文章目录
- 前言
- RDD的底层是什么?
- 结构化 Spark
- 主要优点和好处
- DataFrame API
- Spark的基本数据类型
- Spark的结构化和复杂数据类型
- Schemas 和创建 DataFrames
- Columns 和 Expressions
- Rows
- 通用的 DataFrame 算子
- The Dataset API
- 有类型 Objects、无类型 Objects 和通用 Rows
- 创建 Datasets
- Dataset 算子
- DataFrames 和 Datasets 比较
- 什么时候使用 RDD
- Spark SQL 和底层引擎
- The Catalyst Optimizer
- 总结
前言
在本文中,我们将探索 Spark 的结构化 APIs(DataFrames and Datasets)。我们还将看下 Spark SQL 引擎是如何支撑高级的结构化 APIs 的。
当Spark SQL在早期的Spark 1.x 中首次引入时, 随后是DataFrames 继承了Spark 1.3中 SchemaRDDs ,此时我们第一次看到了Spark中的结构化 API。Spark SQL引入了高级表达操作函数,模仿类似SQL的语法,而Dataframe为后续版本中更多的结构奠定了基础,为Spark计算查询中的高性能操作铺平了道路。
但是,在我们讨论新的结构化API之前,让我们先来看看简单的RDD编程API模型,让我们简要了解一下Spark中没有结构是什么感觉。
RDD的底层是什么?
RDD是Spark中最基本的抽象。有三个与RDD相关的重要特征:
- 依赖关系
- 分区(带有一些位置信息)
- 计算函数:Partition =>
Iterator[T]
首先,这三个都是简单的RDD编程API模型的组成部分,所有高级功能都是在这个模型上构建的。首先,需要一个依赖项列表,该列表指示Spark如何使用其输入构造RDD。当需要重现结果时,Spark可以根据这些依赖关系重新创建RDD,并在其上复制操作, 这个特性使RDD具有弹性。
其次,分区为Spark提供了拆分工作的能力,以便跨 executors 并行化分区上的计算。在某些情况下(例如,从hdfs读取数据),Spark 通过位置信息将任务发送至距离数据进的 executor 上。这样一来,通过网络传输的数据就少了。
最后,RDD有一个计算函数,它为将存储在RDD中的数据生成一个Iterator[T]。
简单又优雅!然而,这种原始模式存在一些问题。首先,计算函数(或计算)对Spark来说是不透明的。也就是说,Spark不知道你在计算函数中做什么。无论执行的是连接、筛选、选择还是聚合,Spark都只将其视为lambda表达式。另一个问题是Iterator[T]数据类型对于Python rdd来说也是不透明的;Spark只知道它是Python中的泛型对象。
这种不透明性显然阻碍了Spark将计算重新安排为高效查询计划的能力。那么解决方案是什么呢?
结构化 Spark
Spark 2.x 介绍了结构化 Spark 的几个关键方案。一种是在数据分析中发现的通用模式来表达计算, 这些模式表示为高级操作,如过滤、选择、计数、聚合、平均和分组,这为开发人员提供了简单清晰的使用方式。
Spark 提供了许多通用的算子,每个算子都是有一个固定的计算逻辑,在构建 Spark 程序的时候,我们可以使用这些通用的算子,这样 Spark 在构建查询计划的时候就知道该如何优化。
最终这些结构化和顺序的 schema 可以让你以表格的形式构建数据,比如 SQL 表或者 sheet,只要按照支持的结构化数据类型(后文会说到)。
那么结构化的好处是什么呢?
主要优点和好处
结构化带来了许多好处,包括更好的性能和跨Spark组件的空间效率。在讨论DataFrame和Dataset api的使用时,我们将进一步探讨这些优点,但现在我们将集中讨论其他优点: 表达性、简单性、可组合性和一致性。
让我们首先用一个简单的代码片段演示表达性和可组合性。在下面的示例中,我们希望聚合每个名字的所有年龄,按名字分组,然后取年龄的平均值——这是数据分析和发现中的常见模式。如果我们要为此使用低级RDD API,代码将如下所示:
# In Python
# Create an RDD of tuples (name, age)
dataRDD = sc.parallelize([("Brooke", 20), ("Denny", 31), ("Jules", 30), ("TD", 35), ("Brooke", 25)])
# Use map and reduceByKey transformations with their lambda
# expressions to aggregate and then compute averageagesRDD = (dataRDD.map(lambda x: (x[0], (x[1], 1))).reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1])).map(lambda x: (x[0], x[1][0]/x[1][1])))
这段代码告诉Spark如何使用一串lambda函数聚合键并计算平均值,没有人会质疑这段代码的晦涩难懂和难以阅读。换句话说,代码指示Spark如何计算查询,它对Spark来说是完全不透明的,因为它没有传达意图。此外,Scala中等效的RDD代码看起来与这里所示的Python代码非常不同。
相比之下,如果我们用高级DSL算子和DataFrame API来表达相同的查询,从而指示Spark做什么更加明确:
# In Python
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg
# Create a DataFrame using SparkSession
spark = (SparkSession.builder.appName("AuthorsAges").getOrCreate())
# Create a DataFrame
data_df = spark.createDataFrame([("Brooke", 20), ("Denny", 31), ("Jules", 30), ("TD", 35), ("Brooke", 25)], ["name", "age"])
# Group the same names together, aggregate their ages, and compute an average
avg_df = data_df.groupBy("name").agg(avg("age"))
# Show the results of the final execution
avg_df.show()+------+--------+
| name|avg(age)|
+------+--------+
|Brooke| 22.5|
| Jules| 30.0|
| TD| 35.0|
| Denny| 31.0|
+------+--------+
这个版本的代码比之前的版本更具表现力,也更简单,因为我们使用了高级DSL算子和api来告诉Spark该做什么。实际上,当我们使用这些算子来构建 Spark 程序的时候,Spark 可以理解我们的计算意图,然后优化查询计划。
有些人认为,只使用高级的、表达性的DSL算子,限制了开发人员定制查询能力。其实没必要这样,现有的算子基本上可以满足已有的查询方式,如果觉得不满足也可以在算子和低级 RDD API 间切换查询方式。
除了易于阅读外,Spark的高级api的结构化还在其组件和语言之间引入了一致性。例如,这里显示的Scala代码与前面的Python代码做同样的事情- API看起来几乎相同:
// In Scala
import org.apache.spark.sql.functions.avg
import org.apache.spark.sql.SparkSession
// Create a DataFrame using SparkSession
val spark = SparkSession
.builder
.appName("AuthorsAges")
.getOrCreate()
// Create a DataFrame of names and ages
val dataDF = spark.createDataFrame(Seq(("Brooke", 20), ("Brooke", 25), ("Denny", 31), ("Jules", 30), ("TD", 35))).toDF("name", "age")
// Group the same names together, aggregate their ages, and compute an average
val avgDF = dataDF.groupBy("name").agg(avg("age"))
// Show the results of the final execution
avgDF.show()+------+--------+
| name|avg(age)|
+------+--------+
|Brooke| 22.5|
| Jules| 30.0|
| TD| 35.0|
| Denny| 31.0|
+------+--------+
因为Spark SQL引擎是构建高级结构化api的基础,才使得这些简单性和表达性都是可能的。正是由于这个支持所有Spark组件的引擎,我们才获得了统一的api。无论是在结构化流还是MLlib中表达对DataFrame的查询,我们总是将DataFrame作为结构化数据进行转换和操作。我们将在本文后面更深入地了解Spark SQL引擎,但现在让我们探索那些用于常见操作的api和dsl,以及如何使用它们进行数据分析。
DataFrame API
Spark dataframe在结构、格式和一些特定操作上受到了pandas dataframe的启发,它就像是带有命名列和schema的分布式内存表,其中每个列都有特定的数据类型:整数、字符串、数组、映射、实数、日期、时间戳等。在人的眼中,Spark DataFrame就像一张表。如下表所示:
当数据被可视化为结构化表时,它不仅易于理解,而且当涉及到你可能希望对行和列执行的常见操作时,也易于使用。Dataframe是不可变的,Spark保持所有转换的血缘关系。你可以添加或更改列的名称和数据类型,在保留以前版本的同时创建新的Dataframe, DataFrame中的命名列及其关联的Spark数据类型可以在 schema 中声明。
在生成 schema 之前我们需要检查下这些结构化数据类型在 Spark 中是否可用,然后我们接下来看如何使用 schema 生成一个 DataFrame,去验证上表中的数据。
Spark的基本数据类型
与其支持的编程语言相匹配,Spark支持基本的内部数据类型。这些数据类型可以在Spark应用程序中声明,也可以在schema中定义。例如,在Scala中,我们可以定义或声明特定列名的类型为String、Byte、Long或Map等。这里,我们定义了与Spark数据类型相关的变量名:
$SPARK_HOME/bin/spark-shell
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> val nameTypes = StringType
nameTypes: org.apache.spark.sql.types.StringType.type = StringType
scala> val firstName = nameTypes
firstName: org.apache.spark.sql.types.StringType.type = StringType
scala> val lastName = nameTypes
lastName: org.apache.spark.sql.types.StringType.type = StringType
Spark支持的基本Scala数据类型如下表所示。它们都是DataTypes类的子类型,除了DecimalType:
Spark支持类似的Python基本数据类型,如下表所示:
Spark的结构化和复杂数据类型
对于复杂的数据分析,将不仅仅处理简单或基本的数据类型,数据将是复杂的,通常是结构化的或嵌套的,需要Spark来处理这些复杂的数据类型。它们有多种形式:映射、数组、结构、日期、时间戳、字段等。Spark支持的Scala结构化数据类型如下表所示:
Python中Spark支持的等价结构化数据类型如下表所示: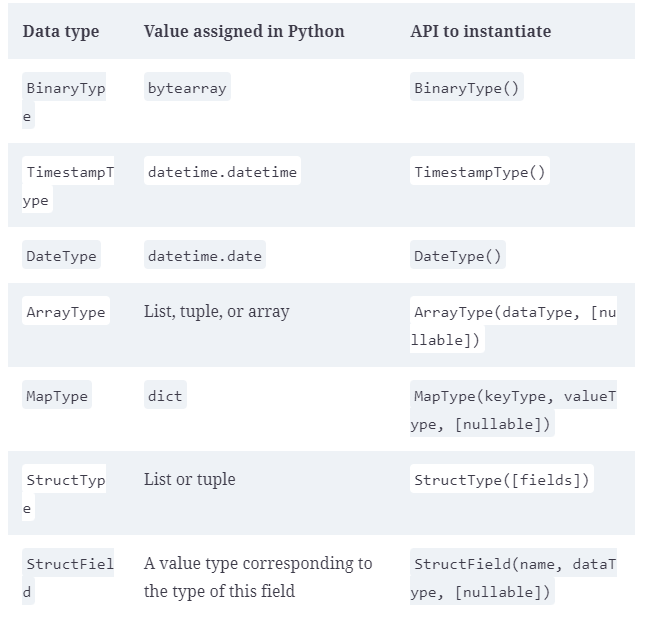
虽然这些表展示了支持的大量类型,但在为数据定义schema时,更重要的是了解这些类型是如何组合在一起的。
Schemas 和创建 DataFrames
Spark中的schema 为DataFrame定义了列名和相关的数据类型。通常,当从外部数据源读取结构化数据时,schema 就会发挥作用(后续文章我会详细说明)。与采用读时schema 的方法相比,预先定义schema 有三个好处:
- Spark 不在需要推断数据类型
- 可以防止Spark仅仅为了读取文件的大部分内容来确定Schema 而创建单独的作业,这对于大型数据文件来说既昂贵又耗时。
- 如果数据与 schema 不匹配,可以及早发现错误。
因此,建议从数据源读取大文件时始终预先定义Schema 。接下来举个简单例子,让我们为前边说的数据表中的数据定义一个Schema ,并使用该schema 创建一个DataFrame。
定义 Schema 的两种方法
Spark允许以两种方式定义schema。一种方法是以编程的方式定义它,另一种方法是使用数据定义语言(Data Definition Language, DDL)字符串,后者更简单,更容易阅读。
要以编程方式为具有三个命名列的DataFrame定义schema:author, title 和 pages ,可以使用Spark DataFrame API。例如:
// In Scala
import org.apache.spark.sql.types._
val schema = StructType(Array(StructField("author", StringType, false),StructField("title", StringType, false),StructField("pages", IntegerType, false)))
# In Python
from pyspark.sql.types import *
schema = StructType([StructField("author", StringType(), False),StructField("title", StringType(), False),StructField("pages", IntegerType(), False)])
使用DDL定义相同的schema要简单得多:
// In Scala
val schema = "author STRING, title STRING, pages INT"
# In Python
schema = "author STRING, title STRING, pages INT"
可以选择任何喜欢的方式来定义schema。对于许多例子,两种都会用:
# In Python
from pyspark.sql import SparkSession# Define schema for our data using DDL
schema = "`Id` INT, `First` STRING, `Last` STRING, `Url` STRING, `Published` STRING, `Hits` INT, `Campaigns` ARRAY<STRING>"# Create our static data
data = [[1, "Jules", "Damji", "https://tinyurl.1", "1/4/2016", 4535, ["twitter",
"LinkedIn"]],[2, "Brooke","Wenig", "https://tinyurl.2", "5/5/2018", 8908, ["twitter",
"LinkedIn"]],[3, "Denny", "Lee", "https://tinyurl.3", "6/7/2019", 7659, ["web",
"twitter", "FB", "LinkedIn"]],[4, "Tathagata", "Das", "https://tinyurl.4", "5/12/2018", 10568,
["twitter", "FB"]],[5, "Matei","Zaharia", "https://tinyurl.5", "5/14/2014", 40578, ["web",
"twitter", "FB", "LinkedIn"]],[6, "Reynold", "Xin", "https://tinyurl.6", "3/2/2015", 25568,
["twitter", "LinkedIn"]]]# Main program
if __name__ == "__main__":# Create a SparkSessionspark = (SparkSession.builder.appName("Example-3_6").getOrCreate())# Create a DataFrame using the schema defined aboveblogs_df = spark.createDataFrame(data, schema)# Show the DataFrame; it should reflect our table aboveblogs_df.show()# Print the schema used by Spark to process the DataFrameprint(blogs_df.printSchema())
从控制台中运行此程序将产生以下输出:
$ spark-submit Example-3_6.py
...
+-------+---------+-------+-----------------+---------+-----+------------------+
|Id |First |Last |Url |Published|Hits |Campaigns |
+-------+---------+-------+-----------------+---------+-----+------------------+
|1 |Jules |Damji |https://tinyurl.1|1/4/2016 |4535 |[twitter,...] |
|2 |Brooke |Wenig |https://tinyurl.2|5/5/2018 |8908 |[twitter,...] |
|3 |Denny |Lee |https://tinyurl.3|6/7/2019 |7659 |[web, twitter...] |
|4 |Tathagata|Das |https://tinyurl.4|5/12/2018|10568|[twitter, FB] |
|5 |Matei |Zaharia|https://tinyurl.5|5/14/2014|40578|[web, twitter,...]|
|6 |Reynold |Xin |https://tinyurl.6|3/2/2015 |25568|[twitter,...] |
+-------+---------+-------+-----------------+---------+-----+------------------+root|-- Id: integer (nullable = false)|-- First: string (nullable = false)|-- Last: string (nullable = false)|-- Url: string (nullable = false)|-- Published: string (nullable = false)|-- Hits: integer (nullable = false)|-- Campaigns: array (nullable = false)| |-- element: string (containsNull = false)
如果希望在代码的其他地方使用此schema,只需执行blogs_df.schema,它将返回schema 定义:
StructType(List(StructField("Id",IntegerType,false),
StructField("First",StringType,false),
StructField("Last",StringType,false),
StructField("Url",StringType,false),
StructField("Published",StringType,false),
StructField("Hits",IntegerType,false),
StructField("Campaigns",ArrayType(StringType,true),false)))
如果要从JSON文件读取数据,而不是创建静态数据,那么schema 定义将是相同的。让我们用一个Scala示例来说明相同的代码,这次是从JSON文件中读取:
// In Scala
package main.scala.chapter3import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._object Example3_7 {def main(args: Array[String]) {val spark = SparkSession.builder.appName("Example-3_7").getOrCreate()if (args.length <= 0) {println("usage Example3_7 <file path to blogs.json>")System.exit(1)}// Get the path to the JSON fileval jsonFile = args(0)// Define our schema programmaticallyval schema = StructType(Array(StructField("Id", IntegerType, false),StructField("First", StringType, false),StructField("Last", StringType, false),StructField("Url", StringType, false),StructField("Published", StringType, false),StructField("Hits", IntegerType, false),StructField("Campaigns", ArrayType(StringType), false)))// Create a DataFrame by reading from the JSON file // with a predefined schemaval blogsDF = spark.read.schema(schema).json(jsonFile)// Show the DataFrame schema as outputblogsDF.show(false)// Print the schemaprintln(blogsDF.printSchema)println(blogsDF.schema)}
}
毫不奇怪,Scala程序的输出与Python程序的输出没有什么不同:
+---+---------+-------+-----------------+---------+-----+----------------------+
|Id |First |Last |Url |Published|Hits |Campaigns |
+---+---------+-------+-----------------+---------+-----+----------------------+
|1 |Jules |Damji |https://tinyurl.1|1/4/2016 |4535 |[twitter, LinkedIn] |
|2 |Brooke |Wenig |https://tinyurl.2|5/5/2018 |8908 |[twitter, LinkedIn] |
|3 |Denny |Lee |https://tinyurl.3|6/7/2019 |7659 |[web, twitter,...] |
|4 |Tathagata|Das |https://tinyurl.4|5/12/2018|10568|[twitter, FB] |
|5 |Matei |Zaharia|https://tinyurl.5|5/14/2014|40578|[web, twitter, FB,...]|
|6 |Reynold |Xin |https://tinyurl.6|3/2/2015 |25568|[twitter, LinkedIn] |
+---+---------+-------+-----------------+---------+-----+----------------------+root|-- Id: integer (nullable = true)|-- First: string (nullable = true)|-- Last: string (nullable = true)|-- Url: string (nullable = true)|-- Published: string (nullable = true)|-- Hits: integer (nullable = true)|-- Campaigns: array (nullable = true)| |-- element: string (containsNull = true)StructType(StructField("Id",IntegerType,true), StructField("First",StringType,true), StructField("Last",StringType,true), StructField("Url",StringType,true),StructField("Published",StringType,true), StructField("Hits",IntegerType,true),StructField("Campaigns",ArrayType(StringType,true),true))
现在我们已经了解了如何在DataFrame中使用结构化数据和schema,接下来让我们关注一下DataFrame的列和行,以及使用DataFrame API对它们进行操作意味着什么。
Columns 和 Expressions
如前所述,dataframe中的命名列在概念上类似于pandas或R dataframe或RDBMS表中的命名列:
它们描述一种类型的字段。可以按列的名称列出所有列,并且可以使用关系表达式或计算表达式对列的值执行操作。在Spark支持的语言中,列是具有公共方法的对象(由Column类型表示)。
还可以在列上使用逻辑或数学表达式。例如,可以使用expr("columnName * 5")或(expr("columnName - 5") > col(anothercolumnName))创建一个简单的表达式,其中columnName是Spark类型(整数,字符串等)。expr()是pyspark.sql.functions (Python)和org.apache.spark.sql.functions (Scala)包的一部分。与这些包中的任何其他函数一样,expr()接受Spark将作为表达式解析的参数,并计算结果。
NOTE
Scala、Java和Python都有与列相关的公共方法。我们注意到Spark文档同时引用了col和Column。Column是对象的名称,而col()是返回Column的标准内置函数。
让我们看一些例子,看看我们可以用Spark中的列做些什么。每个示例后面都有它的输出:
// In Scala
scala> import org.apache.spark.sql.functions._
scala> blogsDF.columns
res2: Array[String] = Array(Campaigns, First, Hits, Id, Last, Published, Url)// Access a particular column with col and it returns a Column type
scala> blogsDF.col("Id")
res3: org.apache.spark.sql.Column = id// Use an expression to compute a value
scala> blogsDF.select(expr("Hits * 2")).show(2)
// or use col to compute value
scala> blogsDF.select(col("Hits") * 2).show(2)+----------+
|(Hits * 2)|
+----------+
| 9070|
| 17816|
+----------+// Use an expression to compute big hitters for blogs
// This adds a new column, Big Hitters, based on the conditional expression
blogsDF.withColumn("Big Hitters", (expr("Hits > 10000"))).show()+---+---------+-------+---+---------+-----+--------------------+-----------+
| Id| First| Last|Url|Published| Hits| Campaigns|Big Hitters|
+---+---------+-------+---+---------+-----+--------------------+-----------+
| 1| Jules| Damji|...| 1/4/2016| 4535| [twitter, LinkedIn]| false|
| 2| Brooke| Wenig|...| 5/5/2018| 8908| [twitter, LinkedIn]| false|
| 3| Denny| Lee|...| 6/7/2019| 7659|[web, twitter, FB...| false|
| 4|Tathagata| Das|...|5/12/2018|10568| [twitter, FB]| true|
| 5| Matei|Zaharia|...|5/14/2014|40578|[web, twitter, FB...| true|
| 6| Reynold| Xin|...| 3/2/2015|25568| [twitter, LinkedIn]| true|
+---+---------+-------+---+---------+-----+--------------------+-----------+// Concatenate three columns, create a new column, and show the
// newly created concatenated column
blogsDF.withColumn("AuthorsId", (concat(expr("First"), expr("Last"), expr("Id")))).select(col("AuthorsId")).show(4)+-------------+
| AuthorsId|
+-------------+
| JulesDamji1|
| BrookeWenig2|
| DennyLee3|
|TathagataDas4|
+-------------+// These statements return the same value, showing that
// expr is the same as a col method call
blogsDF.select(expr("Hits")).show(2)
blogsDF.select(col("Hits")).show(2)
blogsDF.select("Hits").show(2)+-----+
| Hits|
+-----+
| 4535|
| 8908|
+-----+// Sort by column "Id" in descending order
blogsDF.sort(col("Id").desc).show()
blogsDF.sort($"Id".desc).show()+--------------------+---------+-----+---+-------+---------+-----------------+
| Campaigns| First| Hits| Id| Last|Published| Url|
+--------------------+---------+-----+---+-------+---------+-----------------+
| [twitter, LinkedIn]| Reynold|25568| 6| Xin| 3/2/2015|https://tinyurl.6|
|[web, twitter, FB...| Matei|40578| 5|Zaharia|5/14/2014|https://tinyurl.5|
| [twitter, FB]|Tathagata|10568| 4| Das|5/12/2018|https://tinyurl.4|
|[web, twitter, FB...| Denny| 7659| 3| Lee| 6/7/2019|https://tinyurl.3|
| [twitter, LinkedIn]| Brooke| 8908| 2| Wenig| 5/5/2018|https://tinyurl.2|
| [twitter, LinkedIn]| Jules| 4535| 1| Damji| 1/4/2016|https://tinyurl.1|
+--------------------+---------+-----+---+-------+---------+-----------------+
在最后一个例子中,表达式blogs_df.sort(col("Id").desc)和blogs_df.sort($"Id".desc)是相同的。它们都按降序对名为Id的DataFrame列进行排序: 一个使用显式函数col("id")返回column对象,而另一个在列的名称前使用$,这是Spark中的一个函数,将名为Id的列转换为column。
NOTE
这里我们只列举了最简单的,并且只在Column对象上使用了几个方法。要获得Column对象的所有公共方法的完整列表,请参考Spark文档。
DataFrame中的列对象不能孤立存在.
每一个 Column 对象都是记录中一行的一部分,所有的行一起构成了一个DataFrame,正如我们将在本文后面看到的,它实际上是Scala中的Dataset[row]。
Rows
Spark中的行是一个通用的row对象,包含一个或多个列。每一列可以是相同的数据类型(例如,整数或字符串),或者它们可以有不同的类型(整数、字符串、映射、数组等)。因为Row是Spark中的一个对象,并且是一个有序的字段集合,所以你可以用Spark支持的每种语言实例化Row,并通过从0开始的索引访问它的字段:
// In Scala
import org.apache.spark.sql.Row
// Create a Row
val blogRow = Row(6, "Reynold", "Xin", "https://tinyurl.6", 255568, "3/2/2015", Array("twitter", "LinkedIn"))
// Access using index for individual items
blogRow(1)
res62: Any = Reynold
# In Python
from pyspark.sql import Row
blog_row = Row(6, "Reynold", "Xin", "https://tinyurl.6", 255568, "3/2/2015", ["twitter", "LinkedIn"])
# access using index for individual items
blog_row[1]
'Reynold'
如果需要快速交互和探索,可以使用Row对象来创建dataframe:
# In Python
rows = [Row("Matei Zaharia", "CA"), Row("Reynold Xin", "CA")]
authors_df = spark.createDataFrame(rows, ["Authors", "State"])
authors_df.show()
// In Scala
val rows = Seq(("Matei Zaharia", "CA"), ("Reynold Xin", "CA"))
val authorsDF = rows.toDF("Author", "State")
authorsDF.show()+-------------+-----+
| Author|State|
+-------------+-----+
|Matei Zaharia| CA|
| Reynold Xin| CA|
+-------------+-----+
但是,在实践中,我们通常希望像前面所示的那样从文件中读取dataframe。在大多数情况下,由于文件将非常庞大,因此定义schema并使用它是创建dataframe的一种更快、更有效的方法。
在创建了大型分布式DataFrame之后,我们将希望对其执行一些常见的数据操作。让我们来看看可以使用结构化api中的高级关系操作符执行的一些Spark操作。
通用的 DataFrame 算子
要在DataFrame上执行常见的数据操作,首先需要从保存结构化数据的数据源加载一个DataFrame。Spark提供了一个接口 DataFrameReader,它使我们能够从多种数据源(如JSON, CSV, Parquet, Text, Avro, ORC等格式)中读取数据到DataFrame中。同样,要以特定格式将DataFrame写回数据源,Spark使用 DataFrameWriter。
DataFrameReader 和 dataframerwriter 的使用
在Spark中读写非常简单,因为这些高层次的抽象和社区的贡献可以连接到各种各样的数据源,包括常见的NoSQL存储、rdbms、流引擎(如Apache Kafka和Kinesis)等等。
首先,让我们读取一个包含旧金山消防局呼叫数据的大型CSV文件,如前所述,我们将为该文件定义一个schema,并使用DataFrameReader类及其方法告诉Spark该做什么。因为这个文件包含28列和超过4,380,660条记录(原始数据集有60多个列。我们删除了一些不必要的列,删除了null或无效值的记录,并添加了一个额外的Delay列),所以定义schema 比让Spark推断 schema 更有效。
NOTE
如果不想指定模式,Spark可以以较低的成本从示例中推断 schema。例如,可以使用samplingRatio选项:
// In Scala
val sampleDF = spark
.read
.option(“samplingRatio”, 0.001)
.option(“header”, true)
.csv(“”“/databricks-datasets/learning-spark-v2/
sf-fire/sf-fire-calls.csv”“”)
下边是代码实现:
# In Python, define a schema
from pyspark.sql.types import *# Programmatic way to define a schema
fire_schema = StructType([StructField('CallNumber', IntegerType(), True),StructField('UnitID', StringType(), True),StructField('IncidentNumber', IntegerType(), True),StructField('CallType', StringType(), True), StructField('CallDate', StringType(), True), StructField('WatchDate', StringType(), True),StructField('CallFinalDisposition', StringType(), True),StructField('AvailableDtTm', StringType(), True),StructField('Address', StringType(), True), StructField('City', StringType(), True), StructField('Zipcode', IntegerType(), True), StructField('Battalion', StringType(), True), StructField('StationArea', StringType(), True), StructField('Box', StringType(), True), StructField('OriginalPriority', StringType(), True), StructField('Priority', StringType(), True), StructField('FinalPriority', IntegerType(), True), StructField('ALSUnit', BooleanType(), True), StructField('CallTypeGroup', StringType(), True),StructField('NumAlarms', IntegerType(), True),StructField('UnitType', StringType(), True),StructField('UnitSequenceInCallDispatch', IntegerType(), True),StructField('FirePreventionDistrict', StringType(), True),StructField('SupervisorDistrict', StringType(), True),StructField('Neighborhood', StringType(), True),StructField('Location', StringType(), True),StructField('RowID', StringType(), True),StructField('Delay', FloatType(), True)])# Use the DataFrameReader interface to read a CSV file
sf_fire_file = "/databricks-datasets/learning-spark-v2/sf-fire/sf-fire-calls.csv"
fire_df = spark.read.csv(sf_fire_file, header=True, schema=fire_schema)
// In Scala it would be similar
val fireSchema = StructType(Array(StructField("CallNumber", IntegerType, true),StructField("UnitID", StringType, true),StructField("IncidentNumber", IntegerType, true),StructField("CallType", StringType, true), StructField("Location", StringType, true),......StructField("Delay", FloatType, true)))// Read the file using the CSV DataFrameReader
val sfFireFile="/databricks-datasets/learning-spark-v2/sf-fire/sf-fire-calls.csv"
val fireDF = spark.read.schema(fireSchema)
.option("header", "true")
.csv(sfFireFile)
spark.read.csv()函数读入CSV文件并返回包含 schema 中指定类型的行和命名列的DataFrame。
想以特定格式将DataFrame写入外部数据源,可以使用DataFrameWriter接口。与DataFrameReader一样,它支持多个数据源。Parquet,一种流行的列示存储格式,是默认格式;它使用快速压缩来压缩数据。如果DataFrame被写成Parquet,那么 scheme 将作为Parquet元数据的一部分保存。在这种情况下,后续读取回DataFrame不需要手动提供 schema。
将DataFrame保存为Parquet文件或SQL表
常见的数据操作是查询和转换数据,然后以Parquet格式持久化DataFrame或将其保存为SQL表。持久化转换后的DataFrame与读取它一样简单。例如,要在读取数据框后将其作为文件持久化,将执行以下操作:
// In Scala to save as a Parquet file
val parquetPath = ...
fireDF.write.format("parquet").save(parquetPath)
# In Python to save as a Parquet file
parquet_path = ...
fire_df.write.format("parquet").save(parquet_path)
或者作为表保存:
// In Scala to save as a table
val parquetTable = ... // name of the table
fireDF.write.format("parquet").saveAsTable(parquetTable)
# In Python
parquet_table = ... # name of the table
fire_df.write.format("parquet").saveAsTable(parquet_table)
在读取数据之后,让我们浏览一下对dataframe执行的一些常见操作。
转换和操作
现在,在内存中有了一个由San Francisco Fire Department调用组成的分布式DataFrame,作为开发人员,要做的第一件事就是检查数据,看看列是什么样子。它们是正确的类型吗?有需要转换成不同类型的吗?它们有空值吗?
投影和过滤
关系术语中的投影是一种方法,通过使用过滤器只返回与特定关系条件匹配的行。在Spark中,投影是用select()方法完成的,而过滤器可以用filter()或where()方法表示。我们可以使用这种技术来查询数据集的特定信息:
# In Python
few_fire_df = (fire_df.select("IncidentNumber", "AvailableDtTm", "CallType") .where(col("CallType") != "Medical Incident"))
few_fire_df.show(5, truncate=False)
// In Scala
val fewFireDF = fireDF
.select("IncidentNumber", "AvailableDtTm", "CallType")
.where($"CallType" =!= "Medical Incident")
fewFireDF.show(5, false)+--------------+----------------------+--------------+
|IncidentNumber|AvailableDtTm |CallType |
+--------------+----------------------+--------------+
|2003235 |01/11/2002 01:47:00 AM|Structure Fire|
|2003235 |01/11/2002 01:51:54 AM|Structure Fire|
|2003235 |01/11/2002 01:47:00 AM|Structure Fire|
|2003235 |01/11/2002 01:47:00 AM|Structure Fire|
|2003235 |01/11/2002 01:51:17 AM|Structure Fire|
+--------------+----------------------+--------------+
only showing top 5 rows
重命名、添加和删除列
有时出于样式或约定的原因需要重命名特定列,有时则是为了可读性或简洁性。有时候数据集的列中可能会有空格,例如,列名“IncidentNumber ”和“IncidentNumber”。列名中的空格可能会有问题,特别是当想要将DataFrame写入或保存为Parquet文件时(这是禁止的)。
通过使用StructField在 schema 中指定所需的列名,就像我们所做的那样,我们有效地更改了结果DataFrame中的所有名称。
或者,可以使用withColumnRenamed()方法选择性地重命名列。例如,让我们将列Delay的名称更改为ResponseDelayd inMins,并查看超过五分钟的响应时间:
# In Python
new_fire_df = fire_df.withColumnRenamed("Delay", "ResponseDelayedinMins")
(new_fire_df.select("ResponseDelayedinMins").where(col("ResponseDelayedinMins") > 5).show(5, False))
// In Scala
val newFireDF = fireDF.withColumnRenamed("Delay", "ResponseDelayedinMins")
newFireDF
.select("ResponseDelayedinMins")
.where($"ResponseDelayedinMins" > 5)
.show(5, false)
将返回一个新的重命名列:
+---------------------+
|ResponseDelayedinMins|
+---------------------+
|5.233333 |
|6.9333334 |
|6.116667 |
|7.85 |
|77.333336 |
+---------------------+
only showing top 5 rows
NOTE
因为DataFrame转换是不可变的,所以当我们使用withcolumnrename()重命名一个列时,我们会得到一个新的DataFrame,同时保留原来的列名称。
修改列的内容或其类型是数据查询过程中常见的操作。在某些情况下,数据是原始的或脏的,或者其类型不适合作为关系操作符的参数提供。例如,在数据集中,列CallDate、WatchDate和AlarmDtTm是字符串,而不是Unix时间戳或SQL日期,这两者都是Spark支持的,并且可以在转换或操作期间(例如,在基于日期或基于时间的数据分析期间)轻松操作。
那么我们如何将它们转换成更可用的格式呢?这非常简单,这要归功于一些高级API方法。Spark.sql.functions有一组to/from date/timestamp函数,比如to_timestamp()和to_date(),我们可以使用它们来实现这个目的:
# In Python
fire_ts_df = (new_fire_df.withColumn("IncidentDate", to_timestamp(col("CallDate"), "MM/dd/yyyy")).drop("CallDate") .withColumn("OnWatchDate", to_timestamp(col("WatchDate"), "MM/dd/yyyy")).drop("WatchDate") .withColumn("AvailableDtTS", to_timestamp(col("AvailableDtTm"), "MM/dd/yyyy hh:mm:ss a")).drop("AvailableDtTm"))# Select the converted columns
(fire_ts_df.select("IncidentDate", "OnWatchDate", "AvailableDtTS").show(5, False))
// In Scala
val fireTsDF = newFireDF
.withColumn("IncidentDate", to_timestamp(col("CallDate"), "MM/dd/yyyy"))
.drop("CallDate")
.withColumn("OnWatchDate", to_timestamp(col("WatchDate"), "MM/dd/yyyy"))
.drop("WatchDate")
.withColumn("AvailableDtTS", to_timestamp(col("AvailableDtTm"), "MM/dd/yyyy hh:mm:ss a"))
.drop("AvailableDtTm") // Select the converted columns
fireTsDF
.select("IncidentDate", "OnWatchDate", "AvailableDtTS")
.show(5, false)
这些查询包含了相当大的工作量,让我们来分析一下它们做了什么:
- 将现有列的数据类型从字符串转换为spark支持的时间戳。
- 在适当的情况下,使用格式字符串"MM/dd/yyyy"或"MM/dd/yyyy hh: MM:ss a"指定的新格式。
- 转换为新数据类型后,删除旧列,并将新列作为
withColumn()的第一个参数。 - 将新修改的DataFrame 实例化为 fire_ts_df。
查询的新列结果如下:
+-------------------+-------------------+-------------------+
|IncidentDate |OnWatchDate |AvailableDtTS |
+-------------------+-------------------+-------------------+
|2002-01-11 00:00:00|2002-01-10 00:00:00|2002-01-11 01:58:43|
|2002-01-11 00:00:00|2002-01-10 00:00:00|2002-01-11 02:10:17|
|2002-01-11 00:00:00|2002-01-10 00:00:00|2002-01-11 01:47:00|
|2002-01-11 00:00:00|2002-01-10 00:00:00|2002-01-11 01:51:54|
|2002-01-11 00:00:00|2002-01-10 00:00:00|2002-01-11 01:47:00|
+-------------------+-------------------+-------------------+
only showing top 5 rows
现在我们已经修改了日期,我们可以使用spark.sql.functions中的函数进行查询,如dayofmonth()、dayofyear()和dayofweek()来进一步查询我们的数据。我们可以找出在过去七天内记录了多少电话,或者我们可以通过这个查询查看数据集中包含了多少年的消防部门电话:
# In Python
(fire_ts_df.select(year('IncidentDate')).distinct().orderBy(year('IncidentDate')).show())
// In Scala
fireTsDF
.select(year($"IncidentDate"))
.distinct()
.orderBy(year($"IncidentDate"))
.show()
+------------------+
|year(IncidentDate)|
+------------------+
| 2000|
| 2001|
| 2002|
| 2003|
| 2004|
| 2005|
| 2006|
| 2007|
| 2008|
| 2009|
| 2010|
| 2011|
| 2012|
| 2013|
| 2014|
| 2015|
| 2016|
| 2017|
| 2018|
+------------------+
到目前为止,我们已经探讨了一些常见的数据操作:读取和写入数据框架.
定义schema 并在读取DataFrame时使用它。
将DataFrame保存为Parquet文件或表。
从现有DataFrame投射和过滤选定的列。
以及修改、重命名和删除列。
聚合
如果我们想知道最常见的火警呼叫类型是什么,或者哪个邮政编码占了最多的电话,该怎么办?这类问题在数据分析和查询中很常见。
Dataframes 上的一些转换和算子,如groupBy()、orderBy()和count(),提供了按列名进行聚合的能力,然后在它们之间聚合计数。
# In Python
(fire_ts_df.select("CallType").where(col("CallType").isNotNull()).groupBy("CallType").count().orderBy("count", ascending=False).show(n=10, truncate=False))
// In Scala
fireTsDF
.select("CallType")
.where(col("CallType").isNotNull)
.groupBy("CallType")
.count()
.orderBy(desc("count"))
.show(10, false)+-------------------------------+-------+
|CallType |count |
+-------------------------------+-------+
|Medical Incident |2843475|
|Structure Fire |578998 |
|Alarms |483518 |
|Traffic Collision |175507 |
|Citizen Assist / Service Call |65360 |
|Other |56961 |
|Outside Fire |51603 |
|Vehicle Fire |20939 |
|Water Rescue |20037 |
|Gas Leak (Natural and LP Gases)|17284 |
+-------------------------------+-------+
NOTE
DataFrame API也提供了collect()方法,但是对于非常大的DataFrame来说,这是资源繁重(昂贵)且危险的,因为它可能导致内存不足(OOM)异常。与count()不同,它向驱动程序返回单个数字,collect()返回整个DataFrame或Dataset中所有Row对象的集合。如果想查看一些Row记录,最好使用take(n),它将只返回DataFrame的前n个Row对象。
其他常见的DataFrame 算子
与我们看到的所有其他方法一样,DataFrame API提供了描述性统计方法,如min()、max()、sum()和avg()。让我们看一些示例,展示如何使用SF消防局的数据集计算它们。
在这里,我们计算警报的总和,平均响应时间,以及我们数据集中所有火警调用的最小和最大响应时间,以Pythonic 的方式导入PySpark函数,以免与内置Python函数冲突:
# In Python
import pyspark.sql.functions as F
(fire_ts_df.select(F.sum("NumAlarms"), F.avg("ResponseDelayedinMins"),F.min("ResponseDelayedinMins"), F.max("ResponseDelayedinMins")).show())
// In Scala
import org.apache.spark.sql.{functions => F}
fireTsDF
.select(F.sum("NumAlarms"), F.avg("ResponseDelayedinMins"), F.min("ResponseDelayedinMins"), F.max("ResponseDelayedinMins"))
.show()+--------------+--------------------------+--------------------------+---------+
|sum(NumAlarms)|avg(ResponseDelayedinMins)|min(ResponseDelayedinMins)|max(...) |
+--------------+--------------------------+--------------------------+---------+
| 4403441| 3.902170335891614| 0.016666668|1879.6167|
+--------------+--------------------------+--------------------------+---------+
对于数据科学工作内容中常见的更高级的统计需求,请阅读API文档,了解stat()、describe()、correlation()、covariance()、sampleBy()、approxQuantile()、frequentItems()等方法。
正如我们所看到的,用DataFrames的高级API和DSL 算子进行链式查询是很容易的。如果我们尝试对rdd做同样的事情,我们无法想象代码的不透明性和不可读性!
接下来,我们将把重点转移到Dataset API,并探索这两个API如何为开发人员提供统一的结构化接口,用于编程Spark。然后,我们将查看RDD、DataFrame和Dataset API之间的关系,并帮助您确定何时使用哪个API以及为什么使用。
The Dataset API
Spark 2.0将DataFrame和Dataset api统一为具有类似接口的结构化api,这样开发人员只需要学习一组api。Datasets 有两种特征: 定义类型和未定义类型的 API:
从概念上讲,可以将Scala中的DataFrame视为通用对象集合Dataset[Row]的别名,其中Row是一个通用的无类型JVM对象,可以包含不同类型的字段。相比之下,Dataset 是Scala中强类型JVM对象的集合或Java中的类。或者,正如Dataset文档所说,Dataset是:
- 域特定对象的强类型集合,可以使用函数或关系操作并行转换。每个数据集(在Scala中)也有一个称为DataFrame的未类型化视图,它是一个行数据集。
有类型 Objects、无类型 Objects 和通用 Rows
在Spark支持的语言中,Datasets 只在Java和Scala中有意义,而在Python和R中只有DataFrames 有意义。这是因为Python和R不是编译时类型安全的。类型是在执行期间动态推断或赋值的,而不是在编译期间。在Scala和Java中则相反,类型在编译时绑定到变量和对象。然而,在Scala中,DataFrame只是untyped Dataset[Row]的别名,下图进行了简单的对比:
Row是Spark中的通用对象类型,包含可以使用索引访问的混合类型集合。在内部,Spark操作Row对象,将它们转换为其他语言的等效类型。例如,Int作为Row中的一个字段将被映射或转换为IntegerType或IntegerType(),分别用于Scala或Java和Python:
// In Scala
import org.apache.spark.sql.Row
val row = Row(350, true, "Learning Spark 2E", null)
# In Python
from pyspark.sql import Row
row = Row(350, True, "Learning Spark 2E", None)
通过索引访问:
// In Scala
row.getInt(0)
res23: Int = 350
row.getBoolean(1)
res24: Boolean = true
row.getString(2)
res25: String = Learning Spark 2E
# In Python
row[0]
Out[13]: 350
row[1]
Out[14]: True
row[2]
Out[15]: 'Learning Spark 2E'
相比之下,有类型的对象是JVM中实际的Java或Scala类对象。Dataset中的每个元素都映射到一个JVM对象。
创建 Datasets
与从数据源创建 DataFrames 一样,在创建 Dataset 时,必须了解 schema。换句话说,您需要知道数据类型。虽然使用JSON和CSV数据可以推断 schema,但对于大型数据集,这是资源密集型的(昂贵的)。在Scala中创建数据集时,为结果数据集指定模式的最简单方法是使用case类。在Java中,使用JavaBean类。
Scala: Case classes
当我们希望将自己的特定领域对象实例化为Dataset时,可以通过在Scala中定义case类来实现。
我们的文件有如下的JSON字符串行:
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip":
"80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude":
53.080000, "longitude": 18.620000, "scale": "Celsius", "temp": 21,
"humidity": 65, "battery_level": 8, "c02_level": 1408,"lcd": "red",
"timestamp" :1458081226051}
为了将每个JSON条目表示为DeviceIoTData,一个特定于领域的对象,我们可以定义一个Scala case类:
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude: Double,lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)
一旦定义,我们可以使用它来读取文件并将返回的Dataset[Row]转换为Dataset[DeviceIoTData](输出被截断以适合页面):
// In Scala
val ds = spark.read.json("/databricks-datasets/learning-spark-v2/iot-devices/iot_devices.json").as[DeviceIoTData]ds: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...]ds.show(5, false)+-------------|---------|----|----|-------------|---------|---+
|battery_level|c02_level|cca2|cca3|cn |device_id|...|
+-------------|---------|----|----|-------------|---------|---+
|8 |868 |US |USA |United States|1 |...|
|7 |1473 |NO |NOR |Norway |2 |...|
|2 |1556 |IT |ITA |Italy |3 |...|
|6 |1080 |US |USA |United States|4 |...|
|4 |931 |PH |PHL |Philippines |5 |...|
+-------------|---------|----|----|-------------|---------|---+
only showing top 5 rows
Dataset 算子
正如你可以对 Dataframe 执行转换和算子操作一样,你也可以对 Dataset 执行转换和算子操作。根据操作的类型,结果会有所不同:
// In Scala
val filterTempDS = ds.filter({d => {d.temp > 30 && d.humidity > 70})filterTempDS: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...]filterTempDS.show(5, false)+-------------|---------|----|----|-------------|---------|---+
|battery_level|c02_level|cca2|cca3|cn |device_id|...|
+-------------|---------|----|----|-------------|---------|---+
|0 |1466 |US |USA |United States|17 |...|
|9 |986 |FR |FRA |France |48 |...|
|8 |1436 |US |USA |United States|54 |...|
|4 |1090 |US |USA |United States|63 |...|
|4 |1072 |PH |PHL |Philippines |81 |...|
+-------------|---------|----|----|-------------|---------|---+
only showing top 5 rows
在这个查询中,我们使用一个函数作为Dataset方法filter()的参数。这是一个具有许多签名的重载方法。我们使用的版本是filter(func: (T) > Boolean): Dataset[T],它接受一个lambda函数func: (T) > Boolean作为参数。
lambda函数的参数是DeviceIoTData类型的JVM对象。因此,我们可以使用点(.)表示法访问它的各个数据字段,就像在Scala类或JavaBean中一样。
下面是另一个例子,结果是另一个更小的 Dataset:
// In Scala
case class DeviceTempByCountry(temp: Long, device_name: String, device_id: Long, cca3: String)
val dsTemp = ds.filter(d => {d.temp > 25}).map(d => (d.temp, d.device_name, d.device_id, d.cca3)).toDF("temp", "device_name", "device_id", "cca3").as[DeviceTempByCountry]
dsTemp.show(5, false)+----+---------------------+---------+----+
|temp|device_name |device_id|cca3|
+----+---------------------+---------+----+
|34 |meter-gauge-1xbYRYcj |1 |USA |
|28 |sensor-pad-4mzWkz |4 |USA |
|27 |sensor-pad-6al7RTAobR|6 |USA |
|27 |sensor-pad-8xUD6pzsQI|8 |JPN |
|26 |sensor-pad-10BsywSYUF|10 |USA |
+----+---------------------+---------+----+
only showing top 5 rows
或者可以只检索数据集的第一行:
val device = dsTemp.first()
println(device)device: DeviceTempByCountry =
DeviceTempByCountry(34,meter-gauge-1xbYRYcj,1,USA)
或者,可以使用列名表达相同的查询,然后强制转换为Dataset[DeviceTempByCountry]:
// In Scala
val dsTemp2 = ds.select($"temp", $"device_name", $"device_id", $"device_id", $"cca3").where("temp > 25").as[DeviceTempByCountry]
NOTE
从语义上讲,select()类似于前一个查询中的map(),因为这两个查询都选择字段并生成相同的结果。
当我们使用数据集时,底层Spark SQL引擎处理JVM对象的创建、转换、序列化和反序列化。它还在Dataset编码器的帮助下处理java之外的堆内存管理。
DataFrames 和 Datasets 比较
到目前为止,我们可能想知道为什么以及何时应该使用 DataFrames 或 Datasets。在许多情况下,两者都可以,这取决于正在使用的语言,但在某些情况下,其中一种比另一种更可取。下面是一些例子:
- 如果你想让 Spark 做什么,而不是怎么做,使用 DataFrames 或 Datasets。
- 如果您想要丰富的语义、高级抽象和DSL操作符,使用 DataFrames 或 Datasets。
- 如果你想要严格的编译时类型安全,并且不介意为特定的
Dataset[T]创建多个case类,请使用Datasets。 - 如果你的处理需要高级表达式、过滤器、映射、聚合、计算平均值或总和、SQL查询、列访问或在半结构化数据上使用关系操作符,请使用 DataFrames 或 Datasets。
- 如果你的程序要求关系转换类似于sql的查询,请使用dataframe。
- 如果你想利用和受益于钨编码器的高效序列化,使用 Datasets。
- 如果希望统一、代码优化和简化Spark组件之间的api,请使用dataframe。
- 如果你是R语言用户,请使用DataFrames。
- 如果你是Python用户,请使用dataframe,如果需要更多控制,可以使用rdd。
- 如果需要空间和速度效率,请使用dataframe。
- 如果希望在编译期间而不是在运行时捕获错误,请选择下图所示的适当API。
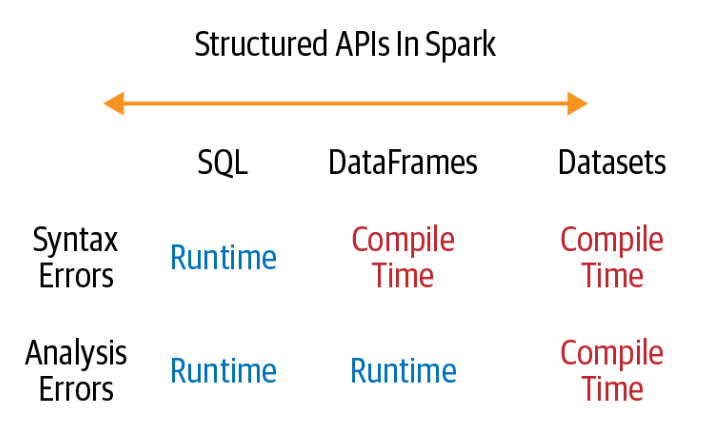
什么时候使用 RDD
你可能会问: rdd被贬为二等公民了吗?它们被弃用了吗?
答案是一个响亮的否定!
RDD API将继续得到支持,尽管所有未来的开发工作都将在Spark 2.x和Spark 3.0 中进行,将继续使用DataFrame接口和语义,而不是使用rdd。
在某些情况下,你可能需要考虑使用rdd,例如:
- 是否正在使用rdd编写的第三方软件包
- 可以放弃Dataframs和Dataset提供的代码优化、有效的空间利用和性能优势吗
- 想要精确地指示Spark如何做查询
构建高效查询和生成紧凑代码的过程是Spark SQL引擎的工作。它是我们一直在研究的结构化api构建的基础。
Spark SQL 和底层引擎
在编程层面,Spark SQL允许开发人员使用 schema 对结构化数据发出与ANSI SQL:2003兼容的查询。自从在Spark 1.3中引入以来,Spark SQL已经发展成为一个强大的引擎,许多高级结构化功能都建立在它的基础上。除了允许你对你的数据发出类似SQL的查询,Spark SQL引擎:
- 统一Spark组件,并允许 Java、Scala、Python和R中的 DataFrames/Datasets 的抽象,从而简化了结构化数据集的处理。
- 连接Apache Hive metastore和表。
- 从结构化文件格式(JSON, CSV, Text, Avro, Parquet, ORC等)中以特定模式读写结构化数据,并将数据转换为临时表。
- 提供交互式Spark SQL shell,用于快速数据查询。
- 通过标准数据库JDBC/ODBC连接器提供与外部工具之间的桥接。
- 为JVM生成优化的查询计划和紧凑的代码,以便最终执行。
下图显示了Spark SQL与其他组件间的交互: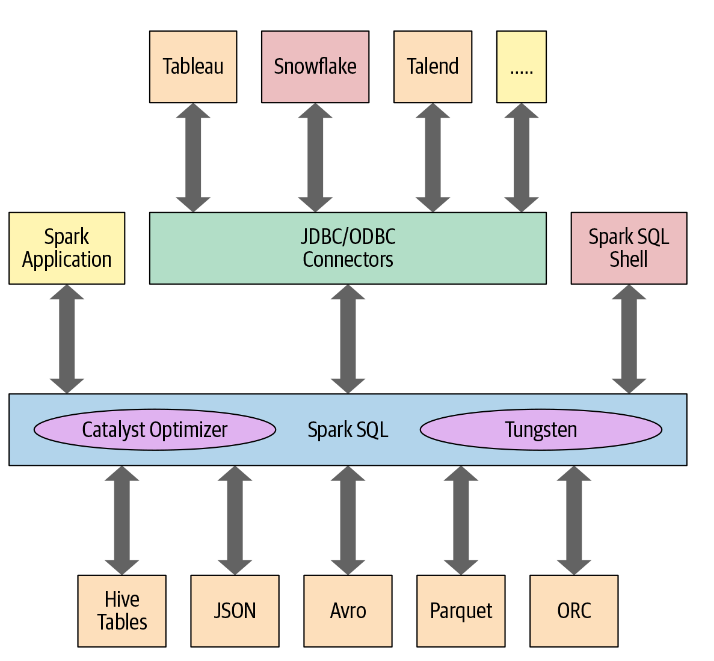
Spark SQL引擎的核心是Catalyst优化器和Project Tungsten。它们一起支持高级的DataFrame和Dataset api以及SQL查询。
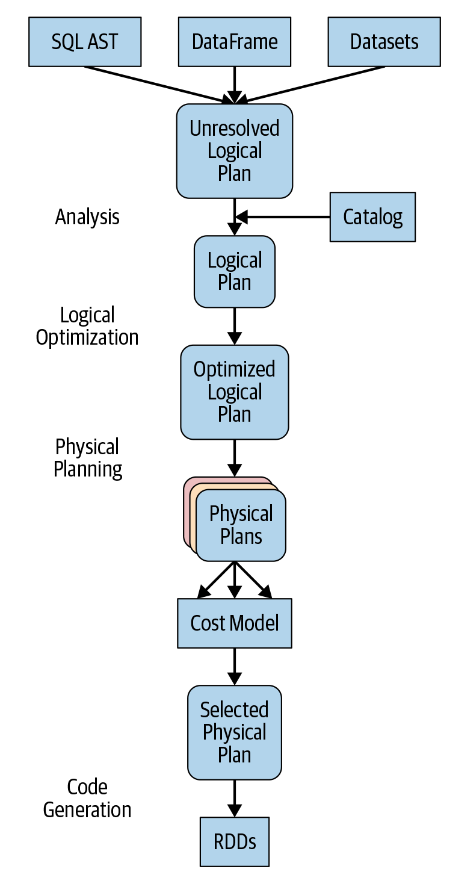
The Catalyst Optimizer
Catalyst优化器接受计算查询并将其转换为执行计划。它经历了四个转变阶段,如下图所示:
- 分析
- 逻辑优化
- 生成物理计划
- 代码生成
下面两个示例代码块将经历相同的过程,最终得到类似的查询计划和相同的执行字节码。也就是说,不管你使用哪种语言,你的计算过程都是一样的,产生的字节码可能是一样的:
# In Python
count_mnm_df = (mnm_df.select("State", "Color", "Count").groupBy("State", "Color").agg(sum("Count").alias("Total")).orderBy("Total", ascending=False))
-- In SQL
SELECT State, Color, sum(Count) AS Total
FROM MNM_TABLE_NAME
GROUP BY State, Color
ORDER BY Total DESC
要查看Python代码经历的不同阶段,可以在DataFrame上使用count_mnm_df.explain(True)方法。或者,要查看不同的逻辑和物理计划,可以在Scala中调用df.queryExecution.logical或df.queryExecution.optimizedPlan:
count_mnm_df.explain(True)== Parsed Logical Plan ==
'Sort ['Total DESC NULLS LAST], true
+- Aggregate [State#10, Color#11], [State#10, Color#11, sum(Count#12) AS...]+- Project [State#10, Color#11, Count#12]+- Relation[State#10,Color#11,Count#12] csv== Analyzed Logical Plan ==
State: string, Color: string, Total: bigint
Sort [Total#24L DESC NULLS LAST], true
+- Aggregate [State#10, Color#11], [State#10, Color#11, sum(Count#12) AS...]+- Project [State#10, Color#11, Count#12]+- Relation[State#10,Color#11,Count#12] csv== Optimized Logical Plan ==
Sort [Total#24L DESC NULLS LAST], true
+- Aggregate [State#10, Color#11], [State#10, Color#11, sum(Count#12) AS...]+- Relation[State#10,Color#11,Count#12] csv== Physical Plan ==
*(3) Sort [Total#24L DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(Total#24L DESC NULLS LAST, 200)+- *(2) HashAggregate(keys=[State#10, Color#11], functions=[sum(Count#12)],
output=[State#10, Color#11, Total#24L])+- Exchange hashpartitioning(State#10, Color#11, 200)+- *(1) HashAggregate(keys=[State#10, Color#11],
functions=[partial_sum(Count#12)], output=[State#10, Color#11, count#29L])+- *(1) FileScan csv [State#10,Color#11,Count#12] Batched: false,
Format: CSV, Location:
InMemoryFileIndex[file:/Users/jules/gits/LearningSpark2.0/chapter2/py/src/...
dataset.csv], PartitionFilters: [], PushedFilters: [], ReadSchema:
struct<State:string,Color:string,Count:int>
让我们考虑另一个DataFrame计算示例。下面的Scala代码经历了类似的过程,底层引擎优化了它的逻辑和物理计划:
// In Scala
// Users DataFrame read from a Parquet table
val usersDF = ...
// Events DataFrame read from a Parquet table
val eventsDF = ...
// Join two DataFrames
val joinedDF = users
.join(events, users("id") === events("uid"))
.filter(events("date") > "2015-01-01")
在经过初始分析阶段后,查询计划由Catalyst优化器进行转换和重新排列, 如下图: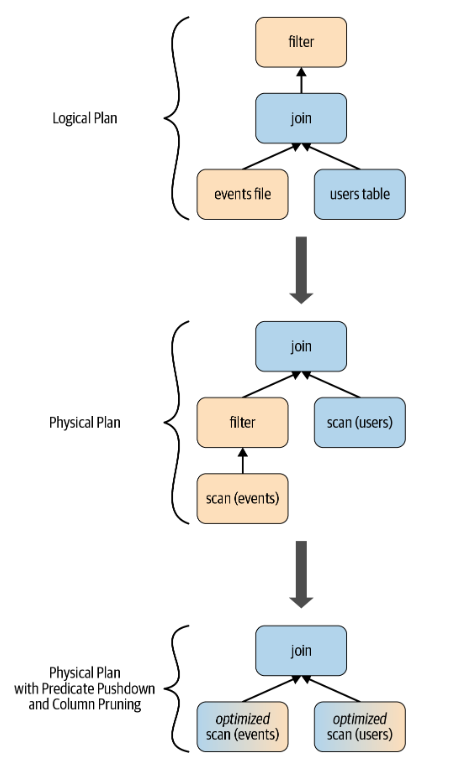
让我们逐一查看四个查询优化阶段。
阶段一:分析
Spark SQL引擎首先为SQL或DataFrame查询生成一个抽象语法树(AST)。在这个初始阶段,任何列或表的名称都将通过查询内部Catalog来解析,Catalog是Spark SQL的编程接口,包含列、数据类型、函数、表、数据库等名称的列表。一旦它们都被成功地解决了,查询就会进入下一个阶段。
阶段二:逻辑优化
该阶段包括两个内部阶段,应用基于标准规则的优化方法,Catalyst优化器将首先构建一组多个计划,然后使用其基于成本的优化器(CBO)为每个计划分配成本。这些计划以操作员树的形式展开,它们可能包括,例如常数折叠、谓词下推、投影剪枝、布尔表达式简化等过程。这个逻辑计划是物理计划的输入。
阶段三:生成物理计划
在此阶段,Spark SQL使用与Spark执行引擎中可用的物理操作符匹配的物理操作符,为所选逻辑计划生成最优物理计划。
阶段四:生成代码
查询优化的最后阶段涉及生成在每台机器上运行的高效Java字节码。由于Spark SQL可以对内存中加载的数据集进行操作,因此Spark可以使用最先进的编译器技术来生成代码以加快执行速度。换句话说,它就像一个编译器。促进整个阶段代码生成的Project Tungsten在这里发挥了作用。
什么是全阶段代码生成?这是一个物理查询优化阶段,它将整个查询压缩为单个函数,消除了虚拟函数调用,并为中间数据使用CPU寄存器。Spark 2.0中引入的第二代Tungsten引擎使用这种方法生成紧凑的RDD代码以供最终执行。这种流线型策略显著提高了CPU效率和性能。
总结
在本文中,我们深入探讨了Spark的结构化api,从Spark结构的历史和优点开始。
通过说明性的常见数据操作和代码示例,我们演示了高级DataFrame和Dataset API比低级RDD API更具表现力和直观性。结构化api旨在简化大型数据集的处理,为常见的数据操作提供特定于领域的操作符,从而提高代码的可读性。
我们根据不同用例场景探讨了何时使用rdd、数据框架和数据集。
最后,我们深入了解了Spark SQL引擎的主要组件——Catalyst优化器和Project tungsten——是如何支持结构化高级api和DSL操作符的。正如你所看到的,无论使用哪种支持Spark的语言,Spark查询都要经历相同的优化过程,从逻辑和物理计划构建到最终的紧凑代码生成。