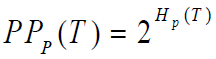NLP学习笔记(4)——语料库和语言知识库
- 1. 基础知识
- 2.语料库技术的发展
- 第一个阶段:早期,20世纪五十年代中期之前
- 二个阶段:沉寂时期,1957-20世纪八十年代初
- 第三个阶段:复苏与发展时期,20世纪八十年代以后
- 3.国内语料库的研究状况
- 4. 语料库的类型
- (a)按照其内容构成和目的进行划分:
- (b)按语言种类划分
- 其他信息
- 5.重点:语料库建设中存在的问题
- 5.1对于语料库的设计,需要考虑的问题:
- 5.2 汉语语料库开发中存在的问题
- 6.介绍一些典型语料库
- 7.词汇知识库
- 7.1 WordNet
- 7.2 HowNet(知网)
- 7.3 概念层次网络
1. 基础知识
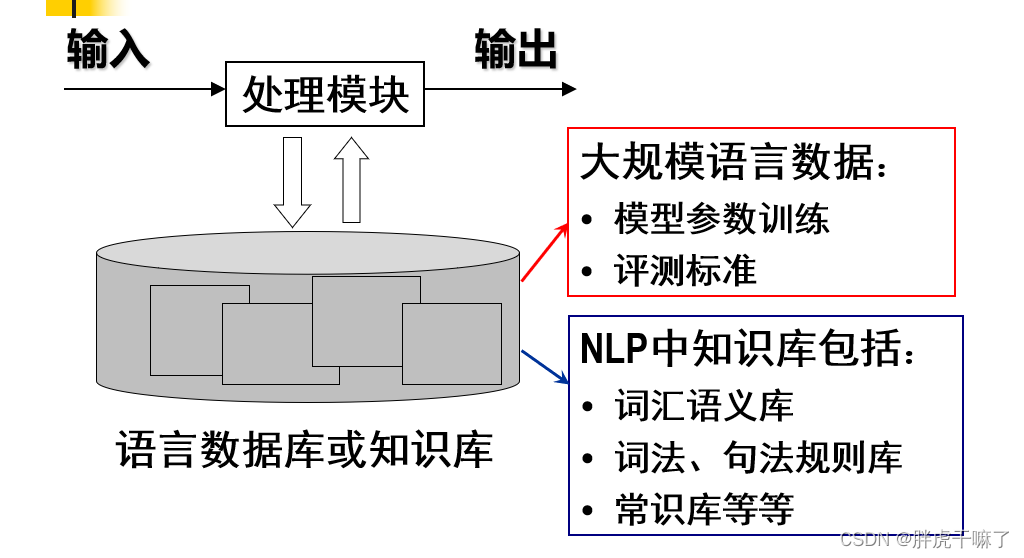
对于预先准备的知识材料,分为语言数据库(语料库)和知识库两种。
对于语言数据句库:主要是大规模的语言数据,难点在于模型参数训练与评测标准的设置;
对于知识库:包括词汇语义库,词法、句法规则库,常识库等等
语料库语言学的定义:基于语料库进行语言学研究
下面介绍其他几种定义,可能更有益于对其理解:
- 根据篇章结构对语言的研究称为语料库语言学
- 基于现实生活中语言运用的实例进行的语言研究称为语料库语言学
- 以语料为语言描写的起点或以语料为验证有关语言的假说的方法称为语料库语言学。
关于语料库语言学研究的内容:
- 语料库的建设与编纂
- 语料库的加工和管理技术
- 语料库的使用
2.语料库技术的发展
掌握程度:分清三个阶段的各自时间节点,以及判断其低谷期、复苏的特征及原因
第一个阶段:早期,20世纪五十年代中期之前

二个阶段:沉寂时期,1957-20世纪八十年代初
沉寂的原因大概是由于句法理论的兴起,即NLP先验知识运用的另一分支,知识库的发展

第三个阶段:复苏与发展时期,20世纪八十年代以后
(1)其复苏的特征有二:
- 第一是第二代语料库相继建成
- 第二是基于语料库的研究项目增多



(2)其复苏的原因同样有二:
(i)首先,得益于计算机的迅速发展,计算能力与速度的增强使得语料库技术有了用武之地;
(ii)其次,转换 生成语言学派对语料库的批判不都正确(如指责计算机分析语料是伪技术),有的是片面的甚至是错误的(如对语料数据价值的否定)
3.国内语料库的研究状况
掌握情况要求:了解现状即可,代表性内容要进行记忆



4. 语料库的类型
按照不同的标准,可以将语料库进行许多种划分
(a)按照其内容构成和目的进行划分:
(1)异质的:仅进行最简单的语料收集方法,没有事先规定和选材原则
(2)同质的:与上一条相反,如美国TIPSTER项目只收集军事方面的文本内容
(3)系统的:充分考虑语料的动态和静态问题、代表性和平衡问题以及语料库的规模等问题
(4)专用的:如北美的人文科学语料库
(b)按语言种类划分
(1)单语语料库
(2)双语的或多语的语料库
对于非单语的语料库,要考虑是否要保证篇章对齐、句子对齐、结构对齐等问题
其他信息
(1)关于如何区分生语料和熟语料的方法:
看语料是否被标注了:
熟语料的特征——具有词性标注;有句法结构信息标注(树库);有语义信息标注
(2)对于平衡语料库,着重考虑了语料的代表性和平衡性
掌握要求为:对平衡语料库采集的规则要了解,可能考察选择判断
语料库采集的七项原则:
-1-语料的真实性
-2-可靠性
-3-科学性
-4-代表性
-5-权威性
-6-分布性
-7-流通性
其中,语料的分布性还可以考虑语料的科学领域分布、地域分布、时间分布和语体分布
(3)一个好像不是很重要的问题:

(4)关于平行语料库
其两种含义:
- 第一种是在同一种语言的语料上的平行。其平行性表现为语料选取的时间、对象、比例、文本数、文本长度等几乎是一致的。
举个例子:“国际英语语料库”,共有20个平行的子语料库,分别来自以英语为母语或官方语言和主要语言的国家,如英国、美国、加拿大、澳大利亚、新西兰等。建库的目的是对不同国家的英语进行对比研究。 - 第二种是指在两种或多种语言之间的平行采样和加工。例如,机器翻译中的双语对齐语料库
(5)比较重要:共时语料库和历时语料库
共时语料库:是为了对语言进行共时(同一时段)研究而建立的语料库。研究一个共时时空下的元素与元素之间的关系
历时语料库:是为了对语言进行历时研究而建立的语料库。研究一个历时切面中元素与元素关系的演化
判断是否为历时语料库的4条规则(要求可以完成选判)
-1-是否动态:语料库必须是开放的、动态的(基础)
-2-文本是否具有量化的流通度属性:所有的语料都应该来自于大众传媒,具有与传媒特色相应的流通度属性。其量化的属性值也是动态的(随时间与条件、背景的变化,其流通度属性存在差异)(来源存在流通度属性)
-3-深加工是否基于动态的加工方法:随语料库的动态变化采集,并进行动态地加工(加工过程的动态性)
-4-是否取得动态的加工结果:语料的加工结果也应是动态的和历时的(加工结果的动态性)
5.重点:语料库建设中存在的问题
重点章节
5.1对于语料库的设计,需要考虑的问题:
(1)动态与静态:

(2)代表性和平衡性:
一个语料库具有代表性,是指在该语料库上获得的分析结果可以概括成为这种语言整体或其指定部分的特征。
(3)规模:

(4)语料库的管理和维护

5.2 汉语语料库开发中存在的问题
(1)语料库建设的规范问题

需要考虑或保证的是:粉刺标准是否已经确定和统一;词类标记集被普遍采用和遵循;文本属性规范如何体现
(2)产权保护和国家语料库建设问题

6.介绍一些典型语料库

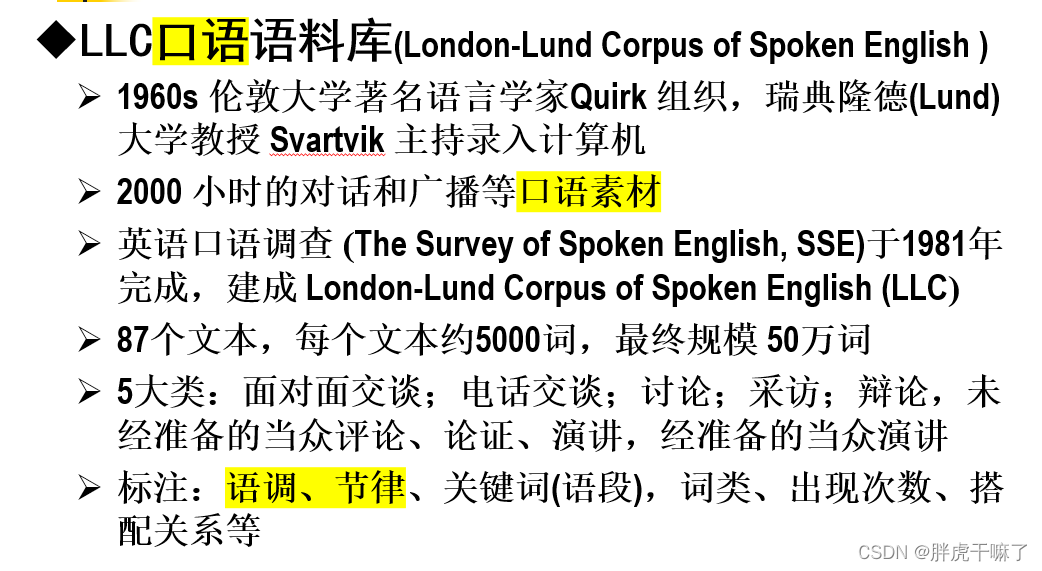




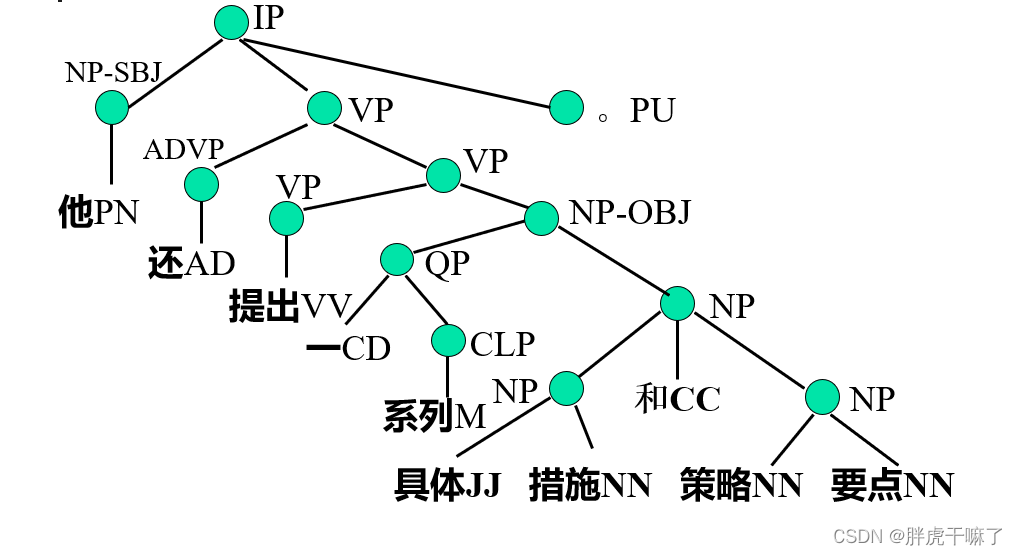
对于宾夕法尼亚大学树库的扩展:
自PropBank开始,出现语义角色标注
一个例子:


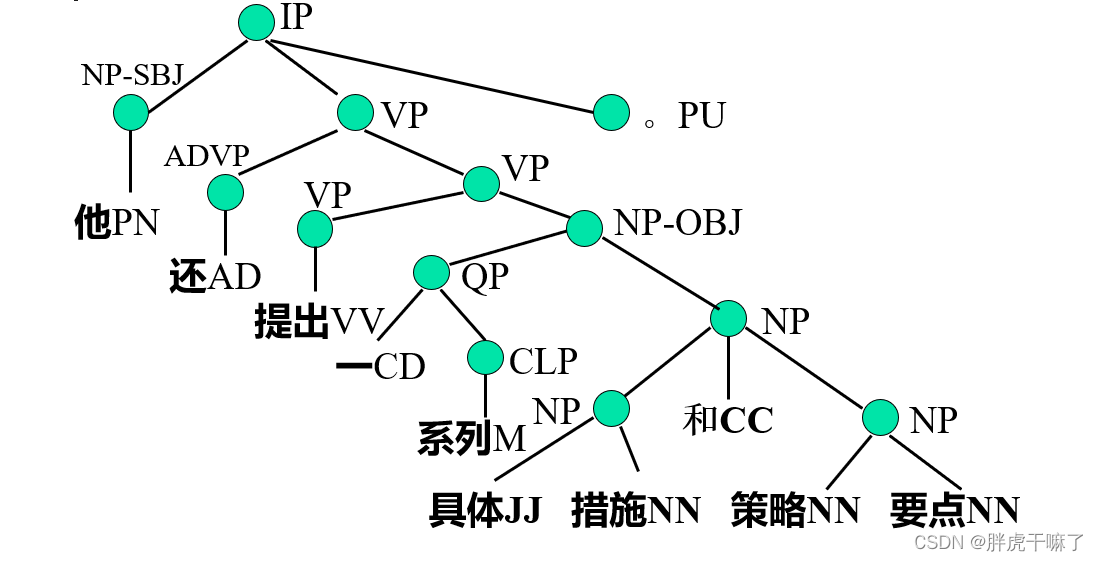
自PropBank开始,出现语义角色标注

自PropBank开始,语料库中开始出现语义角色标注

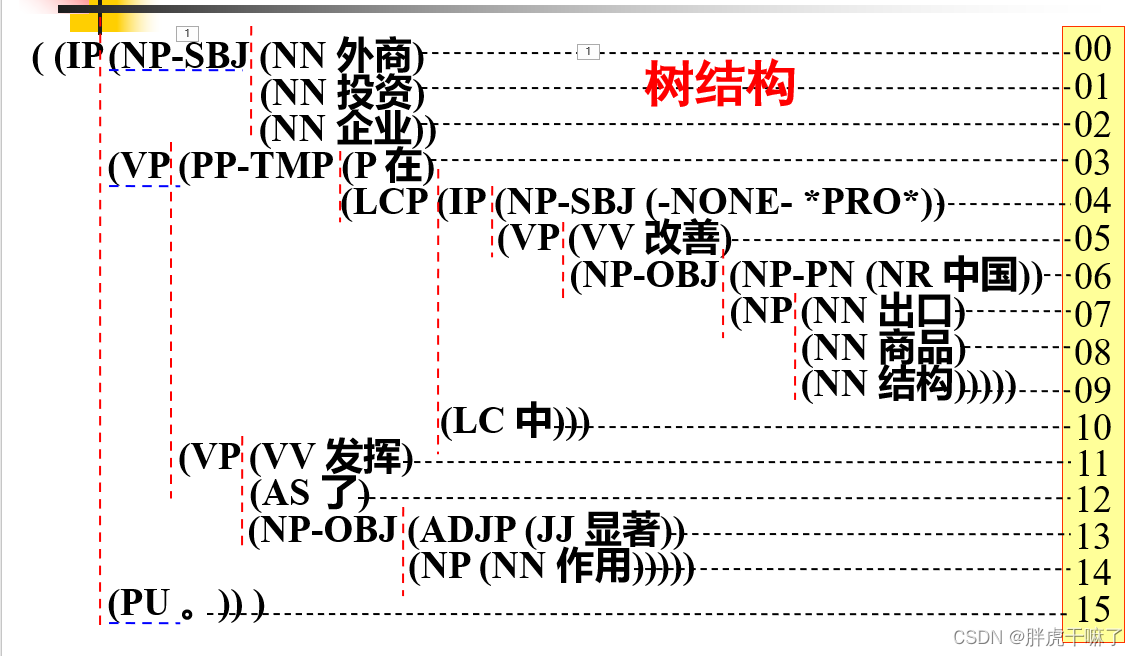
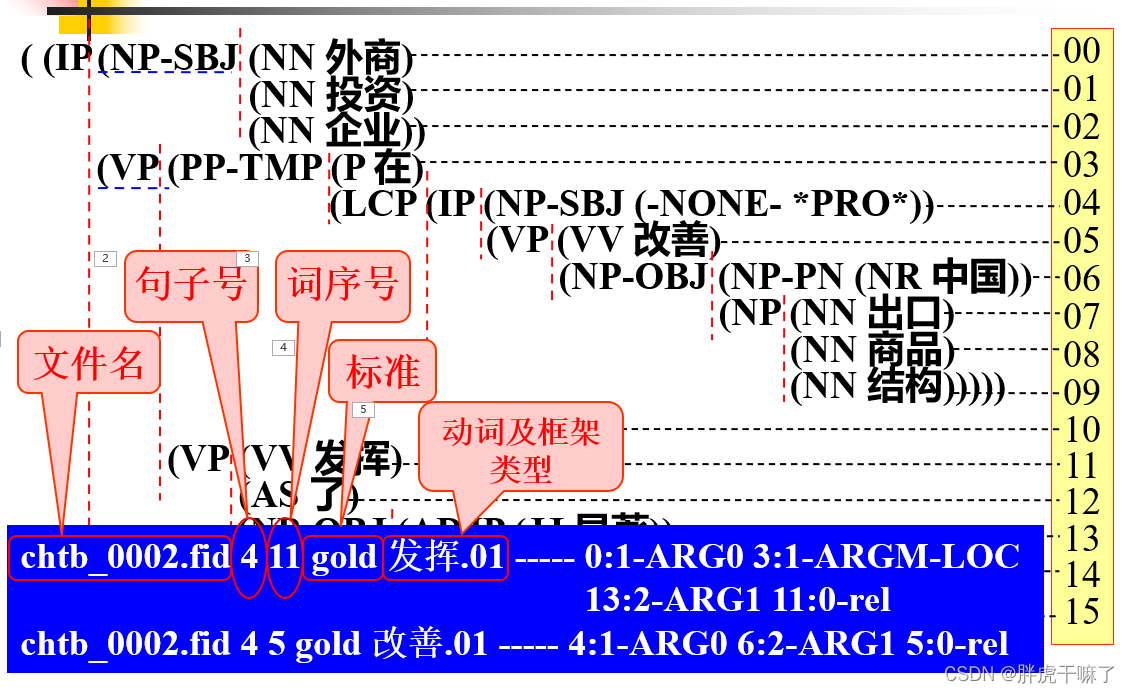
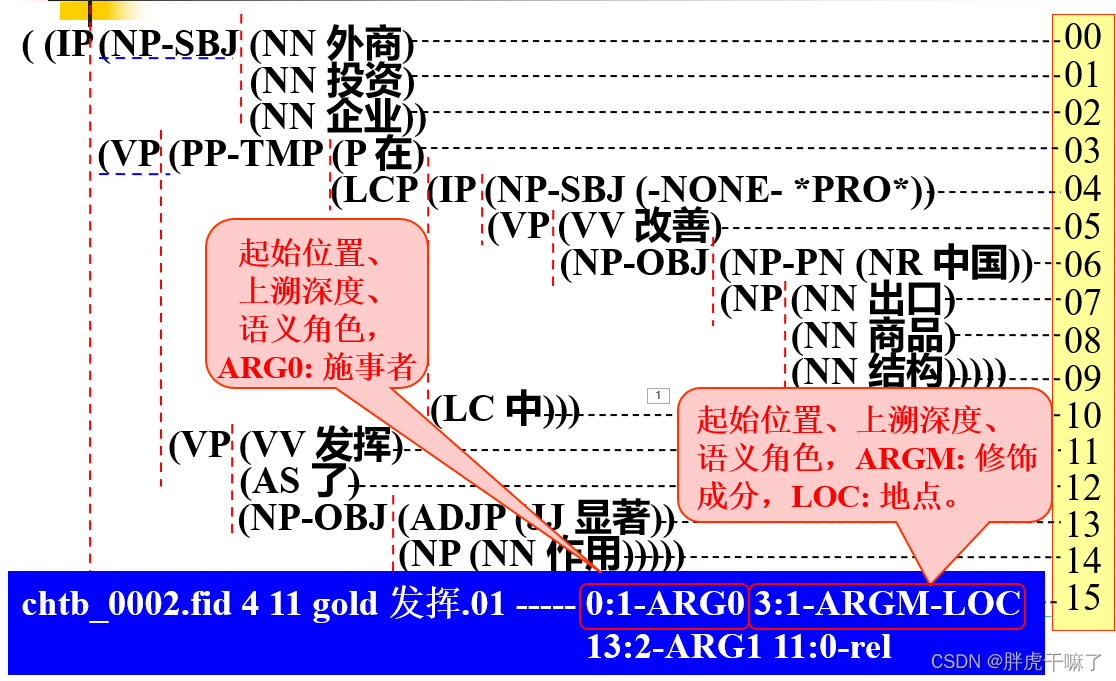
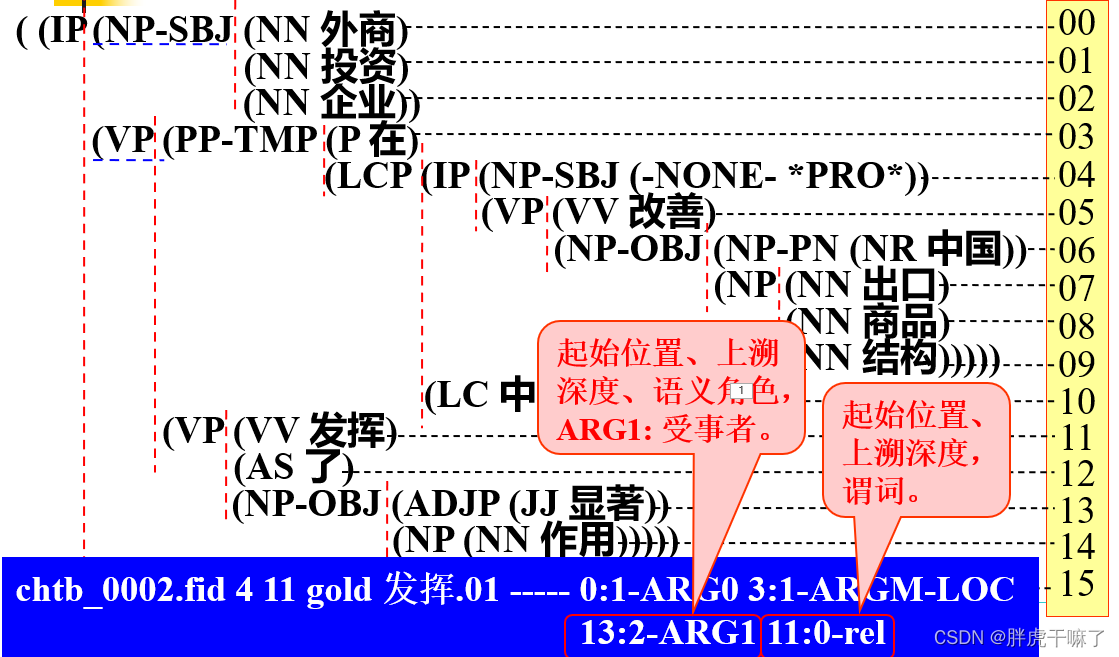


Nombank专注于标注树库中名次的词义和相关的论元信息;
而原PropBank标注的是句子的语法结构,PropBank拓展中的目标是对原树库中的句法节点标注上特定的论元标记。

对于NomBank中的中文属性库:

比较重要的是,针对语篇的UPenn语篇树库。
综合PropBank针对于句子的语法结构,NomBank标注树库中名词的词义和相关论元信息,UPenn则标注语篇结构信息

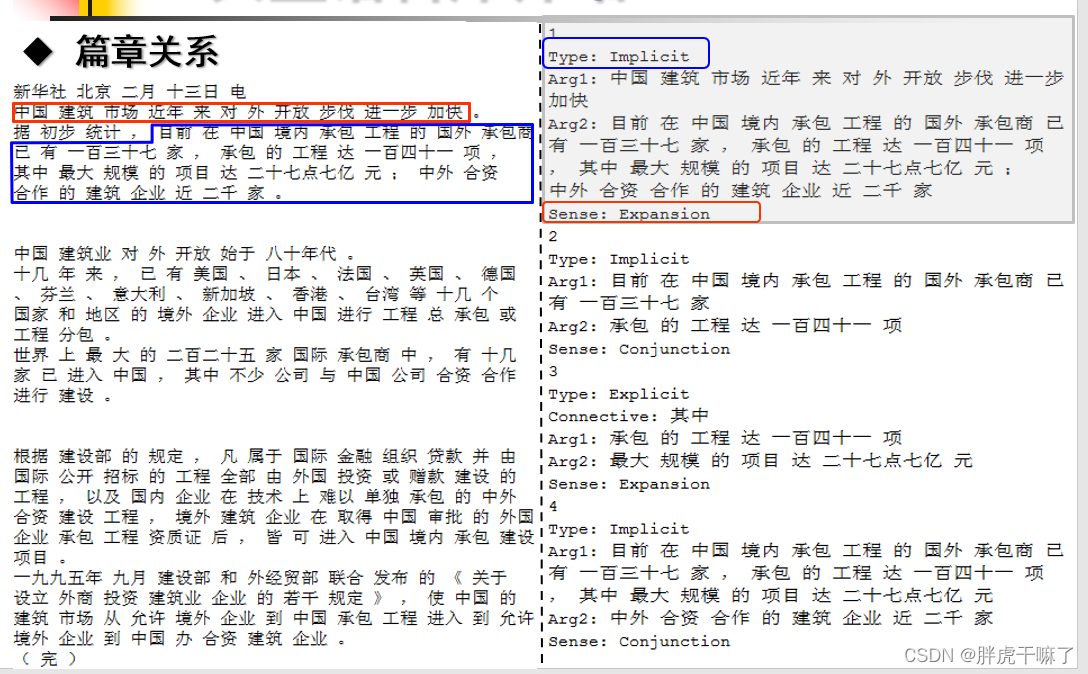
上图左侧是一片完整的文档,在这篇文档中有若干个篇章关系。右侧则罗列出了该文档第一段的关系。下面对其关系进行分析。
关系1、2为隐式关系(相关类型包括显式和隐式),关系1的参数Arg1与Arg2的范围分别标在左图的红色、蓝色方框中,其功能类型的判断为扩展类型。
对于关系三,是一个显式的关系,其关联词(特属于显式的关系Explicit)为“其中”,功能类型是扩展类型。
在上文中的例子中,我们可以发现,PDTB(Penn Discourse Tree Bank)风格下的标注体系允许两个篇章关系的文本之间存在覆盖、嵌套和交叉。
关于其对应的汉语篇章树库(CDTB)1.0
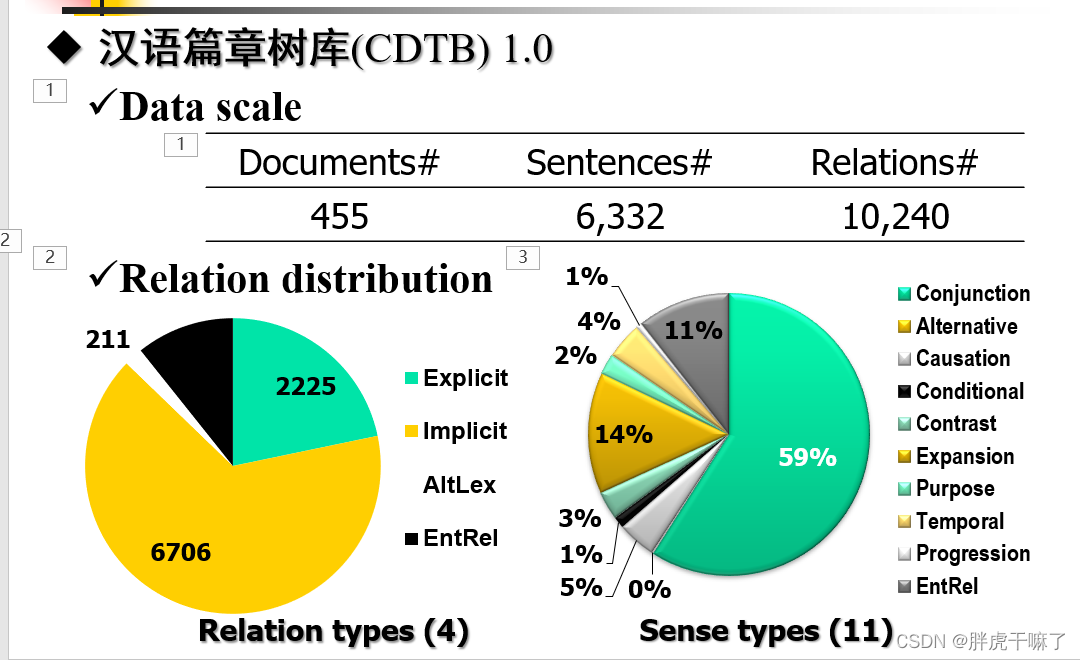
中英篇章树库对比(要求了解即可)
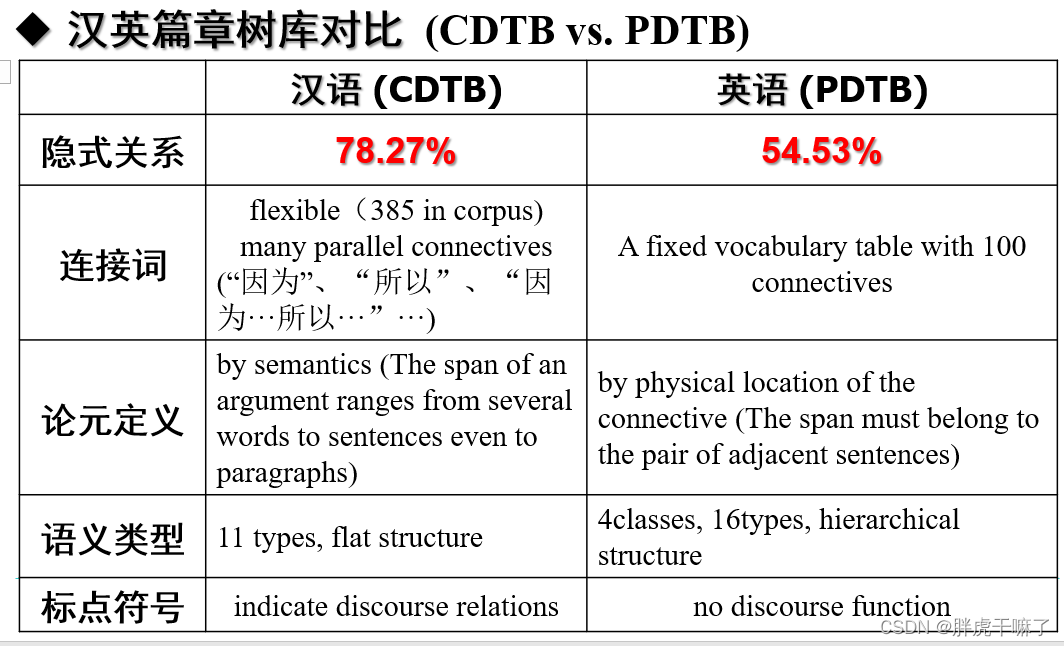
可以观察到,中文中的隐式关系比例要高于英文,其关联词没有明确的定义,且组合关联词的现象较多,用法灵活。中文中(CDTB)的Argument是根据语义定义的,其范围可以是某个短语也可以跨越几个段落,中文中的标点,(比较典型的如逗号)往往具有篇章关系指示功能。
对于英文(PDTB)是依据位置定义的,显式关系中在句法上与关联词相连的为Arg2,其余部分定义为Arg1;非显式关系中的前依据定义为Arg1,后一句为Arg2.




PDT的三个层次



7.词汇知识库
关于知识库,主要分为两种,WordNet与HowNet
需要掌握:
关于WordNet,有哪四种关系
关于HowNet,是什么样的关系,关系为单向还是双向的(不同关系的单、双向不同),关系中有多少种类型
7.1 WordNet
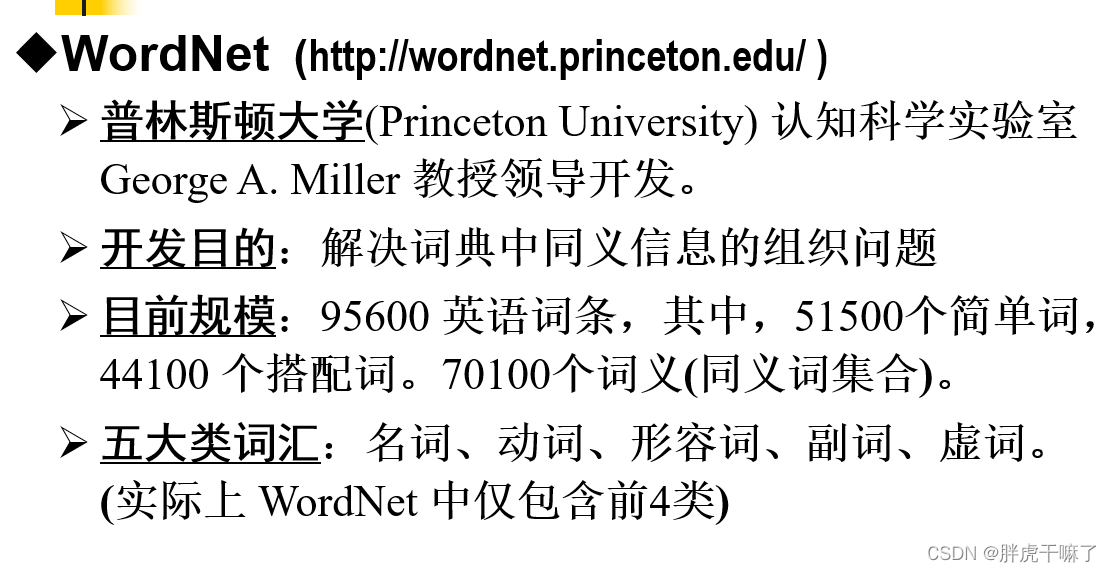

WordNet是按语义关系来组织的,故而WordNet之中的关系表现为语义关系。
关于WordNet的四种语义关系:
- 同义关系
- 反义关系
- 上下位关系(从属/上属关系)
- 部分关系(部分/整体关系)
关于WordNet的应用:
词汇消歧、语义推理、理解等

7.2 HowNet(知网)
比较重要


- 关于知网的特色
知网作为一个知识系统,名副其实地是一张网,其着力反映概念的共性和个性;同时还要反映概念之间 和概念的属性之间的各种关系。
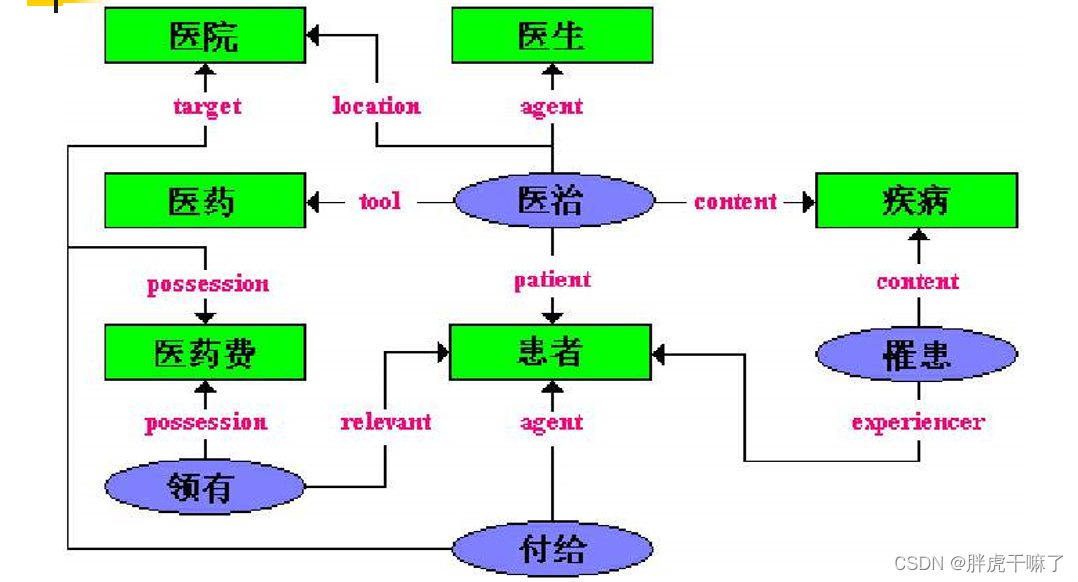
- 知网描述的关系:
-1-上下位关系(与WordNet共有)
-2-同义关系(与WordNet共有)
-3-反义关系(与WordNet共有)
-4-对义关系
-5-部件-整体关系(与WordNet共有)
-6-属性-宿主关系
-7-材料-成品关系
-8-施事/经验者/关系主体-事件关系(如“一生”、“雇主”)
-9-受事/内容/领属物等-事件关系(如“患者”、“雇员”)
-10-工具-事件关系(如“手表”、“计算机”)
-11-场所-事件关系(如“银行”、“医院”)
-12-时间-事件关系(如“假日”、“孕期”)
-13-值-属性关系(如“蓝”、“慢”)
-14-实体-值关系(如“矮子”、“傻瓜”)
-15-事件-角色关系(由加角色名体现,如“购物”、“盗墓”)
-16-相关关系(如“谷物”、“煤田”)
7.3 概念层次网络
(Hierarchical Network of Concepts,HNC)