转自: 百丽百灵(ID:BL100BL)
转自数据分析公号,来源:数据客
什么是用户画像?
用户画像(User Profile),作为大数据的根基,它完美地抽象出一个用户的信息全貌,为进一步精准、快速地分析用户行为习惯、消费习惯等重要信息,提供了足够的数据基础,奠定了大数据时代的基石。
用户画像,即用户信息标签化,就是企业通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌作是企业应用大数据技术的基本方式。用户画像为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息。
用户画像的四阶段
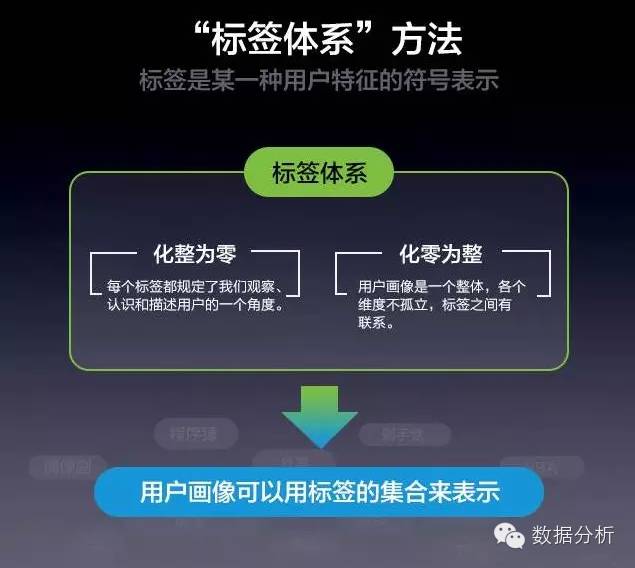
用户画像的焦点工作就是为用户打“标签”,而一个标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、用户偏好等,最后将用户的所有标签综合来看,就可以勾勒出该用户的立体“画像”了。
具体来讲,当为用户画像时,需要以下四个阶段:
用户画像的意义
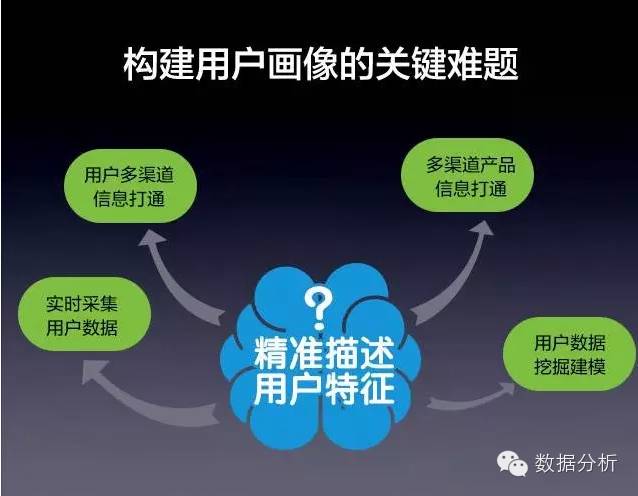
用户画像的构建是有难度的。主要表现为以下四个方面:
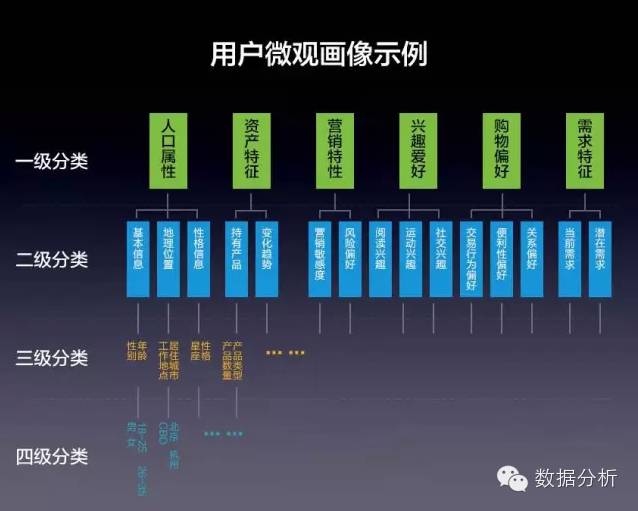
为了精准地描述用户特征,可以参考下面的思路,从用户微观画像的建立→用户画像的标签建模→用户画像的数据架构,我们由微观到宏观,逐层分析。
首先我们从微观来看,如何给用户的微观画像进行分级呢?如下图所示
总原则:基于一级分类上述分类逐级进行细分。
第一分类:人口属性、资产特征、营销特性、兴趣爱好、购物爱好、需求特征
第二分类…
第三分类……….
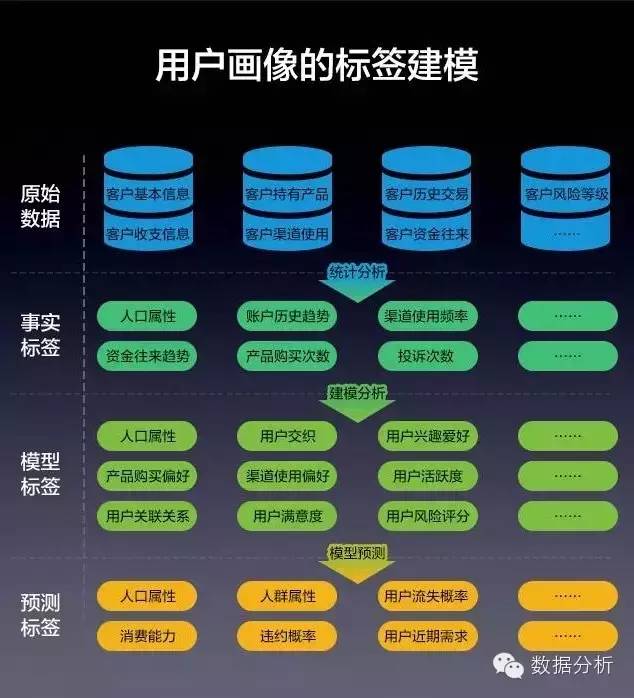
完成了对客户微观画像分析后,就可以考虑为用户画像的标签建模了。
从原始数据进行统计分析,得到事实标签,再进行建模分析,得到模型标签,再进行模型预测,得到预测标签。
最后从宏观层面总结,就是得到用户画像的数据架构。
LotuseeData莲子数据在具体设备分析的统计基础上,提供了更强大的自定义时间,用户分组,渠道活动转化追踪等新功能,并累计了大量的设备和用户标签,为进一步的用户画像提供了坚实的基础。
百分点技术总监郭志金谈用户画像数据建模方法
伴随着大数据应用的讨论、创新,个性化技术成为了一个重要落地点。相比传统的线下会员管理、问卷调查、购物篮分析,大数据第一次使得企业能够通过互联网便利地获取用户更为广泛的反馈信息,为进一步精准、快速地分析用户行为习惯、消费习惯等重要商业信息,提供了足够的数据基础。伴随着对人的了解逐步深入,一个概念悄然而生:用户画像(UserProfile),完美地抽象出一个用户的信息全貌,可以看作企业应用大数据的根基。
一、什么是用户画像?
男,31岁,已婚,收入1万以上,爱美食,团购达人,喜欢红酒配香烟。
这样一串描述即为用户画像的典型案例。如果用一句话来描述,即:用户信息标签化。
如果用一幅图来展现,即:
二、为什么需要用户画像
用户画像的核心工作是为用户打标签,打标签的重要目的之一是为了让人能够理解并且方便计算机处理,如,可以做分类统计:喜欢红酒的用户有多少?喜欢红酒的人群中,男、女比例是多少?
也可以做数据挖掘工作:利用关联规则计算,喜欢红酒的人通常喜欢什么运动品牌?利用聚类算法分析,喜欢红酒的人年龄段分布情况?
大数据处理,离不开计算机的运算,标签提供了一种便捷的方式,使得计算机能够程序化处理与人相关的信息,甚至通过算法、模型能够“理解” 人。当计算机具备这样的能力后,无论是搜索引擎、推荐引擎、广告投放等各种应用领域,都将能进一步提升精准度,提高信息获取的效率。
三、如何构建用户画像
一个标签通常是人为规定的高度精炼的特征标识,如年龄段标签:25~35岁,地域标签:北京,标签呈现出两个重要特征:语义化,人能很方便地理解每个标签含义。这也使得用户画像模型具备实际意义。能够较好的满足业务需求。如,判断用户偏好。短文本,每个标签通常只表示一种含义,标签本身无需再做过多文本分析等预处理工作,这为利用机器提取标准化信息提供了便利。
人制定标签规则,并能够通过标签快速读出其中的信息,机器方便做标签提取、聚合分析。所以,用户画像,即:用户标签,向我们展示了一种朴素、简洁的方法用于描述用户信息。
3.1 数据源分析
构建用户画像是为了还原用户信息,因此数据来源于:所有用户相关的数据。
对于用户相关数据的分类,引入一种重要的分类思想:封闭性的分类方式。如,世界上分为两种人,一种是学英语的人,一种是不学英语的人;客户分三类,高价值客户,中价值客户,低价值客户;产品生命周期分为,投入期、成长期、成熟期、衰退期…所有的子分类将构成了类目空间的全部集合。
这样的分类方式,有助于后续不断枚举并迭代补充遗漏的信息维度。不必担心架构上对每一层分类没有考虑完整,造成维度遗漏留下扩展性隐患。另外,不同的分类方式根据应用场景,业务需求的不同,也许各有道理,按需划分即可。
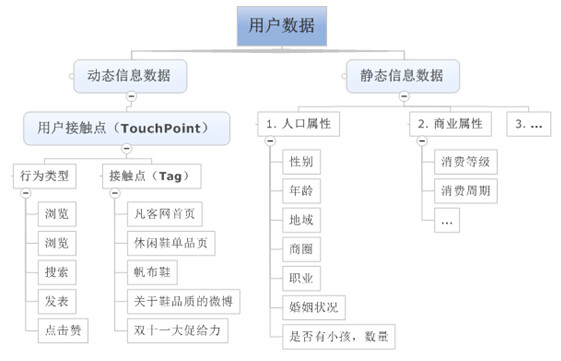
本文将用户数据划分为静态信息数据、动态信息数据两大类。
静态信息数据
用户相对稳定的信息,如图所示,主要包括人口属性、商业属性等方面数据。这类信息,自成标签,如果企业有真实信息则无需过多建模预测,更多的是数据清洗工作,因此这方面信息的数据建模不是本篇文章重点。
动态信息数据
用户不断变化的行为信息,如果存在上帝,每一个人的行为都在时刻被上帝那双无形的眼睛监控着,广义上讲,一个用户打开网页,买了一个杯子;与该用户傍晚溜了趟狗,白天取了一次钱,打了一个哈欠等等一样都是上帝眼中的用户行为。当行为集中到互联网,乃至电商,用户行为就会聚焦很多,如上图所示:浏览凡客首页、浏览休闲鞋单品页、搜索帆布鞋、发表关于鞋品质的微博、赞“双十一大促给力”的微博消息。等等均可看作互联网用户行为。
本篇文章以互联网电商用户,为主要分析对象,暂不考虑线下用户行为数据(分析方法雷同,只是数据获取途径,用户识别方式有些差异)。
在互联网上,用户行为,可以看作用户动态信息的唯一数据来源。如何对用户行为数据构建数据模型,分析出用户标签,将是本文着重介绍的内容。
3.2 目标分析
用户画像的目标是通过分析用户行为,最终为每个用户打上标签,以及该标签的权重。如,红酒 0.8、李宁 0.6。
标签,表征了内容,用户对该内容有兴趣、偏好、需求等等。
权重,表征了指数,用户的兴趣、偏好指数,也可能表征用户的需求度,可以简单的理解为可信度,概率。
3.3 数据建模方法
下面内容将详细介绍,如何根据用户行为,构建模型产出标签、权重。一个事件模型包括:时间、地点、人物三个要素。每一次用户行为本质上是一次随机事件,可以详细描述为:什么用户,在什么时间,什么地点,做了什么事。
什么用户:关键在于对用户的标识,用户标识的目的是为了区分用户、单点定位。
以上列举了互联网主要的用户标识方法,获取方式由易到难。视企业的用户粘性,可以获取的标识信息有所差异。
什么时间:时间包括两个重要信息,时间戳+时间长度。时间戳,为了标识用户行为的时间点,如,1395121950(精度到秒),1395121950.083612(精度到微秒),通常采用精度到秒的时间戳即可。因为微秒的时间戳精度并不可靠。浏览器时间精度,准确度最多也只能到毫秒。时间长度,为了标识用户在某一页面的停留时间。
什么地点:用户接触点,Touch Point。对于每个用户接触点。潜在包含了两层信息:网址 + 内容。网址:每一个url链接(页面/屏幕),即定位了一个互联网页面地址,或者某个产品的特定页面。可以是PC上某电商网站的页面url,也可以是手机上的微博,微信等应用某个功能页面,某款产品应用的特定画面。如,长城红酒单品页,微信订阅号页面,某游戏的过关页。
内容:每个url网址(页面/屏幕)中的内容。可以是单品的相关信息:类别、品牌、描述、属性、网站信息等等。如,红酒,长城,干红,对于每个互联网接触点,其中网址决定了权重;内容决定了标签。
注:接触点可以是网址,也可以是某个产品的特定功能界面。如,同样一瓶矿泉水,超市卖1元,火车上卖3元,景区卖5元。商品的售卖价值,不在于成本,更在于售卖地点。标签均是矿泉水,但接触点的不同体现出了权重差异。这里的权重可以理解为用户对于矿泉水的需求程度不同。即,愿意支付的价值不同。
标签 权重
矿泉水 1 // 超市
矿泉水 3 // 火车
矿泉水 5 // 景区
类似的,用户在京东商城浏览红酒信息,与在品尚红酒网浏览红酒信息,表现出对红酒喜好度也是有差异的。这里的关注点是不同的网址,存在权重差异,权重模型的构建,需要根据各自的业务需求构建。
所以,网址本身表征了用户的标签偏好权重。网址对应的内容体现了标签信息。
什么事:用户行为类型,对于电商有如下典型行为:浏览、添加购物车、搜索、评论、购买、点击赞、收藏 等等。
不同的行为类型,对于接触点的内容产生的标签信息,具有不同的权重。如,购买权重计为5,浏览计为1
红酒 1 // 浏览红酒
红酒 5 // 购买红酒
综合上述分析,用户画像的数据模型,可以概括为下面的公式:用户标识 + 时间 + 行为类型 + 接触点(网址+内容),某用户因为在什么时间、地点、做了什么事。所以会打上**标签。
用户标签的权重可能随时间的增加而衰减,因此定义时间为衰减因子r,行为类型、网址决定了权重,内容决定了标签,进一步转换为公式:
标签权重=衰减因子×行为权重×网址子权重
如:用户A,昨天在品尚红酒网浏览一瓶价值238元的长城干红葡萄酒信息。
标签:红酒,长城
时间:因为是昨天的行为,假设衰减因子为:r=0.95
行为类型:浏览行为记为权重1
地点:品尚红酒单品页的网址子权重记为 0.9(相比京东红酒单品页的0.7)
假设用户对红酒出于真的喜欢,才会去专业的红酒网选购,而不再综合商城选购。
则用户偏好标签是:红酒,权重是0.95*0.7 * 1=0.665,即,用户A:红酒 0.665、长城 0.665。
上述模型权重值的选取只是举例参考,具体的权重值需要根据业务需求二次建模,这里强调的是如何从整体思考,去构建用户画像模型,进而能够逐步细化模型。
四、总结:
本文并未涉及具体算法,更多的是阐述了一种分析思想,在计划构建用户画像时,能够给您提供一个系统性、框架性的思维指导。
核心在于对用户接触点的理解,接触点内容直接决定了标签信息。内容地址、行为类型、时间衰减,决定了权重模型是关键,权重值本身的二次建模则是水到渠成的进阶。模型举例偏重电商,但其实,可以根据产品的不同,重新定义接触点。
比如影视产品,我看了一部电影《英雄本色》,可能产生的标签是:周润发 0.6、枪战 0.5、港台 0.3。
最后,接触点本身并不一定有内容,也可以泛化理解为某种阈值,某个行为超过多少次,达到多长时间等。
比如游戏产品,典型接触点可能会是,关键任务,关键指数(分数)等等。如,积分超过1万分,则标记为钻石级用户。钻石用户 1.0。
百分点现已全面应用用户画像技术于推荐引擎中,在对某电商客户,针对活动页新访客的应用中,依靠用户画像产生的个性化效果,对比热销榜,推荐效果有显著提升:推荐栏点击率提升27%, 订单转化率提升34%。
转自灯塔大数据,来源:大数据人
新浪微博的用户画像是怎样构建的?
1.概述
从上一篇《认识每一个“你”:微博中的用户模型》里面对用户模型维度的划分可以看出,属性和兴趣维度的用户模型都可以归入用户画像(User Profile)的范畴。而所谓用户画像,简单来说就是对用户的信息进行标签化。如图1所示。一方面,标签化是对用户信息进行结构化,方便计算机的识别和处理;另一方面,标签本身也具有准确性和非二义性,也有利于人工的整理、分析和统计。
用户属性指相对静态和稳定的人口属性,例如:性别、年龄区间、地域、受教育程度、学校、公司……这些信息的收集和建立主要依靠产品本身的引导、调查、第三方提供等。微博本身就有比较完整的用户注册引导、用户信息完善任务、认证用户审核、以及大量的合作对象等,在收集和清洗用户属性的过程中,需要注意的主要是标签的规范化以及不同来源信息的交叉验证。
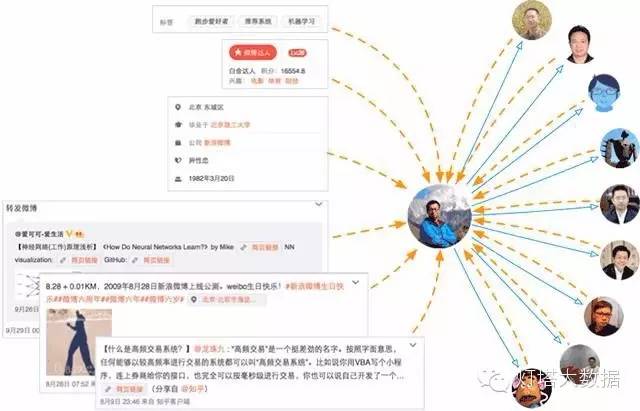
用户兴趣则是更加动态和易变化的特征,首先兴趣受到人群、环境、热点事件、行业……等方面的影响,一旦这些因素发生变化,用户的兴趣容易产生迁移;其次,用户的行为(特指在互联网上的行为)多样且碎片化,不同行为反映出来的兴趣差异较大。接下来主要介绍一下微博画像中兴趣维度的构建方法。2.微博用户兴趣分析1 标签来源用户自标签、达人或认证标签、公司、学校、微群标签、星座、微博关键词……这些来源都可能成为用户的标签。而针对每个特定的用户收集标签除了其自身以外,他关注用户的标签也会传递到该用户身上。如图2所示(蓝色实线代表关注关系,橙色虚线代表兴趣标签来源)。
2 权重计算
在收集到一个用户可能存在的标签后,还需要给标签赋一定的权重,用来区分不同标签对于该用户的重要程度。不同标签的来源用户质量,标签的传递路径,转发关系,标签的本身,以及标签与用户之间的共现关系都会考虑在内。
不同质量的用户自身产生的标签权重不一样,质量越高,认为该标签的可信度越高,无论是将该标签赋给自己还是传递出去的时候其权重值越高。
标签的传递路径主要是针对基于关注关系的标签传递,亲密度比较高的关注用户传递过来的标签权重值会比较高。
标签是来自于用户的原创还是其转发的微博,权重值会有区别,一般来说原创的权重会高于转发权重。
如果标签本身是一个非常常见的词,那么它用于刻画用户的兴趣的区分性是比较差的,相反如果是一个长尾词,则区分性较强。出于这样的考虑,越是长尾词,标签的权重值会越高。
标签与用户的共现关系是指用户和该标签是否经常共同出现,评价的是两者的关联性。关联性越高,则标签的权重值越高。
综合上述的因素,一个标签对于特定用户的权重值可以大致表示为:标签权重 = (来源因子 + 亲密度因子 + 转发因子 + 长尾因子) × 共现因子。
3 时效性随着时间的变化,用户的兴趣会发生转移,时间越久远,标签的权重应该相应的下降,距离当前时间越近的兴趣标签应该得到适当突出。出于这样的考虑,一般会在标签权重值上叠加一个时间衰减函数,这个时间衰减函数被设计成如图3所示的指数衰减的形式,通过定义衰减幅度和半衰期,调节衰减的程度,体现不同的时效性。
此外,针对用户的兴趣,还会设定一个较小的时间窗口来获取用户的短期兴趣。通过用户在短时间内的原创、转发和关注行为收集兴趣标签,并计算标签的权重。短期兴趣更新周期会较长期兴趣更短,兴趣更集中,但是能够比较及时地反应用户兴趣的变化。4 从兴趣到能力然而,用户具有某方面的兴趣,只代表了他愿意接受这方面的信息,并不能代表他具有产生相关内容的能力。因此,在挖掘了用户兴趣标签的基础上,还需要发掘哪些用户能够针对特定的标签具有一定的内容生产能力。
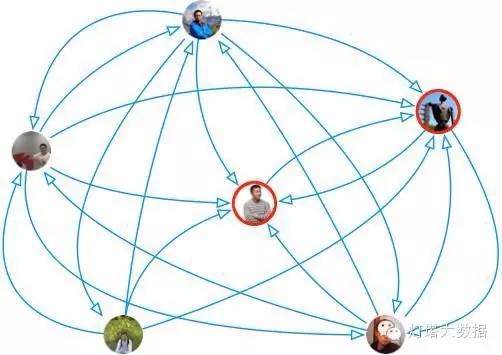
微博中的关注关系可以认为是一种认证,具有相同兴趣的用户之间的关注则有可能是兴趣相投(当然也可能不是,但毕竟有一定的指导性),那么将具有相同兴趣标签的用户提出来,通过关注关系构成一个图,被认证得最多的用户(被关注边指向得最多)被认为在这个兴趣标签上具有最强能力。如图4所示中的带红色边框的用户。
欢网大数据开启“全网+跨屏”用户画像新时代
来源:新华网
长期以来,智能电视行业一直局限于电视端数据进行用户画像分析,希望以此进行精准营销,难道仅基于电视端收视数据进行用户画像就可以实现精准营销吗?此方式虽然取得一些成果,但是距大数据时代众多收视用户的精准营销还是距离遥远。近日,欢网大数据以卓越创新的“全网+跨屏”理念,掀起了电视行业融合全网大数据的精准营销革命,该理念通过关联智能电视与PC、移动端数据,不仅能够跨屏识别用户,而且可以获悉用户在不同终端的使用行为。此举打破传统电视行业信息孤岛,实现跨屏全网数据融合,颠覆电视端营销方式,打造通过分析用户线上线下行为数据获知真实潜在需求的精准营销平台,并以此提升基于智能电视平台所实现的“增强电视”、“T2O”等一系列精准营销的服务价值。
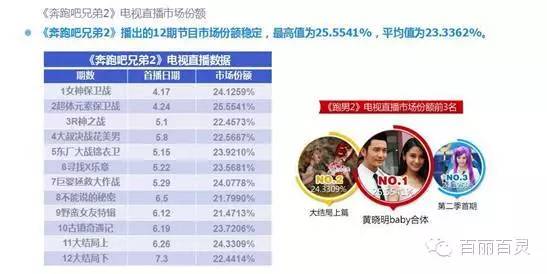
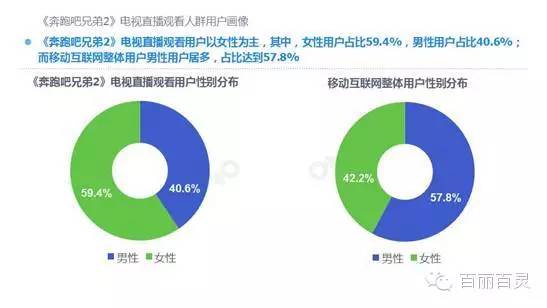
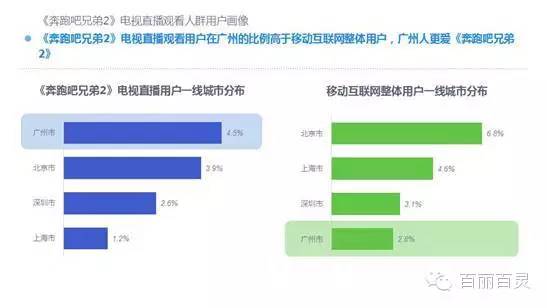
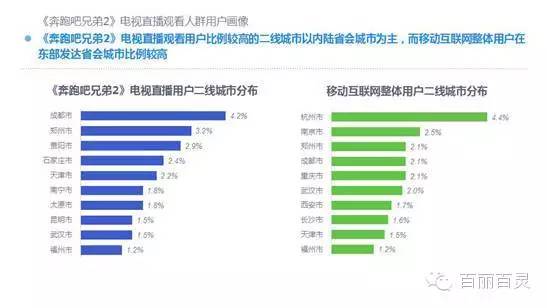
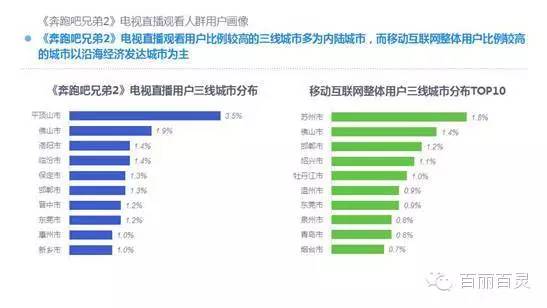
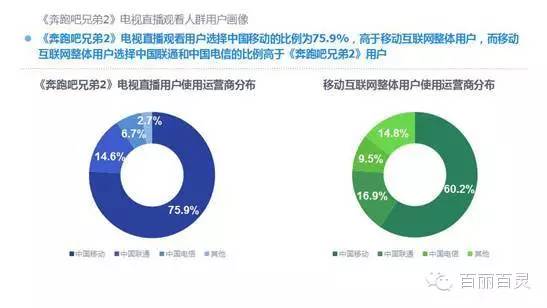
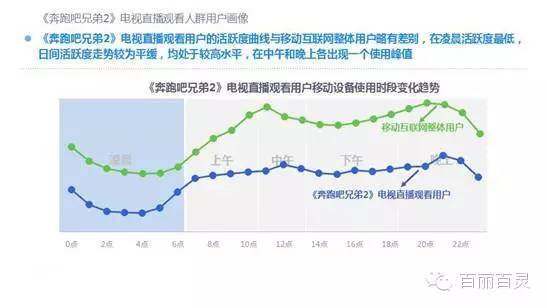
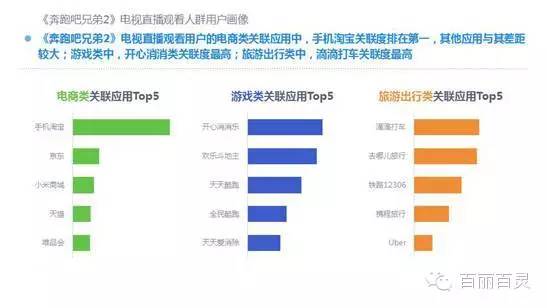
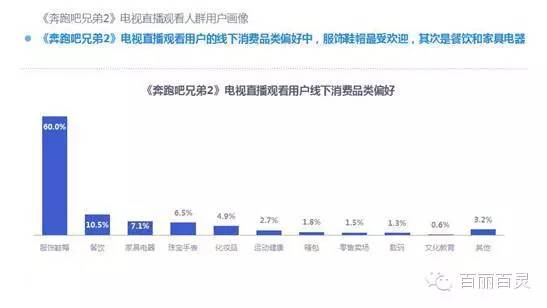
欢网作为国内最大的互联网智能电视服务商,自创立以来一直致力于成为电视内容的聚合者和分发者,而用户画像是提供个性化电视营销服务的基础。“全网+跨屏”融合更加全面的用户数据,这包括用户在电视端的收视数据、与其它智能终端的行为习惯数据。以热门综艺《奔跑吧兄弟2》为例,观看该节目的电视用户,平时主要活动区域、偏好何种APP软件、忠爱哪些品牌、喜欢吃什么玩什么等,通过全网数据的融合,了解其行为习惯,建立用户画像,将有助于精准营销、个性化内容推送,再度提升文化娱乐对消费行为的影响。
何谓智能电视用户画像?是收集、融合并分析智能电视用户海量收视数据以及全网使用行为后,判断其家庭收视偏好、消费行为与能力、家庭成员组成、潜在购物倾向等,最终梳理出不同属性的用户人群,为业务运营提供更充足的信息基础。
以下为欢网科技与TalkingData联合发布的热门综艺案列分析:
建立全网用户画像,是颠覆传统意义上仅以电视端数据进行用户画像的革命性的营销方式。多端数据的结合,可将更精准的服务推送给有潜在需求的用户,从而帮助需求方锁定用户群。此举有助于电视台、节目组、制作方、广告商更精确的了解受众用户,为之后编播节目、投放广告等带来极大价值。
欢网大数据打破了固有的“电视归电视,互联网归互联网”的局面。以“全网+跨屏”探索智能电视与互联网行业的未来,在颠覆传统理念的同时,让智能电视用户享受更优质的服务。
大数据用户画像在金融行业实践一. 用户画像背后的原因
金融消费行为的改变,
企业无法接触到客户
80后、90后总计共有3.4亿人口,并日益成为金融企业主要的消费者,但是他们的金融消费习惯正在改变,他们不愿意到金融网点办理业务,不喜欢被动接受金融产品和服务。年轻人将主要的时间都消费在移动互联网,消费在智能手机上。平均每个人,每天使用智能手机的时间超过了3小时,年轻人可能会超过4个小时。浏览手机已经成为工作和睡觉之后的,人类第三大生活习惯,移动APP也成为所有金融企业的客户入口、服务入口、消费入口、数据入口。
金融企业越来越难面对面接触到年轻人,无法像过去一样,从对话中了解年轻人的想法,了解年轻人金融产品的需求。
消费者需求出现分化,需要寻找目标客户 客户消费习惯的改变,企业无法接触到客户,无法了解客户需求;
客户需求的分化,企业需要细分客户,为目标客户开发设计产品。
金融企业需要借助于户画像,来了解客户,找到目标客户,触达客户。
二. 用户画像的目的
用户画像是在解客户需求和消费能力,以及客户信用额度的基础上,寻找潜在产品的目标客户,并利用画像信息为客户开发产品。
提到用户画像,很多厂商都会提到360度用户画像,其实经常360度客户画像是一个广告宣传用语,根本不存数据可以全面描述客户,透彻了解客户。人是非常复杂的动物,信息纬度非常复杂,仅仅依靠外部信息来刻画客户内心需要根本不可能。
用户画像一词具有很重的场景因素,不同企业对于用户画像有着不同对理解和需求。举个例子,金融行业和汽车行业对于用户画像需求的信息完全不一样,信息纬度也不同,对画像结果要求也不同。每个行业都有一套适合自己行业的用户画像方法,但是其核心都是为客户服务,为业务场景服务。
用户画像本质就是从业务角度出发对用户进行分析,了解用户需求,寻找目标客户。另外一个方面就是,金融企业利用统计的信息,开发出适合目标客户的产品。
从商业角度出发的用户画像对企业具有很大的价值,用户画像目的有两个。
一个是业务场景出发,寻找目标客户。另外一个就是,参考用户画像的信息,为用户设计产品或开展营销活动。
三. 用户画像工作坚持的原则
市场上用户画像的方法很多,许多企业也提供用户画像服务,将用户画像提升到很有逼格一件事。金融企业是最早开始用户画像的行业,由于拥有丰富的数据,金融企业在进行用户画像时,对众多纬度的数据无从下手,总是认为用户画像数据纬度越多越好,画像数据越丰富越好,某些输入的数据还设定了权重甚至建立了模型,搞的用户画像是一个巨大而复杂的工程。但是费力很大力气进行了画像之后,却发现只剩下了用户画像,和业务相聚甚远,没有办法直接支持业务运营,投入精力巨大但是回报微小,可以说是得不偿失,无法向领导交代。
事实上,用户画像涉及数据的纬度需要业务场景结合,既要简单干练又要和业务强相关,既要筛选便捷又要方便进一步操作。用户画像需要坚持三个原则,分别是人口属性和信用信息为主,强相关信息为主,定性数据为主。下面就分别展开进行解释和分析。
3.1 信用信息和人口属性为主 描述一个用户的信息很多,信用信息是用户画像中重要的信息,信用信息是描述一个人在社会中的消费能力信息。任何企业进行用户画像的目的是寻找目标客户,其必须是具有潜在消费能力的用户。信用信息可以直接证明客户的消费能力,是用户画像中最重要和基础的信息。一句戏言,所有的信息都是信用信息就是这个道理。其包含消费者工作、收入、学历、财产等信息。
定位完目标客户之后,金融企业需要触达客户,人口属性信息就是起到触达客户的作用,人口属性信息包含姓名、性别,电话号码,邮件地址,家庭住址等信息。这些信息可以帮助金融企业联系客户,将产品和服务推销给客户。
3.2 采用强相关信息,忽略弱相关信息 我们需要介绍一下强相关信息和弱相关信息。强相关信息就是同场景需求直接相关的信息,其可以是因果信息,也可以是相关程度很高的信息。
如果定义采用0到1作为相关系数取值范围的化,0.6以上的相关系数就应该定义为强相关信息。例如在其他条件相同的前提下,35岁左右人的平均工资高于平均年龄为30岁的人,计算机专业毕业的学生平均工资高于哲学专业学生,从事金融行业工作的平均工资高于从事纺织行业的平均工资,上海的平均工资超过海南省平均工资。从这些信息可以看出来人的年龄、学历、职业、地点对收入的影响较大,同收入高低是强相关关系。简单的将,对信用信息影响较大的信息就是强相关信息,反之则是弱相关信息。
用户其他的信息,例如用户的身高、体重、姓名、星座等信息,很难从概率上分析出其对消费能力的影响,这些弱相关信息,这些信息就不应该放到用户画像中进行分析,对用户的信用消费能力影响很小,不具有较大的商业价值。
用户画像和用户分析时,需要考虑强相关信息,不要考虑弱相关信息,这是用户画像的一个原则。
3.3 将定量的信息归类为定性的信息 用户画像的目的是为产品筛选出目标客户,定量的信息不利于对客户进行筛选,需要将定量信息转化为定性信息,通过信息类别来筛选人群。
例如可以将年龄段对客户进行划分,18岁-25岁定义为年轻人,25岁-35岁定义为中青年,36-45定义为中年人等。可以参考个人收入信息,将人群定义为高收入人群,中等收入人群,低收入人群。参考资产信息也可以将客户定义为高、中、低级别。定性信息的类别和方式方法,金融可以从自身业务出发,没有固定的模式。
将金融企业各类定量信息,集中在一起,对定性信息进行分类,并进行定性化,有利与对用户进行筛选,快速定位目标客户,是用户画像的另外一个原则。
用户画像的方法介绍,不要太复杂
金融企业需要结合业务需求进行用户画像,从实用角度出发,我们可以将用户画像信息分成五类信息。分别是人口属性,信用属性,消费特征,兴趣爱好,社交属性。它们基本覆盖了业务需求所需要的强相关信息,结合外部场景数据将会产生巨大的商业价值。我们先了解下用户画像的五大类信息的作用,以及涉及的强相关信息。特别复杂的用户画像纬度例如八个纬度,十个纬度信息都不利于商业应用,不建议金融企业进行采用,其他具有价值的信息,基本上都可以归纳到这五个纬度。金融企业达到其商业需求,从这五个纬度信息进行应用就可以了,不需要过于复杂用户画像这个工作,同时商业意义也不太大。
4.1 人口属性 用于描述一个人基本特征的信息,主要作用是帮助金融企业知道客户是谁,如何触达用户。姓名,性别,年龄,电话号码,邮箱,家庭住址都属于人口属性信息。
4.2 信用属性 用于描述用户收入潜力和收入情况,支付能力。帮助企业了解客户资产情况和信用情况,有利于定位目标客户。客户职业、收入、资产、负债、学历、信用评分等都属于信用信息。
4.3 消费特征 用于描述客户主要消费习惯和消费偏好,用于寻找高频和高价值客户。帮助企业依据客户消费特点推荐相关金融产品和服务,转化率将非常高。为了便于筛选客户,可以参考客户的消费记录将客户直接定性为某些消费特征人群,例如差旅人群,境外游人群,旅游人群,餐饮用户,汽车用户,母婴用户,理财人群等。
4.4 兴趣爱好 用于描述客户具有哪方面的兴趣爱好,在这些兴趣方面可能消费偏好比较高。帮助企业了解客户兴趣和消费倾向,定向进行活动营销。兴趣爱好的信息可能会和消费特征中部分信息有重复,区别在于数据来源不同。消费特征来源于已有的消费记录,但是购买的物品和服务不一定是自己享用,但是兴趣爱好代表本人的真实兴趣。例如户外运动爱好者,旅游爱好者,电影爱好者,科技发烧友,健身爱好者,奢侈品爱好者等。兴趣爱好的信息可能来源于社交信息和客户位置信息。
4.5 社交信息 用于描述用户在社交媒体的评论,这些信息往往代表用户内心的想法和需求,具有实时性高,转化率高的特点。例如客户询问上海哪里好玩?澳大利亚墨尔本的交通?房屋贷款哪家优惠多?那个理财产品好?这些社交信息都是代表客户多需求,如果企业可以及时了解到,将会有助于产品推广。这些用户画像信息归类基本覆盖了业务需求和产品开发所需要的信息,需要对这些信息进行进行整理和处理。根据业务场景,将定量的数据转化为定性的数据,并将强相关数据进行整理。(36大数据)5金融企业用户画像的基本步骤
参考金融企业的数据类型和业务需求,可以将金融企业用户画像工作进行细化。基本上从数据集中到数据处理,从强相关数据到定性分类数据,从引入外部数据到依据业务场景进行筛选目标用户。
5.1 画像相关数据的整理和集中金融企业内部的信息分布在不同的系统中,一般情况下,人口属性信息主要集中在客户关系管理系统,信用信息主要集中在交易系统和产品系统之中,也集中在客户关系管理系统中,消费特征主要集中在渠道和产品系统中。
兴趣爱好和社交信息需要从外部引入,例如客户的行为轨迹可以代表其兴趣爱好和品牌爱好,移动设备到位置信息可以提供较为准确的兴趣爱好信息。社交信息,可以借助于金融行业自身的文本挖掘能力进行采集和分析,也是可以借助于厂商的技术能力在社交网站上直接获得。社交信息往往是实时信息,商业价值较高,转化率也较高,是大数据预测方面的主要信息来源。例如用户在社交网站上提出罗马哪里好玩的问题,就代表用户未来可能有出国旅游的需求;如果客户在对比两款汽车的优良,客户购买汽车的可能性就较大。金融企业可以及时介入,为客户提供金融服务。
客户画像数据主要分为五类,人口属性、信用信息、消费特征、兴趣爱好、社交信息。这些数据都分布在不同的信息系统,金融企业都上线了数据仓库(DW),所有画像相关的强相关信息都可以从数据仓库里面整理和集中,并且依据画像商业需求,利用跑批作业,加工数据,生成用户画像的原始数据。
数据仓库成为用户画像数据的主要处理工具,依据业务场景和画像需求将原始数据进行分类、筛选、归纳、加工等,生成用户画像需要的原始数据。
用户画像的纬度信息不是越多越好,只需要找到这五大类画像信息强相关信息,同业务场景强相关信息,同产品和目标客户强相关信息即可。根本不存在360度的用户画像信息,也不存在丰富的信息可以完全了解客户,另外数据的实效性也要重点考虑。5.2 找到同业务场景强相关数据依据用户画像的原则,所有画像信息应该是五大分类的强相关信息。强相关信息是指同业务场景强相关信息,可以帮助金融行业定位目标客户,了解客户潜在需求,开发需求产品。
只有强相关信息才能帮助金融企业有效结合业务需求,创造商业价值。例如姓名、手机号、家庭地址就是能够触达客户的强人口属性信息,收入、学历、职业、资产就是客户信用信息的强相关信息。差旅人群、境外游人群、汽车用户、旅游人群、母婴人群就是消费特征的强相关信息。摄影爱好者、游戏爱好者、健身爱好者、电影人群、户外爱好者就是客户兴趣爱好的强相关信息。社交媒体上发表的旅游需求,旅游攻略,理财咨询,汽车需求,房产需求等信息代表了用户的内心需求,是社交信息场景应用的强相关信息。
金融企业内部信息较多,在用户画像阶段不需要对所有信息都采用,只需要采用同业务场景和目标客户强相关的信息即可,这样有助于提高产品转化率,降低投资回报率(ROI),有利于简单找到业务应用场景,在数据变现过程中也容易实现。
千万不要将用户画像工作搞的过于复杂,同业务场景关系不大,这样就让很多金融企业特别是领导失去用户画像的兴趣,看不到用户画像的商业,不愿意在大数据领域投资。为企业带来商业价值才是用户画像工作的主要动力和主要目的。5.3 对数据进行分类和标签化(定量to定性)金融企业集中了所有信息之后,依据业务需求,对信息进行加工整理,需要对定量的信息进行定性,方便信息分类和筛选。这部分工作建议在数据仓库进行,不建议在大数据管理平台(DMP)里进行加工。
定性信息进行定量分类是用户画像的一个重要工作环节,具有较高的业务场景要求,考验用户画像商业需求的转化。其主要目的是帮助企业将复杂数据简单化,将交易数据定性进行归类,并且融入商业分析的要求,对数据进行商业加工。例如可以将客户按照年龄区间分为学生,青年,中青年,中年,中老年,老年等人生阶段。源于各人生阶段的金融服务需求不同,在寻找目标客户时,可以通过人生阶段进行目标客户定位。企业可以利用客户的收入、学历、资产等情况将客户分为低、中、高端客户,并依据其金融服务需求,提供不同的金融服务。可以参考其金融消费记录和资产信息,以及交易产品,购买的产品,将客户消费特征进行定性描述,区分出电商客户,理财客户,保险客户,稳健投资客户,激进投资客户,餐饮客户,旅游客户,高端客户,公务员客户等。利用外部的数据可以将定性客户的兴趣爱好,例如户外爱好者,奢侈品爱好者,科技产品发烧友,摄影爱好者,高端汽车需求者等信息。
将定量信息归纳为定性信息,并依据业务需求进行标签化,有助于金融企业找到目标客户,并且了解客户的潜在需求,为金融行业的产品找到目标客户,进行精准营销,降低营销成本,提高产品转化率。另外金融企业还可以依据客户的消费特征、兴趣爱好、社交信息及时为客户推荐产品,设计产品,优化产品流程。提高产品销售的活跃率,帮助金融企业更好地为客户设计产品。5.4 依据业务需求引入外部数据利用数据进行画像目的主要是为业务场景提供数据支持,包括寻找到产品的目标客户和触达客户。金融企业自身的数据不足以了解客户的消费特征、兴趣爱好、社交信息。
金融企业可以引入外部信息来丰富客户画像信息,例如引入银联和电商的信息来丰富消费特征信息,引入移动大数据的位置信息来丰富客户的兴趣爱好信息,引入外部厂商的数据来丰富社交信息等。
外部信息的纬度较多,内容也很丰富,但是如何引入外部信息是一项具有挑战的工作。外部信息在引入时需要考虑几个问题,分别是外部数据的覆盖率,如何和内部数据打通,和内部信息的匹配率,以及信息的相关程度,还有数据的鲜活度,这些都是引入外部信息的主要考虑纬度。外部数据鱼龙混杂,数据的合规性也是金融企业在引入外部数据时的一个重要考虑,敏感的信息例如手机号、家庭住址、身份证号在引入或匹配时都应该注意隐私问题,基本的原则是不进行数据交换,可以进行数据匹配和验证。
外部数据不会集中在某一家,需要金融企业花费大量时间进行寻找。外部数据和内部数据的打通是个很复杂的问题,手机号/设备号/身份证号的MD5数值匹配是一种好的方法,不涉及隐私数据的交换,可以进行唯一匹配。依据行业内部的经验,没有一家企业外部数据可以满足企业要求,外部数据的引入需要多方面数据。一般情况下,数据覆盖率达到70%以上,就是一个非常高的覆盖率。覆盖率达到20%以上就可以进行商业应用了。
金融行业外部数据源较好合作方有银联、芝麻信用、运营商、中航信、腾云天下、腾讯、微博、前海征信,各大电商平台等。市场上数据提供商已经很多,并且数据质量都不错,需要金融行业一家一家去挖掘,或者委托一个厂商代理引入也可以。独立第三方帮助金融行业引入外部数据可以降低数据交易成本,同时也可以降低数据合规风险,是一个不错的尝试。另外各大城市和区域的大数据交易平台,也是一个较好的外部数据引入方式。5.5 按照业务需求进行筛选客户(DMP的作用)用户画像主要目的是让金融企业挖掘已有的数据价值,利用数据画像技术寻找到目标客户和客户的潜在需求,进行产品推销和设计改良产品。
用户画像从业务场景出发,实现数据商业变现重要方式。用户画像是数据思维运营过程中的一个重要闭环,帮助金融企业利用数据进行精细化运营和市场营销,以及产品设计。用户画像就是一切以数据商业化运营为中心,以商业场景为主,帮助金融企业深度分析客户,找到目标客户。
DMP(大数据管理平台)在整个用户画像过程中起到了一个数据变现的作用。从技术角度来讲,DMP将画像数据进行标签化,利用机器学习算法来找到相似人群,同业务场景深度结合,筛选出具有价值的数据和客户,定位目标客户,触达客户,对营销效果进行记录和反馈。大数据管理平台DMP过去主要应用在广告行业,在金融行业应用不多,未来会成为数据商业应用的主要平台。
DMP可以帮助信用卡公司筛选出未来一个月可能进行分期付款的客户,电子产品重度购买客户,筛选出金融理财客户,筛选出高端客户(在本行资产很少,但是在他行资产很多),筛选出保障险种,寿险,教育险,车险等客户,筛选出稳健投资人,激进投资人,财富管理等方面等客户,并且可以触达这些客户,提高产品转化率,利用数据进行价值变现。DMP还可以了解客户的消费习惯、兴趣爱好、以及近期需求,为客户定制金融产品和服务,进行跨界营销。利用客户的消费偏好,提高产品转化率,提高用户黏度。
DMP还作为引入外部数据的平台,将外部具有价值的数据引入到金融企业内部,补充用户画像数据,创建不同业务应用场景和商业需求,特别是移动大数据、电商数据、社交数据的应用,可以帮助金融企业来进行数据价值变现,让用户画像离商业应用更加近一些,体现用户画像的商业价值。
用户画像的关键不是360度分析客户,而是为企业带来商业价值,离开了商业价值谈用户画像就是耍流氓。金融企业用户画像项目出发点一定要从业务需求出发,从强相关数据出发,从业务场景应用出发。用户画像的本质就是深度分析客户,掌握具有价值数据,找到目标客户,按照客户需求来定制产品,利用数据实现价值变现。6金融行业用户画像实践6.1 银行用户画像实践介绍银行具有丰富的交易数据、个人属性数据、消费数据、信用数据和客户数据,用户画像的需求较大。但是缺少社交信息和兴趣爱好信息。
到银行网点来办业务的人年纪偏大,未来消费者主要在网上进行业务办理。银行接触不到客户,无法了解客户需求,缺少触达客户的手段。分析客户、了解客户、找到目标客户、为客户设计其需要的产品,成了银行进行用户画像的主要目的。银行的主要业务需求集中在消费金融、财富管理、融资服务,用户画像要从这几个角度出发,寻找目标客户。
银行的客户数据很丰富,数据类型和总量较多,系统也很多。可以严格遵循用户画像的五大步骤。先利用数据仓库进行数据集中,筛选出强相关信息,对定量信息定性化,生成DMP需要的数据。利用DMP进行基础标签和应用定制,结合业务场景需求,进行目标客户筛选或对用户进行深度分析。同时利用DMP引入外部数据,完善数据场景设计,提高目标客户精准度。找到触达客户的方式,对客户进行营销,并对营销效果进行反馈,衡量数据产品的商业价值。利用反馈数据来修正营销活动和提高ROI。形成市场营销的闭环,实现数据商业价值变现的闭环。另外DMP还可以深度分析客户,依据客户的消费特征、兴趣爱好、社交需求、信用信息来开发设计产品,为金融企业的产品开发提供数据支撑,并为产品销售方式提供场景数据。
简单介绍一些DMP可以做到的数据场景变现。A 寻找分期客户利用发卡机构数据+自身数据+信用卡数据,发现信用卡消费超过其月收入的用户,推荐其进行消费分期。B 寻找高端资产客户利用发卡机构数据+移动位置数据(别墅/高档小区)+物业费代扣数据+银行自身数据+汽车型号数据,发现在银行资产较少,在其他行资产较多的用户,为其提供高端资产管理服务。C 寻找理财客户利用自身数据(交易+工资)+移动端理财客户端/电商活跃数据。发现客户将工资/资产转到外部,但是电商消费不活跃客户,其互联网理财可能性较大,可以为其提供理财服务,将资金留在本行。D 寻找境外游客户利用自身卡消费数据+移动设备位置信息+社交好境外强相关数据(攻略,航线,景点,费用),寻找境外游客户为其提供金融服务。E 寻找贷款客户利用自身数据(人口属性+信用信息)+移动设备位置信息+社交购房/消费强相关信息,寻找即将购车/购房的目标客户,为其提供金融服务(抵押贷款/消费贷款)。6.2 保险行业用户画像实践保险行业的产品是一个长周期产品,保险客户再次购买保险产品的转化率很高,经营好老客户是保险公司一项重要任务。保险公司内部的交易系统不多,交易方式不是很复杂,数据主要集中在产品系统和交易系统之中,客户关系管理系统中也包含丰富了信息,但是数据集中在很多保险公司还没有完成,数据仓库建设可能需要在用户画像建设前完成。
保险公司主要数据有人口属性信息,信用信息,产品销售信息,客户家人信息。缺少兴趣爱好、消费特征、社交信息等信息。保险产品主要有寿险,车险,保障,财产险,意外险,养老险,旅游险。
保险行业DMP用户画像的业务场景都是围绕保险产品进行的,简单的应用场景可以是。A依据自身数据(个人属性)+外部养车App活跃情况,为保险公司找到车险客户。B依据自身数据(个人属性)+移动设备位置信息,为保险企业找到商旅人群,推销意外险和保障险。C依据自身数据(家人数据)+人生阶段信息,为用户推荐理财保险,寿险,保障保险,养老险,教育险。D依据自身数据+外部数据,为高端人士提供财产险和寿险。6.3 证券行业用户画像2015年4月13日,一码通实施之后,证券行业面临了互联网证券平台的强力竞争,依据某机构发布的金融App排行榜,移动互联网证券App,排名前5位的证券类App,只有一家传统券商。排名第一的互联网券商是排名第一传统券商的6倍,前三名的互联券商总体覆盖用户接近6000万用户。用户总数还在不断增加。传统证券行业现在面临的主要挑战是用户交易账户的争夺,证券行业如何增加新用户?如何留住用户?如何提高证券行业用户的活跃?如何提高单个客户的收入?是证券行业主要的业务需求。
证券行业拥有的数据类型有个人属性信息例如用户名称,手机号码,家庭地址,邮件地址等。证券公司还拥有交易用户的资产和交易纪录,同时还拥有用户收益数据,利用这些数据和外部数据,证券公司可以利用数据建立业务场景,筛选目标客户,为用户提供适合的产品,同时提高单个客户收入。
证券公司可以利用用户画像数据来进行产品设计,下面举几个例子,看看用户画像和用户分析来帮助证券公司创造商业价值。7外部数据介绍金融企业内部数据主要集中在个人属性,信用属性和消费特征上,缺少社交属性和兴趣偏好等信息,这些信息可以通过第三方获得。
社交数据就是客户在社交媒体上发表的言论和行为,可以是评论,文章,图片,甚至可以是表情符号,音频和视频。社交数据可以依靠第三方平台,在社交网站上利用爬虫技术进行获得(Spider)。社交数据的打通是一个挑战,如果能够让客户的授权最好,金融企业就可以将社交数据纳入到用户画像之中。社交数据具有实时和反映内心需要的特点,某银行已经将社交数据作为分析客户需求的一个重要数据纬度。例如如果某一个客户在社交媒体上发表了一个问题,罗马有哪些好玩的地方,金融企业就会推测客户可能近期会有出境游的计划,就会向客户推销一些旅游相关产品。
社交媒体数据正在成为金融企业积极争取获得的数据,除了利用网络爬虫技术到微博上进行数据采集之外,金融企业自身网站上到文本数据采集和呼叫中心(call center)纪录的信息都可以进行文本挖掘。通过客户编号,进行打通,将其补充到客户画像之中。社交数据需要通过数据挖掘将其定义为结构化数据,并且同业务场景、客户需求向结合,清晰进行分类。例如将母婴论坛发言活跃的用户定义为潜在教育需求客户,将学生论坛活跃的客户定义为学区房需要客户,将境外自助游论坛上活跃的客户定义为境外旅游客户,将理财APP上活跃的客户定义为理财客户等。金融企业完全可以从社交数据中挖掘出客户近期的消费需求,及时进行市场营销和定制产品。
兴趣爱好数据可以借助于移动大数据位置信息获得,客户手机设备的位置轨迹信息可以揭示客户喜欢何种品牌,喜欢吃辣还是吃火锅,客户喜欢旅游还是喜欢宅在家里,客户喜欢看电影还是喜欢运动。客户喜欢中档品牌还是高档品牌,客户喜欢喝茶还是喝咖啡。移动手机上App的安装情况和活动频次一样可以揭示客户的兴趣和爱好。同时移动大数据进行加工之后还可以告诉金融企业,客户近期的需求是买车还是买房。
外部数据引入过程中,金融企业面临的巨大挑战是外部数据的覆盖率,如何打通内外部数据,外部数据同内部客户的匹配率,外部数据同业务的相关度,外部数据的活跃程度等。用户画像平台(DMP)可以通过技术手段将外部数据引入到金融企业内部,建立标准的标签体系,提供灵活的用户画像方式,按照业务场景进行筛选客户。
8移动大数据的商业价值移动互联网时代,移动大数据具有较高的商业价值。如果一个用户不喜欢一个App,其不会装在手机上。客户经常使用的App可以推测用户的兴趣爱好和消费偏好。另外移动设备的位置信息可以帮助金融企业了解客户行为轨迹、兴趣爱好、品牌偏好和消费需求。8.1 移动App提供一切服务,App可以反映用户喜好智能手机上安装的App正在代替PC互联网为所有客户提供服务,清晨起床可以看看天气,了解一下今天的天气情况。出门时可以通过打车App来预定出租车,安排出行。或者通过地图App来了解路况信息,决定进行从哪条路到公司。快到中午时,可以通过外卖App预定午餐,如果想出去吃饭可以利用团购App订餐和买单。中午可以利用旅游App预定家庭旅行机票和酒店,还可以将通过App看看理财产品。如果需要看电影,可以通过票务App来预定要电影票,如果需要看医生,可以通过医疗App预约医生。晚上可以透过App购物、监督子女教育等。可以看出移动App已经可以满足人们大部分生活需要,提供了人们的衣食住行、教育、医疗、旅游、金融等服务。移动App包围了人们的日常生活,成为人们消费的主要场所。
智能手机上App使用的频率,可以代表用户的喜好。例如喜欢理财的客户,其智能手机上一定会安装理财App,并经常使用;母婴人群也会安装和母婴相关的App,频繁使用;商旅人群使用商旅App的频率一定会高于其他移动用户。80后、90后的消费行为将会以移动互联网为主,App的安装和活跃数据更加能够反应出年轻人的消费偏好。8.2 智能设备的位置信息,商业价值广大智能手机设备的位置信息代表了消费者的位置轨迹,这个轨迹可以推测出消费者的消费偏好和习惯。在美国,移动设备位置信息的商业化较为成熟,GPS数据正在帮助很多企业进行数据变现,提高社会运营效率。在中国,移动大数据的商业应用刚刚开始,在房地产业、零售行业、金融行业、市场分析等领域取得了一些效果。移动大数据中的位置信息代表了用户轨迹,商业应用较早。2014年,美国移动设备位置信息的市场规模接近1000亿美金。但中国移动设备位置信息的商业应用才刚刚开始。目前主要的应用在互联网金融的反欺诈领域。
线上的欺诈行为具有较高的隐蔽性,很难识别和侦测。P2P贷款用户很大一部分来源于线上,因此恶意欺诈事件发生在线上的风险远远大于线下。中国的很多数据处于封闭状态,P2P公司在客户真实信息验证方面面临较大的挑战。
移动大数据可以验证P2P客户的居住地点,例如某个客户在利用手机申请贷款时,填写自己居住地是上海。但是P2P企业依据其提供的手机设备信息,发现其过去三个月从来没有居住在上海,这个人提交的信息可能是假信息,发生恶意欺诈的风险较高。移动设备的位置信息可以辨识出设备持有人的居住地点,帮助P2P公司验证贷款申请人的居住地。
借款用户的工作单位是用户还款能力的强相关信息,具有高薪工作的用户,其贷款信用违约率较低。这些客户成为很多贷款平台积极争取的客户,也是恶意欺诈团伙主要假冒的客户。
某个用户在申请贷款时,如果声明自己是工作在上海陆家嘴金融企业的高薪人士,其贷款审批会很快并且额度也会较高。但是P2P公司利用移动大数据,发现这个用户在过去的三个月里面,从来没有出现在陆家嘴,大多数时间在城乡结合处活动,那么这个用户恶意欺诈的可能性就较大。
移动大数据可以帮助P2P公司在一定程度上来验证贷款用户真实工作地点,降低犯罪分子利用高薪工作进行恶意欺诈的风险。
P2P企业可以利用移动设备的位置信息,了解过去3个月用户的行为轨迹。如果某个用户经常在半夜2点出现在酒吧等危险区域,并且经常有飙车行为,这个客户定义成高风险客户的概率就较高。移动App的使用习惯和某些高风险App也可以帮助P2P企业识别出用户的高风险行为。如果用户经常在半夜2点频繁使用App,其成为高风险客户的概率就较大。
移动大数据在预防互联网恶意欺诈和高风险客户识别方面,已经有了成熟的应用场景。很多公司已经开始利用第三方机构的数据,预防互联网恶意欺诈和识别高风险客户,并取得了较好的效果。移动大数据应用场景正在被逐步挖掘出来,未来移动大数商业应用将更加广阔。
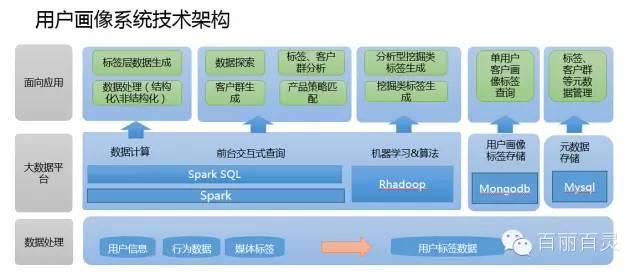
用户画像的技术选型与架构实现
大数据分析-用户画像详解























本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/65172.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
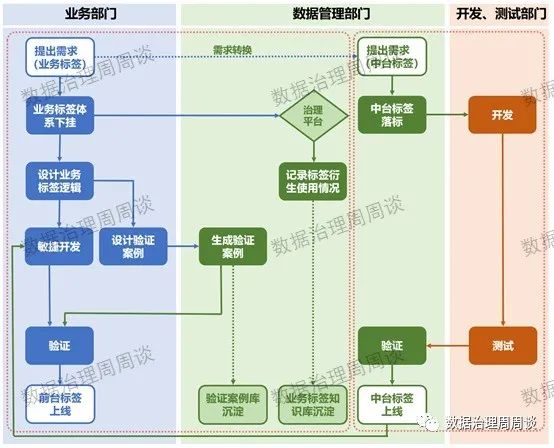
数据应用案例之“客户画像体系”
01
数据标签管理和应用中的问题
数据标签是面向业务的数据资产组织方式,是数据资产为业务系统赋能的重要载体。数据标签从源系统采集、数据清洗、分层管理,到最终根据业务需求组织成可使用的标签,是一个漫长的过程,其中有五大痛…
行为画像分析 行业客户画像 行业用户画像
在大数据时代,洞察「用户画像」是精准营销的基础和前提。它可以给出一个用户的信息全貌,为品牌精准快速地分析用户行为习惯、消费习惯并制定精准营销计划提供坚实的数据和信息基础。
那么,品牌该如何构建精准的用户画像,从而实现…

客户画像中的聚类分析
客户画像会用聚类分析 实际工作中,最常使用的当属回归类模型,其次便是客户画像。即便是评分模型也会涉及到客户画像,由于首富客户的违约特征与普通百姓不同,故需进行区分,信用分池即为客户画像。 客户画像使用的技术为…

用户画像 客户喜好消费的商品分类模型表
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新) 用户画像 总文章 客户喜好消费的商品分类模型表
订单中 商品类目表 GDM层(临时表)SQL目的:统计用户订单…

如何做好会员用户画像分析,比消费者本身更懂自己?
随着各平台知识付费开启,“万物付费时代”已悄然而至。线下传统的粗犷式运营模式已不再符合时代潮流。如何在这样一个付费时代做好企业的精准化会员客户策略分析管理,成为当今人们尤为关注的话题。
作品背景:
某连锁超市在各地有80家线下零…
如何构建用户画像来实现精准营销?
用户画像,又称人群画像,是根据客户人口统计学信息,社交关系,偏好习惯和消费行为等信息而抽象出来的标签化画像。
构建客户画像的核心工作即是给客户贴“标签”(犹如娱乐圈中明星的立人设)
标签由两部分组…
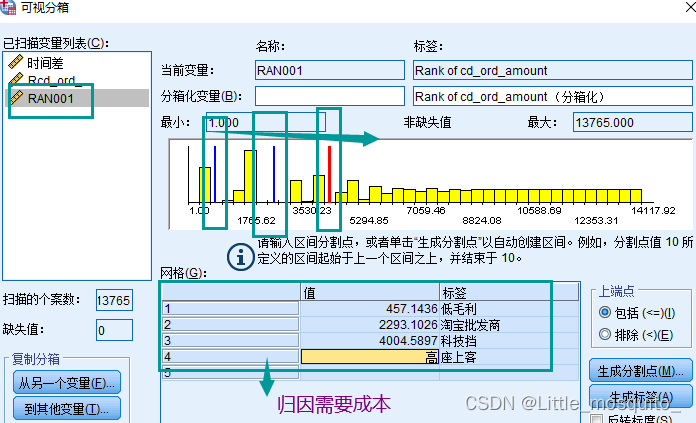
SPSS 市场细分:客户画像\客户价值模型
行为标签(x)\价值标签(y)
客户行为标签的制作步骤X:
判断x的个数分组:通过聚类算法(系统聚类、K均值聚类、俩阶段聚类、神经网络聚类);制作标签(重点&#…
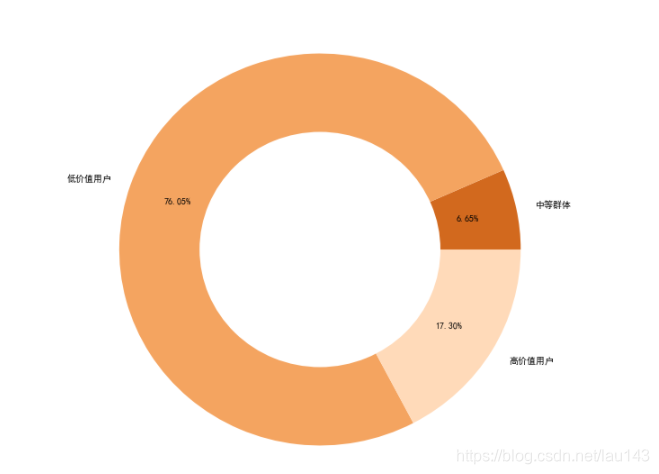
客户流失及用户画像分析
1 项目背景
在今天产品高度同质化的阶段,市场竞争不断加剧,企业与企业之间的竞争,主要集中在对客户的争夺上。“用户就是上帝”促使众多企业不惜代价去争夺尽可能多的新客户。但是,在企业不惜代价发展新用户的过程中,…
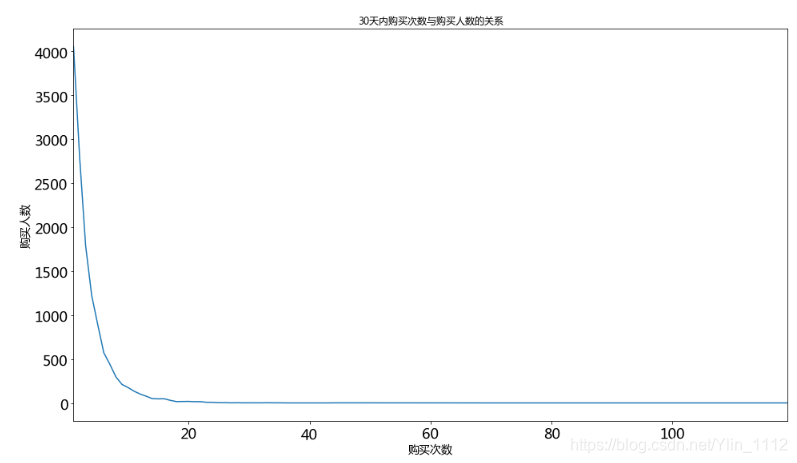
淘宝用户行为分析——用户画像
文章目录 一、数据介绍二、数据预处理2.1 数据抽样2.2 缺失值处理2.3 日期与时段处理2.4 制作用户标签表 三、用户行为标签3.1 用户浏览活跃时间段3.2 用户购买活跃时间段3.3 关于类目的用户行为3.3.1 浏览最多的类目3.3.2 收藏最多的类目3.3.3 加购最多的类目3.3.4 购买最多的…

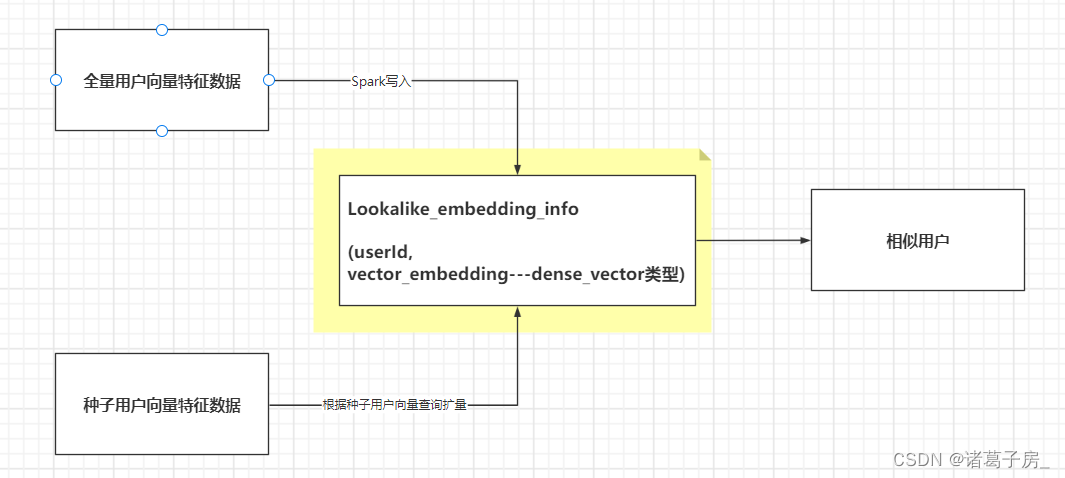
用户画像系列——Lookalike在营销圈选扩量中的应用
在用户画像系列——当我们聊用户画像,我们在聊什么?
介绍了用户画像的应用场景:
(1)个性化推荐
通过用户标签给用户推荐合适的商品或者内容
(2)营销圈选
根据组合条件(比如说:性别女、年龄25-30、都市白领)圈选出一部分用户,给他们发送p…

一键上手时下最火AI作画工具
摘要:在华为云ModelArts上, 无需考虑计算资源、环境的搭建,就算不懂代码,也能按照教程案例,通过Stable Diffusion成为艺术大师。 本文分享自华为云社区《跟着华为云ModelArts,一键上手时下最火AI作画工具》…

2019 智见 AI workshop in Beijing
[持续更新]2019 智见 AI workshop in Beijing 前言代季峰:卷积神经网络中的几何形变建模Deformable Conv V1Deformable Conv V2Tricks & Exprience 张士峰:物体检测算法的对比探索和展望Detector Algorithm Overviewanchor-basedanchor-free RefineD…

湖北黄冈中学2021年高考成绩查询,2019年黄冈中学高考成绩发布,包揽全市文科前13名,省内排名却不值一提...
2019年黄冈中学高考成绩发布,包揽全市文科前13名,省内排名却不值一提 2019年6月23日,黄冈中学公布了2019年黄冈中学的高考成绩,如下图所示,今年黄冈中学的高考成绩相比2018年略有提高。 全校参考总人数共883人…
Paper | Densely Connected Convolutional Networks
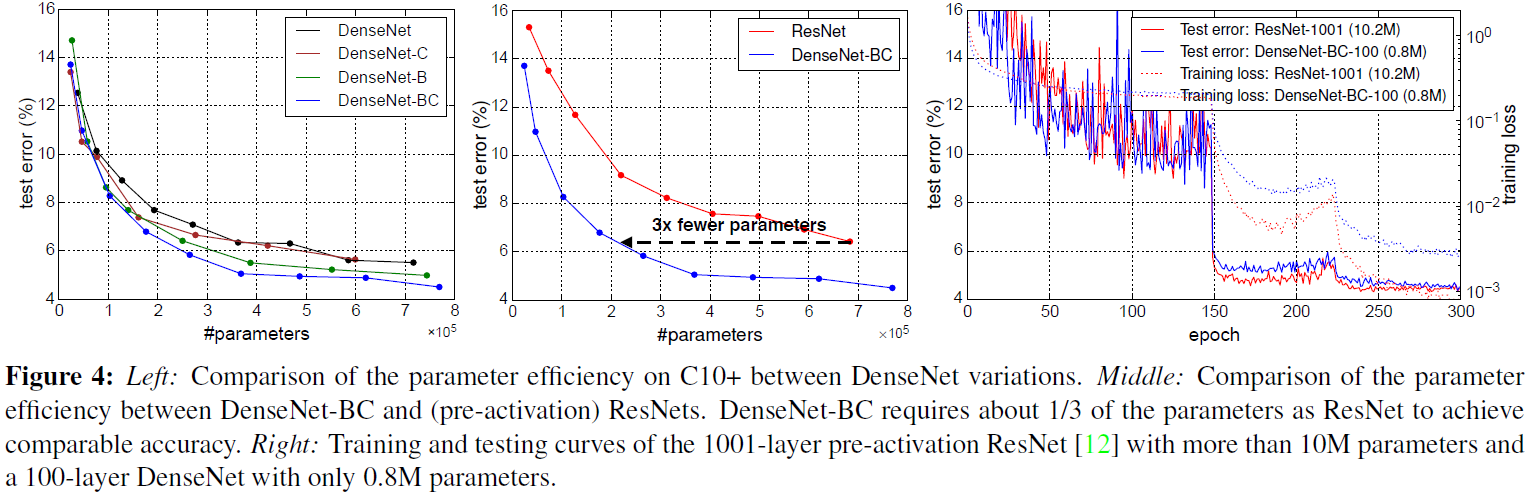
目录 黄高老师190919在北航的报告听后感故事背景网络结构 Dense blockDenseNet 过渡层成长率瓶颈层细节实验 发表在2017 CVPR。 摘要 Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to train if they contain…

黄冈中学2021高考成绩查询,清华公布2021丘班录取名单,黄冈中学表现尴尬,衡中无人上榜...
每个学生心中都有个清华和北大梦,只不过后来发现自己能力有限,清华北大更是遥不可及,学生眼下的想法只是纠结能不能考上重点大学,但是这也并不妨碍大家对名牌院校的好奇心。 清华大学一直是理科学生梦寐以求的高等学府,…

清华商汤上海AICUHK提出Siamese Image Modeling,兼具linear probing和密集预测性能!...
关注公众号,发现CV技术之美 本文分享论文『Siamese Image Modeling for Self-Supervised Vision Representation Learning』,由清华(黄高组)&商汤(代季峰组)&上海AI Lab&CUHK提出Siamese Image…

2022CVPR云分享 | 清华大学四位讲者带你玩转计算机视觉
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! 7月20日晚上7点半,本期我们邀请到清华大学黄高老师实验室的四位讲者,为大家解读2022CVPR的优秀论文! 哔哩哔哩直播通道 扫码关注AI TIME哔哩哔哩官方账号预约直播 7月20日 19…