文章目录
- 任务介绍
- 数据来源及预处理
- Unet实现过程中遇到的bug
任务介绍
本项目是基于Unet网络对心肌图像进行心池和心肌分割。写这篇博客为了记录下我在写模型时遇到的bug和思考,我发现好像没有一篇从头到尾的笔记,我作为小白真的遇到了很多大坑,所以写写我建模的整个过程。一把辛酸泪www
如果碰巧你也遇到了这些bug,希望我的方法能帮助你呀。
最后贴上全部代码:GitHub

数据来源及预处理
- 数据介绍
数据为45位病人LGE MRI图像,数据格式为nii.gz。随机抽选9张图像为训练集,validation dataset比例为10%。
1)先将3Dnii.gz图像转换成2D切片
nii.gz是医学图像常用的格式。可以通过SimpleITK库处理。
将3D图像转成2D切片的思路很简单,因为是按列表存储将一张张2D切片存储成3D图像的。
完整代码过长,具体见GitHub
def load_img(path):img = sitk.ReadImage(path)data = sitk.GetArrayFromImage(img)return data
def clip_img(img,path):for i in range(img.shape[0])clip = img[i]clip = clip[0:240,0:240]clip_file = os.path.join(IMAGE_PATH,path+str(i)+IMAGE_FORMAT)plt.imsave(clip_file,clip)2)进行数据增强(image augmentation)
数据增强过程中遇到的问题是:不同于图像分类问题只需要进行图像增强,分割任务需要同时对label image和data image进行同步一对一增强。这步我部分参考keras官方教程。
但是官方教程的操作让后期数据导入modle的过程不能随意调参,所以并没有完全照搬代码。根据官网,发现原理主要是label和image增强时运用同一个随机种子。所以我按照该原理写代码,导出数据之后发现label和image的确是一对一关系,成功!
tips: random.randint()的范围要大于等于你augmentation后图片的数量。比如我生成8000张随机图片,所以设置的是random.randint(1,100000)
def image_augmentation(img,label,augnum):#num means batch_sizeimage_datagen = ImageDataGenerator(rotation_range = 0.2,width_shift_range = 0.1,height_shift_range = 0.1,shear_range = 0.1,zoom_range = 0.1,fill_mode = 'nearest')label_datagen = ImageDataGenerator(rotation_range = 0.2,width_shift_range = 0.1,height_shift_range = 0.1,shear_range = 0.1,zoom_range = 0.1,fill_mode = 'nearest')#random.seed(1)seed = random.randint(1,100000)n = 0for batch in image_datagen.flow(img,batch_size=1,save_to_dir=path,save_prefix='aug',save_format='png',seed=seed):n +=1if n > augnum:breakn = 0for batch in image_datagen.flow(label,batch_size=1,save_to_dir=path_,save_prefix='aug_label',save_format='png',seed=seed):n +=1if n >augnum:breakreturn3) 对label进行one-hot encoding处理
4) 正则化
Unet实现过程中遇到的bug
1.Found 0 images belonging to 0 classes
keras读取数据需要数据树形式,
即 data/class_one …
/class_two …
服务器上将一个文件夹内容移到另一个文件夹的操作:
mv ./* ./另一个文件夹
2. Unet检测出来全零
这个问题困扰了我很久,最开始训练阶段预测出来结果全是0,图片全黑/全白。找了很多博客,问了朋友最后终于解决了这个问题。
首先:这个错误可以是很多结果导致的,我只能列出我遇到的原因,可能还存在其他奇奇怪怪的原因。慢慢排除一定能解决问题
1.最最最重要:看看数据集是否正确
我犯过的傻错误:
1)label数据集没有经过 one-hot encoding处理/处理方法出错。
(有朋友说不用one-hot encoding处理也可以 但是我没有实验过)
2) label和image增强后不一一对应。
3)testdata做了两次正则化
2. loss function
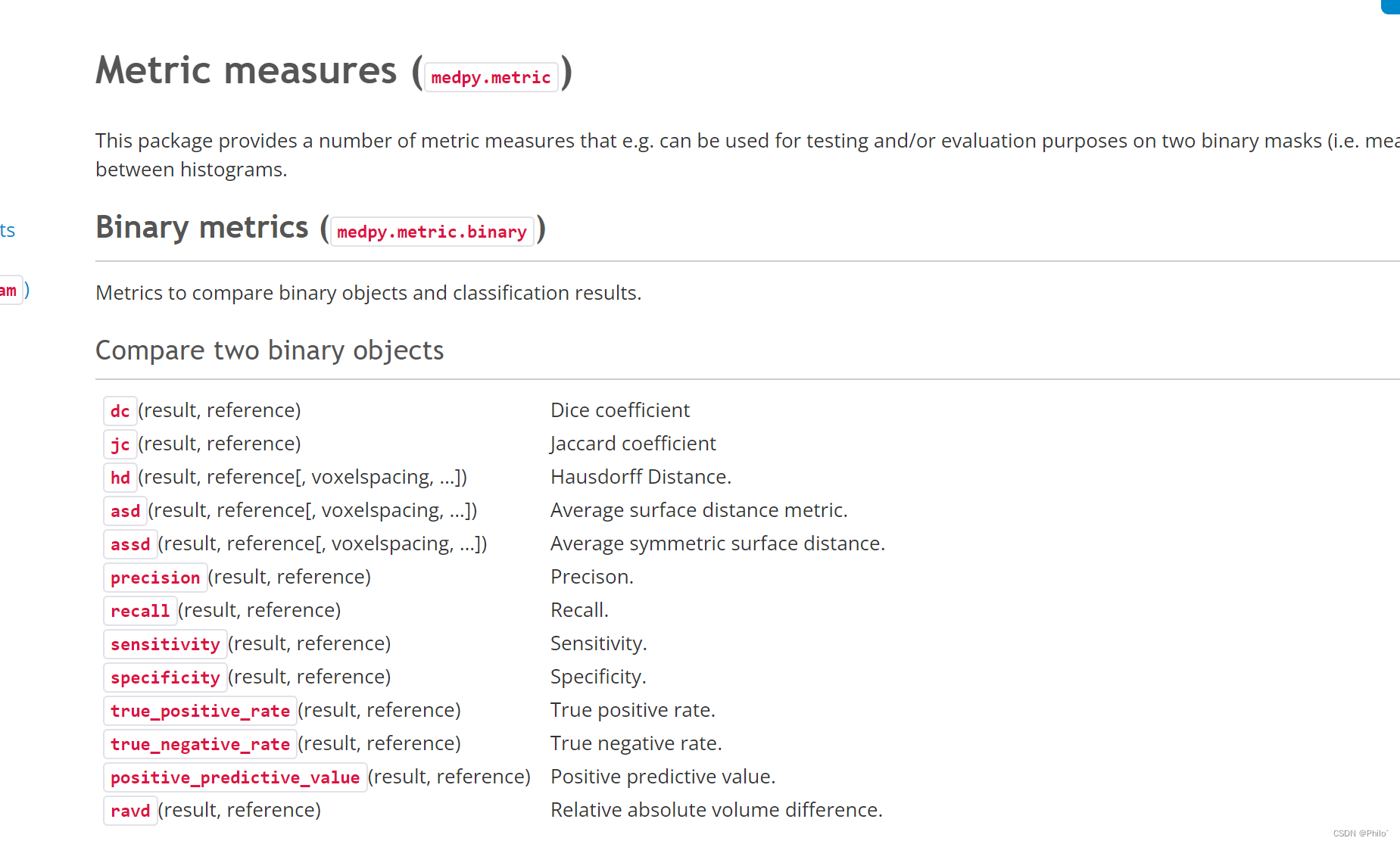
因为本实验进行的是医学图像分割,存在背景占比大,目标物占比小的问题。所以选用Cross-entropy loss效果不一定很好。后期我选用DICE LOSS作为loss function。但是我看了很多博客都只提到了二分类DICE LOSS。所以我根据原理自己写了多分类的DICE LOSS。

(图源:https://www.cnblogs.com/hotsnow/p/10954624.html)
@lucyyy
def dice_coef(y_true,y_pred):sum1 = 2*tf.reduce_sum(y_true*y_pred,axis=(0,1,2))sum2 = tf.reduce_sum(y_true**2+y_pred**2,axis=(0,1,2))dice = (sum1+0.1)/(sum2+0.1)dice = tf.reduce_mean(dice)return dice
def dice_coef_loss(y_true,y_pred):return 1.-dice_coef(y_true,y_pred)最后,分割出来accuracy分别在左心池,左心肌,右心池上达到了0.9,0.81.0.83。效果还是不错的。