map和set
STL分为序列式容器(vector、list、deque)和关联式容器(map、set)
序列式容器:数据与数据之间没有很强的联系。(各个数据之间没什么关联)。底层为线性序列的数据结构,里面存储的是元素本身。栈和队列是适配器。
关联式容器:数据和数据之间有很强的关联关系(在数据检索时比序列式容器效率更高。底层是红黑树,再底层是一棵搜索树。)
set
set的本质是Key模型(Key模型就是确认在不在的模型)。典型的set底层是二叉搜索树
 Compare是一个仿函数,用来比较。默认给的是less,相当于operator<,我们可以传别的,来控制这里的比较规则、比较方式。
Compare是一个仿函数,用来比较。默认给的是less,相当于operator<,我们可以传别的,来控制这里的比较规则、比较方式。
key_comp/value_comp获取key/value的比较器。 提供它两是为了保持set与map的一个兼容
set支持增删查,不支持修改,因为Key模型的底层是二叉搜索树,其一旦被修改,整个树就有可能错误了,所以是不允许修改的。
set的拷贝构造赋值都是深拷贝,而且是一棵树,消耗比较大。
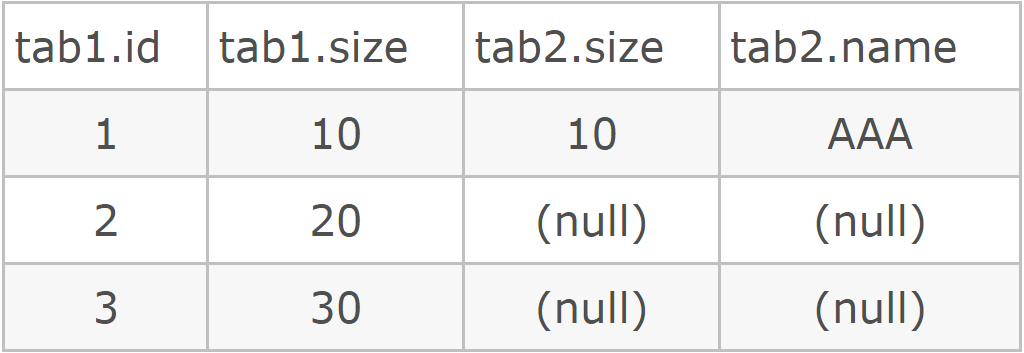
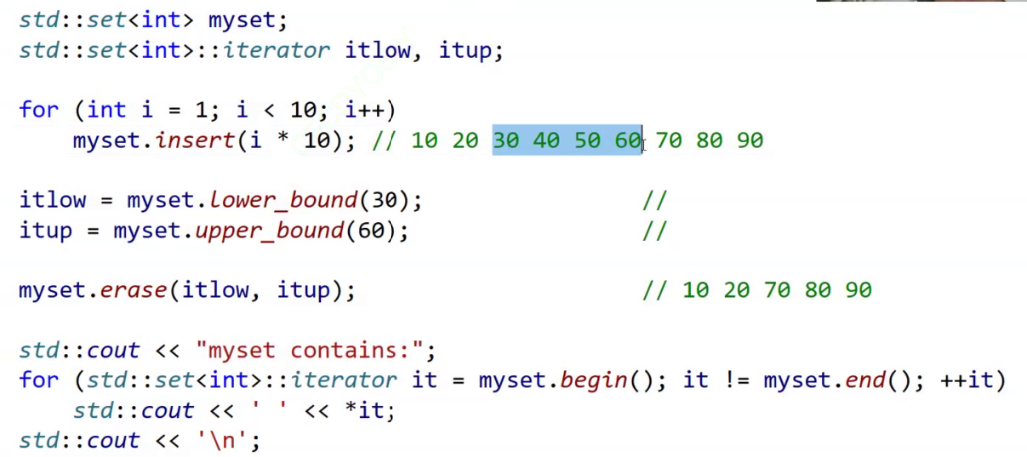
lower_bound、upper_bound
删除30-60
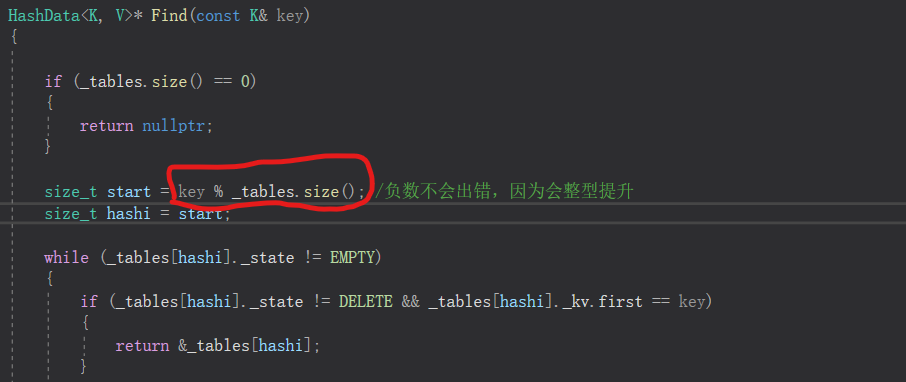
itlow = lower_bound(30);//返回大于等于30这个的值的位置//如果给35,则是40到60
itup = upper_bound(60);//返回大于60这个的值的位置,这里返回的是70//如果给55,返回的是60的位置,但是因为是左闭右开,所以60并没有被删掉
//10 20 30 40 50 60 70 80 90
set.erase(itlow, itup);//删除30到70所括住的区间[30, 70)
equal_range
x <= val < y(左闭右开)

map

map底层存储的结构是pair,pair是一个模板的键值对。map的底层是一棵树
pair的原型大致为
这是SGI-STL原码中对于键值对的定义

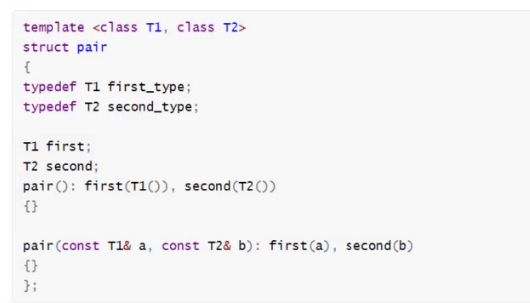


这里能不能用auto推导?不能,它推不出来
因为其插入时,只看key,val相不相同无所谓,但是map不支持冗余,所以只要key有了,就不支持再插入了。

其实也不用typedef pair
 我们可以用make_pair。前面的都是调用构造。而make_pair是一个函数模板,它的实现方式大致如下,它的优势就是自动推导,不需要我们显式地写模板参数了。make_pair是构造一个匿名pair然后返回
我们可以用make_pair。前面的都是调用构造。而make_pair是一个函数模板,它的实现方式大致如下,它的优势就是自动推导,不需要我们显式地写模板参数了。make_pair是构造一个匿名pair然后返回

一般被定义成inline

有时候有些头文件我们每包含,但是我们仍能使用的原因:
它们被其他头文件包含了。
map的遍历
void test_map1() {map<string, string> dict;pair <string, string> kv1("hello","你好");dict.insert(kv1);dict.insert(make_pair("sort", "排序"));dict.insert(make_pair("push", "插入"));dict.insert(make_pair("pop","删除"));//dict.insert(make_pair("hello", "hi"));//优势:自动推导类型,不用显式地写模板参数//map的遍历map<string, string>::iterator it = dict.begin();//auto it = dict.begin();while (it != dict.end()){cout << it->first << it->second << endl;//cout << (*it).first <<(*it).second << endl;//pair不支持流插入,它没有重载流插入。//我们用kv键值对++it;}cout << endl;for (const auto& kv : dict)//范围for是依次取数据赋值给kv,其实就是迭代器*it给kv,但是这样拷贝代价太大了,所以尽量把引用加上减少拷贝。{cout << kv.first << ":" << kv.second << endl;}cout << endl;}
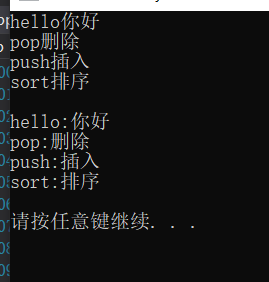

map和set的迭代器都是双向迭代器,也就是可以正向和反向遍历。
第三十节00:11:00-00:25:00 将双箭头做特殊处理 只看了一遍,没笔记,代码只写了一点
map中的[]
它去容器里找k对应的元素,然后返回对应的value。如果这个key没有被匹配到,它会插入一个新的元素,这个元素就用这个key,然后返回它的映射类型,如果它没有对应的映射类型,value用它的默认构造(default constructor)
即:
1.map中有这个key,返回value的引用(可用于查找,修改value)
2.map中没有这个key,会插入一个新元素,该元素为pair(key, V()); ,返回value(这里的value就是pair里自动创建的value)的引用(可用于插入,修改) V()是value类型的匿名对象。这个value是一个缺省值,该value如果是int类型,则其缺省值为0,若为string,则其为"",若为指针,则其为nullptr
[]的底层是这样实现的
map中的insert
上面的value_type实际上就是pair<K, V> val;
返回的不是true和false,而是pair
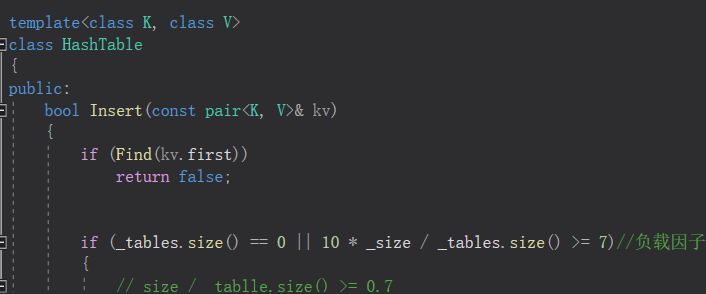
insert一个值,如果已经有这个值了,就不插入,bool就是false。如果没有,那就插入,bool是true
再讲解:
返回一个pair,pair的first被设置为迭代器,这个迭代器指向新插入的元素或者是跟这个key相等的元素,second是bool,如果插入成功,返回true。如果插入失败(即有key与它相等),则返回false。
即
插入时只看key。
1.key已经在map中,返回pair<key_iterator, false>//返回新插入元素的迭代器或与这个值相等的元素的迭代器;如果与key相等的元素已经存在,返回false(即已存在且相等的话,返回false)
2.key不在map中,返回pair(new_key_iterator, true);
第三十节1:06:30-1:15:00模拟实现[]
insert返回pair就是为[]准备的。
multimap为什么没有[]呢?
因为它允许键值冗余了,例如我们要返回苹果,我们应该返回哪次苹果来时的value呢?multi也不能用之前的代码帮我们统计次数了,因为它可以多次插入一样的值。
multimap也是看key,但是不管key有没有出现过,它都是插入,value相不相同无所谓

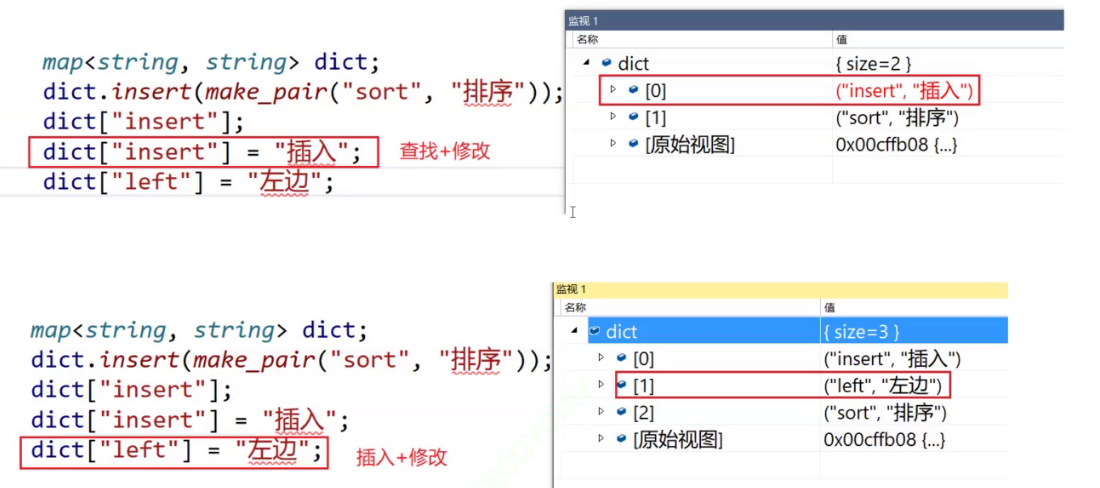


两个题:第三十节1:38:40-2:58:00
unordered_map、unordered_set
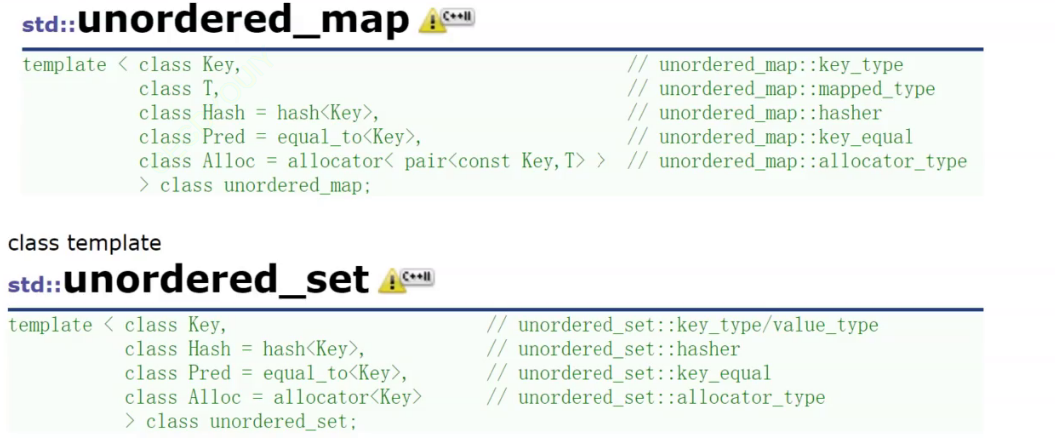
map/set与unordered系列的区别
1.map和set遍历是有序的,该类为无序
2.unordered系列只有单向迭代器,map和set是双向迭代器
数据越多,unordered系列效率更高,但是它的插入稍微差一点,因为它插入时要扩容,扩容的代价有点大
unordered系列的优点:
在处理大量数据时,其增删查改效率更优,尤其是查找。
当我们遇到这种情况时(一个不能被运算的类型需要运算)。
unordered_map里有一个参数帮助我们解决这种情况。hash<Key>
hash<Key>是一个仿函数,
所以要在这里添加一个Hash的仿函数