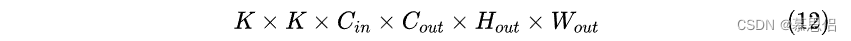客户画像会用聚类分析
实际工作中,最常使用的当属回归类模型,其次便是客户画像。即便是评分模型也会涉及到客户画像,由于首富客户的违约特征与普通百姓不同,故需进行区分,信用分池即为客户画像。
客户画像使用的技术为聚类分析,在营销场景中经常会逻辑回归模型与聚类分析一起配合构建模型。

聚类分析是什么?
聚类分析可以理解为利用数据公式具体的计算样本的相似程度,将相似的样本归为一类,将不相似的样本归为一类。例如:
- 对奶茶加盟店的经营业绩进行分类;
-
对来商场消费的客户进行分类;
-
评估一个产品的好坏时,将繁复的评价指标进行分类,从而简化评估体系。

聚类分析专门针对看上去不好区分、但必须区分的数据。决策树、逻辑回归模型以及神经网络中皆有Y,样本中已经区分出了好坏,最终好坏样本差距越大则说明模型效果越好,如好坏样本无差别,则模型有错误需要修正。但如果样本中没有Y,则加大了好坏样本的区分难度,此时便需要使用聚类分析。
聚类分析与逻辑回归是不同的模型体系
模型可以大致理解为两种:
- 有监督模型、验证性模型、预测模型:有X有Y,例如逻辑回归模型、决策树模型以及神经网络
- 无监督训练模型、探索模型、模式发现:有X无Y例如聚类分析,有Y无X例如产品推荐算法

需要说明的是,模式发现实现的技术较多,但是大部分只是存在于博士论文之中,实际工作中能够用到的很少。由于与预测类模型相比,模式发现对数据的要求极高,例如,在从实际应用效果的角度来看,聚类分析对数据的要求要比所有的分类选择模型的要求高许多,即聚类分析的假定要严格许多,只是大部分情况下, 人们使用聚类分析的时候,不会提及到它的假定罢了。
聚类分析的弊端?
决策树有一个最大的弊端,即变更数据集后,做好的规则变动较大,即便变量固定仅仅换了观测,决策树的结果也会完全不同,但是,即便决策树的变动性如此大,决策树都要比聚类分析稳定的多。
可见聚类分析是如此的不稳定,因此想做好聚类分析,必须要遵循完整的数据分析流程,才能够保证建模数据的稳定以及结果的可靠。

聚类分析的流程?
聚类分析的基本流程为:
- 数据准备:包含变量与观测的选择、变量的分布分析以及量纲选择
- 聚类分析
- 聚类后处理:包含类数的确定以及标签的确定
- 模型的部署

需要注意的是,虽然变量聚类也带有聚类两个字,但是并不是聚类分析算法,而是一种主成分分析。而且,由于业务人员不懂聚类算法,所以需要聚类分析后,构建完善相应的标签系统。
红楼梦到底谁写的?
可以使用聚类分析来判断红楼梦的作者,通过分析红楼梦的语言风格,将红楼梦120回中的每一回视作一个观测,将虚词频次视作分析变量,做聚类分析。
单独对前八十回进行聚类分析,分析发现前八十回语言风格非常相似,则可以判断前八十回的作者为同一人(曹雪芹);单独对后四十回进行聚类分析,分析发现后四十回无法聚为一类,则可判断后四十回的作者并非为同一个人;对前八十回与后四十回进行聚类分析,分析发现前后两部分无法聚为一类,则可判断后四十回可能不是曹雪芹所写。
所以,关于红楼梦的作者,很多资料中说其前八十回由曹雪芹所著,后四十回由无名氏编写高鹗编辑,很有意思。

我的公众号:Data Analyst
个人网站:https://www.datanalyst.net/