关于语音会议的大概设计草图如下:

根据流程图可以看出,我一共分了六个模块分别命名为:
- A_preprocessor(预处理器):用来对音频进行预处理
- A_file_store(文件存储):用来管理录音的文件以及记录的文件
- A_recognizer(识别器):用来进行识别说话人是谁
- A_recorder(录音器):用来获取音频文件
- A_translator(翻译器):用来将录音转化为文字记录
- A_windows(窗口):与用户交互,对该系统进行各种命令操作
下面为每个模块主要使用的python第三方库
- A_preprocessor(预处理器):librosa、wave
- A_file_store(文件存储):shutil、functools
- A_recognizer(识别器):tensorflow
- A_recorder(录音器):puaudio
- A_translator(翻译器):tensorflow
- A_windows(窗口):pyqt5
当然这些只不过是主要使用的,其中应该还有其他的工具类的第三方库需要使用,只不过现在还不清楚都需要哪些,由于技术有限,只有等到真正编码的时候才会知道
可以看出,这里最主要的两个模块就是识别器和翻译器,也是最难的,想要实现准确识别说话人并且可以将语音转化成文字这两个功能,对我来说还是比较困难的,单靠我自己一个人想,肯定是不行的,这里我主要参考了两位大佬的代码
第一个大佬是AI柠檬开发的基于深度学习的中文语音识别系统,参考这个应用到翻译器中我想应该不成问题。
第二个大佬是夜雨飘零开发的基于Tensorflow实现简单的声纹识别模型,参考这个应用到识别器中。
窗口模块已经使用Qt designer开发完成,主要效果如下
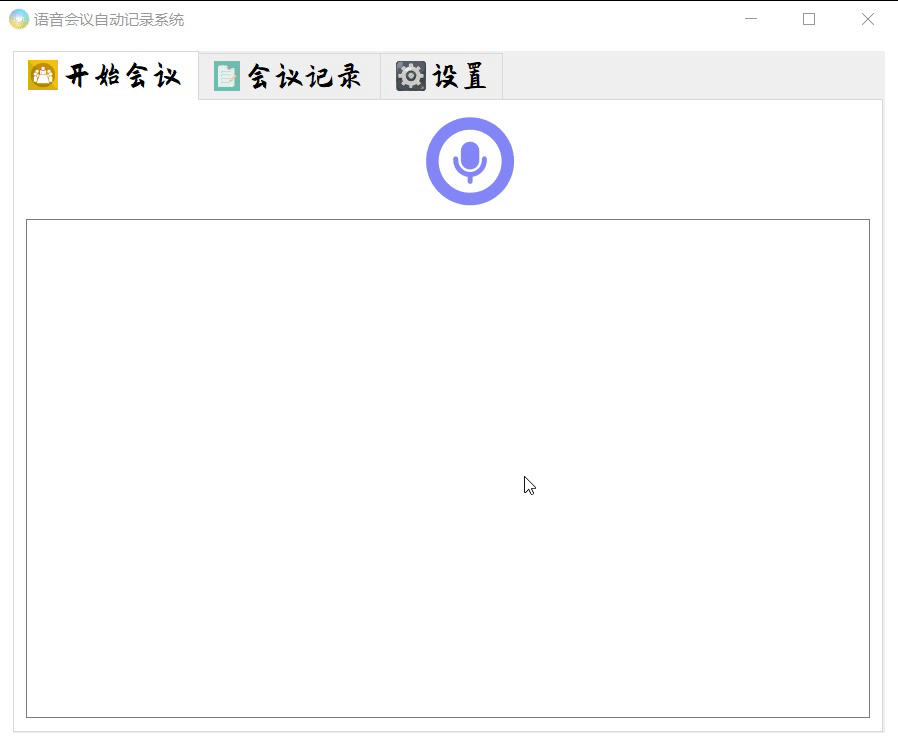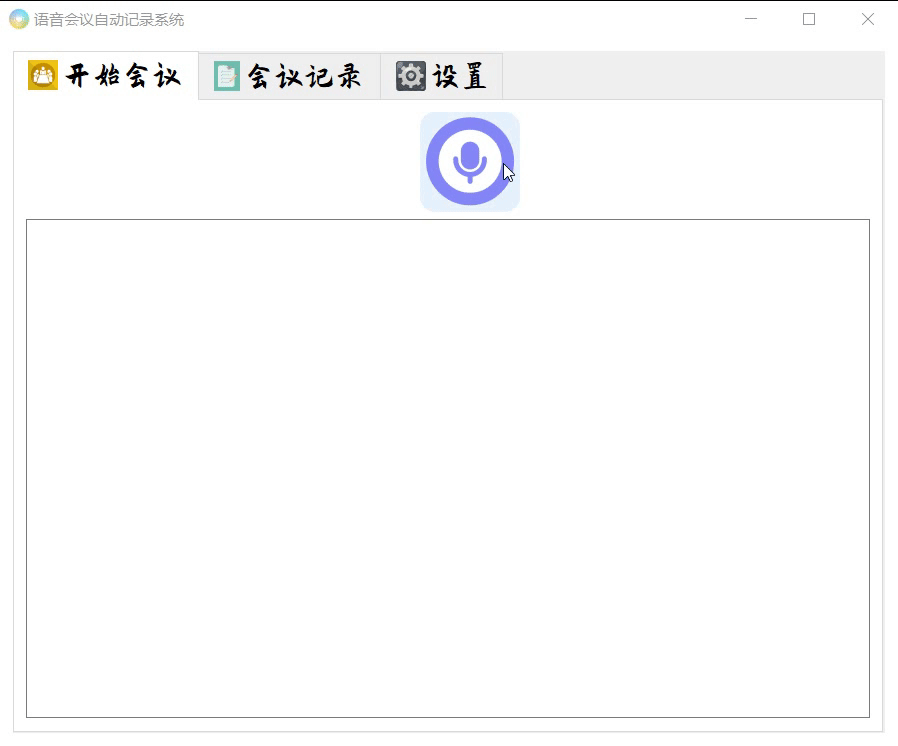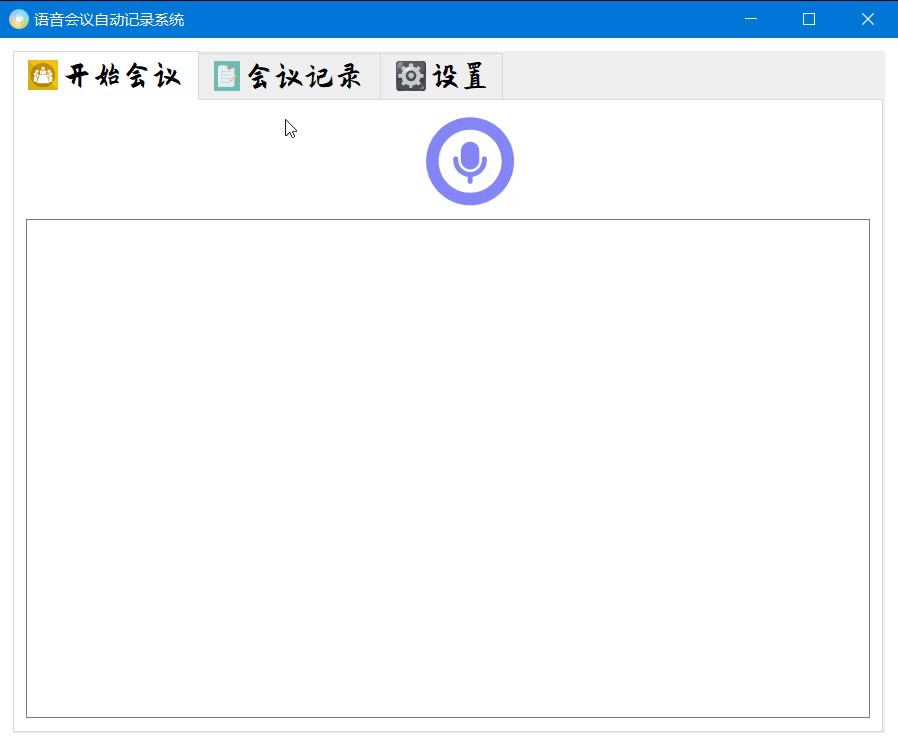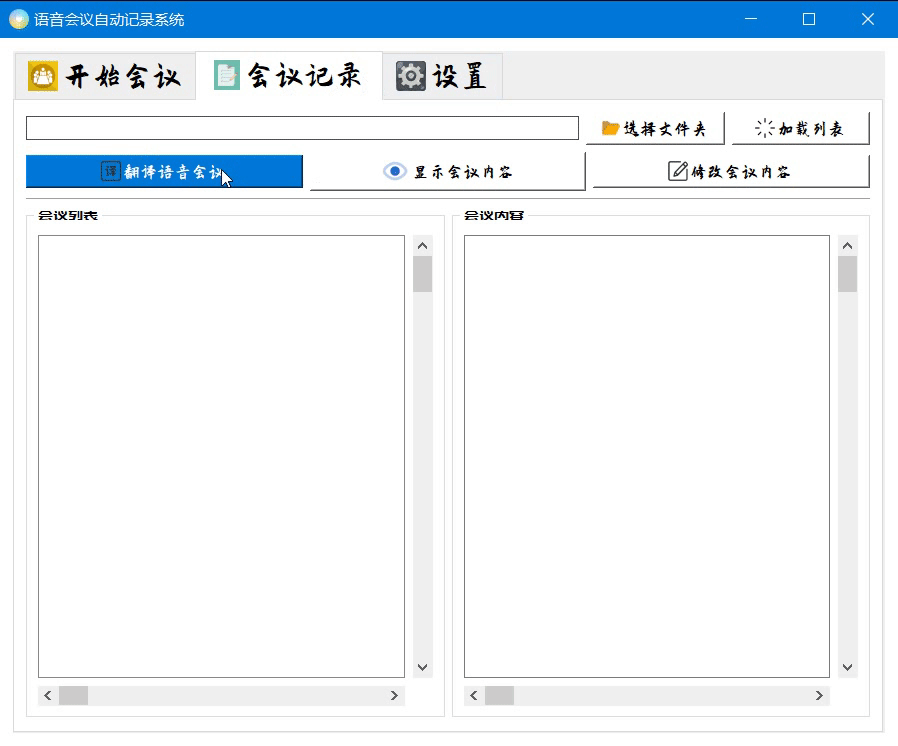
目前的开发进程就是到这里了,还没有一个详细的开发流程,后面的打算就是先理解两位大佬的源码,然后结合他们的源码做出我自己的东西,这里再次感谢两位大佬的源码分享,万分感谢!
这就是我目前的思路,如果有不对的或者不好的,欢迎各位大佬能够指点迷津。