01
波士顿动力机器狗去新西兰放羊了!网友:不努力连狗都不如
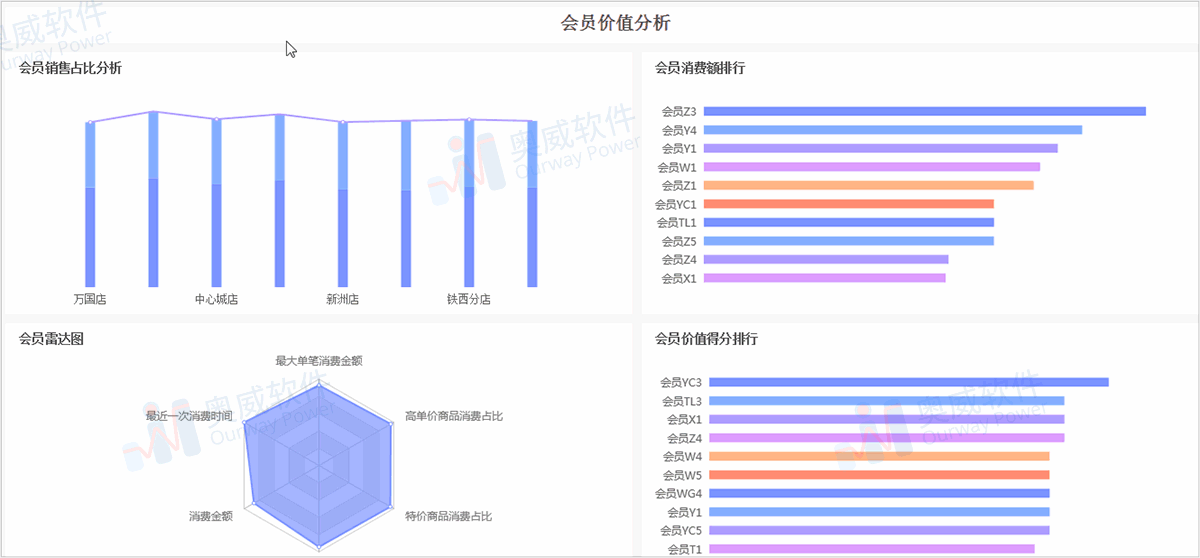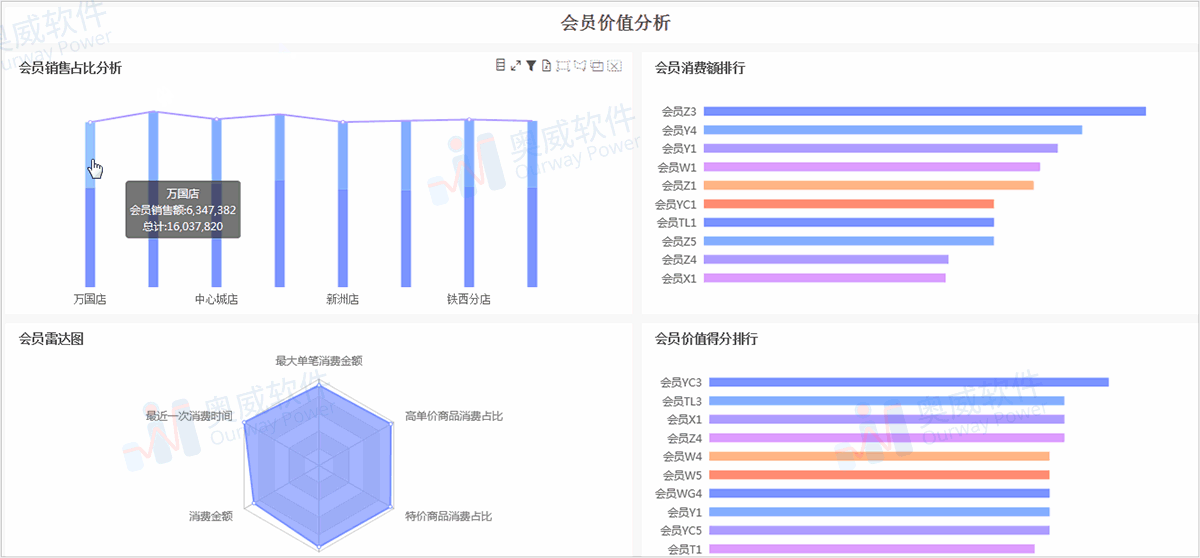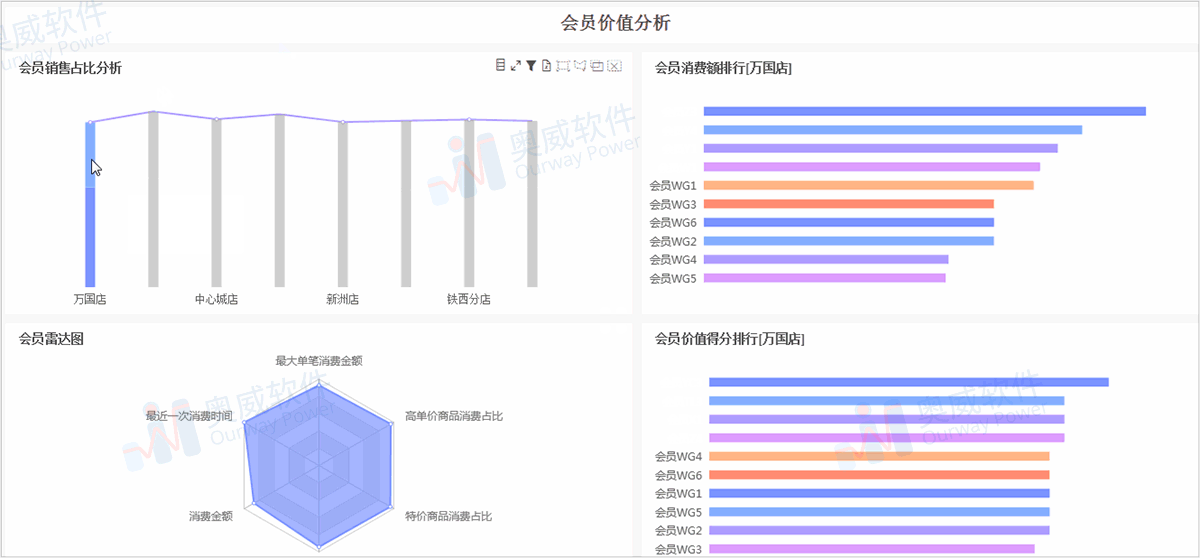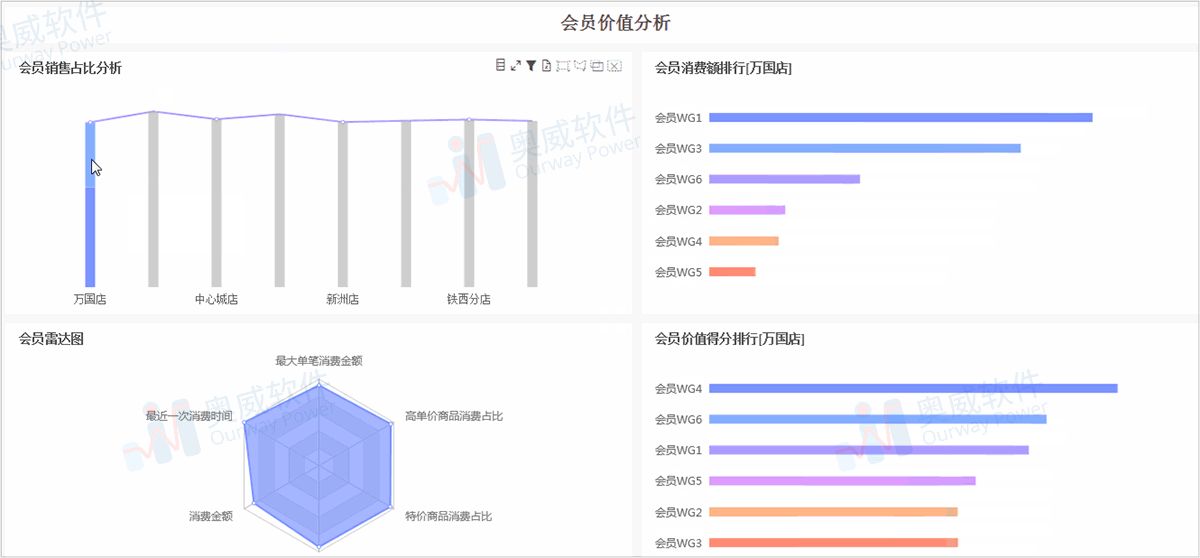
波士顿动力的科学家可能做梦也没想到,他们研制出来的Spot机械狗,刚刚商用,就被训练来放羊了。
新西兰,一个因为牛奶和羊毛被中国人熟知的国家,农牧业是他们的一大经济支柱。因此,很多当地的科创企业都非常关注农牧业的科技创新。
波士顿动力的小型机器狗Spot因其矫健灵活的身体素质,轻松穿越复杂地形的能力以及长达两个小时的续航时间,看起来就很适合在农场巡逻,甚至承担起放羊的重任。最近,当地一家叫做Rocos的机器人软件公司,就放出了这样一段demo。
此前,Spot已经被用于多个场景。
协助出警:马萨诸塞州警察局是美国第一个使用波士顿动力公司的Spot机器狗的执法机构。根据ACLU获得的文件,马萨诸塞州警察局拆弹小队从波士顿动力公司租借了Spot机器狗,租期三个月,从8月开始,一直持续到11月。
实时地图构建:很多危险或狭窄的场景下不适合人类工作,比如建筑工地、车间等,但是我们又想了解内部的情况,绘制室内地图。这时Spot就能派上用场了,Spot本身携带有摄像头、雷达、红外传感器、GPS定位系统等,还有超强的运动能力,可以绕过各种障碍,做实时地图构建不费吹灰之力。
此外,你可以用Python可以直接控制Spot了,波士顿开源了Spot的SDK,意味着你买了Spot之后,可以利用自己DIY它的功能,拥有自己的专用机器狗不是梦。
利用Python开发Spot功能
02
微软推人人可用的机器学习,打通windows应用程序任督二脉
北京时间 5 月 19 日晚间 11 点,微软一年一度的「Build开发者大会」正式线上开幕。今年的大会,微软着重强调了机器学习领域的进展。Build大会上微软宣布将开源多个机器学习工具包。
这次机器学习领域的重头戏要属WhiteNoise 了,WhiteNoise 是一个使用差分隐私的工具包,不久就可以通过 Azure 和 GitHub 上的开放源码来使用了。差分隐私旨在提供一种加密方法,当从统计数据库查询时,最大化数据查询的准确性,同时最大限度减少识别其记录的机会。
WSL将支持GPU:
假设您在Windows主机上安装了正确的GPU驱动程序,将可用于任何已安装的WSL发行版(Ubuntu、Fedora、openSUSE),而无需安装任何其他软件包。为了实现WSL 2对GPU的支持,WDDMv2.9驱动程序将把GPU-PV扩展到Linux端。这个过程是由一个新的Linux内核驱动Dxgkrnl来实现,该驱动利用GPU-PV协议将GPU暴露给用户模式的Linux。
有了GPU支持以后,微软还在WSL中加入了机器学习API DirectML。这样开发者就能够在WSL上训练神经网络,不必再单独安装一个Linux系统。而且,微软官方郑重宣布,WSL将很快推出英伟达CUDA加速功能,可以加速cuDNN、cuBLAS、TensorRT等CUDA-X库。
除了CUDA支持之外,微软还在WSL中带来了对NVIDIA-docker工具的支持,在云中执行的容器化GPU工作负载可以在WSL内部按原样运行。既然已经支持了GPU,那么对GUI图形化程序的支持也扫除了障碍。过去WSL只能使用命令行应用,今后WSL将可以直接运行Linux中的GUI应用。
信息来源:新智元
03
推动量子计算与AI融合,飞桨成为中国首个支持量子机器学习的深度学习平台
“新基建”给中国“产业智能化”带来强劲的新引擎。飞桨作为智能时代的操作系统与技术底座,也再次迎来高光时刻。5月20日,由深度学习技术及应用国家工程实验室与百度联合主办的“WAVE SUMMIT 2020”深度学习开发者峰会以线上形式召开。
本届峰会,飞桨公布最新全景图,带来多达35项全新发布和重磅升级,不仅进一步升级核心框架、完善从开发训练到部署的全流程工业级极致体验、深化企业端服务,更着眼未来,引领布局前沿技术,首发量子机器学习开发工具“量桨”,以及蓄力AI人才培养和开发者生态,发布青少年AI科普教育“晨曦计划”、“星辰计划”开发者探索基金等。
百度飞桨总架构师于佃海、百度深度学习技术平台部高级总监马艳军在峰会上详细介绍了飞桨开源深度学习平台的最新进展。百度AI开发平台部总监忻舟分享了飞桨企业版EasyDL零门槛AI开发平台的全面升级。百度研究院量子计算研究所所长段润尧重磅发布量桨。继2019年11月的WAVE SUMMIT秋季峰会后,短短半年时间,飞桨全平台带来35项全新发布和重要升级,其中包括8大新产品和27项升级。
从开发、训练到部署,飞桨开源深度学习平台为开发者带来开发全流程体验的提升。马艳军介绍,飞桨官方模型库新增39个算法,算法总数达到146个,预训练模型200多个,助力开发者进行低代码二次开发。全新发布3个端到端开发套件:PaddleClas图像分类、Parakeet语音合成和PLSC海量类别图像分类。全面升级PaddleDetection目标检测开发套件的模型数量、性能和产业应用能力。
训练方面,新增自动混合精度、重计算机制等底层技术升级,提升训练框架的速度,降低显存占用;扩展了模型并行、弹性训练等大规模分布式训练能力,全新发布PaddleCloud云上任务提交工具,让训练更快、更好、更省,满足苛刻的工业级应用需求。
部署层面,飞桨全面打通多平台、多场景的部署能力,持续夯实模型压缩PaddleSlim、原生推理引擎Paddle Inference、在线部署框架Paddle Serving、轻量化预测引擎Paddle Lite等端到端部署核心能力,全新发布国内首个开源JavaScript深度学习前端推理引擎Paddle.js,用于小程序、网页端部署。
此外还有全新发布的PaddleX全流程开发工具,后端开源,可快速集成,支持多端部署和模型加密。独具特色的飞桨Master模式全面升级,预训练模型更多、迁移学习能力更强。企业开发者可以通过PaddleHub和EasyDL享用飞桨Master模式,仅用少量数据、简单操作、更低成本,实现多场景下的优异模型效果。
(图:飞桨发布量子机器学习开发工具Paddle Quantum量桨)
除了以上前沿的开源工具,飞桨还率先支持了复数神经网络,全面支持跨学科的机器学习研究。段润尧重磅发布量子机器学习开发工具Paddle Quantum量桨。飞桨成为国内首个、也是唯一支持量子机器学习的深度学习平台。通过飞桨深度学习平台赋能量子计算,量桨为领域内的科研人员以及开发者便捷地开发量子人工智能的应用提供了强有力的支撑,同时也为广大量子计算爱好者提供了一条可行的学习途径。
(图:百度研究院量子计算研究所所长段润尧介绍
Paddle Quantum量桨)
峰会的最后,飞桨发布了百度“星辰计划”开发者探索基金的参与机制,将以100亿流量、1000万基金、1000万算力支持广大开发者和百度一起参与到用AI技术解决社会问题的理想和实践中,用科技的力量让世界变得更美好。
信息来源:飞桨PaddlePaddle
04
登顶GLUE的百度ERNIE再突破:语言生成预训练模型ERNIE-GEN刷新SOTA
过去一年,百度提出的 ERNIE 通过持续学习海量数据中的知识在中英文十六个自然语言理解任务上取得领先效果,并在去年 12 月登顶权威评测榜单 GLUE 榜首。ERNIE 在工业界也得到了大规模应用,如搜索引擎、新闻推荐、广告系统、语音交互、智能客服等。今日,研究团队又在自然语言生成任务上实现新的突破。
他们提出了首个基于多流(multi-flow)机制生成完整语义片段的预训练模型 ERNIE-GEN,显著提升了自然语言生成任务效果。借助飞桨的高效分布式训练优势,百度开源了 ERNIE-GEN 的英文预训练模型,并对开源工具进行了动静合一升级,核心代码精简了 59% 。
逐片段生成任务:
ERNIE-GEN 在生成预训练中提出了逐片段 (span-by-span) 生成任务的训练目标。片段(span)是 1 到 3 个词组成的 N-Gram。在生成时,模型对每个片段进行整体预测,片段内部词的生成互不依赖。这种训练方式让模型具备短语粒度的生成能力,能够提升生成质量。
填充生成机制:
ERNIE-GEN 在训练和解码时用统一的「[ATTN]」和第 n 个位置编码作为生成第 n 个词的底层输入。「[ATTN]」与前 n-1 个词根据词义信息和位置信息进行 Self-Attention 计算,自适应地将上文中的重要信息「填充」(infilling)到当前词的表示中,用以进行预测。这种生成方式减小了对上一个词的依赖,训练和解码的一致性减弱了曝光偏差。
填充生成机制:左图为 word-by-word 生成,右图为 span-by-span 生成
噪声感知生成方法:
为了进一步强化编码器的鲁棒性,ERNIE-GEN 在训练时按一定概率将目标文本中的词替换成噪声,用来模拟解码时的生成错误,提升模型排除错误干扰的能力。研究者在实验中发现,仅用简单的随机词替换策略就能较好地提升生成效果。
多片段-多粒度目标片段采样:
为了解决预训练时单一的目标片段采样导致编码器、解码器交互弱的问题,ERNIE-GEN 使用了多目标片段的采样策略,使源文本片段和目标文本片段充分交叉,增强二者的关联性,有利于编码器和解码器的联合学习。同时,考虑到学习目标的多样性,在采样目标片段时使用了两种不同的长度分布。
Multi-Flow 框架:
为了实现上述的填充生成机制和逐片段生成,ERNIE-GEN 基于 transformer 设计了 multi-flow attention 结构。其中 contextual flow 用于提供上文的表示;word- by-word flow 和 span-by-span flow 均由「[ATTN]」占位符+位置编码的序列构成,二者根据不同的掩码矩阵分别实现 word 粒度和 span 粒度的生成。
ERNIE-GEN 开源项目包含飞桨静态图、动态图两个版本。基于更大规模预训练数据集的 ERNIE-GEN 也正式发布在 GitHub 上。
GitHub链接:
https://github.com/PaddlePaddle/ERNIE/
论文链接:
https://arxiv.org/abs/2001.11314
信息来源:百度NLP
05
央视“AI 电视”上线!打造智能化服务场景
作为中央广播电视总台央视网旗下互联网电视新媒体运营机构,未来电视充分发挥行业领军者角色,以 AI 算法和大数据为基础,在互联网电视大屏旗舰产品 CCTV. 新视听重磅上线“AI 电视”功能。
通过“AI 电视”功能,CCTV. 新视听将重点打造央视频道专区,构建中央电视台专属阵地,既满足用户看电视的传统收视习惯,又能为不同用户提供差异化智能服务。除了内容层面的优势,CCTV. 新视听还通过人工智能、大数据等技术打造智能化服务场景,包括 AI 听、AI 识图推荐、AI 语音等,全面优化用户体验。
信息来源:中关村在线
06
本周论文推荐
【ACL 2020 | 百度】:NLP 文本生成与摘要
Leveraging Graph to Improve Abstractive Multi-Document Summarization
论文介绍:
多文档摘要(Multi-Document Summarization)技术自动为主题相关的文档集生成简洁、连贯的摘要文本,具有广阔的应用场景,例如热点话题综述、搜索结果摘要、聚合写作等。
生成式多文档摘要方法的难点之一是如何有效建模文档内及文档间的语义关系,从而更好地理解输入的多文档。为此,本论文提出基于图表示的多文档生成式摘要方法 GraphSum,在神经网络模型中融合多文档语义关系图例如语义相似图、篇章结构图等,建模多篇章输入及摘要内容组织过程,从而显著提升多文档摘要效果。
GraphSum 基于端到端编解码框架,其中图编码器利用语义关系图对文档集进行编码表示,图解码器进一步利用图结构组织摘要内容并解码生成连贯的摘要文本。GraphSum 还可以非常容易地与各种通用预训练模型相结合,从而进一步提升摘要效果。在大规模多文档摘要数据集 WikiSum 和 MultiNews 上的实验表明,GraphSum 模型相对于已有的生成式摘要方法具有较大的优越性,在自动评价和人工评价两种方式下的结果均有显著提升。
END