你相信我们对大模型也存在「迷信权威」吗?
ChatGPT 的 GPT-4 名声在外,我们就不自觉地更相信它,优先使用它。但我用 ChatALL 比较 AI 大模型们这么久,得到的结论是:
ChatGPT GPT-4 在大多数情况下确实是最强,但综合费用、访问难度、封号风险等条件,它就不是了。而大多数人在用的 ChatGPT 3.5,就更不是了。
那么最强的是谁呢?Bing Chat!先列举几个客观事实,再做主观分析。
| ChatGPT 3.5 | ChatGPT 4 | Bing Chat | |
|---|---|---|---|
| 费用 | 免费 | 每月 20 美元 | 免费 |
| 注册 | 国外手机号 | 国外手机号 | 任意邮箱 |
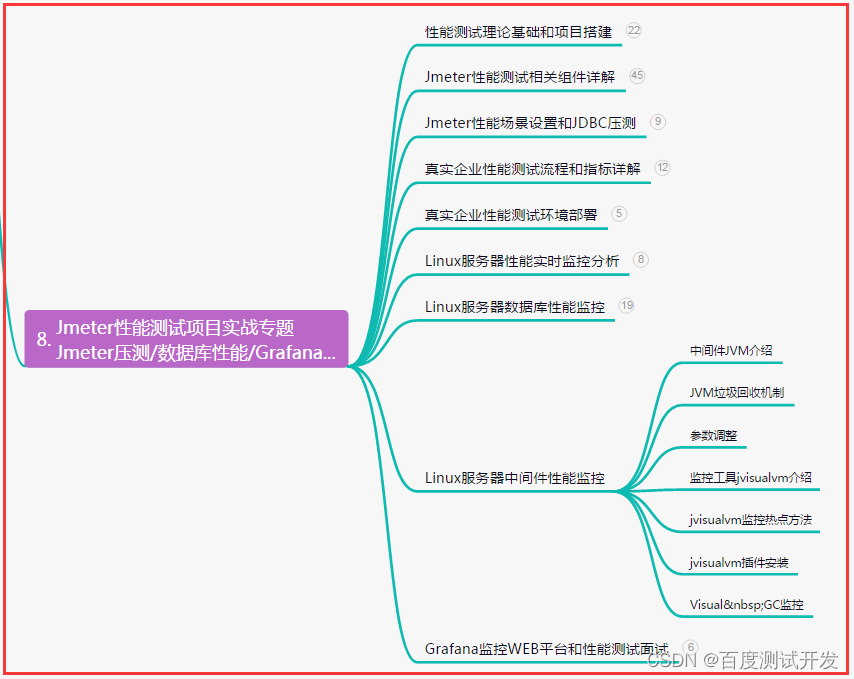
| 封 IP | 多 | 多 | 少 |
| 封帐号 | 有 | 有 | 无 |
| 浏览器兼容 | 好 | 好 | 只 Edge |
从上表可以看出,除了浏览器兼容这一项以外,都是 Bing Chat 更好。
下面再主观分析下模型的效果,毕竟这个是王道。
先透露一个小道消息。据说,Bing Chat 比 ChatGPT 更早使用了 GPT-4 模型。甚至可能从第一天就是 GPT-4。但为什么没有人说 Bing Chat 比当时的 ChatGPT 3.5 更强?大概就是明星光环导致的吧。
Bing Chat 的三个风格:创造力、平衡和精确,从一开始时就不是同一个模型设了不同的 temperature 那么简单。
起初,创造力的模型是 h3imaginative,平衡是 harmonyv3,精确是 h3precise。从命名看,平衡就很独特。后来不知道某一天「平衡」变成了 galileo(伽利略),更独特了。
用 chatall.ai 同时发 prompt 给它们,能明显感觉到「平衡」的生成速度更快。这也说明基础模型和另两个大有不同。可能是 GPT-3.5,也可能是 GPT-4 最新的蒸馏调优版(就像现在的 3.5 比最早的 3.5 快很多一样)。后者的可能性更大。
也就是说,Bing Chat 就是免费的 GPT-4 了,何必还费劲去鼓捣 ChatGPT 呢?
如果以上分析还不够说服力,那么我们来看客观数据。
下面是 chatall.ai 五月份的数据统计:
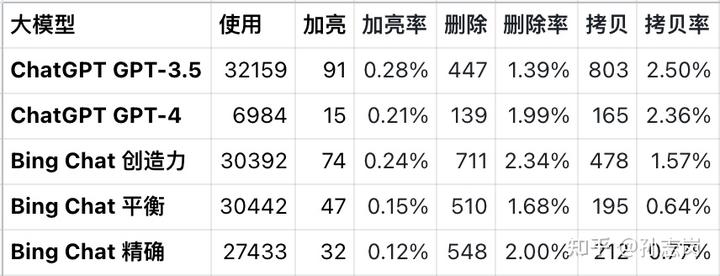
解释下数据:
- 发送、加亮、删除和拷贝四列是用户对大模型做对应操作的次数,「率」就顾名思义了
- 「加亮」是突出显示,表示这个结果好。但因为 ChatALL 现在长期保存数据的能力还不够,这个操作的意义不大,不是很能说明问题
- 「删除」表示这条结果太差了,不想再看到了。但因为 ChatALL 这段时间在 Bing Chat 上出了不少 bug,很可能有大量出错信息被删除
- 「拷贝」表示这条结果我打包带走拿去用了,是另一种认可,且可能是最强的认可
坦率说,因为基数不够大,以及各种缺陷,这个数据只能参考。但考虑到 ChatGPT 的光环加持,Bing Chat 受 ChatALL bug 的负面影响,还是可以说明 Bing Chat 和 ChatGPT 4 效果上是伯仲之间的。
转载:https://zhuanlan.zhihu.com/p/633148476