概叙
科普文:深入理解ElasticSearch体系结构-CSDN博客
Elasticsearch各版本比较

ElasticSearch 单点安装
1 创建普通用户
#1 创建普通用户名,密码
[root@hlink1 lyz]# useradd lyz
[root@hlink1 lyz]# passwd lyz#2 然后 关闭xshell 重新登录 ip 地址 用 lyz 用户登录#3 为 lyz 用户分配 sudoer 权限
[lyz@hlink1 ~]$ su
[lyz@hlink1 ~]$ vi /etc/sudoers
# 在 root ALL=(ALL) ALL 下面添加普通用户权限lyz ALL=(ALL) ALL2 下载安装 ES
# 4 下载安装包
[lyz@hlink1 ~]$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.2-linux-x86_64.tar.gz
# 5 解压安装包
[lyz@hlink1 ~]$ tar -xzf elasticsearch-7.15.2-linux-x86_64.tar.gz# 6 修改配置
[lyz@hlink1 ~]# cd elasticsearch-7.15.2/config
[lyz@hlink1 elasticsearch-7.15.2]# mkdir log
[lyz@hlink1 elasticsearch-7.15.2]# mkdir data
[lyz@hlink1 elasticsearch-7.15.2]# cd config
[lyz@hlink1 config]# rm -rf elasticsearch.yml
[lyz@hlink1 config]# vim elasticsearch.yml# 粘贴如下内容# 配置集群名称,保证每个节点的名称相同,如此就能都处于一个集群之内了
cluster.name: lyz-es
# # 每一个节点的名称,必须不一样
node.name: hlink1
path.data: /home/lyz/elasticsearch-7.15.2/log
path.logs: /home/lyz/elasticsearch-7.15.2/data
network.host: 0.0.0.0
# # http端口(使用默认即可)
http.port: 9200
# # 集群列表,你es集群的ip地址列表
discovery.seed_hosts: ["hlink1"]
# # 启动的时候使用一个master节点
cluster.initial_master_nodes: ["hlink1"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"3 修改 jvm.option
修改 jvm.option 配置文件,调整 jvm 堆内存大小,每个人根据自己服务器的内存大小来进行调整
# 7 修改 jvm.option 配置文件
[lyz@hlink1 config]# vim jvm.options
-Xms2g
-Xmx2g4 修改系统配置,解决启动问题
由于使用普通用户来安装 es 服务,且 es 服务对服务器的资源要求比较多,包括内存大小,线程数等。所以我们需要给普通用户解开资源的束缚
ES 因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux 系统当中打开文件最大数目的限制,不然 ES 启动就会抛错
进入 Root 用户
# 8 进入 root 用户
[lyz@hlink1 config]# su
Password:# 9 在最下面添加如下内容: 注意*不要去掉了
[root@hlink1 config]# sudo vim /etc/security/limits.conf* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 40965 普通用户启动线程数限制
修改普通用户可以创建的最大线程数
10 若为 Centos7,执行下面的命令
[root@hlink1 config]# sudo vim /etc/security/limits.d/20-nproc.conf# 找到如下内容:
* soft nproc 1024#修改为
* soft nproc 40966 普通用户调大虚拟内存
# 11 调大系统的虚拟内存
[root@hlink1 config]# vim /etc/sysctl.confvm.max_map_count=262144# 12 执行 sysctl -p
# 行完了 sysctl -p 若输出的结果和你配置的一样,说明配置成功了.
[root@hlink1 config]# sysctl -p
vm.max_map_count = 2621447 启动 ES 服务
# 13 切换用户
[root@hlink1 config]# exit
exit
[lyz@hlink1 config]$# 直接启动 es 或者 后台启动 es
[lyz@hlink1 config]$ cd ..
[lyz@hlink1 elasticsearch-7.15.2]$ cd bin
# 直接启动
[lyz@hlink1 bin]$ ./elasticsearch
# 后台启动 nohup ./elasticsearch 2>&1 &# 浏览器访问 http://hlink1:9200/?pretty
Elasticsearch集群搭建
一、环境配置
一主亮从;3节点
角色 IP地址 操作系统
master 99.99.10.30 CentOS Linux release 7.9.2009 (Core)
slave 99.99.10.31 CentOS Linux release 7.9.2009 (Core)
slave 99.99.10.32 CentOS Linux release 7.9.2009 (Core)# Elasticsearch 不能以 root 用户运行,创建一个新用户并赋予适当权限。
sudo adduser es
sudo passwd 123456
sudo usermod -aG sudo es
# 调整 vm.max_map_count 参数,以满足 Elasticsearch 的需求。
sudo sysctl -w vm.max_map_count=262144
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
# 增加文件描述符限制。
sudo echo "elasticsearch - nofile 65535" | sudo tee -a /etc/security/limits.conf
sudo echo "elasticsearch - nproc 4096" | sudo tee -a /etc/security/limits.conf
# 调整内存锁定:
sudo echo "elasticsearch soft memlock unlimited" | sudo tee -a /etc/security/limits.conf
sudo echo "elasticsearch hard memlock unlimited" | sudo tee -a /etc/security/limits.conf
# 安装java
sudo yum install java-11-openjdk-devel -y
# 配置 JAVA_HOME 环境变量(在.bash_profile 文件,添加以下内容)
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk
export PATH=$JAVA_HOME/bin:$PATH
# 然后重新加载配置:
source ~/.bashrc
#检查Java版本
java -version
openjdk version "11.0.23" 2024-04-16 LTS
OpenJDK Runtime Environment (Red_Hat-11.0.23.0.9-2.el7_9) (build 11.0.23+9-LTS)
OpenJDK 64-Bit Server VM (Red_Hat-11.0.23.0.9-2.el7_9) (build 11.0.23+9-LTS, mixed mode, sharing)
二、安装elasticsearch
es官方下载地址,es和kibana尽量下载同一版本
elasticsearch各版本下载地址
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
kibana (es的可视化管理工具)
https://www.elastic.co/cn/downloads/past-releases/#kibana
# 解压elasticsearch包到/usr/local/下面:
tar -zxvf elasticsearch-7.10.0-linux-x86_64.tar.gz -C /usr/local/
#将elasticsearch-7.10.0重命名为es
cd /usr/local/
mv elasticsearch-7.10.0 es
# 这个文件夹用于存储 Elasticsearch 的数据,它将所有的索引数据和相关元数据存储在这个目录中
mkdir -p /data/elasticsearch_data/data
# 这个文件夹用于存储 Elasticsearch 的日志文件,记录了 Elasticsearch 的运行状态、错误信息和性能指标。
mkdir -p /data/elasticsearch_data/logs
sudo chown -R es:es /data/elasticsearch_data
sudo chmod -R 755 /data/elasticsearch_data
# 这个文件夹用于存储 Elasticsearch 的备份数据。
mkdir -p /opt/backup/es
mkdir -p /opt/backup/es1
sudo chown -R es:es /opt/backup/
sudo chmod -R 755 /opt/backup/
三、配置elasticsearch
1.先搭建单个节点,再复制到其他节点:
path.data: /opt/data
path.logs: /opt/logs#http访问端口,程序或kibana使用
http.port: 9200xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
# 尝试启动
./bin/elasticsearch
设置安全账号信息(ES要启动状态):执行以下命令,给各账号设置密码(演示使用的密码都为:123456), 整个集群只需要设置一次即可警告:设置账户密码切记要在单实例非集群模式时配置,不能添加任何集群的配置,否则会设置失败./bin/elasticsearch-setup-passwords interactive
2.集群配置:
cluster.name: elasticsearchnode.name: node1path.data: /data/elasticsearch_data/datapath.logs: /data/elasticsearch_data/logs#数据备份和恢复使用,可以一到多个目录
path.repo: ["/opt/backup/es", "/opt/backup/es1"]http.port: 9200#是否可以参与选举主节点
node.master: true#是否是数据节点
node.data: true#允许访问的ip,4个0的话则允许任何ip进行访问
network.host: 0.0.0.0#es各节点通信端口
transport.tcp.port: 9300#集群每个节点IP地址。
discovery.seed_hosts: ["99.99.10.30:9300", "99.99.10.31:9300", "99.99.10.32:9300"]#es7.x新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]#配置是否压缩tcp传输时的数据,默认为false,不压缩
transport.tcp.compress: true# 是否支持跨域,es-header插件使用
http.cors.enabled: true# *表示支持所有域名跨域访问
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Type,Content-Length#集群模式开启安全 https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.keystore.password: "123456"
xpack.security.transport.ssl.truststore.password: "123456"#默认为1s,指定了节点互相ping的时间间隔。
discovery.zen.fd.ping_interval: 1s#默认为30s,指定了节点发送ping信息后等待响应的时间,超过此时间则认为对方节点无响应。
discovery.zen.fd.ping_timeout: 30s#ping失败后重试次数,超过此次数则认为对方节点已停止工作。
discovery.zen.fd.ping_retries: 3
四、复制elasticsearch到其他节点
scp -r /usr/local/es/ root@99.99.10.31:/usr/local/
scp -r /usr/local/es/ root@99.99.10.32:/usr/local/sudo chown -R es:es /usr/local/es/
sudo chmod -R 755 /usr/local/es/五、测试elasticsearch集群
集群信息查看
# 切换到es用户
su es# 启动es
cd /usr/local/es/
./bin/elasticsearch# 查看集群信息
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cluster/health?pretty"
{"cluster_name" : "elasticsearch","status" : "green","timed_out" : false,"number_of_nodes" : 3,"number_of_data_nodes" : 3,"active_primary_shards" : 1,"active_shards" : 2,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
这个 JSON 响应显示了 Elasticsearch 集群的健康状态及其一些关键指标。指标解读如下:集群基本信息
cluster_name: "elasticsearch"
集群的名称。这是你在 elasticsearch.yml 配置文件中指定的名称。
集群健康状态
status: "green"
集群的健康状态。可能的状态有三种:
green: 所有主分片和副本分片都是可用的。
yellow: 所有主分片都是可用的,但有一些副本分片不可用。
red: 有一些主分片不可用。
timed_out: false
表示查询是否超时。false 表示查询在规定时间内完成。节点和分片信息
number_of_nodes: 3
集群中的节点总数。这里表示集群中有 3 个节点。
number_of_data_nodes: 3
集群中的数据节点总数。数据节点存储数据并处理搜索请求。这里表示所有 3 个节点都是数据节点。分片状态
active_primary_shards: 1
当前活动的主分片数量。主分片是实际存储数据的分片。
active_shards: 2
当前活动的总分片数量,包括主分片和副本分片。这里有 1 个主分片和 1 个副本分片。
relocating_shards: 0
正在重新分配的分片数量。重新分配是指将分片从一个节点移动到另一个节点。
initializing_shards: 0
正在初始化的分片数量。这些分片正在被分配和恢复。
unassigned_shards: 0
未分配的分片数量。可能是因为没有足够的节点来分配这些分片。
delayed_unassigned_shards: 0
延迟分配的未分配分片数量。这些分片被延迟分配,通常是因为某些节点暂时不可用。任务和队列信息
number_of_pending_tasks: 0
当前待处理的任务数量。任务可以是索引刷新、分片移动等。
number_of_in_flight_fetch: 0
当前正在获取的分片数量。通常是在执行搜索请求时从不同的分片获取数据。
task_max_waiting_in_queue_millis: 0
当前任务队列中等待时间最长的任务的等待时间(毫秒)。这里表示没有任务在队列中等待。活动分片百分比
active_shards_percent_as_number: 100.0
当前活动分片占所有分片的百分比。100% 表示所有分片都是活动的,没有分片是未分配的或初始化中的。创建索引验证
# 创建一个索引看集群中每个节点索引数据
curl -XPUT -u elastic:123456 "http://127.0.0.1:9200/test-index"curl -XGET -u elastic:123456 "http://localhost:9200/_cat/indices?pretty"
green open test-index _hNfQpNqTZWAsPKrqa51XA 1 1 0 0 416b 208b
green open .security-7 L6YSY_F0Sl207ijttvv4CQ 1 1 7 0 51.5kb 25.7kb
六、安装kibana和es-header插件:(可选)
# 下载kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.10.0-linux-x86_64.tar.gz# 解压到/usr/local/,并重命名为kibana
tar -zxvf kibana-7.10.0-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local/
mv kibana-7.10.0-linux-x86_64/ kibana# 配置kibana,并加入下面的配置
vim /usr/local/kibana/config/kibana.yml
--------------------------------------
#设置为中文
i18n.locale: "zh-CN"
#允许其它IP可以访问
server.host: "0.0.0.0"
elasticsearch.username: "kibana_system"
elasticsearch.password: "elastic123"
#es集群地址,填写真实的节点地址
elasticsearch.hosts: ["http://xxx.xx.xx.xx:9200","http://xxx.xx.xx.xx:9200","http://xxx.xx.xx.xx:9200"]
--------------------------------------# 启动kibana
cd /usr/local/kibana/
./bin/kibana
es-head安装如下面的官方文档所示:
https://github.com/mobz/elasticsearch-head
七、Elasticsearch如何合理的设置分片:
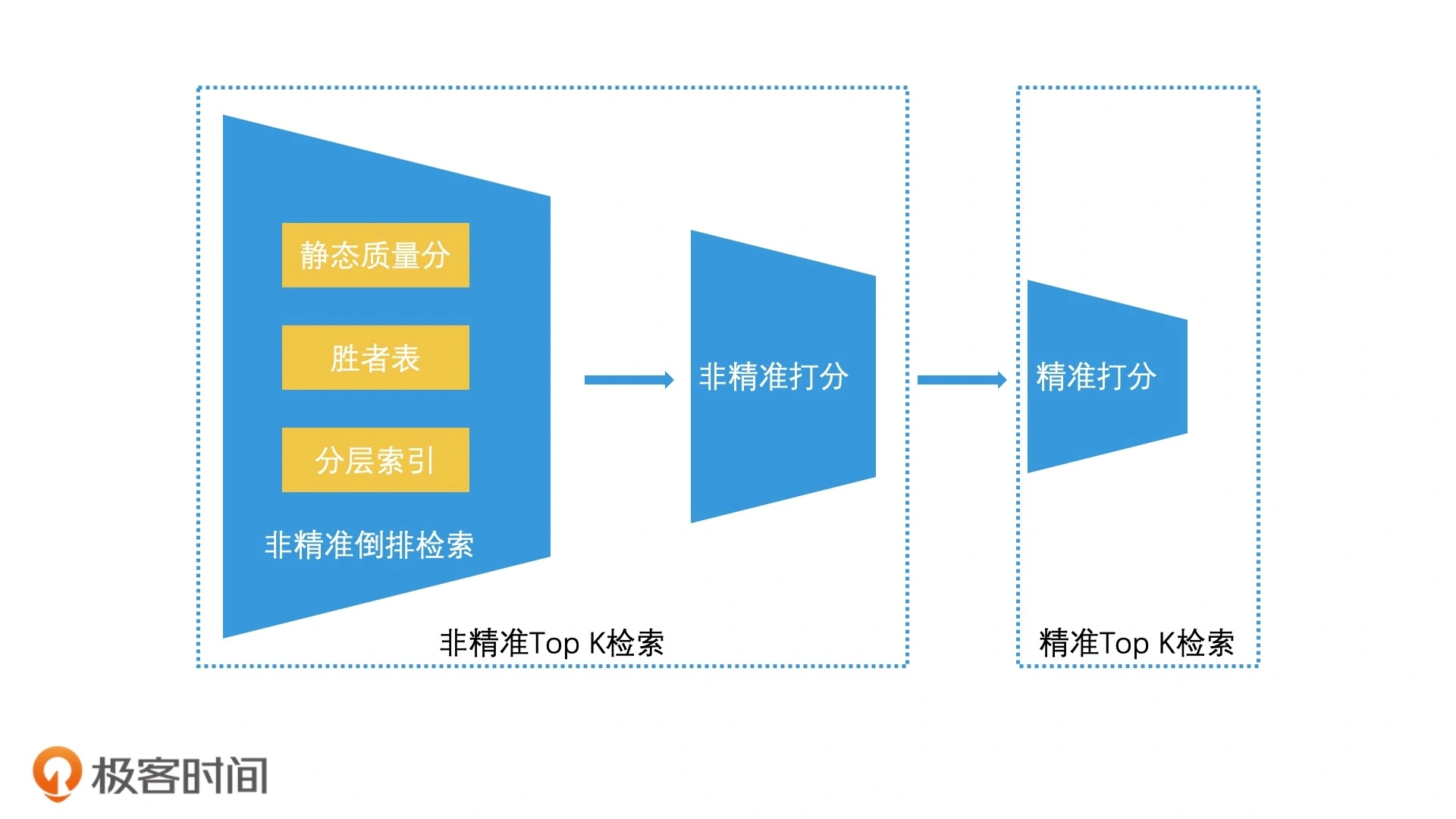
科普文:深入理解ElasticSearch体系结构-CSDN博客
一、什么是分片
在 Elasticsearch 中,索引是由一个或多个分片组成的。每个分片是一个完整的 Lucene 索引,独立存储数据并执行搜索操作。通过分片,Elasticsearch 可以将数据分布到多个节点上,从而提高系统的吞吐量和容错能力。
二、分片的类型
主分片(Primary Shard):
- 每个索引默认包含的分片。
- 数据首先写入主分片,然后再复制到副本分片。
- 主分片的数量在索引创建时确定,之后不能更改。
副本分片(Replica Shard):
- 主分片的副本,用于提高数据的高可用性和搜索性能。
- 默认情况下,每个主分片有一份副本分片。
- 可以动态调整副本的数量。
三、分片的工作原理
数据分布:当你向 Elasticsearch 索引文档时,Elasticsearch 会根据文档的 ID 计算一个哈希值,并根据这个哈希值决定将文档存储到哪个主分片。这种方式确保了文档在主分片间的均匀分布。
数据存储:当你向 Elasticsearch 索引文档时,Elasticsearch 会根据文档的 ID 计算一个哈希值,并根据这个哈希值决定将文档存储到哪个主分片。这种方式确保了文档在主分片间的均匀分布。
数据存储:每个分片是一个独立的 Lucene 索引,包含多个倒排索引。这些倒排索引用于高效的全文搜索。分片将文档分成多个段(segment),每个段是一个不可变的索引文件。随着文档的添加,新的段会不断创建,旧的段会被合并以优化性能和存储空间。
数据副本:副本分片存储在不同的节点上,以防止单点故障。如果一个主分片节点故障,Elasticsearch 可以将副本分片升级为主分片,并继续提供服务。副本分片不仅用于故障恢复,还可以分担搜索请求的负载,从而提高查询性能。
请求处理
写请求(Indexing Request):
- 写请求首先发送到主分片。
- 主分片将数据写入自身,然后将数据复制到对应的副本分片。
- 所有分片都成功写入后,返回确认响应。
读请求(Search Request):
- 读请求可以发送到任意一个副本分片,包括主分片。
- 通过这种方式,读请求可以被均衡地分配到所有分片,提高查询性能。
四、分片的优点
水平扩展:通过增加分片和节点,可以轻松扩展 Elasticsearch 集群以处理更多数据和更高的查询负载。
高可用性:通过副本分片,Elasticsearch 提供了数据冗余,确保在节点故障时数据不会丢失。
高性能:分片使得搜索和索引请求可以并行处理,提高了系统的吞吐量。
五、分片如何设置
分片的官方建议:我在 Elasticsearch 集群内应该设置多少个分片? | Elastic Blog
1、分片过小会导致段过小,进而致使开销增加。您要尽量将分片的平均大小控制在至少几 GB 到几十 GB 之间。
对时序型数据用例而言,分片大小通常介于 20GB 至 40GB 之间。
2、由于单个分片的开销取决于段数量和段大小,所以通过 forcemerge 操作强制将
较小的段合并为较大的段能够减少开销并改善查询性能。理想状况下,
应当在索引内再无数据写入时完成此操作。请注意:这是一个极其耗费资源的操作,
所以应该在非高峰时段进行。
3、每个节点上可以存储的分片数量与可用的堆内存大小成正比关系,但是 Elasticsearch并未
强制规定固定限值。这里有一个很好的经验法则:确保对于节点上已配置的每个 GB,将分片数量
保持在 20 以下。如果某个节点拥有 30GB 的堆内存,那其最多可有 600 个分片,但是在此限值范围内,您设置的分片数量越少,效果就越好。一般而言,这可以帮助集群保持良好的运行状态。
(编者按:从 8.3 版开始,我们大幅减小了每个分片的堆使用量,
因此对本博文中的经验法则也进行了相应更新。请按照以下提示了解 8.3+ 版本的
Elasticsearch。)
在网上总结的:
每个分片的数据量不超过最大JVM堆空间设置,一般不超过32G。如果一个索引大概500G,那分片大概在16个左右比较合适。
单个索引分片个数一般不超过节点数的3倍,推荐是1.5 ~ 3倍之间。假如一个集群3个节点,根据索引数据量大小分片数在5-9之间比较合适。
主分片、副本和节点数,分配时也可以参考以下关系:节点数<= 主分片数 * (副本数 +1 )
创建索引时指定分片数量:
PUT /my_index
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
Elasticsearch常用操作命令:
# es启动:./bin/elasticsearch# 访问地址:http://localhost:9200/ 默认9200端口# Kibana 启动:./bin/Kibana# 访问地址:http://localhost:5600/ 默认5600端口
# 查看集群状态
# 检查集群运行情况:
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/health?v"# 查看集群节点列表:
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/nodes"# 查看所有索引:
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/indices?v"
# 索引操作API
# 1.查询查看分片状态-Authorization方式(postman通过账密获取token)
curl -XGET ‘http://127.0.0.1:9200/_cluster/allocation/explain?pretty’ --header ‘Authorization’: Basic ZWxhc3RpYzphcDIwcE9QUzIw’# 2.查询查看分片状态-账密方式
curl -XGET -u elastic "http://127.0.0.1:9200/_cluster/allocation/explain?pretty" -H ‘Content-Type:application/json’# 3.查询集群状态命令
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cluster/health?pretty"# 4.查询Es全局状态
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cluster/stats?pretty"# 5.查询集群设置
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cluster/settings?pretty"# 6.查询集群文档总数
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/count?v"# 7.查看当前集群索引分片信息
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/shards?v"# 8.查看集群实例存储详细信息
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/allocation?v"# 9.查看当前集群的所有实例
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/nodes?v"# 10.查看当前集群等待任务
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/pending_tasks?v"# 11.查看集群查询线程池任务
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/thread_pool/search?v"# 12.查看集群写入线程池任务
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/thread_pool/bulk?v"# 13.清理ES所有缓存
curl -XPOST "http://127.0.0.1:9200/_cache/clear"# 14.查询索引信息
curl -XGET -u : ‘https://127.0.0.1:9200/licence_info_test?pretty’# 15.关闭索引
curl -XGET -u : ‘https://127.0.0.1:9200/my_index/_close?pretty’# 16.打开索引
curl -XGET -u : ‘https://127.0.0.1:9200/my_index/_open?pretty’01 ES索引搜索查询(MySQL和ES对比)

简单梳理了一下ES JavaAPI的相关体系,感兴趣的可以自己研读一下源码。


02 词条查询
所谓词条查询,也就是ES不会对查询条件进行分词处理,只有当词条和查询字符串完全匹配时,才会被查询到。
2.1 等值查询-term
等值查询,即筛选出一个字段等于特定值的所有记录。
SQL:
| 1 |
|
而使用ES查询语句却很不一样(注意查询字段带上keyword):
| 1 2 3 4 5 6 7 8 9 10 11 |
|
ElasticSearch 5.0以后,string类型有重大变更,移除了string类型,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索。
查询结果:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
Java 中构造 ES 请求的方式:(后续例子中只保留 SearchSourceBuilder 的构建语句)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
仔细观察查询结果,会发现ES查询结果中会带有_score这一项,ES会根据结果匹配程度进行评分。打分是会耗费性能的,如果确认自己的查询不需要评分,就设置查询语句关闭评分:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
Java构建查询语句:
| 1 2 3 |
|
2.2 多值查询-terms
多条件查询类似 Mysql 里的IN 查询,例如:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
Java 实现:
| 1 2 3 4 |
|
2.3 范围查询-range
范围查询,即查询某字段在特定区间的记录。
SQL:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
Java构建查询条件:
| 1 2 3 4 |
|
2.4 前缀查询-prefix
前缀查询类似于SQL中的模糊查询。
SQL:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 |
|
Java构建查询条件:
| 1 2 3 4 |
|
2.5 通配符查询-wildcard
通配符查询,与前缀查询类似,都属于模糊查询的范畴,但通配符显然功能更强。
SQL:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 |
|
Java构建查询条件:
| 1 2 3 |
|
03 负责查询
前面的例子都是单个条件查询,在实际应用中,我们很有可能会过滤多个值或字段。先看一个简单的例子:
| 1 |
|
这样的多条件等值查询,就要借用到组合过滤器了,其查询语句是:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
Java构造查询语句:
| 1 2 3 4 5 6 |
|
3.1 布尔查询
布尔过滤器(bool filter)属于复合过滤器(compound filter)的一种 ,可以接受多个其他过滤器作为参数,并将这些过滤器结合成各式各样的布尔(逻辑)组合。
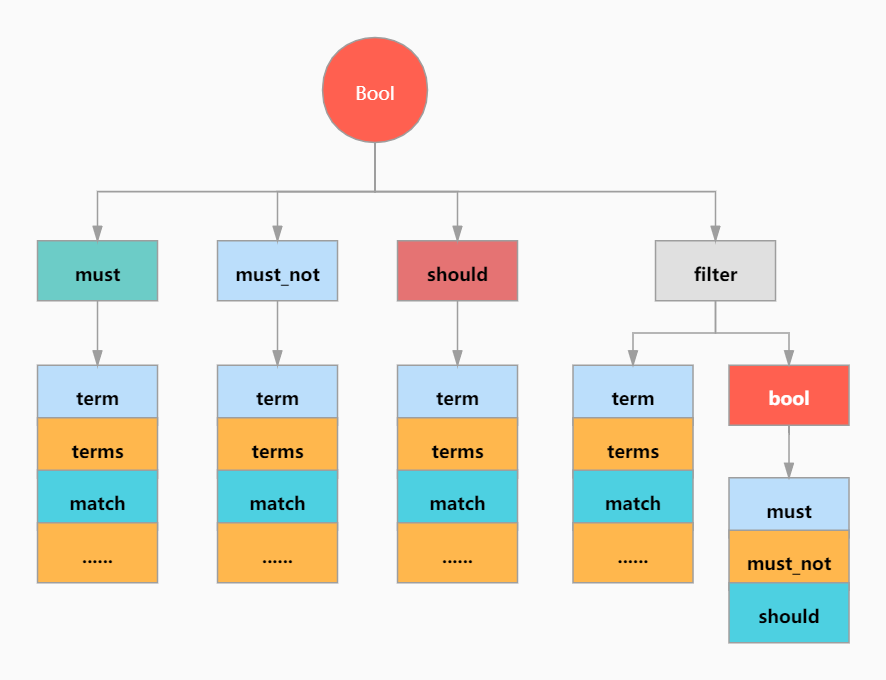
bool 过滤器下可以有4种子条件,可以任选其中任意一个或多个。filter是比较特殊的,这里先不说。
| 1 2 3 4 5 6 7 |
|
- must:所有的语句都必须匹配,与 ‘=’ 等价。
- must_not:所有的语句都不能匹配,与 ‘!=’ 或 not in 等价。
- should:至少有n个语句要匹配,n由参数控制。
精度控制:
所有 must 语句必须匹配,所有 must_not 语句都必须不匹配,但有多少 should 语句应该匹配呢?默认情况下,没有 should 语句是必须匹配的,只有一个例外:那就是当没有 must 语句的时候,至少有一个 should 语句必须匹配。
我们可以通过 minimum_should_match 参数控制需要匹配的 should 语句的数量,它既可以是一个绝对的数字,又可以是个百分比:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
Java构建查询语句:
| 1 2 3 4 5 6 7 8 |
|
最后,看一个复杂些的例子,将bool的各子句联合使用:
| 1 |
|
用 Elasticsearch 来表示上面的 SQL 例子:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
|
用Java构建这个查询条件:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
3.2 Filter查询
query和filter的区别:query查询的时候,会先比较查询条件,然后计算分值,最后返回文档结果;而filter是先判断是否满足查询条件,如果不满足会缓存查询结果(记录该文档不满足结果),满足的话,就直接缓存结果,filter不会对结果进行评分,能够提高查询效率。
filter的使用方式比较多样,下面用几个例子演示一下。
方式一,单独使用:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
单独使用时,filter与must基本一样,不同的是filter不计算评分,效率更高。
Java构建查询语句:
| 1 2 3 4 5 |
|
方式二,和must、must_not同级,相当于子查询:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
Java:
| 1 2 3 4 5 6 |
|
方式三,将must、must_not置于filter下,这种方式是最常用的:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
|
Java:
| 1 2 3 4 5 6 7 8 |
|
04 聚合查询
接下来,我们将用一些案例演示ES聚合查询。
4.1 最值、平均值、求和
案例:查询最大年龄、最小年龄、平均年龄。
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 |
|
Java:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
使用聚合查询,结果中默认只会返回10条文档数据(当然我们关心的是聚合的结果,而非文档)。返回多少条数据可以自主控制:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
而Java中只需增加下面一条语句即可:
| 1 |
|
与max类似,其他统计查询也很简单:
| 1 2 3 4 |
|
4.2 去重查询
案例:查询一共有多少个门派。
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 |
|
Java:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
4.3 分组聚合
4.3.1 单条件分组
案例:查询每个门派的人数
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
Java:
| 1 2 3 4 5 6 |
|
4.3.2 多条件分组
案例:查询每个门派各有多少个男性和女性
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
4.4 过滤聚合
前面所有聚合的例子请求都省略了 query ,整个请求只不过是一个聚合。这意味着我们对全部数据进行了聚合,但现实应用中,我们常常对特定范围的数据进行聚合,例如下例。
案例:查询明教中的最大年龄。这涉及到聚合与条件查询一起使用。
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
Java:
| 1 2 3 4 5 6 7 |
|
另外还有一些更复杂的查询例子。
案例:查询0-20,21-40,41-60,61以上的各有多少人。
SQL:
| 1 2 3 4 5 6 7 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
查询结果:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|






![[FBCTF2019]RCEService (PCRE回溯绕过和%a0换行绕过)](https://i-blog.csdnimg.cn/direct/ed5f04508d4041af82c9770d26abed10.png)