ImageFolder详解
- 1、数据准备
- 2、ImageFolder类的定义
- transforms.ToTensor()解析
- 3、ImageFolder返回对象
1、数据准备
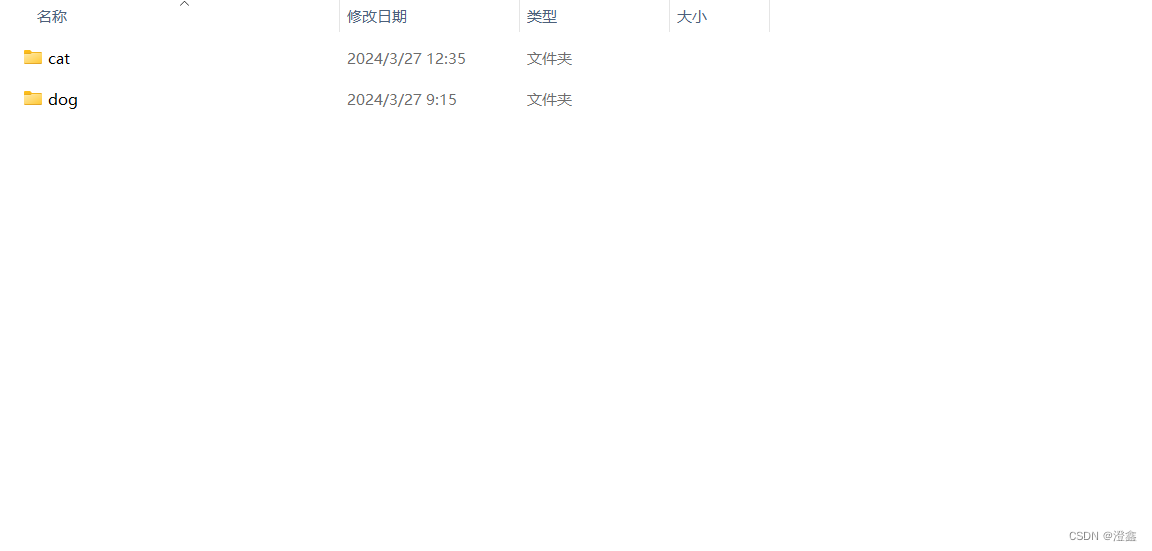
创建一个文件夹,比如叫dataset,将cat和dog文件夹都放在dataset文件夹路径下:
2、ImageFolder类的定义
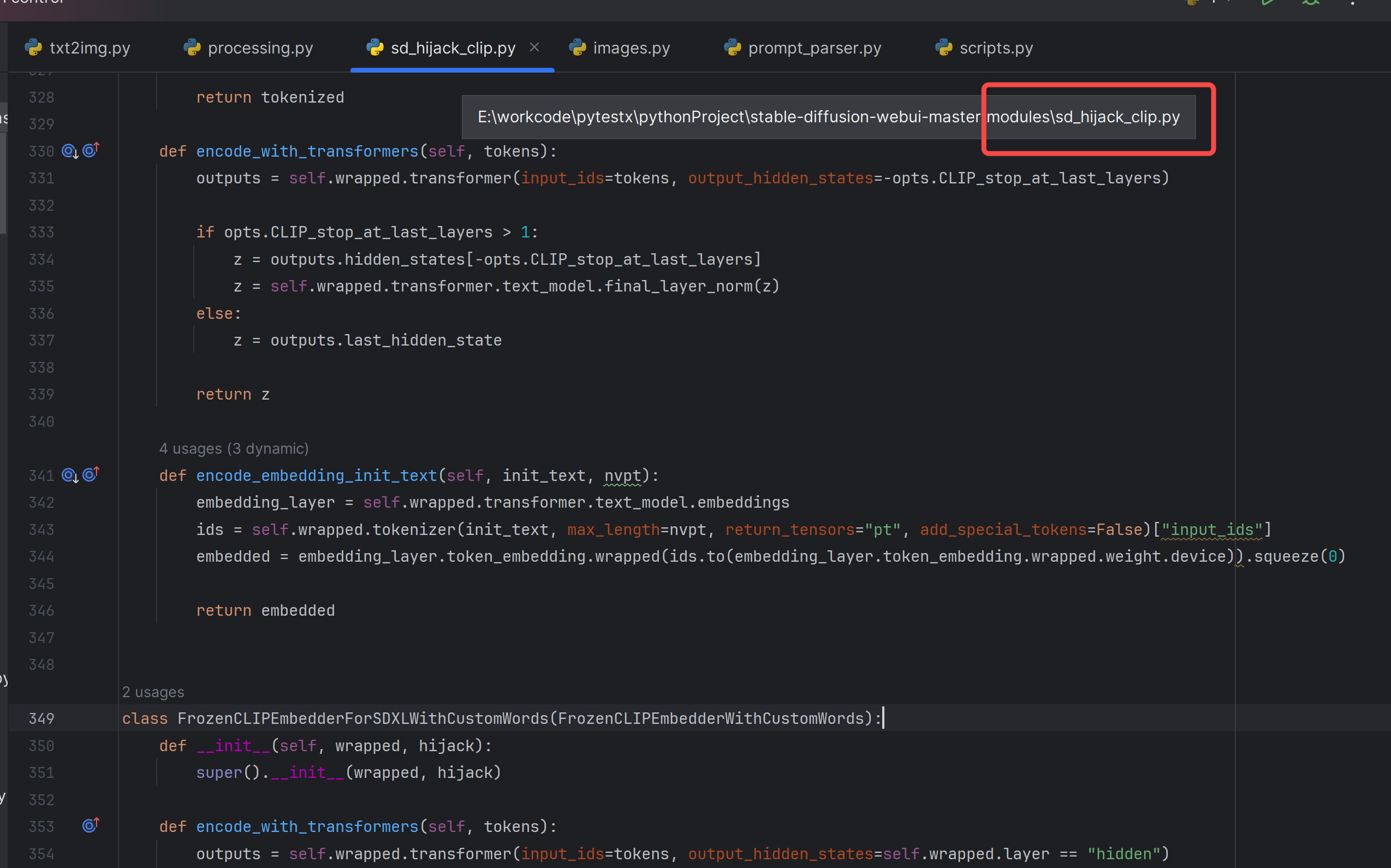
class ImageFolder(DatasetFolder):def __init__(self,root: str,transform: Optional[Callable] = None,target_transform: Optional[Callable] = None,loader: Callable[[str], Any] = default_loader,is_valid_file: Optional[Callable[[str], bool]] = None,):
可以看到,ImageFolder类有这几个参数:
root:图片存储的根目录,即存放不同类别图片文件夹的前一个路径。
transform:即对加载的这些图片进行的前处理的方式,这里可以传入一个实例化的torchvision.Compose()对象,里面包含了各种预处理的操作。
target_transform:对图片类别进行预处理,通常来说不会用到这一步,因此可以直接不传入参数,默认图像标签没有变换,如果需要进行标签的处理,同样可以传入一个实例化的torchvision.Compose()对象。
loader:表示图像数据加载的方式,通常采用默认的加载方式,ImageFolder加载图像的方式为调用PIL库,因此图像的通道顺序是RGB而非opencv的BGR。
is_valid_file:获取图像文件路径的函数,并且可以检查是否有损坏的文件。
示例代码:
ROOT_TEST = 'dataset' #dataset/cat, dataset/dog
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),normalize
])# 加载训练数据集
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)
transforms.ToTensor()解析
这里需要特别说一下ToTensor()这个函数的作用,刚接触深度学习的我那时以为只是单纯的将图像的ndarray和PIL格式转成Tensor格式,后来查看了一下源码之后发现,事情并没有这么简答!
"""Convert a PIL Image or ndarray to tensor and scale the values accordingly.This transform does not support torchscript.Converts a PIL Image or numpy.ndarray (H x W x C) in the range[0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1)or if the numpy.ndarray has dtype = np.uint8In the other cases, tensors are returned without scaling... note::Because the input image is scaled to [0.0, 1.0], this transformation should not be used whentransforming target image masks. See the `references`_ for implementing the transforms for image masks... _references: https://github.com/pytorch/vision/tree/main/references/segmentation"""
这是关于ToTensor()函数的注解,这里明确指出了ToTensor()可以将PIL和ndarray格式的图像数据转成Tensor并缩放它们的值,这里的缩放他们的值的意思在下面也指出了,即将[0, 255]的像素值域归一化[0, 1.0],并且图像转换成Tensor格式之后,维度的顺序也会发生一点变化,从一开始的HWC变成了CHW的排列方式。
3、ImageFolder返回对象
以第一部分为例,我们用一个val_dataset接收了ImageFolder的返回值,那么这个Val_dataset对象里面包含了什么呢:
val_dataset.classes:存放着根目录下的子文件夹的名称(类别名称)的列表。
val_dataset.class_to_idx:存放着类别名称和各自的索引,字典类型。
val_dataset.extensions:存放着ImageFolder可以读取的图像格式名称,元组类型。
val_dataset.targets:存放着根目录下每一张图的类别索引。
val_dataset.transform:我们提供的transform的方式。
val_dataset.imgs:存放着根目录下每一张图的路径和类别索引。元组列表类型。
以上是关于这个ImageFolder返回的对象的属性的解析。
此外,我们可以通过一个for循环来遍历整个val_dataset的所有图像数据,其中val_dataset[i]是一个元组类型的数据,val_dataset[i][0]代表了前处理后的图像数据,类型为tensor,以AlexNet为例,此时的tensor应该是3 * 224 * 224的维度。val_dataset[i][1]代表了图像的类别索引。
完整示例代码:
import torch
from AlexNet import AlexNet
from torch.autograd import Variable
from torchvision import transforms
from torchvision.transforms import ToPILImage
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader# ROOT_TRAIN = 'D:/pycharm/AlexNet/data/train'
ROOT_TEST = 'dataset'# 将图像的像素值归一化到[-1,1]之间
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),normalize
])# 加载训练数据集
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)# 如果有NVIDA显卡,转到GPU训练,否则用CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'# 模型实例化,将模型转到device
model = AlexNet().to(device)# 加载train.py里训练好的模型
model.load_state_dict(torch.load(r'save_model/model_best.pth'))# 结果类型
classes = ["cat","dog"
]# 把Tensor转化为图片,方便可视化
show = ToPILImage()# 进入验证阶段
model.eval()
for i in range(10):x, y = val_dataset[i][0], val_dataset[i][1]# show():显示图片# show(x).show()# torch.unsqueeze(input, dim),input(Tensor):输入张量,dim (int):插入维度的索引,最终扩展张量维度为4维x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=False).to(device)with torch.no_grad():pred = model(x)# argmax(input):返回指定维度最大值的序号# 得到预测类别中最高的那一类,再把最高的这一类对应classes中的那一类predicted, actual = classes[torch.argmax(pred[0])], classes[y]# 输出预测值与真实值print(f'predicted:"{predicted}", actual:"{actual}"')