浅聊泛型常量参数Const Generic
引题
最近有网友私信我讨论:若使用规则宏编译时统计token tree序列的长度,如何绕开由宏递归自身局限性造成的:
被统计序列不能太长
编译延时显著拖长
的问题。然后,就贴出了如下的一段例程代码1:
fn main() {macro_rules! count_tts {($_a:tt $($tail: tt)*) => { 1_usize + count_tts!($($tail)*) };() => { 0_usize };}assert_eq!(10, count_tts!(,,,,,,,,,,));
}嚯!这段短小精悍的代码馁馁地演示了
Incremental TT Muncher设计模式的精髓。赞!
首先,宏递归深度是有极限的(默认是128层)。所以,若每次递归仅新统计一个token,那么被统计序列的最大长度自然不能超过128。否则,突破上限,编译失败!
其次,尾递归优化是运行时压缩函数调用栈的技术手段,却做不到编译时抑制宏调用栈的膨胀。所以,巧用#![recursion_limit="…"]元属性强制调高宏递归深度上限很可能会导致编译器栈溢出。
由此,如果仅追求快速绕过问题,那最经济实惠的作法是:在每次宏递归期间,多统计几个token 例程2(而不是一次一个)。从算数上,将总递归次数降下来,和使计数更长的token tree序列成为可能。
fn main() { // 这代码看着就“傻乎乎的”。macro_rules! count_tts {($_a: tt $_b: tt $_c: tt $_d: tt $_e: tt $_f: tt // 一次递归统计 6 个。$($tail: tt)*) => { 6_usize + count_tts!($($tail)*) };($_a: tt $_b: tt $_c: // 一次递归统计 3 个。tt $($tail: tt)*) => { 3_usize + count_tts!($($tail)*) };($_a: tt // 一次递归统计 1 个。$($tail: tt)*) => { 1_usize + count_tts!($($tail)*) };() => { 0_usize }; // 结束了,统计完成}println!("token tree 个数是 {}", count_tts!(,,,,,,,,,,));
}倘若要标本兼治地解决问题,将递归调用变形成循环结构才是正途,因为循环本身不会增加调用栈的深度。这涵盖了:
宏循环结构将
token tree序列变形成数组字面量。常量函数调用触发编译器对数组字面量的类型推导。
因为
rust数组在编译时明确大小,所以数组长度被编入了数据类型定义内。泛型常量参数从数据类型定义中提取出数组长度值,并作为序列长度返回。
全套操作被统称为Array length设计模式。它带入了两个技术难点:
如何触发
rustc对数组字面量的类型推导,和从推导结果中提取出数组长度信息。如何撇开递归的“吐吞模式”(即,吐
Incremental TT Muncher和吞Push-down Accumulation),仅凭宏循环结构,将token tree序列变形成为数组字面量。
第一个难点源于自rustc 1.51才稳定的新语言特性“泛型常量参数Const Generic”。而第二个难点的解决就多样化了
要么,采用“循环替换设计模式
Repetition Replacement(RR)”要么,启用试验阶段语言特性“元变量表达式
Meta-variable Expression”
接下来,它们会被逐一地讲解分析。
泛型常量参数
从rustc 1.51+起,【泛型常量参数 】允许泛型项(类或函数)接受常量值或常量表达式为泛型参数。根据泛型常量参数出现的位置不同(请见下图例程3),它又细分为
泛型常量参数的形参
泛型常量参数的实参

下文分别将它们简称为“泛型常量形参”与“泛型常量实参”。
泛型参数的分类
于是,已知的泛型参数就包含有三种类型:

泛型常量参数的数据类型
可用作【泛型常量参数】的数据类型包括两类:
整数数字类型:
u8,u16,u32,u64,u128,usize,i8,i16,i32,i64,i128,isize可数字化类型:
char,bool
泛型常量参数的“怪癖”
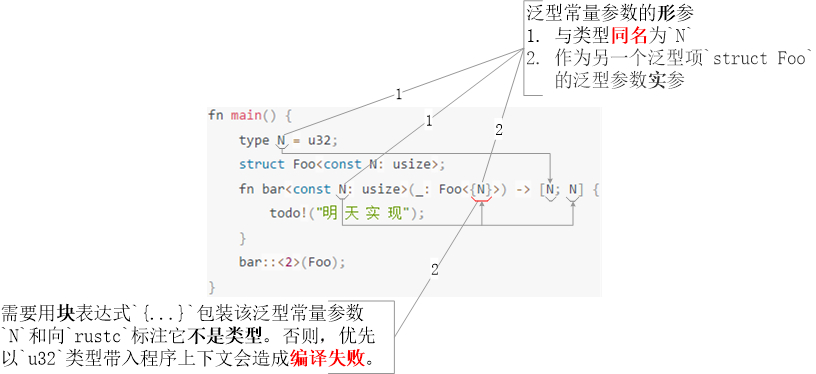
首先,就“同名冲突”而言,若【泛型常量形参】与【类型】同名并作为另一个泛型项的泛型参数实参,那么rustc会优先将该泛型参数当作类型带入程序上下文。多数情况下,这会造成程序编译失败。解决方案是使用块表达式{...}包装泛型常量参数,以向rustc标注此同名参数是泛型常量参数而不是类型名 例程4。
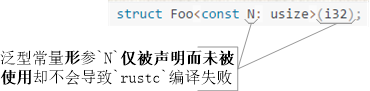
其次,就“声明和使用”而言,泛型常量形参允许仅被声明,而不被使用。对另两种泛型参数而言,这却会导致编译失败例程5。
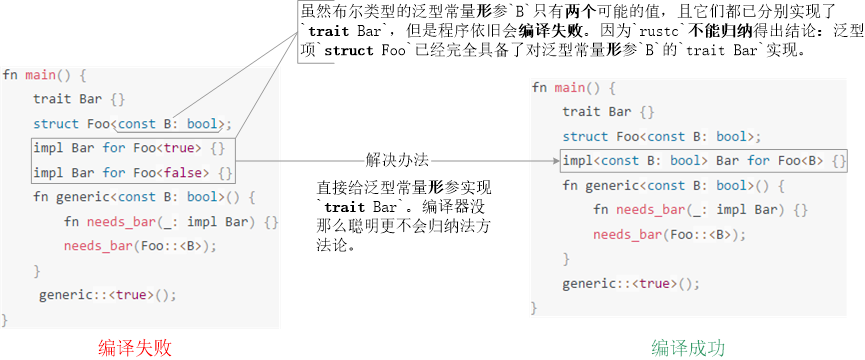
最后,泛型常量实参的trait实现不会因为穷举了全部备选形参值而自动过渡给泛型常量形参。如下例程6(左),即便泛型项struct Foo显示地给泛型常量形参B的每个可能的(实参)值true / false都实现的同一个trait Bar,编译器也不会“聪明地”归纳出该trait Bar已经被此泛型项的泛型常量形参充分实现了,因为编译器可不会“归纳法”方法论(不确定chatGPT是否能做到?)。相反,每个实参上的trait实现都被视作不相关的个例。正确地作法是:泛型项必须明确地给泛型常量形参实现trait例程7(右)。
泛型常量参数的适用位置
泛型常量参数原则上可出现于常量项适用的全部位置,包括但不限于:
运行时求值表达式
#1— 模糊了编译时泛型参数与运行时值之间的界限。常量表达式
#2关联常量
#2关联类型
#3结构体字段 或 绑定变量的数据类型
#4。比如,编译时参数化数组长度。结构体字段 或 绑定变量的值
#5
上述列表内的#1 ~ #5,可在下面例程8源码内找到对应的代码行。
use rand::{thread_rng, Rng};
fn main() {fn foo1<const N1: usize>(input: usize) { // 在泛型函数内,泛型常量参数的形参可用于let sum = 1 + N1 * input; // #1 运行时求值的表达式let foo = Foo([input; N1]); // #5 结构体字段的值let arr: [usize; N1] = [input; N1]; // #4 绑定变量的数据类型 —— 编译时参数化数组长度// #5 绑定变量的值println!("运行时表达式:{sum},\n\元组结构体: {foo:?},\n\数组: {arr:?}");}trait Trait<const N2: usize> {const CONST: usize = N2 + 4; // #2 关联常量 + 常量表达式type Output;}#[derive(Debug)]struct Foo<const N3: usize>([usize; N3] // #4 结构体字段的数据类型 —— 编译时参数化数组长度);impl<const N4: usize> Trait<N4> for Foo<N4> {type Output = [usize; N4]; // #3 关联类型 —— 编译时参数化数组长度}let mut rng = thread_rng();foo1::<2>(rng.gen_range::<usize, _>(1..10));foo1::<{1 + 2}>(rng.gen_range::<usize, _>(1..10));const K: usize = 3;foo1::<K>(rng.gen_range::<usize, _>(1..10));foo1::<{K * 2}>(rng.gen_range::<usize, _>(1..10));
}泛型常量参数的不适用位置
首先,泛型常量形参不能:
定义常量和静态变量,无论是作为类型定义的一部分,还是值
#1隔层使用。比如,在子函数内引用由外层函数声明的泛型常量形参
#2。除了子函数,该规则也适用于在函数体内定义的结构体
#3类型别名
#4
上述列表内的#1 ~ #4,可在下面例程9源码内找到对应的代码行。
fn main() {fn outer<const N: usize>(input: usize) {// 泛型常量参数【不】可用于函数体内的// #1 常量定义// - 既不能定义类型const BAD_CONST: [usize; N] = [1; N];// - 既不能定义值const BAD_CONST: usize = 1 + N;// #1 静态变量定义// - 既不能定义类型static BAD_STATIC: [usize; N] = [N + 1; N];// - 既不能定义值static BAD_STATIC: usize = 1 + N;fn inner(bad_arg: [usize; N]) {// #2 在子函数内不能引用外层函数声明的// 泛型常量形参,无论是将其作为// 变量类型,还是常量值。let bad_value = N * 2;}// #3 结构体内也不能引用外层函数声明的// 泛型常量形参。struct BadStruct([usize; N]);// 相反,需要给结构体重新声明泛型常量参数struct BadStruct<const N: usize>([usize; N]);// #4 类型别名内不能引用外层函数声明的// 泛型常量形参。type BadAlias = [usize; N];// 相反,需要给类型别名重新声明泛型常量参数type BadAlias<const N: usize> = [usize; N];}
}其次,泛型常量实参不接受包含了泛型常量形参的常量表达式例程10。
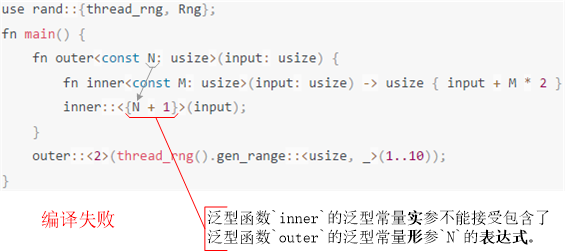
但是,泛型常量实参并不拒绝接受
独立泛型常量形参 例程11
不包含泛型常量形参的普通常量表达式例程12
题外话,不确定这么翻译该术语
lookahead是否正确。我借鉴了 @余晟 在《精通正则表达式》一书中对此词条的译文。被用作泛型常量实参的常量表达式必须被包装在块表达式
{...}内。避免编译器在解析AST过程中陷入正向环视lookahead的无限循环中。
数组重复表达式与泛型常量参数
数组重复表达式[repeat_operand; length_operand]是数组字面量的一种形式。在数组重复表达式中,泛型常量形参
虽然既可用于左
repeat操作数位置,也可用于右length操作数位置例程13但在右
length操作数位置上,泛型常量形参只能独立出现例程14,而不能作为常量表达式的一部分 —— 等同于泛型常量实参的限制。

回到序列计数问题
类似于解析几何中的“投影”方法,通过将高维物体(token tree序列)投影于低维平面(数组),以主动舍弃若干信息项(每个token的具体值与数据类型)为代价,突出该物体更有价值的信息内容(序列长度),便可降低从复杂结构中摘取特定关注信息项的合计复杂度。这套“降维算法”带来的启发就是:
既然读取数组长度是简单的,那为什么不先将
token tree序列变形为数组呢?答:投影
token tree序列为数组
既然
token tree序列的内容细节不被关注,那为什么还要纠结于数组的数据类型与填充值呢?全部充满unit type岂不快哉!再答:投影
token tree序列为单位数组[(); N]。仅数组长度对我们有价值。
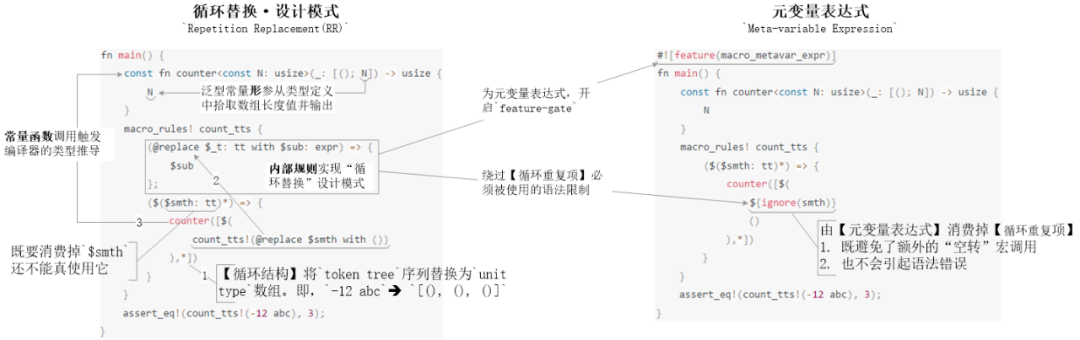
于是,循环替换设计模式Repetition Replacement(RR)与元变量表达式${ignore(识别符名)}都是被用来改善【宏循环结构】的使用体验,以允许Rustacean对循环结构中的循环重复项“宣而不用” —— 既遍历token tree序列,同时又弃掉每个具体的token元素,最后还生成一个等长的单位数组[(); N]。否则,未被使用的“循环重复项”会导致error: attempted to repeat an expression containing no syntax variables matched as repeating at this depth的编译错误。
循环替换设计模式
Repetition Replacement(RR)是以在宏循环体内插入一层“空转”宏调用,消费掉consuming未被使用的“循环重复项”例程15元变量表达式
${ignore(识别符名)}是前者的语法糖,允许Rustacean少敲几行代码。但因为元变量表达式是试验性的新语法,所以需要开启对应的feature-gate开关#![feature(macro_metavar_expr)]才能被使用。例程16
然后,常量函数调用和函数形参触发编译器对单位数组字面量的类型推导。
接着,泛型常量形参从被推导出的数据类型定义内提取出数组长度信息。
最后,将泛型常量形参作为常量函数的返回值输出。
上图,一图抵千词。
结束语
除了前文提及的【宏递归法】与Array Length设计模式,统计token tree序列长度还有
Slice Length设计模式原理类似
Array Length,但调用数组字面量的pub const fn len(&self) -> usize成员方法读取长度值(而不是依赖类型推导和泛型参数提取)。
枚举计数法
规则宏将
token tree序列变形为“枚举类”(而不是数组字面量),再由最后一个枚举值的分辨因子discriminant值加1获得序列长度。但,缺点也明显。比如,
token tree序列内不能包含rust语法关键字与重复项。
比特计数法
典型的算法优化。从数学层面,将程序复杂度从
O(n)降到O(log(n))。有些复杂,回头单独写一篇文章分享之。
【规则宏】与【泛型参数】皆是rust编程语言提供的业务功能开发利器。宏循环结构与泛型常量参数仅只是它们的冰山一角。此文既汇总分享与网友的讨论成果,也对此话题抛砖引玉。希望有机会与路过的神仙哥哥和仙女妹妹们更深入地交流相关技术知识点与实践经验。