_category'].groupby(df_cate_most_collect['user_id']).aggregate(lambda x:','.join(x)).reset_index()
df_cate_collect.head()
| user_id | item_category | |
|---|---|---|
| 0 | 36465 | 12997 |
| 1 | 38745 | 10523 |
| 2 | 45561 | 3783 |
| 3 | 59436 | 11159 |
| 4 | 60723 | 354,2939,6900,8270,8665,10242,11304,11991 |
labels = pd.merge(labels,df_cate_collect,how='left',on='user_id')
labels.rename(columns={'item_category':'cate_most_collect'},inplace=True)
3.3.3 加购最多的类目
#生成逻辑与浏览最多的类目相同
df_cate_most_cart = df_cart.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_cart = df_cart.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_cart.rename(columns={'item_id':'item_category_counts'},inplace=True)
df_cate_most_cart_max = df_cate_most_cart.groupby('user_id').item_category_counts.max().reset_index()
df_cate_most_cart_max.rename(columns={'item_category_counts':'item_category_counts_max'},inplace=True)
df_cate_most_cart = pd.merge(df_cate_most_cart,df_cate_most_cart_max,how='left',on='user_id')
df_cate_most_cart['item_category'] = df_cate_most_cart['item_category'].astype(str)
df_cate_cart = df_cate_most_cart.loc[df_cate_most_cart['item_category_counts']==df_cate_most_cart['item_category_counts_max'],'item_category'].groupby(df_cate_most_cart['user_id']).aggregate(lambda x:','.join(x)).reset_index()
df_cate_cart.head()
| user_id | item_category | |
|---|---|---|
| 0 | 3726 | 6000 |
| 1 | 37101 | 6344 |
| 2 | 45561 | 1863,6648 |
| 3 | 59436 | 2754 |
| 4 | 61797 | 13230 |
labels = pd.merge(labels,df_cate_cart,how='left',on='user_id')
labels.rename(columns={'item_category':'cate_most_cart'},inplace=True)
3.3.4 购买最多的类目
#生成逻辑与浏览最多的类目相同
df_cate_most_buy = df_buy.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_buy = df_buy.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_buy.rename(columns={'item_id':'item_category_counts'},inplace=True)
df_cate_most_buy_max = df_cate_most_buy.groupby('user_id').item_category_counts.max().reset_index()
df_cate_most_buy_max.rename(columns={'item_category_counts':'item_category_counts_max'},inplace=True)
df_cate_most_buy = pd.merge(df_cate_most_buy,df_cate_most_buy_max,how='left',on='user_id')
df_cate_most_buy['item_category'] = df_cate_most_buy['item_category'].astype(str)
df_cate_buy = df_cate_most_buy.loc[df_cate_most_buy['item_category_counts']==df_cate_most_buy['item_category_counts_max'],'item_category'].groupby(df_cate_most_buy['user_id']).aggregate(lambda x:','.join(x)).reset_index()
df_cate_buy.head()
| user_id | item_category | |
|---|---|---|
| 0 | 38745 | 10556 |
| 1 | 45561 | 6717,10559 |
| 2 | 53394 | 13500 |
| 3 | 59436 | 4370 |
| 4 | 100605 | 930,3783,11455 |
labels = pd.merge(labels,df_cate_buy,how='left',on='user_id')
labels.rename(columns={'item_category':'cate_most_buy'},inplace=True)
del df_browse
del df_collect
del df_cart
del df_buy
del df_cate_most_browse
del df_cate_most_collect
del df_cate_most_buy
del df_cate_most_cart
del df_cate_most_browse_max
del df_cate_most_collect_max
del df_cate_most_cart_max
del df_cate_most_buy_max
del df_cate_browse
del df_cate_collect
del df_cate_cart
del df_cate_buy
gc.collect(0)
112
3.4 30天用户行为
- 数据集中的数据正好是一个月,30天的数据即整个数据集的数据
3.4.1 近30天购买次数
#将购买行为按用户进行分组,统计次数
df_counts_30_buy = df[df['behavior_type']==4].groupby('user_id').item_id.count().reset_index()
df_counts_30_buy.head()
| user_id | item_id | |
|---|---|---|
| 0 | 38745 | 2 |
| 1 | 45561 | 2 |
| 2 | 53394 | 1 |
| 3 | 59436 | 4 |
| 4 | 100605 | 3 |
labels = pd.merge(labels,df_counts_30_buy,how='left',on='user_id')
labels.rename(columns={'item_id':'counts_30_buy'},inplace=True)
3.4.2 近30天加购次数
#将加购行为按用户进行分组,统计次数
df_counts_30_cart = df[df['behavior_type']==3].groupby('user_id').item_id.count().reset_index()
df_counts_30_cart.head()
| user_id | item_id | |
|---|---|---|
| 0 | 3726 | 1 |
| 1 | 37101 | 1 |
| 2 | 45561 | 22 |
| 3 | 59436 | 9 |
| 4 | 61797 | 5 |
labels = pd.merge(labels,df_counts_30_cart,how='left',on='user_id')
labels.rename(columns={'item_id':'counts_30_cart'},inplace=True)
3.4.3 近30天活跃天数
#对用户进行分组,统计活跃的天数,包括浏览、收藏、加购、购买
counts_30_active = df.groupby('user_id')['date'].nunique()
counts_30_active.head()
user_id
492 11
3726 15
19137 6
36465 7
37101 19
Name: date, dtype: int64
labels = pd.merge(labels,counts_30_active,how='left',on='user_id')
labels.rename(columns={'date':'counts_30_active'},inplace=True)
del df_counts_30_buy
del df_counts_30_cart
del counts_30_active
gc.collect()
238
3.5 7天用户行为
#数据集中的最后日期是12月18号,统计11号之后的用户行为
df_near_7 = df[df['date']>datetime.strptime('2014-12-11', '%Y-%m-%d')]
3.5.1 近7天购买次数
df_counts_7_buy = df_near_7[df_near_7['behavior_type']==4].groupby('user_id').item_id.count().reset_index()
df_counts_7_buy.head()
| user_id | item_id | |
|---|---|---|
| 0 | 45561 | 2 |
| 1 | 59436 | 1 |
| 2 | 100605 | 2 |
| 3 | 100890 | 1 |
| 4 | 131694 | 2 |
labels = pd.merge(labels,df_counts_7_buy,how='left',on='user_id')
labels.rename(columns={'item_id':'counts_7_buy'},inplace=True)
3.5.2 近7天加购次数
df_counts_7_cart = df_near_7[df_near_7['behavior_type']==3].groupby('user_id').item_id.count().reset_index()
df_counts_7_cart.head()
| user_id | item_id | |
|---|---|---|
| 0 | 3726 | 1 |
| 1 | 45561 | 9 |
| 2 | 59436 | 7 |
| 3 | 100605 | 2 |
| 4 | 131694 | 3 |
labels = pd.merge(labels,df_counts_7_cart,how='left',on='user_id')
labels.rename(columns={'item_id':'counts_7_cart'},inplace=True)
3.5.3 近7天活跃天数
counts_7_active = df_near_7.groupby('user_id')['date'].nunique()
counts_7_active.head()
user_id
492 4
3726 5
19137 1
36465 2
37101 5
Name: date, dtype: int64
labels = pd.merge(labels,counts_7_active,how='left',on='user_id')
labels.rename(columns={'date':'counts_7_active'},inplace=True)
del df_counts_7_buy
del df_counts_7_cart
del counts_7_active
gc.collect()
112
3.6 最后一次行为距今天数
3.6.1 上次浏览距今天数
days_browse = df[df['behavior_type']==1].groupby('user_id')['date'].max().apply(lambda x:(datetime.strptime('2014-12-19','%Y-%m-%d')-x).days)
days_browse.head()
user_id
492 1
3726 1
19137 7
36465 3
37101 3
Name: date, dtype: int64
labels = pd.merge(labels,days_browse,how='left',on='user_id')labels.rename(columns={'date':'days_browse'},inplace=True)
3.6.2 上次加购距今天数
days_cart = df[df['behavior_type']==3].groupby('user_id')['date'].max().apply(lambda x:(datetime.strptime('2014-12-19','%Y-%m-%d')-x).days)
days_cart.head()
user_id
3726 1
37101 8
45561 1
59436 4
61797 18
Name: date, dtype: int64
labels = pd.merge(labels,days_cart,how='left',on='user_id')
labels.rename(columns={'date':'days_cart'},inplace=True)
3.6.3上次购买距今天数
days_buy = df[df['behavior_type']==4].groupby('user_id')['date'].max().apply(lambda x:(datetime.strptime('2014-12-19','%Y-%m-%d')-x).days)
days_buy.head()
user_id
38745 23
45561 6
53394 22
59436 7
100605 7
Name: date, dtype: int64
labels = pd.merge(labels,days_buy,how='left',on='user_id')
labels.rename(columns={'date':'days_buy'},inplace=True)del days_browse
del days_buy
del days_cart
gc.collect()
42
3.7 最近两次购买间隔天数
df_interval_buy = df[df['behavior_type']==4].groupby(['user_id','date']).item_id.count().reset_index()interval_buy = df_interval_buy.groupby('user_id')['date'].apply(lambda x:x.sort_values().diff(1).dropna().head(1)).reset_index()interval_buy['date'] = interval_buy['date'].apply(lambda x : x.days)interval_buy.drop('level_1',axis=1,inplace=True)interval_buy.rename(columns={'date':'interval_buy'},inplace=True)
interval_buy.head()
| user_id | interval_buy | |
|---|---|---|
| 0 | 59436 | 2 |
| 1 | 100605 | 3 |
| 2 | 106362 | 2 |
| 3 | 131694 | 3 |
| 4 | 137907 | 9 |
labels = pd.merge(labels,interval_buy,how='left',on='user_id')del df_interval_buy
gc.collect()
70
3.8是否浏览未下单
df_browse_buy = df.loc[(df['behavior_type']==1) | (df['behavior_type']==4),['user_id','item_id','behavior_type','time']]browse_not_buy = pd.pivot_table(df_browse_buy,index=['user_id','item_id'],columns=['behavior_type'],values=['time'],aggfunc=['count'])browse_not_buy.columns = ['browse','buy']browse_not_buy.fillna(0,inplace=True)browse_not_buy['browse_not_buy'] = 0browse_not_buy.loc[(browse_not_buy['browse']>0) & (browse_not_buy['buy']==0),'browse_not_buy'] = 1browse_not_buy = browse_not_buy.groupby('user_id')['browse_not_buy'].sum().reset_index()browse_not_buy.head()
| user_id | browse_not_buy | |
|---|---|---|
| 0 | 492 | 34 |
| 1 | 3726 | 68 |
| 2 | 19137 | 10 |
| 3 | 36465 | 12 |
| 4 | 37101 | 118 |
labels = pd.merge(labels,browse_not_buy,how='left',on='user_id')labels['browse_not_buy'] = labels['browse_not_buy'].apply(lambda x: '是' if x>0 else '否')
3.9 是否加购未下单
df_cart_buy = df.loc[(df['behavior_type']==3) | (df['behavior_type']==4),['user_id','item_id','behavior_type','time']]
cart_not_buy = pd.pivot_table(df_cart_buy,index=['user_id','item_id'],columns=['behavior_type'],values=['time'],aggfunc=['count'])
cart_not_buy.columns = ['cart','buy']
cart_not_buy.fillna(0,inplace=True)
cart_not_buy['cart_not_buy'] = 0
cart_not_buy.loc[(cart_not_buy['cart']>0) & (cart_not_buy['buy']==0),'cart_not_buy'] = 1
cart_not_buy = cart_not_buy.groupby('user_id')['cart_not_buy'].sum().reset_index()
cart_not_buy.head()
| user_id | cart_not_buy | |
|---|---|---|
| 0 | 3726 | 1 |
| 1 | 37101 | 1 |
| 2 | 38745 | 0 |
| 3 | 45561 | 22 |
| 4 | 53394 | 0 |
labels = pd.merge(labels,cart_not_buy,how='left',on='user_id')
labels['cart_not_buy'] = labels['cart_not_buy'].apply(lambda x: '是' if x>0 else '否')
四、 用户属性标签
4.1 是否复购用户
buy_again = df[df['behavior_type']==4].groupby('user_id')['item_id'].count().reset_index()buy_again.rename(columns={'item_id':'buy_again'},inplace=True)buy_again.head()
| user_id | buy_again | |
|---|---|---|
| 0 | 38745 | 2 |
| 1 | 45561 | 2 |
| 2 | 53394 | 1 |
| 3 | 59436 | 4 |
| 4 | 100605 | 3 |
labels = pd.merge(labels,buy_again,how='left',on='user_id')labels['buy_again'].fillna(-1,inplace=True)
#未购买的用户标记为‘未购买’,有购买未复购的用户标记为‘否’,有复购的用户标记为‘是’
labels['buy_again'] = labels['buy_again'].apply(lambda x: '是' if x>1 else '否' if x==1 else '未购买')
4.2 访问活跃度
user_active_level = labels['counts_30_active'].value_counts().sort_index(ascending=False)plt.figure(figsize=(16,9))
user_active_level.plot(title='30天内访问次数与访问人数的关系',fontsize=18)
plt.ylabel('访问人数',fontsize=14)
plt.xlabel('访问次数',fontsize=14)
Text(0.5, 0, ‘访问次数’)
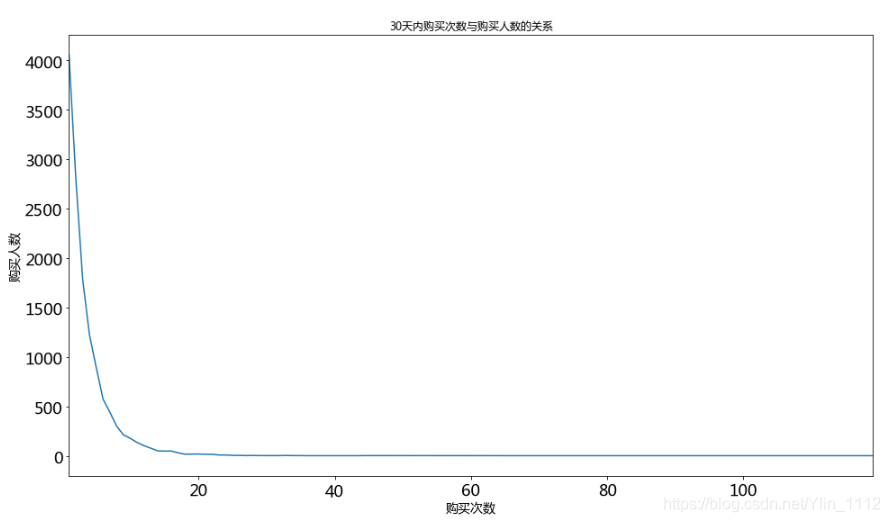
**分析:**14次左右是个拐点,因此定义购买次数小于等于14次为低活跃,大于14次为高活跃,此定义只是从用户的分布角度出发,工作中当从业务出发定义是否活跃。
labels['buy_active_level'] = '高'
labels.loc[labels['counts_30_buy']<=14,'buy_active_level'] = '低'
4.3 购买的品类是否单一
buy_single = df[df['behavior_type']==4].groupby('user_id').item_category.nunique().reset_index()buy_single.rename(columns={'item_category':'buy_single'},inplace=True)labels = pd.merge(labels,buy_single,how='left',on='user_id')
labels['buy_single'].fillna(-1,inplace=True)
labels['buy_single'] = labels['buy_single'].apply(lambda x: '是' if x>1 else '否' if x==1 else '未购买' )
4.4 用户价值分组(RFM)
last_buy_days = labels['days_buy'].value_counts().sort_index()plt.figure(figsize=(16,9))
last_buy_days.plot(title='最后一次购买距今天数与购买人数的关系',fontsize=18)
plt.ylabel('购买人数',fontsize=14)
plt.xlabel('距今天数',fontsize=14)
Text(0.5, 0, ‘距今天数’)
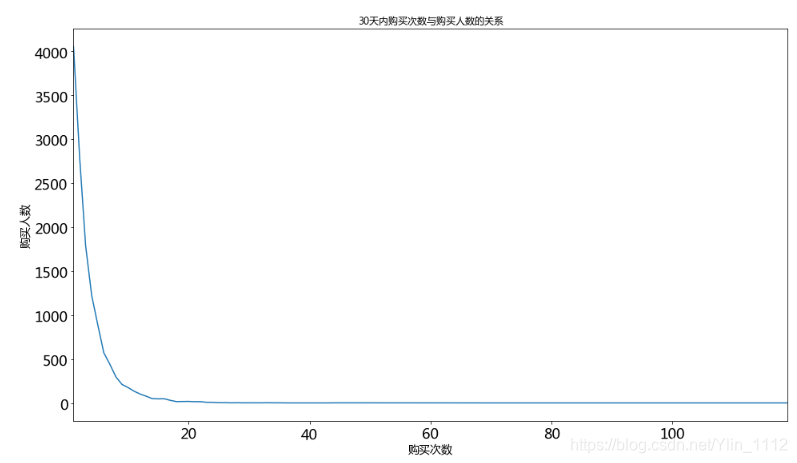
注:访问异常的那天为双12
labels['buy_days_level'] = '高'
labels.loc[labels['days_buy']>8,'buy_days_level'] = '低'
labels['rfm_value'] = labels['buy_active_level'].str.cat(labels['buy_days_level'])
def trans_value(x):if x == '高高':return '重要价值客户'elif x == '低高':return '重要深耕客户'elif x == '高低':return '重要唤回客户'else: return '即将流失客户'
labels['rfm'] = labels['rfm_value'].apply(trans_value)
labels.drop(['buy_days_level','rfm_value'],axis=1,inplace=True)
labels['rfm'].value_counts()
重要深耕客户 7167
重要价值客户 7142
即将流失客户 5631
重要唤回客户 16
Name: rfm, dtype: int64
| user_id | time_browse | time_buy | cate_most_browse | cate_most_collect | cate_most_cart | cate_most_buy | counts_30_buy | counts_30_cart | counts_30_active | … | days_cart | days_buy | interval_buy | browse_not_buy | cart_not_buy | buy_again | user_active_level | buy_active_level | buy_single | rfm | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 34517089 | 中午 | 上午 | 11241 | 11824 | 603 | 603 | 1.0 | 3.0 | 24 | … | 18.0 | 18.0 | NaN | 是 | 是 | 否 | 高 | 低 | 否 | 即将流失客户 |
| 1 | 136592808 | 下午 | 下午 | 7098 | 10879 | 7957 | 7957,9772,12753 | 3.0 | 5.0 | 21 | … | 6.0 | 2.0 | 1.0 | 是 | 是 | 是 | 高 | 低 | 是 | 重要深耕客户 |
| 2 | 117599174 | 上午 | 凌晨,上午,下午,晚上 | 5894 | 6054 | 6936,8291,9102 | 2949,5550,10258,12982 | 4.0 | 3.0 | 25 | … | 2.0 | 7.0 | 4.0 | 是 | 是 | 是 | 高 | 低 | 是 | 重要深耕客户 |
| 3 | 38516732 | 晚上 | 下午 | 9693 | 3783 | 9397,13926 | 10500 | 11.0 | 41.0 | 29 | … | 2.0 | 2.0 | 3.0 | 是 | 是 | 是 | 高 | 低 | 是 | 重要深耕客户 |
| 4 | 29120381 | 晚上 | NaN | 6513 | NaN | 3944 | NaN | NaN | 4.0 | 13 | … | 2.0 | NaN | NaN | 是 | 是 | 未购买 | 低 | 高 | 未购买 | 重要价值客户 |
接下来是对用户画像的详细分析,包括用户个性化标签、用户偏好标签、群体偏好标签,涉及到TF-IDF算法、余弦相似度算法
- 首先,对数据进行预处理
#提取日期
df_orginal['time'] = df_orginal['time'].str[0:10]
#填充字段'user_geohash',作为下一步groupby的计数字段
df_orginal['user_geohash'].fillna('1',inplace=True)
#对所有数据按'user_id','item_id','behavior_type','item_category','time'进行分组
df = df_orginal.groupby(['user_id','item_id','behavior_type','item_category','time'])['user_geohash'].count().reset_index()
df.rename(columns={'user_geohash':'behavior_count'},inplace=True)
df.head()
| user_id | item_id | behavior_type | item_category | time | behavior_count | |
|---|---|---|---|---|---|---|
| 0 | 492 | 254885 | 1 | 6344 | 2014-12-07 | 9 |
| 1 | 492 | 254885 | 3 | 6344 | 2014-12-07 | 1 |
| 2 | 492 | 254885 | 4 | 6344 | 2014-12-07 | 1 |
| 3 | 492 | 2316002 | 1 | 6247 | 2014-12-09 | 3 |
| 4 | 492 | 3473697 | 1 | 2413 | 2014-12-12 | 2 |
#回收内存
del df_orginal
gc.collect()
df['time'] = pd.to_datetime(df['time'])
五、用户个性化标签
5.1 应用TF-IDF算法计算标签权重
# 计算每个用户身上每个标签的个数
df_tag_weight_tfidf_01_01 = df.groupby(['user_id','item_id'])['time'].count().reset_index()
df_tag_weight_tfidf_01_01.rename(columns={'time':'weight_m_p'},inplace=True)# 计算每个用户身上的标签总数
df_tag_weight_tfidf_01_02 = df.groupby(['user_id'])['time'].count().reset_index()
df_tag_weight_tfidf_01_02.rename(columns={'time':'weight_m_s'},inplace=True)
df_tag_weight_tfidf_01 = pd.merge(df_tag_weight_tfidf_01_01,df_tag_weight_tfidf_01_02,how='left',on='user_id')
# 每个标签的行为数
df_tag_weight_tfidf_02 = df_tag_weight_tfidf_01.groupby(['item_id']).weight_m_p.sum().reset_index()
df_tag_weight_tfidf_02.rename(columns={'weight_m_p':'weight_w_p'},inplace=True)
# 所有标签的总和
df_tag_weight_tfidf_02['weight_w_s'] = df_tag_weight_tfidf_01['weight_m_p'].sum()
df_tag_weight_tfidf_03 = pd.merge(df_tag_weight_tfidf_01,df_tag_weight_tfidf_02,how='left',on='item_id')# 应用TF-IDF计算标签权重
df_tag_weight_tfidf_03['tfidf_ratio'] = (df_tag_weight_tfidf_03['weight_m_p']/df_tag_weight_tfidf_03['weight_m_s'])*(np.log10(df_tag_weight_tfidf_03['weight_w_s']/df_tag_weight_tfidf_03['weight_w_p']))
df = pd.merge(df,df_tag_weight_tfidf_03[['user_id','item_id','tfidf_ratio']],how='left',on=['user_id','item_id']).reset_index(drop=True)del df_tag_weight_tfidf_01_01
del df_tag_weight_tfidf_01_02
del df_tag_weight_tfidf_01
del df_tag_weight_tfidf_02
del df_tag_weight_tfidf_03
gc.collect()
101
5.2 建立行为类型权重维表
浏览行为,权重0.3
收藏行为,权重0.5
加购行为,权重1
购买行为,权重1.5
df['act_weight_plan'] = 0.3
df.loc[df['behavior_type']==2,'act_weight_plan']=0.5
df.loc[df['behavior_type']==3,'act_weight_plan']=1
df.loc[df['behavior_type']==4,'act_weight_plan']=1.5
5.3 计算用户标签权重
#标签权重衰减函数
#本项目中,加购行为的权重不随着时间的增长而衰减,而购买、浏览、收藏随着时间的推移,其对当前的参考性越来越弱,因此权重会随着时间的推移越来越低
def weight_time_reduce(act_date):date_interval = datetime.strptime('2014-12-19', '%Y-%m-%d') - act_datedate_interval = date_interval.daystime_reduce_ratio = np.exp(date_interval*(-0.1556))return time_reduce_ratio
df['time_reduce_ratio'] = 1
df.loc[df['behavior_type']!=3,'time_reduce_ratio'] = df.loc[df['time_reduce_ratio']!=3,'time'].apply(lambda x:weight_time_reduce(x))# 标签总权重 = 行为类型权重*衰减系数*行为数*TFIDF标签权重
df['act_weight'] = df['act_weight_plan']*df['time_reduce_ratio']*df['behavior_count']*df['tfidf_ratio']
df.head(5)
| user_id | item_id | behavior_type | item_category | time | behavior_count | tfidf_ratio | act_weight_plan | time_reduce_ratio | act_weight | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 492 | 254885 | 1 | 6344 | 2014-12-07 | 9 | 0.149319 | 0.3 | 0.154556 | 0.062311 |
| 1 | 492 | 254885 | 3 | 6344 | 2014-12-07 | 1 | 0.149319 | 1.0 | 1.000000 | 0.149319 |
| 2 | 492 | 254885 | 4 | 6344 | 2014-12-07 | 1 | 0.149319 | 1.5 | 0.154556 | 0.034617 |
| 3 | 492 | 2316002 | 1 | 6247 | 2014-12-09 | 3 | 0.062962 | 0.3 | 0.210978 | 0.011955 |
| 4 | 492 | 3473697 | 1 | 2413 | 2014-12-12 | 2 | 0.060274 | 0.3 | 0.336486 | 0.012169 |
六、用户偏好标签
# 要计算两两标签的相似性,计算量太大,服务器性能有限,在此只选取有过购买的标签
user_tag_public = df[df['behavior_type']==4]
user_tag_01 = user_tag_public[['user_id','item_id']]
#user_tag_02 = df.loc[df['behavior_type']==4,['user_id','item_id']]
6.1 计算两两标签共同对应的用户数
# 将两表正交,得到每个用户下,其所有标签的的两两组合
user_tag_02 = pd.merge(user_tag_01,user_tag_01,on='user_id')# 删除重复值,即同一用户由上述正交得到的数据表中,两个标签为同一标签的数据
user_tag_03 = user_tag_02.drop(labels=user_tag_02[user_tag_02['item_id_x']==user_tag_02['item_id_y']].index,axis=0)
# 用两个标签分组,计算用户数,即每两个标签同时出现在不同的用户中的个数
user_tag = user_tag_03.groupby(['item_id_x','item_id_y'])['user_id'].count().reset_index()
user_tag.rename(columns={'user_id':'counts_common'},inplace=True)
6.2 计算每个标签对应的用户数
# 计算每一个标签对应的不同的用户数,即每个标签出现在不同的用户中的个数
user_tag_05 = user_tag_01.groupby(['item_id'])['user_id'].nunique().reset_index()
user_tag_05.rename(columns={'user_id':'counts_item_user'},inplace=True)
# 计算标签1有关的用户数
user_tag = pd.merge(user_tag,user_tag_05,how='left',left_on='item_id_x',right_on='item_id').drop('item_id_x',axis=1)
user_tag.rename(columns={'counts_item_user':'counts_item_x','item_id':'item_id_x'},inplace=True)
# 计算标签2有关的用户数
user_tag = pd.merge(user_tag,user_tag_05,how='left',left_on='item_id_y',right_on='item_id').drop('item_id_y',axis=1)
user_tag.rename(columns={'counts_item_user':'counts_item_y','item_id':'item_id_y'},inplace=True)
6.3 计算两两标签之间的相似性
# 余弦相似度计算两两标签的相关性
user_tag['power'] = user_tag['counts_common'] / np.sqrt(user_tag['counts_item_x']*user_tag['counts_item_y'])
6.4 对每个用户的历史标签权重加总
# 对用户、标签进行分组,计算每个用户每个标签的权重和
user_tag_06 = user_tag_public.groupby(['user_id','item_id'])['act_weight'].sum().reset_index()
6.5 计算推荐给用户的相关标签
# 将用户与所有与其有关的标签作对应
user_peasona_tag = pd.merge(user_tag_06,user_tag,how='left',left_on='item_id',right_on='item_id_x').drop('item_id',axis=1)del user_tag_01
del user_tag_02
del user_tag_03
del user_tag_05
del user_tag_06
gc.collect()
77
# 计算推荐得分值 得分值 = 行为权重*相关性
user_peasona_tag['recommend'] = user_peasona_tag['act_weight']*user_peasona_tag['power']# 对所有数据按得分值排序,再按’user_id'分组,得到每个用户有关的得分值最高的10个标签
user_peasona_tag_total = user_peasona_tag.sort_values('recommend', ascending=False).groupby(['user_id']).head(10)
user_peasona_tag_total.head(10)
| user_id | act_weight | counts_common | item_id_x | counts_item_x | item_id_y | counts_item_y | power | recommend | |
|---|---|---|---|---|---|---|---|---|---|
| 941565 | 16680502 | 6.132241 | 176.0 | 354309086.0 | 1.0 | 337331963.0 | 2.0 | 124.450793 | 763.162218 |
| 941547 | 16680502 | 2.591208 | 176.0 | 337331963.0 | 2.0 | 354309086.0 | 1.0 | 124.450793 | 322.477880 |
| 941558 | 16680502 | 6.132241 | 22.0 | 354309086.0 | 1.0 | 177149139.0 | 1.0 | 22.000000 | 134.909295 |
| 4517695 | 61545656 | 1.393036 | 88.0 | 131284675.0 | 1.0 | 250218619.0 | 1.0 | 88.000000 | 122.587185 |
| 4517697 | 61545656 | 1.393036 | 77.0 | 131284675.0 | 1.0 | 270996967.0 | 1.0 | 77.000000 | 107.263787 |
| 4517934 | 61545656 | 0.890714 | 88.0 | 250218619.0 | 1.0 | 131284675.0 | 1.0 | 88.000000 | 78.382824 |
| 4517685 | 61545656 | 1.393036 | 55.0 | 131284675.0 | 1.0 | 36667020.0 | 1.0 | 55.000000 | 76.616990 |
| 529309 | 11279964 | 5.639947 | 19.0 | 168681351.0 | 2.0 | 395358462.0 | 1.0 | 13.435029 | 75.772847 |
| 529307 | 11279964 | 5.639947 | 19.0 | 168681351.0 | 2.0 | 379008813.0 | 1.0 | 13.435029 | 75.772847 |
| 529306 | 11279964 | 5.639947 | 19.0 | 168681351.0 | 2.0 | 375010017.0 | 1.0 | 13.435029 | 75.772847 |
del user_peasona_tag
del user_peasona_tag_total
gc.collect()
7
七、群体用户画像标签
需要先对用户人群进行分类,为了降低复杂性并实现群体用户画像标签的设计,暂时先随机对用户进行指定性别,以后有时间将对上部划分出来的用户群体进行画像标签设计
7.1 随机指定性别并划分群体
user = pd.DataFrame(df['user_id'].unique(),columns=['user_id'])user['sex'] = np.random.randint(0,2,(20000))
user.loc[user['sex']==1,'sex'] = '男'
user.loc[user['sex']==0,'sex'] = '女'
df_group = pd.merge(df[['user_id','item_id','act_weight']],user,how='left',on='user_id')del df
gc.collect()
36
df_group.head(5)
| user_id | item_id | act_weight | sex | |
|---|---|---|---|---|
| 0 | 492 | 254885 | 0.062311 | 女 |
| 1 | 492 | 254885 | 0.149319 | 女 |
| 2 | 492 | 254885 | 0.034617 | 女 |
| 3 | 492 | 2316002 | 0.011955 | 女 |
| 4 | 492 | 3473697 | 0.012169 | 女 |
7.2 使用TF-IDF计算不同人群的标签偏好
# 计算每个性别、每个标签的权重加总
df_group_weight_tfidf_01_01 = df_group.groupby(['sex','item_id'])['act_weight'].sum().reset_index()df_group_weight_tfidf_01_01.head(5)
| sex | item_id | act_weight | |
|---|---|---|---|
| 0 | 女 | 64 | 0.008926 |
| 1 | 女 | 270 | 0.000093 |
| 2 | 女 | 391 | 0.000333 |
| 3 | 女 | 668 | 0.000369 |
| 4 | 女 | 869 | 0.000324 |
df_group_weight_tfidf_01_01.rename(columns={'act_weight':'weight_m_p'},inplace=True)
# 计算每个性别的所有标签的权重加总
df_group_weight_tfidf_01_02 = df_group.groupby(['sex'])['act_weight'].sum().reset_index()
df_group_weight_tfidf_01_02.rename(columns={'act_weight':'weight_m_s'},inplace=True)
df_group_weight_tfidf_01 = pd.merge(df_group_weight_tfidf_01_01,df_group_weight_tfidf_01_02,how='left',on='sex')
df_group_weight_tfidf_01.head(5)
| sex | item_id | weight_m_p | weight_m_s | |
|---|---|---|---|---|
| 0 | 女 | 64 | 0.008926 | 26497.333993 |
| 1 | 女 | 270 | 0.000093 | 26497.333993 |
| 2 | 女 | 391 | 0.000333 | 26497.333993 |
| 3 | 女 | 668 | 0.000369 | 26497.333993 |
| 4 | 女 | 869 | 0.000324 | 26497.333993 |
# 计算每个标签的权重加总
df_group_weight_tfidf_02 = df_group_weight_tfidf_01.groupby(['item_id'])['weight_m_p'].sum().reset_index()
df_group_weight_tfidf_02.rename(columns={'weight_m_p':'weight_w_p'},inplace=True)
# 计算所有标签的权重加总
df_group_weight_tfidf_02['weight_w_s'] = df_group_weight_tfidf_01['weight_m_p'].sum()
df_group_weight_tfidf_02.head(5)
| item_id | weight_w_p | weight_w_s | |
|---|---|---|---|
| 0 | 37 | 0.006981 | 53319.602753 |
| 1 | 64 | 0.009180 | 53319.602753 |
| 2 | 177 | 0.000028 | 53319.602753 |
| 3 | 270 | 0.000093 | 53319.602753 |
| 4 | 368 | 0.000358 | 53319.602753 |
df_group_weight_tfidf_03 = pd.merge(df_group_weight_tfidf_01,df_group_weight_tfidf_02,how='left',on='item_id')
# 使用TF-IDF算法计算每个性别对每个标签的偏好权重值
df_group_weight_tfidf_03['tfidf_ratio'] = (df_group_weight_tfidf_03['weight_m_p']/df_group_weight_tfidf_03['weight_m_s'])*(df_group_weight_tfidf_03['weight_w_s']/df_group_weight_tfidf_03['weight_w_p'])del df_group
del df_group_weight_tfidf_01_01
del df_group_weight_tfidf_01_02
del df_group_weight_tfidf_01
del df_group_weight_tfidf_02
gc.collect()
34
# 对所有数据按得分值排序,再按性别分组,得到每个性别得分值最高的10个标签
df_group_weight = df_group_weight_tfidf_03.sort_values('tfidf_ratio', ascending=False).groupby(['sex']).head(10)
df_group_weight.head(15)
| sex item_id | weight_m_p | weight_m_s | weight_w_p | weight_w_s | tfidf_ratio | |
|---|---|---|---|---|---|---|
| 1949040 | 女 | 285531425 | 0.001849 | 26497.333993 | 0.001849 | 53319.602753 |
| 839482 | 女 | 123092722 | 0.013124 | 26497.333993 | 0.013124 | 53319.602753 |
| 839460 | 女 | 123089014 | 0.000588 | 26497.333993 | 0.000588 | 53319.602753 |
| 1976591 | 女 | 289570426 | 0.000451 | 26497.333993 | 0.000451 | 53319.602753 |
| 839463 | 女 | 123089770 | 0.000002 | 26497.333993 | 0.000002 | |
| 1976588 | 女 | 289570130 | 0.000143 | 26497.333993 | 0.000143 | 53319.602753 |
| 1976587 | 女 | 289570063 | 0.000196 | 26497.333993 | 0.000196 | 53319.602753 |
| 1976586 | 女 | 289569845 | 0.000010 | 26497.333993 | 0.000010 | 53319.602753 |
| 1976585 | 女 | 289569647 | 0.000782 | 26497.333993 | 0.000782 | 53319.602753 |
| 1976581 | 女 | 289569188 | 0.089799 | 26497.333993 | 0.089799 | 53319.602753 |
| 3521579 | 男 | 111562094 | 0.000046 | 26822.268761 | 0.000046 | 53319.602753 |
| 5292053 | 男 | 371765933 | 0.000012 | 26822.268761 | 0.000012 | 53319.602753 |
| 4371778 | 男 | 236398624 | 0.000206 | 26822.268761 | 0.000206 | 53319.602753 |
| 4437179 | 男 | 246007442 | 0.007151 | 26822.268761 | 0.007151 | 53319.602753 |
| 5174663 | 男 | 354526634 | 0.000209 | 26822.268761 | 0.000209 | 53319.602753 |