一.安装
1.在小皮的设置界面检测3306端口,保障3306端口可用;

2、在小皮的首面界面,启动MySQL;

3、进行环境变量设置,找到MySQL的路径,进行复制;

4、在Windows的搜索栏内,输入“环境变量”,打开“系统环境变量”,进入系统属性界面。点击环境变量键,进入环境变量界面,在系统变量栏内找到Path,点击编辑。在编辑环境变量界面新建,复制3步骤的路径,确定。

5、在Windows的搜索栏内,输入cmd打开终端,输入命令:mysql -u root -p,再输入password为root
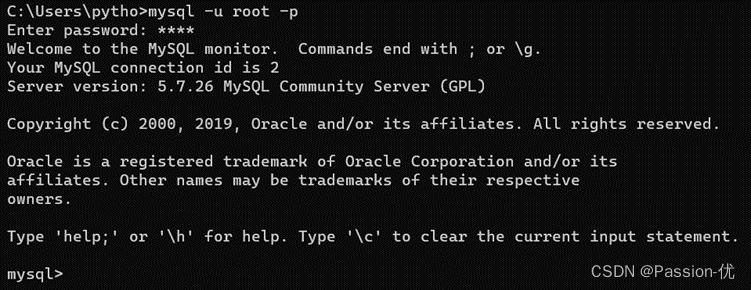
6、输入使用show databases; #重点强调database后面要加上s,表复数,多个表;最后是一定要加上“;”分号作为语句的结束表示。

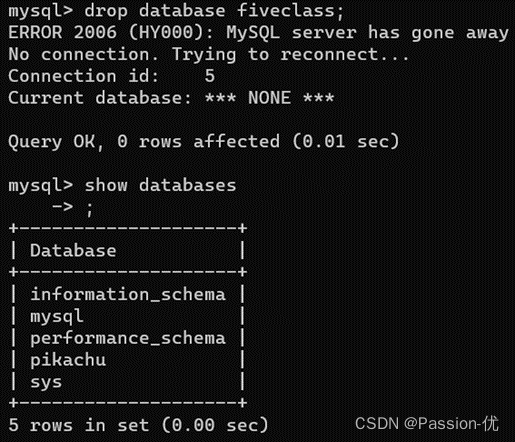
7、输入命令:create database fiveclass; #建立一个名为fiveclass的数据库。通过命令show databases; 查询已建立完成。注意开头不能以数字开头,中间不能带-,可以带_。

8、此为练习删除数据库,输入命令:drop database fiveclass; 通过命令show databases; 查询删除完成。
9、输入命令:use fiveclass; #表示使用fiveclass这个数据库。
输入命令:create table studentslist(
id int(6) primary key,
name varchar(20),
tel int(11),
sex varchar(2),
age int(3)); #表示建立studentslist这个表,表列名分别为id、name、tel、sex、age,其中id为键值。
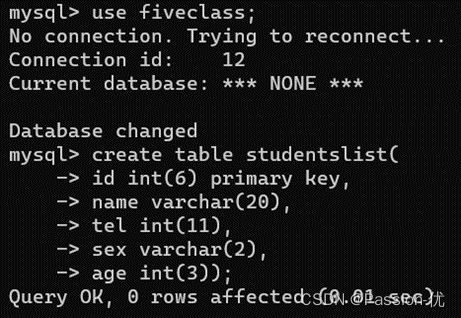
10、插入studentslist中各列的相关值。


11、显示表格数值情况,输入命令:select * from studentslist;
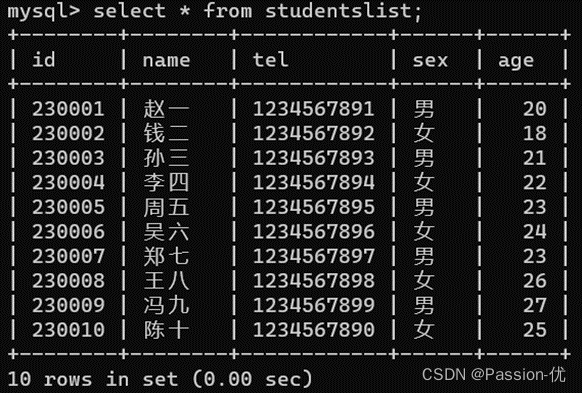
12、拓展:增加一列class,默认为5班。命令为alter table studentslist add class varchar(10) default ‘5班’;
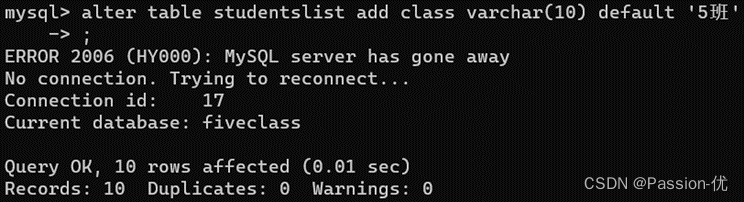

13、拓展:将sex 列由verchar(3)变更为verchar(4),命令:alter table studentslist modify column sex varchar(4);
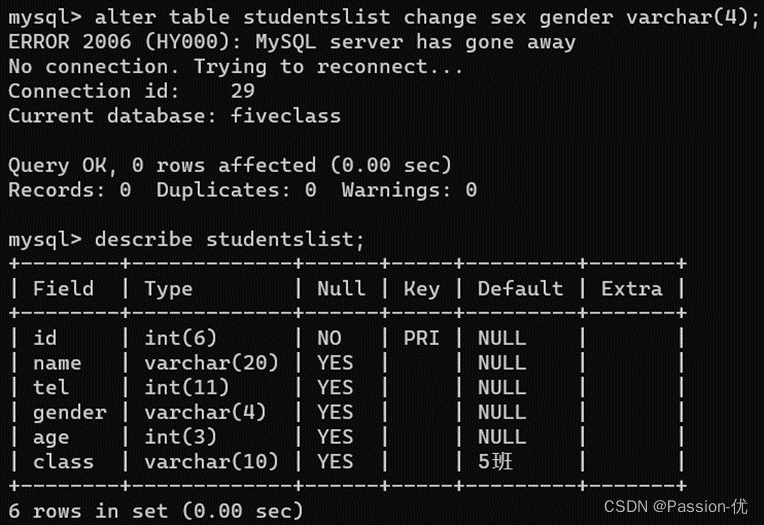
14、拓展:查询表数据类型情况,命令: describe studentslist;

15、拓展:在已有的sex列中增加默认值为男,命令:
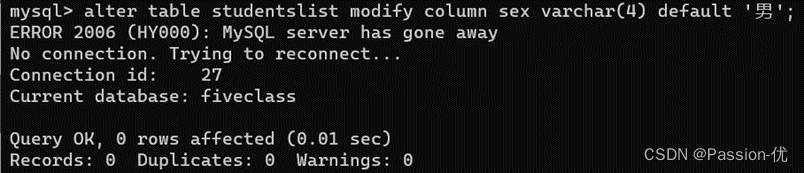

16、拓展:将列sex修改为gender,命令:alter table studentslist change sex gender varchar(4);
ALTER TABLE 语句
ALTER TABLE 语句用于在已有的表中添加、修改或删除列。
SQL ALTER TABLE 语法
如需在表中添加列,请使用下列语法:
ALTER TABLE table_name
ADD column_name datatype
要删除表中的列,请使用下列语法:
ALTER TABLE table_name
DROP COLUMN column_name
注释:某些数据库系统不允许这种在数据库表中删除列的方式 (DROP COLUMN column_name)。
要改变表中列的数据类型,请使用下列语法:
ALTER TABLE table_name
ALTER COLUMN column_name datatype
原始的表 (用在例子中的):
Persons 表:
Id LastName FirstName Address City
1 Adams John Oxford Street London
2 Bush George Fifth Avenue New York
3 Carter Thomas Changan Street Beijing
SQL ALTER TABLE 实例
现在,我们希望在表 "Persons" 中添加一个名为 "Birthday" 的新列。
我们使用下列 SQL 语句:
ALTER TABLE Persons
ADD Birthday date
请注意,新列 "Birthday" 的类型是 date,可以存放日期。数据类型规定列中可以存放的数据的类型。
新的 "Persons" 表类似这样:
Id LastName FirstName Address City Birthday
1 Adams John Oxford Street London
2 Bush George Fifth Avenue New York
3 Carter Thomas Changan Street Beijing
改变数据类型实例
现在我们希望改变 "Persons" 表中 "Birthday" 列的数据类型。
我们使用下列 SQL 语句:
ALTER TABLE Persons
ALTER COLUMN Birthday year
请注意,"Birthday" 列的数据类型是 year,可以存放 2 位或 4 位格式的年份。
DROP COLUMN 实例
接下来,我们删除 "Person" 表中的 "Birthday" 列:
ALTER TABLE Person
DROP COLUMN Birthday
Persons 表会成为这样:
Id LastName FirstName Address City
1 Adams John Oxford Street London
2 Bush George Fifth Avenue New York
3 Carter Thomas Changan Street Beijing
增加默认值
在MySQL中,我们可以使用ALTER TABLE命令来修改已有表的结构。其中包括增加默认值到某一列。下面是具体的操作步骤:
ALTER TABLE 表名 MODIFY COLUMN 列名 列类型 DEFAULT 默认值 ;
其中,ALTER TABLE命令用来修改表的结构,表名则是要修改的表的名字。MODIFY COLUMN后面的列名和列类型用来指明该列的数据类型。DEFAULT关键字用来指定默认值,最后是这个列的默认值。
修改列名
ALTER语句用于修改数据表的结构,而其中一个常用的操作就是修改列名。如下是ALTER语句的一个简单格式:
ALTER TABLE table_name CHANGE old_col_name new_col_name column_definition;
其中,'table_name'是要修改的数据表的名称;'old_col_name'是原有的列名;'new_col_name'是你想要修改成的新列名;'column_definition'是新列的定义。
二.Oracle表操作
1.创建表
create table tabname(
col1 type1 [not null] [primary key],
col2 type2 [not null],
..)
根据已有的表创建新表:
A:select*intotable_newfromtable_old(使用旧表创建新表)
B:create table tab_new as select col1,col2…
from tab_old definition only<仅适用于Oracle>
2.删除表
drop table tabname
3.重命名表
alter table 表名 rename to 新表名
eg:
alter table tablename rename to newtablename
4.增加字段
alter table表名add(字段名 字段类型 默认值 是否为空);
例:
alter table tablename add (ID int);
eg:
alter table tablename add (ID varchar2(30) default '空' not null);
5.修改字段
说明:
alter table表名modify(字段名 字段类型 默认值 是否为空);
eg:
alter table tablename modify (ID number(4));
6.重名字段
说明:
alter table 表名 rename column 列名 to 新列名
(其中:column是关键字)
eg:
alter table tablename rename column ID to newID;
7.删除字段
说明:alter table 表名 drop column 字段名;
eg:
alter table tablename drop column ID;
8.添加主键
alter table tabname add primary key(col)
9.删除主键
alter table tabname drop primary key(col)
10.创建索引
create [unique] index idxname on tabname(col….)
11.删除索引
drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
12.创建视图
create view viewname as select statement
13.删除视图
drop view viewname
三.Oracle操作数据
1.数据查询
select <列名> from <表名>
[where <查询条件表达试>]
[order by <排序的列名>[asc或desc]]
2.插入数据
insert into 表名 values(所有列的值);
insert into test values(1,'zhangsan',20);
insert into 表名(列) values(对应的值);
insert into test(id,name) values(2,'lisi');
3.更新数据
update 表 set 列=新的值 [where 条件] -->更新满足条件的记录
update test set name='zhangsan2' where name='zhangsan'
update 表 set 列=新的值 -->更新所有的数据
update test set age =20;
4.删除数据
● delete from表名where条件 -->删除满足条件的记录
Delete from test where id=1;
delete from test -->删除所有
commit;-->提交数据
rollback;-->回滚数据
● delete方式可以恢复删除的数据,但是提交了,就没办法了 delete删除的时候,会记录日志 -->删除会很慢很慢
● truncate table表名
删除所有数据,不会影响表结构,不会记录日志,数据不能恢复 -->删除很快
● drop table表名
删除所有数据,包括表结构一并删除,不会记录日志,数据不能恢复-->删除很快
5.数据复制
● 表数据复制
insert into table1 (select * from table2);
● 复制表结构
create table table1 select * from table2 where 1>1;
● 复制表结构和数据
create table table1 select * from table2;
● 复制指定字段
create table table1 as select id, name from table2 where 1>1;
四.数据库复制命令
不同的数据库语法不同(SQL Sever和Oracle为例),且复制包括目标表已存在和目标表不存在的情况,分别回答:
1.SQL Server中,如果目标表存在:
insert into 目标表 select * from 原表;
2.SQL Server中,如果目标表不存在:
Select * into 目标表 from 原表 #复制表结构和数据
Select * from 目标表 from 原表 where 1=0 #只复制表结构
3.Oracle中,如果目标表存在:
insert into 目标表 select * from 原表;
commit;
4.Oracle中,如果目标表不存在:
create table 目标表 as select * from 原表; #复制表结构和数据
create table 目标表 as select * from 原表 where 1=0; #只复制表结构
五.SQL Server 常用命令总结
1.数据记录筛选:
sql='select * from 数据表 where 字段名=字段值 order by 字段名 [desc]'
sql='select * from 数据表 where 字段名 like '%字段值%' order by 字段名 [desc]'
sql='select top 10 * from 数据表 where 字段名 order by 字段名 [desc]'
sql='select * from 数据表 where 字段名 in ('值1','值2','值3')'
sql='select * from 数据表 where 字段名 between 值1 and 值2'
2.更新数据记录:
sql='update 数据表 set 字段名=字段值 where 条件表达式'
sql='update 数据表 set 字段1=值1,字段2=值2 …… 字段n=值n where 条件表达式'
3.删除数据记录:
sql='delete from 数据表 where 条件表达式'
sql='delete from 数据表' (将数据表所有记录删除)
4.添加数据记录:
sql='insert into 数据表 (字段1,字段2,字段3 …) values (值1,值2,值3 …)'
sql='insert into 目标数据表 select * from 源数据表' (把源数据表的记录添加到目标数据表)
5.数据记录统计函数:
AVG
(字段名) 得出一个表格栏平均值
COUNT
(*|字段名) 对数据行数的统计或对某一栏有值的数据行数统计
MAX
(字段名) 取得一个表格栏最大的值
MIN
(字段名) 取得一个表格栏最小的值
SUM
(字段名) 把数据栏的值相加
引用以上函数的方法:
sp_helpdb 查看数据库
go use 数据库名
go select * from sysobjects where xtype='u'
查看数据库中有什么数据表
go sp_help 数据表名 查看数据表的结构
go sql='select sum(字段名) as 别名 from 数据表 where 条件表达式'
set rs=conn.excute(sql) #用 rs('别名') 获取统的计值,其它函数运用同上。
6.数据表的建立和删除:
CREATE TABLE
数据表名称(字段1 类型1(长度),字段2 类型2(长度) …… )
例:
CREATE TABLE tab01( name varchar (50),datetime default now())
DROP TABLE 数据表名称 (永久性删除一个数据表)
7.记录集对象的方法:
rs.movenext 将记录指针从当前的位置向下移一行
rs.moveprevious 将记录指针从当前的位置向上移一行
rs.movefirst 将记录指针移到数据表第一行
rs.movelast 将记录指针移到数据表最后一行
rs.absoluteposition=N 将记录指针移到数据表第N行
rs.absolutepage=N 将记录指针移到第N页的第一行
rs.pagesize=N 设置每页为N条记录
8.更改表格
ALTER TABLE table_name ADD COLUMN column_name DATATYPE
说明:增加一个栏位(没有删除某个栏位的语法。
ALTER TABLE table_name ADD PRIMARY KEY (column_name)
说明:更改表得的定义把某个栏位设为主键。
ALTER TABLE table_name DROP PRIMARY KEY
(column_name)
说明:把主键的定义删除。
9.建立索引
CREATE INDEX index_name ON table_name (column_name)
说明:对某个表格的栏位建立索引以增加查询时的速度。
10.删除
DROP
table_name
DROP
index_name
六.注意
p 精确值和 s 大小的十进位整数,精确值p是指全部有几个数(digits)大小值,s是指小数点後有几位数。如果没有特别指定,则系统会设为 p=5; s=0 。
float 32位元的实数。
double 64位元的实数。
char (n) n 长度的字串,n不能超过 254。
varchar (n) 长度不固定且其最大长度为 n 的字串,n不能超过 4000。
graphic(n) 和 char(n) 一样,不过其单位是两个字元
double -bytes, n不能超过127。这个形态是为了支援两个字元长度的字体,例如中文字。
vargraphic(n) 可变长度且其最大长度为 n 的双字元字串,n不能超过 2000。
date包含了 年份、月份、日期。
time包含了 小时、分钟、秒。
timestamp 包含了 年、月、日、时、分、秒、千分之一秒。
资料定义好之後接下来的就是资料的操作。资料的操作不外乎增加资料(insert)、查询资料(query)、更改资料(update) 、删除资料(delete)四种模式,以下分 别介绍他们的语法:
1、增加资料:
INSERT INTO table_name (column1,column2,...) valueS ( value1,value2, ...)
说明:
1.若没有指定
column 系统则会按表格内的栏位顺序填入资料。
2.栏位的资料形态和所填入的资料必须吻合。
3.table_name 也可以是景观 view_name。
INSERT INTO table_name (column1,column2,...)
SELECT columnx,columny,... FROM another_table
说明:也可以经过一个子查询(subquery)把别的表格的资料填入。
2、查询资料:
基本查询
SELECT column1,columns2,... FROM table_name
说明:把table_name 的特定栏位资料全部列出来
SELECT * FROM table_name WHERE column1 = xxx [ AND column2 > yyy] [ OR column3 <> zzz]
3、交叉连接
交叉连接不带
WHERE 子句,它返回被连接的两个表所有数据行的笛卡尔积,返回到结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。
例,titles表中有6类图书,而publishers表中有8家出版社,则下列交叉连接检索到的记录数将等于6*8=48行。
SELECT type,pub_name FROM titles CROSS JOIN publishers ORDER BY type UNION
运算符可以将两个或两个以上上SELECT语句的查询结果集合合并成一个结果集合显示,即执行联合查询。
UNION的语法格式为:
select_statement UNION [ ALL ] selectstatement [ UNION [ ALL ] selectstatement][…n]
其中selectstatement为待联合的SELECT查询语句。ALL选项表示将所有行合并到结果集合中。不指定该项时,被联合查询结果集合中的重复行将只保留一行。联合查询时,查询结果的列标题为第一个查询语句的列标题。因此,要定义列标题必须在第一个查询语句中定义。要对联合查询结果排序时,也必须使用第一查询语句中的列名、列标题或者列序号。
在使用UNION运算符时,应保证每个联合查询语句的选择列表中有相同数量的表达式,并且每个查询选择表达式应具有相同的数据类型,或是可以自动将它们转换为相同的数据类型。在自动转换时,对于数值类型,系统将低精度的数据类型转换为高精度的数据类型。
在包括多个查询的UNION语句中,其执行顺序是自左至右,使用括号可以改变这一执行顺序。例如:查询1 UNION (查询2 UNION 查询3)
INSERT语句
用户可以用INSERT语句将一行记录插入到指定的一个表中。例如,要将雇员John Smith的记录插入到本例的表中,可以使用如下语句:
INSERT INTO EMPLOYEES valueS ( 'Smith','John','1980-06-10','Los Angles',16,45000);
通过这样的INSERT语句,系统将试着将这些值填入到相应的列中。这些列按照我们创建表时定义的顺序排列。在本例中,第一个值“Smith”将填到第一个列LAST_NAME中;第二个值“John”将填到第二列FIRST_NAME中……以此类推。
我们说过系统会“试着”将值填入,除了执行规则之外它还要进行类型检查。如果类型不符(如将一个字符串填入到类型为数字的列中),系统将拒绝这一次操作并返回一个错误信息。
如果SQL拒绝了你所填入的一列值,语句中其他各列的值也不会填入。这是因为SQL提供对事务的支持。一次事务将数据库从一种一致性转移到另一种一致性。如果事务的某一部分失败,则整个事务都会失败,系统将会被恢复(或称之为回退)到此事务之前的状态。
回到原来的INSERT的例子,请注意所有的整形十进制数都不需要用单引号引起来,而字符串和日期类型的值都要用单引号来区别。为了增加可读性而在数字间插入逗号将会引起错误。记住,在SQL中逗号是元素的分隔符。
同样要注意输入文字值时要使用单引号。双引号用来封装限界标识符。
对于日期类型,我们必须使用SQL标准日期格式(yyyy-mm-dd)
--设置用户访问数据库的形式 Alter database TestAA set SINGLE_USER with rollback immediate --设置单用户访问数据库
Alter database TestAA set RESTRICTED_USER with rollback immediate
RESTRICTED_USER 只允许 db_owner 固定数据库角色成员以及 dbcreator 和 sysadmin 固定服务器角色成员连接到数据库,不过对连接数没有限制。在ALTER DATABASE语句的终止子句所指定的时间范围内,所有数据库连接都将被断开。在数据库转换到 RESTRICTED_USER 状态后,不合格用户所做的连接尝试将被拒绝。
Alter database TestAA set MULTI_USER with rollback immediate
--设置用户正常访问
--设置数据库恢复模式
sql 2008 不支持nolog 和 truncate_only 如果要截断日志的话,需要先把数据库搞成简单模型,然后在收缩日志,在改成完全模式。备份一次数据库。
Alter database set recovery {simple/ full /bulk_logged} dbcc shrinkfile( 'filename' ,10)
--导出数据到文本
--EXEC master..xp_cmdshell 'bcp 'Select cdoc_id,csubject from cmsdbquery..tbl_article' queryout c:\DT.txt -c -SXXXXX -Usa -PXXXXX'
--跟踪脚本需要打开的选项
set statistics io on
set statistics profile on
Set statistics time on
--释放过程高速缓存将导致重新编译某些部分
DBCC FREEPROCCACHE
--从缓冲池中删除所有清除缓冲区
不用关闭和重启服务器或者服务
DBCC DROPCLEANBUFFERS
--以报表形式显示有关过程高速缓存的信息
DBCC PROCCACHE
--显示指定表上的指定目标的当前分布统计信息
DBCC SHOW_STATISTICS ( table , target )
--从远程服务器打开数据库连接取数据
SELECT top 20 * FROM OPENDATASOURCE( 'SQLOLEDB' , 'Data Source=xxx.xxx.xx.x,port;User ID=sa;Password=xxxxxxx' ).[product].dbo.tableaa data source 好像不能有中括号,好多网友的opendatasource不能用就是这个原因
SELECT * FROM OpenDataSource ( 'Microsoft.Jet.OLEDB.4.0' , 'Data Source='c:\bbb.xls';User ID=;Password=;Extended properties=Excel 5.0' )...[sheet1$]
文本的查询
文件必须是,号分割文件
HDR=YES 的时候,第一行被认为是字段名
HDR=NO的时候,第一行被认为是数据
select * from OPENROWSET( 'MICROSOFT.JET.OLEDB.4.0' , 'Text;HDR=NO;DATABASE=C:\' --c:\是目录 ,aaa#txt) --文件名
BULK INSERT xxxx_trs.dbo.xxxx_day FROM ' F:\BI_DsssDayAddin_cms_IN.csv ' WITH ( FIELDTERMINATOR =' , ', ROWTERMINATOR =' \n ' )
--查看sql版本
SELECT SERVERPROPERTY(' productversion '),SERVERPROPERTY(' productlevel '),SERVERPROPERTY('edition ')
--初始化标识列
DBCC CHECKIDENT (ProductPicture, RESEED, 1)
--数据库2个比较常用的函数
DATABASEPROPERTY 返回数据库状态的值
select DATABASEPROPERTY(dbname, ' issingleuser ') 返回数据库是不是单用户模式
HAS_DBACCESS ( 'database_name' )返回信息,说明用户是否可以访问指定的数据库
--T终端用户的人
Query user 查询当前登录用户
LogOff sessionid 注销会话
Tsdiscon sessionid 断开某个会话的连接
命令行下需要先建立一个ipc$会话
net use \\10.168.0.21\c$ 'XX' /user:administrator
query user /server 10.168.0.21
tsdiscon 2 /server 10.168.0.21
创建与删除SQL约束或字段约束:SQL约束控制
1)禁止所有表约束的SQL
select 'alter table '+name+' nocheck constraint all ' from sysobjects where type=' U'
2)删除所有表数据的SQL
select 'TRUNCATE TABLE'+name from sysobjects where type='U'
3)恢复所有表约束的SQL
select 'alter table'+name+'check constraint all ' from sysobjects where type='U'
4)删除某字段的约束
declare @name varchar(100)
--DF为约束名称前缀
select @name=b.name from syscolumns a,sysobjects b where a.id=object_id('表名') and b.id=a.cdefault and a.name='字段名' and b.name like 'DF%'
--删除约束
alter table 表名 drop constraint @name
--为字段添加新默认值和约束
ALTER TABLE 表名 ADD CONSTRAINT @name DEFAULT (0) FOR [字段名]对字段约束进行更改
--删除约束
ALTER TABLE tablename
Drop CONSTRAINT 约束名
--修改表中已经存在的列的属性(不包括约束,但可以为主键或递增或唯一)
ALTER TABLE tablename
alter column 列名 int not null
--添加列的约束
ALTER TABLE tablename
ADD CONSTRAINT DF_tablename_列名 DEFAULT(0) FOR 列名
--添加范围约束
alter table tablename add check(性别 in ('M','F'))
创建一个库
CREATE DATABASE g2 ON PRIMARY ( NAME = 'g2', FILENAME = 'E:\benet\data1\g1.mdf' , SIZE = 307200KB , FILEGROWTH = 1024KB ) LOG ON ( NAME = 'g2_log', FILENAME = 'E:\benet\data1\g1_log.ldf' , SIZE = 1024KB , FILEGROWTH = 10%)
创建一个表
CREATE TABLE biao2(id int NOT NULL, xingming char(10) NOT NULL, xingbie float(53) NOT NULL, nianling int NOT NULL, chengji float(53) NULL )4、查询
select * from biao1 where chengji between 400 and 600
select * from biao1 where nianling like 55
select * from biao1 where nianling between 10 and 100
select * from biao1 where id = 5 insert into biao1 values (6 ,' 原迟',1 , 100 , 1542.22) update biao1 set chengji = chengji + 1000
select * from biao1 delete from biao1 where id = 1
select * from biao1
select * from biao1 排序 order by no asc update biao2 set zongji = shuxue + yuwen + huaxue where xingming = 'a' insert into biao1 values (7,'骨血松涛',1 , 700)
select * from biao1 where xingming like ' %血% '
select distinct xingbie from biao1 alter table biao1 drop column chengji 删除一列 alter table biao2 add liehao int
select * from biao1,biao2 where biao1.id=biao2.id 将表一和表二联系起来,建立主索引, 注意小数点的应用
select * from biao1 inner join biao2 on biao1.id=biao2.id 和上面的一样
查询时间
select * from biao2 where riqi between '1993-01-01 00:00:00.000' and '1994-6-29 00:00:00.000'
select xingming from biao2 where bumen ='xiaoshou' and xingbie ='na' delete from biao2 where xingming='jinpeng'
select id ,xingming into biao2_backup from biao2 where xingbie='na' 备份选择的数据 create view shitu as
select xingming ,riqi from biao2 where xingbie = 'na'
创建一个自己匹配的视图
视图相当于是一个符合你的目的的一个查询结果集。他不占用空间,方便你以后的查找.
多文件还原代码
ESTORE DATABASE [benet] FROM DISK = N'G:\bak\wz.bak' WITH FILE = 1, NORECOVERY, NOUNLOAD, REPLACE, STATS = 10 GO
RESTORE DATABASE [benet] FROM DISK = N'G:\bak\cy.bak' WITH FILE = 1, NOUNLOAD, REPLACE, STATS = 10 GO
恢复数据库 benet 来自文件 DISK = N'G:\bak\cy.bak' with 文件数1个,NORECOVERY 指定不发生回滚。从而使前滚按顺序在下一条语句中继续进行。
在这种情况下,还原顺序可还原其他备份,并执行前滚。REPLACE覆盖
A. 还原完整数据库
注意:
MyAdvWorks 数据库仅供举例说明。
以下示例还原完整数据库备份。
复制代码
RESTORE DATABASE MyAdvWorks FROM MyAdvWorks_1注意:
对于使用完全恢复模式或大容量日志恢复模式的数据库,在大多数情况下,SQL Server 2005 都要求您在还原数据库前备份日志尾部。有关详细信息,请参阅尾日志备份。
B. 还原完整数据库备份和差异备份
以下示例还原完整数据库备份后还原差异备份。另外,以下示例还说明如何还原媒体上的另一个备份集。差异备份追加到包含完整数据库备份的备份设备上。
复制代码
RESTORE DATABASE MyAdvWorks FROM MyAdvWorks_1 WITH NORECOVERYRESTORE DATABASE MyAdvWorks FROM MyAdvWorks_1 WITH FILE = 2C.
使用 RESTART 语法还原数据库
以下示例使用 RESTART 选项重新启动因服务器电源故障而中断的 RESTORE 操作。
复制代码--
This database RESTORE halted prematurely due to power failure.RESTORE DATABASE MyAdvWorks FROM MyAdvWorks_1Here is the RESTORE RESTART operation.RESTORE DATABASE MyAdvWorks FROM MyAdvWorks_1 WITH RESTARTD.还原数据库并移动文件
以下示例还原完整数据库和事务日志,并将已还原的数据库移动到 C:\Program Files\Microsoft SQL Server\MSSQL\Data 目录下。
复制代码
RESTORE DATABASE MyAdvWorks FROM MyAdvWorks_1 WITH NORECOVERY, MOVE ' MyAdvWorks ' TO 'c:\Program Files\Microsoft SQL Server\MSSQL\Data\NewAdvWorks.mdf',MOVE 'MyAdvWorksLog1' TO ' c:\Program Files\MicrosoftSQL Server\MSSQL\Data\NewAdvWorks.ldf 'RESTORE LOG MyAdvWorks FROM MyAdvWorksLog1 WITH RECOVERYE.使用 BACKUP 和 RESTORE 创建数据库的副本
以下示例使用 BACKUP 和 RESTORE 语句创建 AdventureWorks 数据库的副本。MOVE 语句使数据和日志文件还原到指定的位置。RESTORE FILELISTONLY 语句用于确定待还原数据库内的文件数及名称。该数据库的新副本称为 TestDB。有关详细信息,请参阅 RESTORE FILELISTONLY (Transact-SQL)。
复制代码
BACKUP DATABASE AdventureWorks TO DISK = 'C:\AdventureWorks.bak'RESTORE FILELISTONLY FROM DISK = 'C:\AdventureWorks.bak'RESTORE DATABASE TestDB FROM DISK = 'C:\AdventureWorks.bak ' WITHMOVE 'AdventureWorks_Data' TO 'C:\testdb.mdf',MOVE 'AdventureWorks_Log ' TO ' C:\testdb.ldf' GOF.使用 STOPAT 语法还原到时间点和使用多个设备进行还原
以下示例将数据库还原到它在 2005 年 4 月 15 日中午 12 点时的状态,并显示涉及多个日志和多个备份设备的还原操作。
复制代码
RESTORE DATABASE MyAdvWorks FROM MyAdvWorks_1, MyAdvWorks_2 WITH NORECOVERY, STOPAT = 'Apr 15, 2005 12:00 AM'RESTORE LOG MyAdvWorks FROM MyAdvWorksLog1 WITH NORECOVERY, STOPAT = 'Apr 15, 2005 12:00 AM'RESTORE LOG MyAdvWorks FROM MyAdvWorksLog2 WITH RECOVERY, STOPAT = 'Apr 15, 2005 12:00 AM'G.将事务日志还原到标记
以下示例将事务日志还原到名为 ListPriceUpdate 的标记事务中的标记处。
复制代码
USE AdventureWorks GOBEGIN TRANSACTION ListPriceUpdate WITH MARK 'UPDATE Product list prices' GOUPDATE Production.Product SET ListPrice = ListPrice * 1.10 WHERE ProductNumber LIKE 'BK-%' GOCOMMIT TRANSACTION ListPriceUpdate GO-- Time passes. Regular database-- and log backups are taken.-- An error occurs.USE master GORESTORE DATABASE AdventureWorks FROM AdvWorks1 WITH FILE = 3, NORECOVERY GORESTORE LOG AdventureWorks FROM AdvWorks1 WITH FILE = 4, STOPATMARK = 'ListPriceUpdate'H.使用 TAPE 语法还原
以下示例从 TAPE 备份设备还原完整数据库备份。
复制代码
RESTORE DATABASE MyAdvWorks FROM TAPE = '\\.\tape0'I. 使用 FILE 和 FILEGROUP 语法还原
以下示例还原一个包含两个文件、一个文件组和一个事务日志的数据库。
复制代码
RESTORE DATABASE MyAdvWorks FILE = 'MyAdvWorks_data_1', FILE = 'MyAdvWorks_data_2', FILEGROUP = 'new_customers' FROM MyAdvWorks_1 WITH NORECOVERY-- Restore the log backup.RESTORE LOG MyAdvWorks FROM MyAdvWorksLog1J.
恢复到数据库快照
以下示例将数据库恢复到数据库快照。此示例假定该数据库当前仅存在一个快照。有关创建此数据库快照的示例,请参阅如何创建数据库快照 (Transact-SQL)。
注意:
恢复到快照将删除所有全文目录。
七.MySQL和SQL Server区别:
1.支持类型不一样。
mysql支持enum以及set类型,不支持nchar和nvarchar,还有ntext类型。
而sql server不支持enum以及set类型。
2.递增语句不一样。
mysql的递增语句是AUTO_INCREMENT,而sql server的递增语句是identity。
3.默认值格式不一样。
sql server默认导出表创建语句的默认值表示为((0)),而在mysql里面,不允许默认值带两个括号。
4.识别符号不同。
sql server的识别符号是[],而mysql的识别符号是`。
5.获取当前时间日期的方法有差别。
sql server支持用getdate()的方法获取当前时间日期,但是mysql获取当前日期方法是通过cur_date(),获取当前完整时间则是要通过now()函数。
6.开发时期不一样。
mysql是开发于90年代中期的,最早的开源数据库中的一个。
sql server是80年代开发的。
7.所用开发语言有差别。
sql server最适合用.net作为开发语言,而mysql能用几乎所有的其他开发语言,最常用的开发语言是PHP。
解析:
在Web应用上,mysql是最好的RDBMS应用软件中的一个。使用的sql语言是用来访问数据库的最常用的标准化语言。因为这个软件体积小,加载速度快,成本不高,开放源码,所以通常中小型网站的开发都用mysql作为网站数据库。
八.mysql和oracle的区别
1.现状与前景
mysql与oracle都是关系型数据库,应用于各种平台。
mysql开源免费的,而oracle则是收费的,并且价格非常高。
2.管理工具上
mysql的管理工具较少,在Linux下的管理工具的安装有时需要安装额外的包(phpmyadmin,etc),有一定复杂性。
oracle有多重成熟命令行、图形界面、web管理工具,还有很多第三方的管理工具,管理极其方便高效。oracle支持大并发,大访问量,是OLTP最好的工具。
3.数据库的层次结构上
mysql:默认用户是root,用户下可以创建好多数据库,每个数据库下还有好多表,一般情况下都是使用默认用户,不会创建多个用户;
oracle:创建一个数据库,数据库下有好多用户:sys、system、scott等,不同用户下有好多表,一般情况下只创建一个数据库用。
4.数据库中表字段类型:
mysql:int、float、double等数值型,varchar、char字符型,date、datetime、time、year、timestamp等日期型。
oracle:number(数值型),varchar2、varchar、char(字符型),date(日期型)等…
5.主键
mysql一般使用自动增长类型,在创建表时只要指定表的主键auto increment,插入记录时,不需要再指定该记录的主键值,mysql将自动增长。
oracle没有自动增长类型,主键一般使用的序列,插入记录时将序列号的下一个值赋给该字段即可,只是ORM框架是只要是native主键生成策略即可。
6.单引号处理
mysql里可以用双引号包起字符串,oracle只可以用单引号包起字符串。
7.查询方式
mysql是直接在SQL语句中使用limit就可以实现分页
racle则是需要用到伪劣ROWNUM和嵌套查询
8.对事务提交
mysql默认是自动提交,可以修改为手动提交
oracle默认不自动提交,需要手动提交,需要在写commit指令或点击commit按钮。
9.对事务的支持
mysql在innodb存储引擎的夯机所的情况下才支持事务
oracle则完全支持事务。
10.事务隔离级别:
mysql是read commited的隔离级别
而oracle是repeatable read的隔离级别
同时二者都支持serializable串行化事务隔离级别,可以实现最高级别的读一致性。每个session提交后其它session才能看到提交的更改;
11.并发性:
mysql以表级锁为主,对资源锁定的粒度很大,如果一个session对一个表加锁时间过长,会让其他session无法更新此表中的数据。
oracle使用行级锁,对资源锁定的粒度要小很多,只是锁定sql需要的资源,并且加锁是在数据库中的数据行上,不依赖于索引,所以oracle对并发性的支持要好很多。
12.逻辑备份
mysql逻辑备份时要锁定数据,才能保证备份的数据是一致的,影响业务正常的dml使用
oracle逻辑备份时不锁定数据,且备份的数据是一致的。
13.复制
mysql:复制服务器配置很简单,但主库出问题时,从库可能丢失一定的数据,且需要手工切换从库到主库;
oracle:既有堆或拉式的传统数据复制,也有dataguard的双机或多机容灾机制,主库出问题时,可以自动切换备库到主库,但配置管理较复杂。
14.性能诊断
mysql的诊断调优方法较少,主要有慢查询日志;
oracle有各种成熟的性能诊断调优工具,能实现很多自动分析、诊断功能。比如awr、addm、sqltrace、tkproof等。
15.日期转换
mysql中日期转换用dateformat()函数;
oracle用to_date()与to_char()两个函数。





![【web | CTF】BUUCTF [护网杯 2018] easy_tornado](https://img-blog.csdnimg.cn/direct/0ff50c504a754de286f85d0632376dd3.png)

![[OPEN SQL] 修改数据](https://img-blog.csdnimg.cn/direct/a275ec0c8bb44cae93bbd67bb39bb922.png)
![[BIZ] - 1.金融交易系统特点](https://img-blog.csdnimg.cn/direct/6489c57a78dd4a3986cb1269c4e6dd2e.png)