面试问题:
- 你只要用缓存,就可能会涉及到redis缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
- 双写一致性,你先动缓存redis还是数据库mysql哪一个?why?
- 延时双删你做过吗?会有哪些问题?
- 有这么一种情况,微服务查询redis无数据mysql有数据,为保证数据双写一致性回写redis你需要注意什么?双检加锁策略你了解过吗?如何尽量避免缓存击穿?
- redis和mysql双写100%会出纰漏,做不到强一致性,你如何保证最终一致性?

谈谈缓存双写一致性的理解
如果redis中有数据:需要和数据库中的值相同。
如果redis中无数据:数据库中的值要是最新值,且准备回写redis。
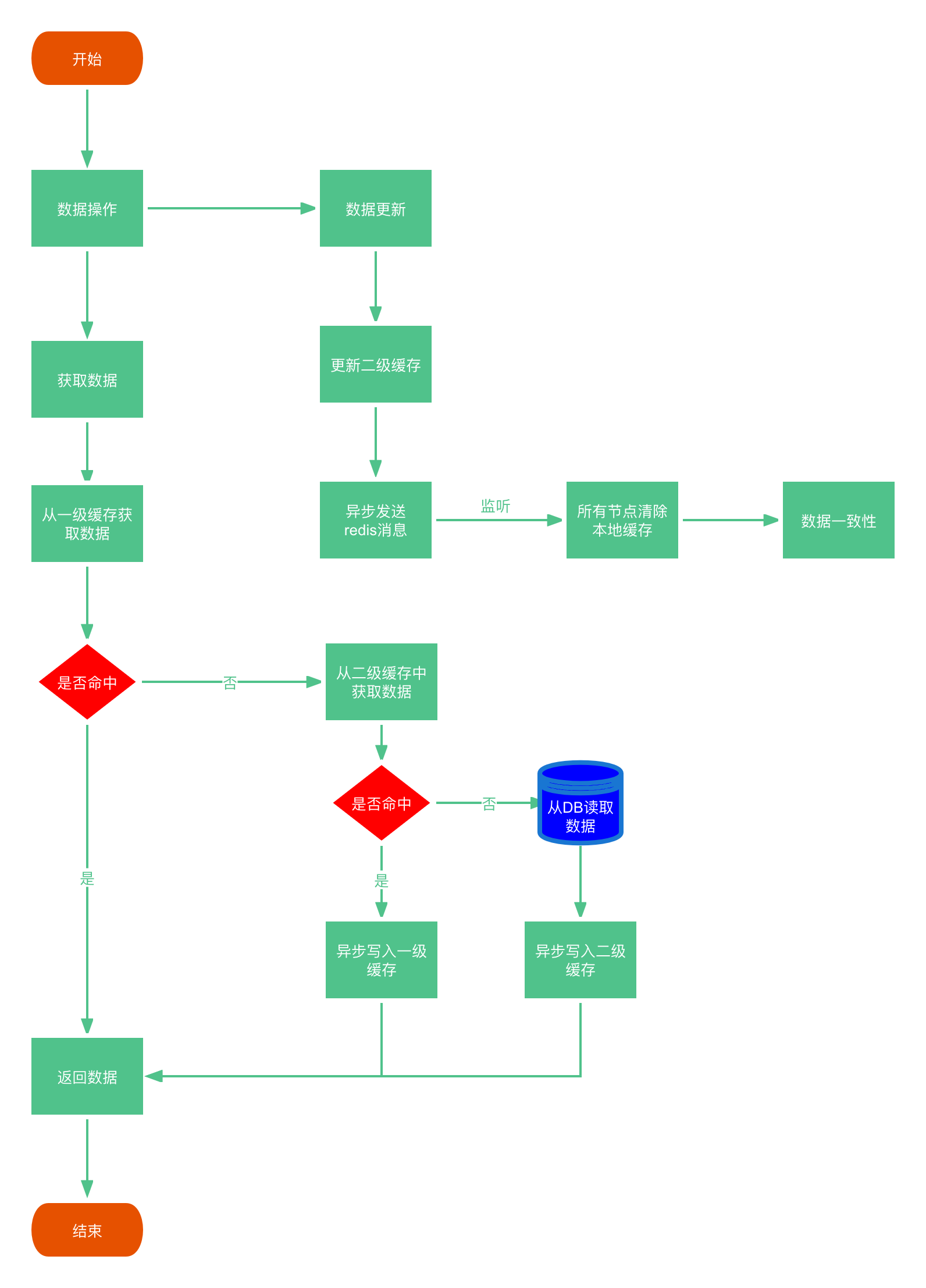
缓存按照操作来分,细分2种:只读缓存和读写缓存。
读写缓存分为同步直写策略和异步缓写策略。
同步直写策略:写数据库后也同步写redis缓存,缓存和数据库中的数据一致;对于读写缓存来说,要想保证缓存和数据库中的数据一致,就要采用同步直写策略。
异步缓写策略:正常业务运行中,mysq数据变动了,但是可以在业务上容许出现一定时间后才作用于redis,比如仓库、物流系统;异常情况出现了,不得不将失败的动作重新修补,有可能需要借助kafka或者RabbitMQ等消息中间件,实现重试重写。
一图代码你如何写

问题,上面业务逻辑你用java代码如何写?
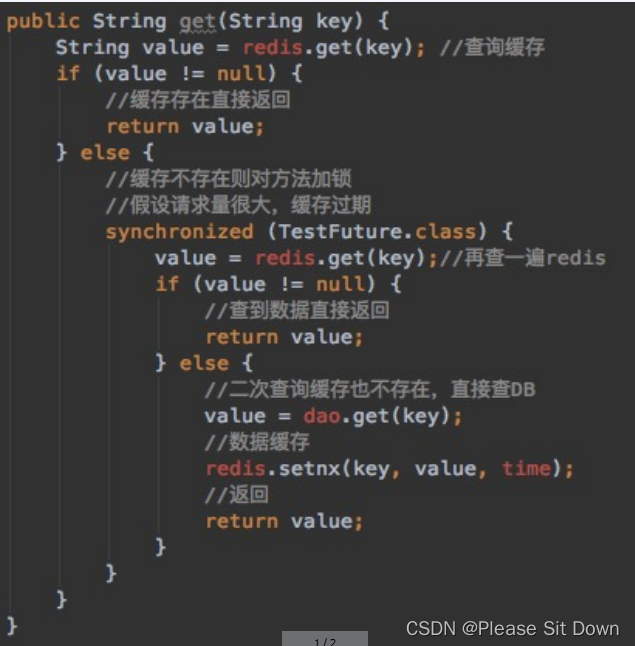
答案:采用双检加锁策略。
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。
后面的线程进来发现已经有缓存了,就直接走缓存。
伪代码:
案例代码:
package com.atguigu.redis.service;import com.atguigu.redis.entities.User;
import com.atguigu.redis.mapper.UserMapper;
import io.swagger.models.auth.In;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.stereotype.Service;
import org.springframework.web.bind.annotation.PathVariable;import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;@Service
@Slf4j
public class UserService {public static final String CACHE_KEY_USER = "user:";@Resourceprivate UserMapper userMapper;@Resourceprivate RedisTemplate redisTemplate;/*** 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行* @param id* @return*/public User findUserById(Integer id){User user = null;String key = CACHE_KEY_USER+id;//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysqluser = (User) redisTemplate.opsForValue().get(key);if(user == null){//2 redis里面无,继续查询mysqluser = userMapper.selectByPrimaryKey(id);if(user == null){//3.1 redis+mysql 都无数据//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redisreturn user;}else{//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率redisTemplate.opsForValue().set(key,user);}}return user;}/*** 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。* @param id* @return*/public User findUserById2(Integer id){User user = null;String key = CACHE_KEY_USER+id;//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,// 第1次查询redis,加锁前user = (User) redisTemplate.opsForValue().get(key);if(user == null) {//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysqlsynchronized (UserService.class){//第2次查询redis,加锁后user = (User) redisTemplate.opsForValue().get(key);//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)if (user == null) {//4 查询mysql拿数据(mysql默认有数据)user = userMapper.selectByPrimaryKey(id);if (user == null) {return null;}else{//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);}}}}return user;}}数据库和缓存一致性的几种更新策略
目的
达到最终一致性。给缓存设置过期时间,定期清理缓存并回写,是保证最终一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记,要以mysql的数据库写入库为准。
上述方案和后续落地案例是调研后的主流+成熟的做法,但是考虑到各个公司业务系统的差距,不是100%绝对正确,不保证绝对适配全部情况,请自行酌情选择打法,合适自己的最好。
可以停机情况
挂牌报错,凌晨升级,温馨提示,服务降级等;使用单线程操作,这样重量级的数据操作最好不要多线程。
不停机4种更新策略
先更新数据库,再更新缓存(不推荐)
异常问题1
1、先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
2、先更新mysql修改为99成功,然后更新redis。
3、此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100 。
4、上述发生,会让数据库里面和缓存redis里面数据不一致,读到redis脏数据。
异常问题2
【先更新数据库,再更新缓存】,A、B两个线程发起调用
【正常逻辑】
1 A update mysql 100
2 A update redis 100
3 B update mysql 80
4 B update redis 80
=============================
【异常逻辑】多线程环境下,A、B两个线程有快有慢,有前有后有并行
1 A update mysql 100
3 B update mysql 80
4 B update redis 80
2 A update redis 100
最终结果,mysql和redis数据不一致,o(╥﹏╥)o,
mysql80,redis100
先更新缓存,再更新数据库(不推荐)
业务上一般把mysql作为底单数据库,保证最后解释。
异常问题
【先更新缓存,再更新数据库】,A、B两个线程发起调用
【正常逻辑】
1 A update redis 100
2 A update mysql 100
3 B update redis 80
4 B update mysql 80
====================================
【异常逻辑】多线程环境下,A、B两个线程有快有慢有并行
A update redis 100
B update redis 80
B update mysql 80
A update mysql 100
结果:mysql100,redis80
先删除缓存,再更新数据库(不推荐)
异常问题
步骤分析1,先删除缓存,再更新数据库
A线程先成功删除了redis里面的数据,然后去更新mysql,此时mysql正在更新中,还没有结束。(比如网络延时)然后B突然出现要来读取缓存数据。
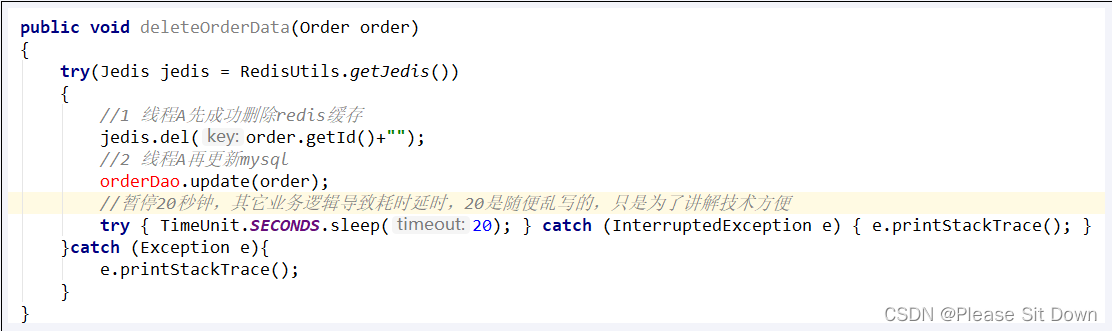
步骤分析2,先删除缓存,再更新数据库
此时redis里面的数据是空的,B线程来读取,先去读redis里数据(已经被A线程delete掉了),此处出来2个问题:
1、B从mysql获得了旧值:B线程发现redis里没有(缓存缺失)马上去mysql里面读取,从数据库里面读取来的是旧值。
2、B会把获得的旧值写回redis:获得旧值数据后返回前台并回写进redis(刚被A线程删除的旧数据有极大可能又被写回了)。
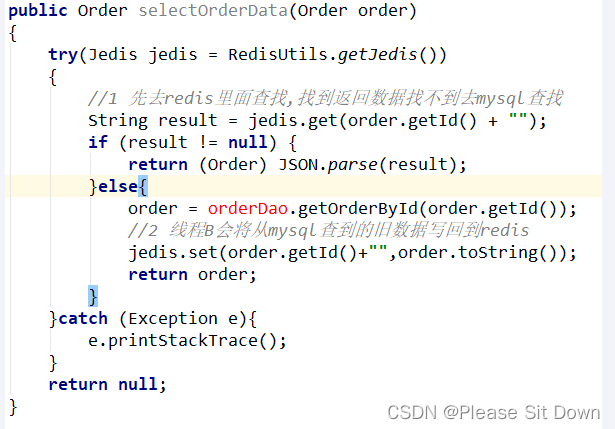
步骤分析3,先删除缓存,再更新数据库
A线程更新完mysql,发现redis里面的缓存是脏数据,A线程直接懵逼了,o(╥﹏╥)o。两个并发操作,一个是更新操作,另一个是查询操作,A删除缓存后,B查询操作没有命中缓存,B先把老数据读出来后放到缓存中,然后A更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
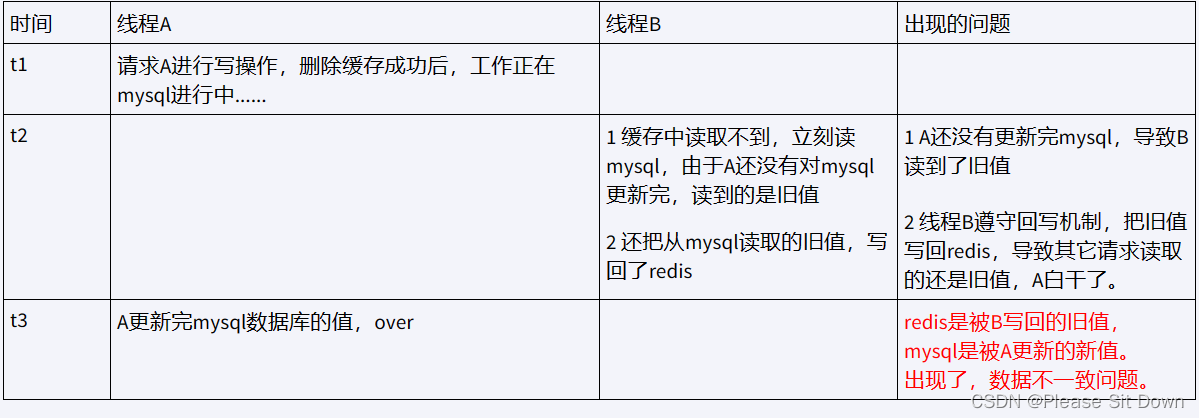
上面3步骤串讲梳理(总结流程)
- (1)请求A进行写操作,删除redis缓存后,工作正在进行中,更新mysql......A还么有彻底更新完mysql,还没commit
- (2)请求B开工查询,查询redis发现缓存不存在(被A从redis中删除了)
- (3)请求B继续,去数据库查询得到了mysql中的旧值(A还没有更新完)
- (4)请求B将旧值写回redis缓存
- (5)请求A将新值写入mysql数据库
上述情况就会导致不一致的情形出现。
解决方案:采用延时双删策略
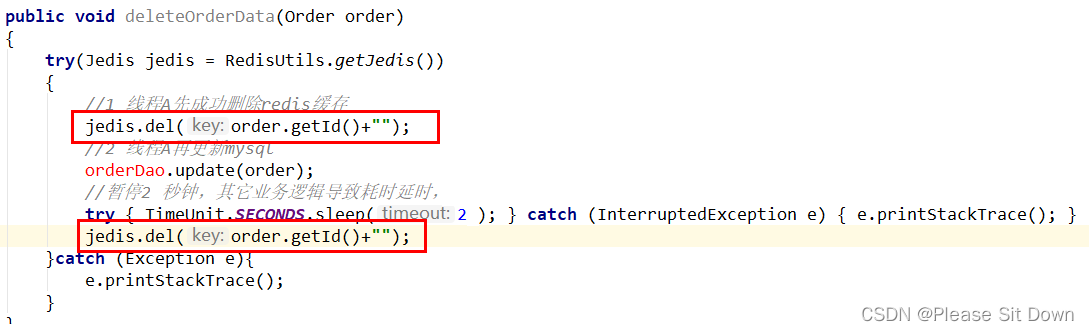
加上sleep的这段时间,就是为了让线程B能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程A再进行删除。所以,线程A sleep的时间,就需要大于线程B读取数据再写入缓存的时间。这样一来,其它线程读取数据时,会发现缓存缺失,所以会从数据库中读取最新值。因为这个方案会在第一次删除缓存值后,延迟一段时间再次进行删除,所以我们也把它叫做“延迟双删”。
双删方案面试题:
- 这个删除该休眠多久呢
线程A sleep的时间,就需要大于线程B读取数据再写入缓存的时间。这个时间怎么确定呢?
第一种方法:
在业务程序运行的时候,统计下线程读数据和写缓存的操作时间,自行评估自己的项目的读数据业务逻辑的耗时,以此为基础来进行估算。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上加百毫秒即可。
这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
第二种方法:
新启动一个后台监控程序,比如WatchDog监控程序,会加时。
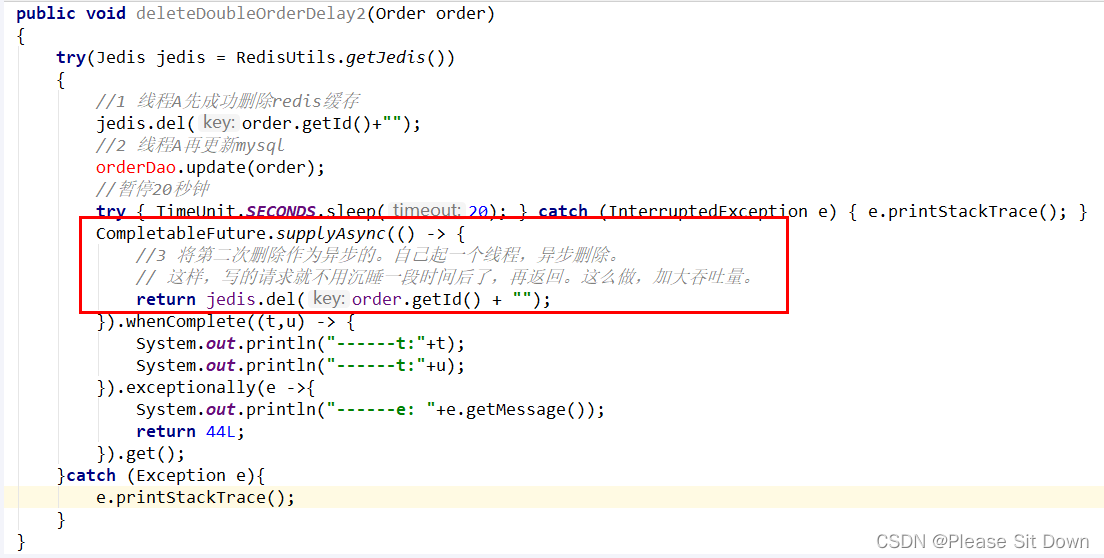
- 这种同步淘汰策略,吞吐量降低怎么办?
采用异步方式删除。
- 看门狗WatchDogi源码分析
先更新数据库,再删除缓存(推荐)
异常问题:
先更新数据库,再删除缓存。

假如缓存删除失败或者来不及,导致请求再次访问redis时缓存命中,读取到的是缓存旧值。
大厂业务指导思想
微软云:Cache-Aside pattern - Azure Architecture Center | Microsoft Learn
阿里巴巴canal思想:上述的订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。
解决方案
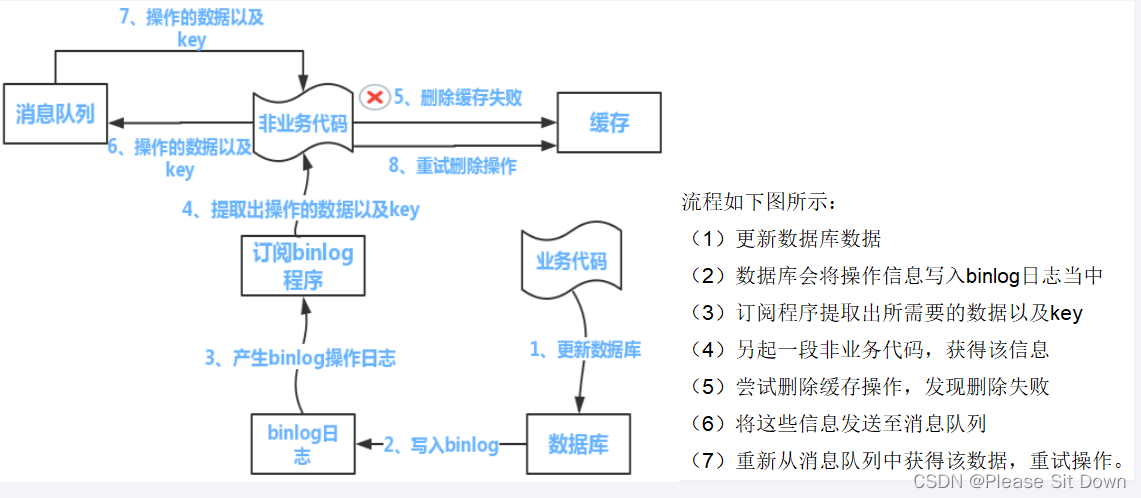
- 可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitMQ等)。
- 当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
- 如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试
- 如果重试超过的一定次数后还是没有成功,我们就需要向业务层发送报错信息了,通知运维人员。
类似经典的分布式事务问题,只有一个权威答案:最终一致性。
例如:
流量充值,先下发短信实际充值可能滞后5分钟,可以接受
电商发货,短信下发但是物流明天见
如何选择
在大多数业务场景下, 建议(仅代表我个人,不权威)优先使用先更新数据库,再删除缓存的方案(先更库→后删存)。
理由如下:
1、先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力导致打满mysql。
2、如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
多补充一句:如果使用先更新数据库,再删除缓存的方案。
如果业务层要求必须读取一致性的数据,那么我们就需要在更新数据库时,先在Redis缓存客户端暂停并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性,这是理论可以达到的效果,但实际,不推荐,因为真实生产环境中,分布式下很难做到实时一致性,一般都是最终一致性,请大家参考。

Redis与MySQL数据双写一致性落地案例

Canal数据同步
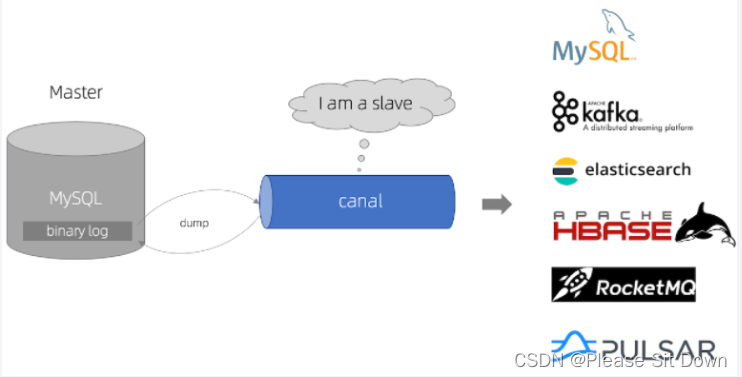
是什么
官网:https://github.com/alibaba/canal/wiki
canal [kə'næl],中文翻译为 水道/管道/沟渠/运河,主要用途是用于 MySQL 数据库增量日志数据的订阅、消费和解析,是阿里巴巴开发并开源的,采用Java语言开发;
历史背景是早期阿里巴巴因为杭州和美国双机房部署,存在跨机房数据同步的业务需求,实现方式主要是基于业务 trigger(触发器) 获取增量变更。从2010年开始,阿里巴巴逐步尝试采用解析数据库日志获取增量变更进行同步,由此衍生出了canal项目;
一句话:canal译意为水道/管道/沟渠,主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费。
能干嘛
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护拆分异构索引、倒排索引等)
- 业务cache刷新
- 带业务逻辑的增量数据处理
去哪下
地址:https://github.com/alibaba/canal/releases/tag/canal-1.1.6
MySQL主从复制工作原理
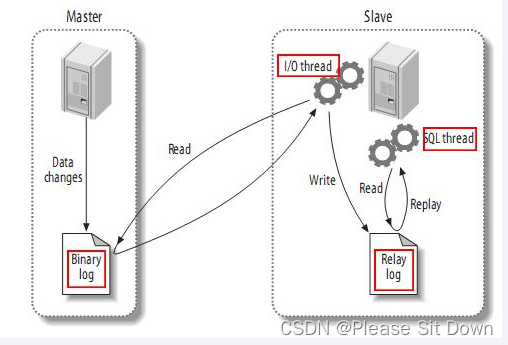
MySQL的主从复制将经过如下步骤:
1、当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
2、salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,
如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
3、同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志;
4、slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
5、salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
6、最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒;
canal工作原理

mysql-canal-redis双写一致性实战
java案例,来源出处:ClientExample · alibaba/canal Wiki · GitHub
mysql配置
1、查看mysql版本
命令:select version();
2、当前的主机二进制日志
命令:show master status;
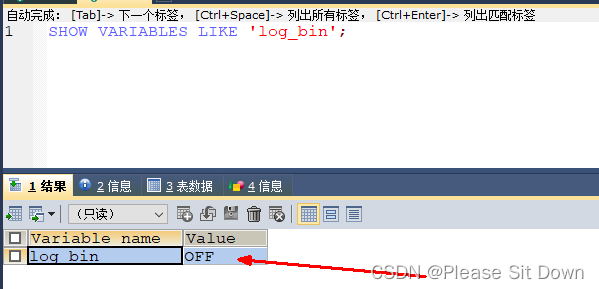
3、查看日志文件是否开启
命令:show variables like 'log_bin';(默认关闭)
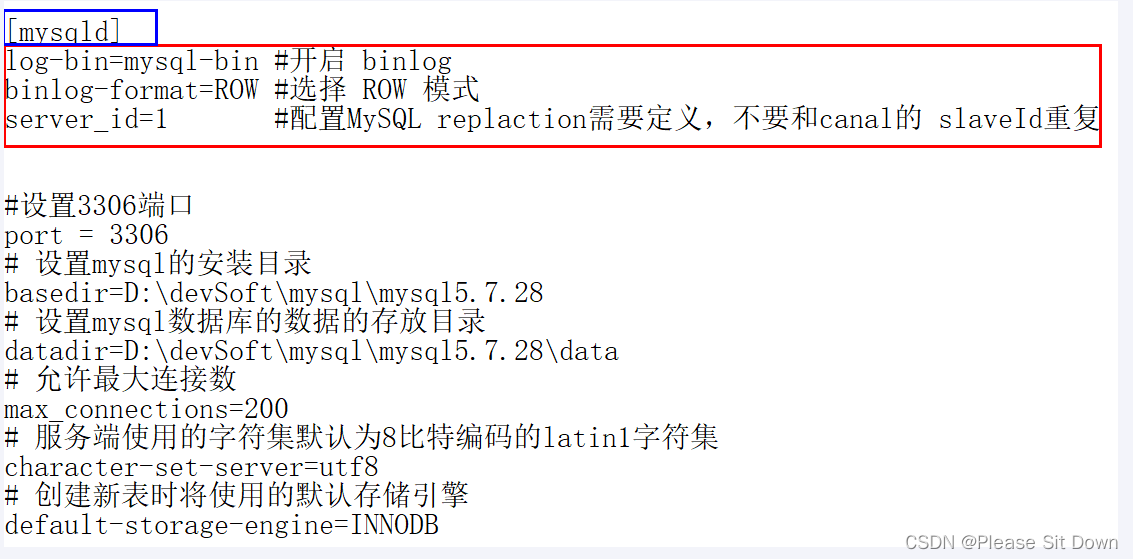
4、开启MySQL的binlog写入功能
打开MySQL安装根目录,修改my.ini文件
log-bin=mysql-bin #开启 binlog
binlog-format=ROW #选择 ROW 模式
server_id=1 #配置MySQL replaction需要定义,不要和canal的 slaveId重复
ROW模式:除了记录sql语句之外,还会记录每个字段的变化情况,能够清楚的记录每行数据的变化历史,但会占用较多的空间。
STATEMENT模式:只记录了sql语句,但是没有记录上下文信息,在进行数据恢复的时候可能会导致数据的丢失情况;
MIX模式:比较灵活的记录,理论上说当遇到了表结构变更的时候,就会记录为statement模式。当遇到了数据更新或者删除情况下就会变为row模式;
5、重启mysql
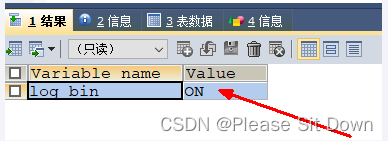
6、再次查看SHOW VARIABLES LIKE 'log_bin';
命令:show variables like 'log_bin';
7、授权canal连接MySQL账号
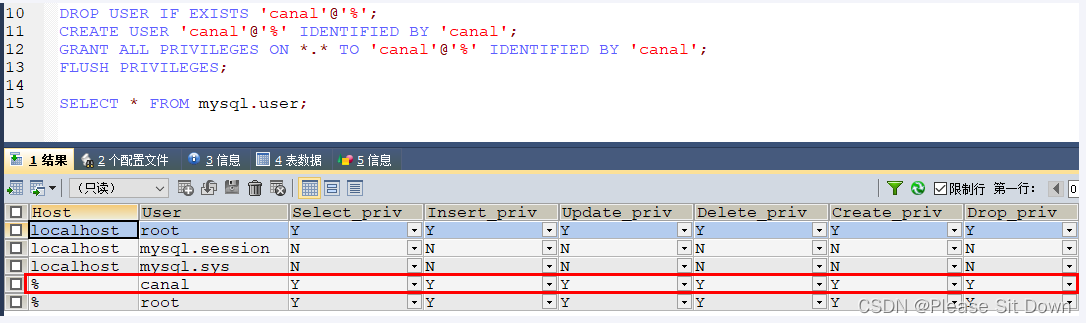
mysql默认的用户在mysql库的user表里
命令:select * from mysql.`user`

默认没有canal账户,此处新建+授权
DROP USER IF EXISTS 'canal'@'%';
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal';
FLUSH PRIVILEGES;
SELECT * FROM mysql.user;
canal服务端
1、下载
网址:https://github.com/alibaba/canal/releases/tag/canal-1.1.6
下载Linux版本:canal.deployer-1.1.6.tar.gz

注意发布时间+版本,2022.8.11后发布的才用
2、解压
解压后整体放入/mycanal路径下
3、配置
修改/mycanal/conf/example路径下instance.properties文件

换成自己的mysql主机master的IP地址
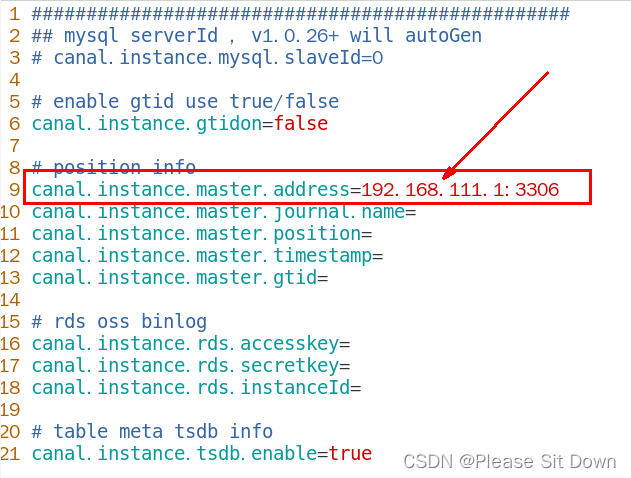
换成自己的在mysq新建的canal账户

4、启动
/opt/mycanal/bin路径下执行:./startup.sh
5、查看canal是否启动成功
查看server日志

查看样例example的日志
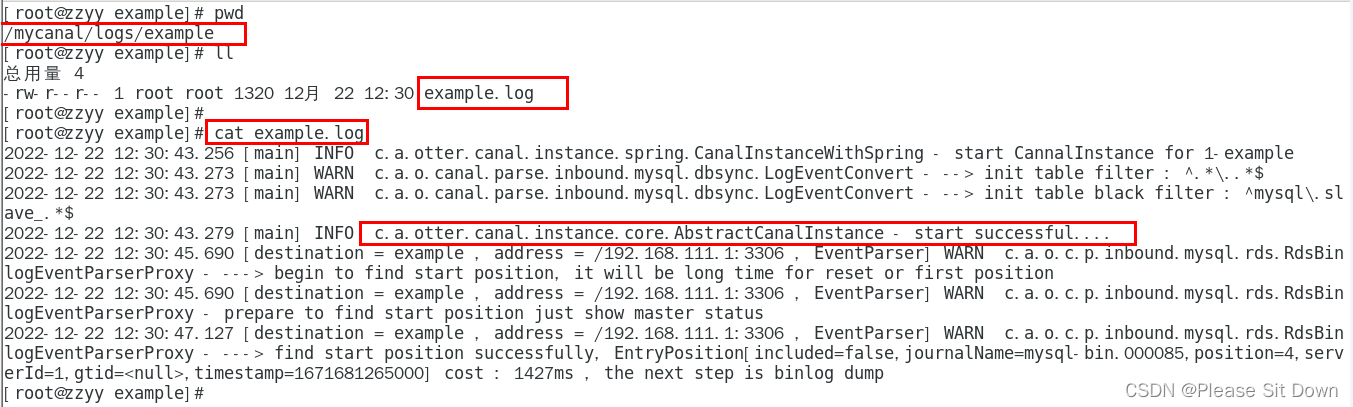
canal客户端(Java编写业务程序)
1、随便选个数据库,以你自己为主,本例bigdata,按照下面建表
CREATE TABLE `t_user` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`userName` varchar(100) NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;2、pom.xml
<!--canal-->
<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.0</version>
</dependency>3、yaml文件
# ========================alibaba.druid=====================
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.druid.test-while-idle=false4、RedisUtils.java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;public class RedisUtils{public static final String REDIS_IP_ADDR = "192.168.111.185";public static final String REDIS_pwd = "111111";public static JedisPool jedisPool;static {JedisPoolConfig jedisPoolConfig=new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPool=new JedisPool(jedisPoolConfig,REDIS_IP_ADDR,6379,10000,REDIS_pwd);}public static Jedis getJedis() throws Exception {if(null!=jedisPool){return jedisPool.getResource();}throw new Exception("Jedispool is not ok");}}
5、RedisCanalClientExample.java
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.atguigu.canal.util.RedisUtils;
import redis.clients.jedis.Jedis;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.TimeUnit;public class RedisCanalClientExample{public static final Integer _60SECONDS = 60;public static final String REDIS_IP_ADDR = "192.168.111.185";private static void redisInsert(List<Column> columns) {JSONObject jsonObject = new JSONObject();for (Column column : columns) {System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());jsonObject.put(column.getName(),column.getValue());}if(columns.size() > 0) {try(Jedis jedis = RedisUtils.getJedis()){jedis.set(columns.get(0).getValue(),jsonObject.toJSONString());}catch (Exception e){e.printStackTrace();}}}private static void redisDelete(List<Column> columns) {JSONObject jsonObject = new JSONObject();for (Column column : columns){jsonObject.put(column.getName(),column.getValue());}if(columns.size() > 0){try(Jedis jedis = RedisUtils.getJedis()){jedis.del(columns.get(0).getValue());}catch (Exception e){e.printStackTrace();}}}private static void redisUpdate(List<Column> columns){JSONObject jsonObject = new JSONObject();for (Column column : columns){System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());jsonObject.put(column.getName(),column.getValue());}if(columns.size() > 0){try(Jedis jedis = RedisUtils.getJedis()){jedis.set(columns.get(0).getValue(),jsonObject.toJSONString());System.out.println("---------update after: "+jedis.get(columns.get(0).getValue()));}catch (Exception e){e.printStackTrace();}}}public static void printEntry(List<Entry> entrys) {for (Entry entry : entrys) {if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {continue;}RowChange rowChage = null;try {//获取变更的row数据rowChage = RowChange.parseFrom(entry.getStoreValue());} catch (Exception e) {throw new RuntimeException("ERROR ## parser of eromanga-event has an error,data:" + entry.toString(),e);}//获取变动类型EventType eventType = rowChage.getEventType();System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));for (RowData rowData : rowChage.getRowDatasList()) {if (eventType == EventType.INSERT) {redisInsert(rowData.getAfterColumnsList());} else if (eventType == EventType.DELETE) {redisDelete(rowData.getBeforeColumnsList());} else {//EventType.UPDATEredisUpdate(rowData.getAfterColumnsList());}}}}public static void main(String[] args){System.out.println("---------O(∩_∩)O哈哈~ initCanal() main方法-----------");//=================================// 创建链接canal服务端CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(REDIS_IP_ADDR,11111), "example", "", "");int batchSize = 1000;//空闲空转计数器int emptyCount = 0;System.out.println("---------------------canal init OK,开始监听mysql变化------");try {connector.connect();//connector.subscribe(".*\\..*");connector.subscribe("bigdata.t_user");connector.rollback();int totalEmptyCount = 10 * _60SECONDS;while (emptyCount < totalEmptyCount) {System.out.println("我是canal,每秒一次正在监听:"+ UUID.randomUUID().toString());Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {emptyCount++;try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }} else {//计数器重新置零emptyCount = 0;printEntry(message.getEntries());}connector.ack(batchId); // 提交确认// connector.rollback(batchId); // 处理失败, 回滚数据}System.out.println("已经监听了"+totalEmptyCount+"秒,无任何消息,请重启重试......");} finally {connector.disconnect();}}
}6、题外话
java程序下connector.subscribe配置的过滤正则
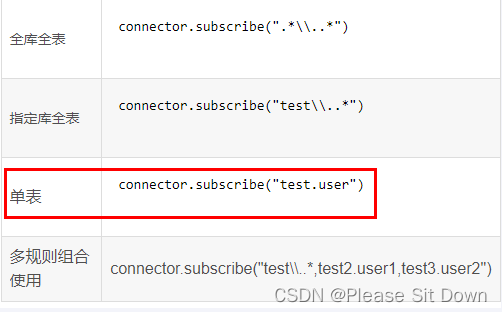
关闭资源代码简写:ty-with-resources释放资源
try(...){
...
}cache(){
...
}finally{
...
}