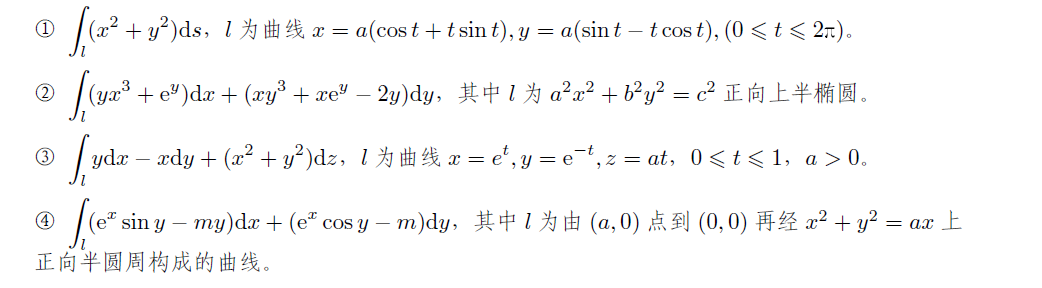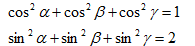目录
- 一、AI时代降临
- 二、AI+OCR与传统OCR技术
- 三、通过人工智能模型生成AI图片技术探索
- 四、提前布局,合合信息AI图像安全技术助力行业健康发展
- 1、识别医疗门诊发票和报告
- 2、图像篡改检测升级,截图篡改检测
- 3、AIGC判别,人脸伪造检测
- 4、OCR对抗攻击
- 五、实现可信AI的工业化应用落地
- 六、总结
大家好,我是哪吒。
一、AI时代降临
去年11月ChatGPT横空出世之后,生成式AI向人们展示出了自己的强大力量,各种大模型如雨后春笋一样涌现,并实现了大规模的商业化。
闲暇之余,我也研究了一番,发现AI在图像处理领域具有许多卓越的优点。其中一项突出的优势是,AI可以快速准确地处理大量的图像数据,大大提高了工作效率。相比传统的人工处理方式,AI可以同时处理多个图像,并在短时间内完成任务。这对于需要处理大规模图像数据的行业,如写博客、电子商务和医学影像等领域,具有极大的意义。
AI在图像处理中可以提供更加准确、精细的结果。通过深度学习和神经网络等技术,AI能够自动学习和识别图像中的特征,从而实现图像内容的分析和理解。这使得AI在人脸识别、图像识别、图像分类等任务中表现出色,并且具有高度的准确性和稳定性。
在本届世界人工智能大会(WAIC 2023)上,中国信通院围绕“多模态基础大模型的可信AI”主题举办了专项论坛。论坛上,合合信息AI图像内容安全技术方案获得广泛关注,合合信息长期聚焦AI+OCR在文档智能领域中的前沿技术探索,"细粒度"视觉差异图像鉴别、证件文档图片信息鉴别、生成式图像判别、文档图像完整性保护等行业焦点议题,通过技术输出、产品服务帮助个人及企业保护图像内容安全。
”AI+OCR”为我们带来了哪些技术上的突破呢?

二、AI+OCR与传统OCR技术
传统OCR技术已经存在了很长时间,但随着AI的发展,AI+OCR技术也逐渐崭露头角。鱼和熊掌不可兼得的道理谁都懂,那么,问题来了,哪一个更好呢?
传统OCR技术主要是基于模板匹配和特征提取的方法来实现字符识别。而AI+OCR则使用深度学习算法,如卷积神经网络(CNN)和循环神经网络(RNN)等。与传统OCR技术相比,AI+OCR可以更好地处理复杂的图像,并且具有更好的自适应能力。
对于单一字体、规则排列的文本,传统OCR技术可以实现非常高的精度。然而,在处理复杂排版的文本时,传统OCR技术可能会出现错误。相比之下,AI+OCR可以更好地处理这些复杂排版文本,并且具有更高的准确性。
传统OCR技术通常比AI+OCR更快,因为它不需要进行大量的训练和学习。然而,在处理复杂场景的文本时,传统OCR技术的速度可能会变慢。相比之下,AI+OCR可以更快地处理这些文本,并且具有更好的灵活性。
传统OCR技术通常适用于单一字体、规则排列的文本。然而,AI+OCR可以处理多种字体、多种语言,并且可以自适应地处理不同场景下的文本。因此,AI+OCR在处理多样化的文本时更加适用。
随着人工智能技术的不断发展,AI+OCR将会成为文档数字化领域的主流技术。未来,AI+OCR将会更加智能、更加自适应,并且可以处理更加复杂的文本。
三、通过人工智能模型生成AI图片技术探索
人工智能模型生成AI图片主要基于深度学习技术和生成对抗网络(GAN)技术。
在深度学习技术中,卷积神经网络(CNN)被广泛应用于图像识别、分类和生成任务中。通过对大量图像数据进行训练,深度学习模型可以学习到图像中的特征和结构,从而能够生成类似的图像。
在生成对抗网络(GAN)技术中,有两个神经网络:生成器和判别器。生成器负责生成图像,而判别器则试图区分生成的图像和真实图像。这两个网络通过互相博弈来不断提升生成器生成逼真图像的能力。
具体而言,生成器会接收一个随机向量或文字描述作为输入,然后通过多层神经网络逐渐将输入转化为图像。生成器的设计是一个关键因素,它需要能够理解输入的语义信息,并将其转化为准确的图像特征。此外,对于文字描述生成图像的应用,通常会使用大规模的训练数据集来学习图像和文字之间的联系,以便在生成过程中根据输入的文字描述生成对应的图像。
人工智能模型生成AI图片的技术仍在不断发展和改进中,但它们的核心基础是深度学习和生成对抗网络技术。
四、提前布局,合合信息AI图像安全技术助力行业健康发展
1、识别医疗门诊发票和报告
通常情况下,人眼能够鉴定出来的伪造图片多具有拼接痕迹、色差,或者字形字体与原图相比有明显的差异,魔高一尺道高一丈,制作出以假乱真的图片绝非难事,因此,采用科技手段进行图片鉴别是防范风险的必要方式。

传统的图像篡改检测方法主要有基于可交换图像文件格式的信息判断,基于图像块的分类方法,手工设计的图像内在特征统计等方法,在面对全局性的裁剪、调色处理,拼接组合、擦除等组合式造假手法时,这些检测方式在覆盖面、精准度层面均存在可提升的空间。
针对现有检测方法的不足,合合信息基于深度学习的图像篡改检测方法,推出了“PS篡改检测”技术,能针对存在人眼几乎不可见的“细粒度”视觉差异的伪造图像进行篡改检测及定位,在身份证检测场景中,篡改检测准确率超99%。
2、图像篡改检测升级,截图篡改检测
在本届世界人工智能大会(WAIC 2023)上,合合信息AI图像检测“黑科技”持续优化升级,去年主要检测在证件、票据等商业材料的PS痕迹,今年升级后的篡改检测技术可检测包括转账记录、聊天记录等截图。
比如给定一张聊天截图,输入到篡改检测模型中,能够判别这张图像是否被篡改过,并且定位出篡改图像的区域。下面这张图,在模型中,被识别为篡改,并通过白色小点,标识出被篡改的位置。

与自然图像、证件照图像识别相比,截图的背景没有纹路和底色,整个截图没有光照差异,难以通过拍照时产生的成像差异进行痕迹判断,现有的视觉模型通常难以充分发掘原始图像和新图像的细粒度差异特征。
为此,合合信息提出了一种基于HRNet的编码器-解码器结构的图像真实性鉴别模型,结合图像本身的信息,包括但不限于噪声、频谱等, 从而捕捉到细粒度的视觉差异,达到高精度鉴别效果。

3、AIGC判别,人脸伪造检测
开年以来,以语言生成类、视觉生成类模式为代表的AIGC产品引发了社会对于图文内容“可信度”问题的讨论。AIGC爆火的背后,生成式AI向人们展示出了自己的强大力量,各种大模型如雨后春笋一样涌现,并实现了大规模的商业化。
那么,怎么才能有效的识别出AI图片和真实图片呢?
这有两个难点,比如生成出来的图像场景繁多,不能穷举,不能通过训练解决;有些生成图和真实图片的相似度过高,很贴近于人类的判断,对于机器而言,真伪判定只会更难。合合信息基于空域与频域关系建模,能够在不用穷举图片的情况下,利用多维度特征来分辨真实图片和生成式图片的细微差异。
模型结构如下图所示:

输入图片后,模型通过多个空间注意力头来关注空间特征,并使用纹理增强模块放大浅层特征中的细微伪影,增强模型对真实人脸和伪造人脸的感知与判断准确度。

4、OCR对抗攻击
有些时候,我们需要将身份证、驾驶证、重要证件图片通过社交媒体发给朋友,或者公司人事,同时我们又不想让这些信息被软件的AI系统识别分析。
合合信息科技已经研制出此项技术,可以既不影响人类的阅读,又可以避免让社交媒体软件对我们的证件图片进行识别分析。

五、实现可信AI的工业化应用落地
可信AI的概念是由何积丰院士2017年在香山科学会议的第36次学术研讨会上首次引入的。是用来解决在人工智能的应用过程中,数据隐私、安全性、公平性等问题而提出的。
可信AI并非新事物,但随着AI的广泛应用和普及,可信AI的重要性逐渐凸显。
要实现可信AI的工业化应用落地,还需要更多行业领先公司承担起责任,借助标准化、开放化的技术手段来统一规范和解决可信AI的问题。合合信息深耕智能文字识别、智能图像处理领域,技术成果获权威机构及市场认可。最近一个月内,公司智能文档处理产品通过中国信通院“可信AI—智能文档处理系统”评估工作,并获得“5级”评定,“5级”为该模块最高评定等级。
合合信息与中国信通院等权威机构一道,携手国内顶尖院校、研究机构及企业,共同探索AI技术在图像领域的可信化落地这一深远命题,助力科技向上的同时向善发展。
六、总结
AI图像内容安全技术正在走进我们的生活,比如文中提到的识别医疗门诊发票和报告、识别聊天记录、文档图像截图篡改,AIGC判别人脸伪造检测、OCR对抗攻击等应用,大大的提高了我们的生活质量,保障了我们的信息安全,提升AI服务的规范性,助力图像产业健康成长,为文档图像内容安全提供保障,助力新时代AI安全体系建设。








![[MIT]微积分重点 第五课 积分总览 学习笔记](https://img-blog.csdnimg.cn/96b2e91429604458941c061ed73d19d6.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rKZ5ryg5LmL6IifdHg=,size_19,color_FFFFFF,t_70,g_se,x_16#pic_center)