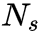| 论文名字 | One-Shot Video Object Segmentation |
| 来源 | 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) |
| 年份 | 2017.4.13 |
| 作者 | S. Caelles K.-K. Maninis J. Pont-Tuset L. Leal-Taixé D. Cremers L. V an Gool ETH Zürich TU München |
| 核心点 | 提出基于全卷积神经网络框架的One-Shot video Object Segmentation (OSVOS)框架用于解决视频中物体分割问题。 |
| 阅读日期 | 2020.10.29 |
| 影响因子 |
|
| 内容总结 | |
| 文章主要解决的问题及解决方案: 解决视频物体分割问题。
文章的主要工作: ①三个贡献,第一个:将CNN用于一个特定的对象实例,给定一个带注释的图像;第二个:将视频每一帧单独处理,将视频对象分割视为每帧分割问题;第三个:可以在速度和精度之间的不同平衡点工作。 ②本文提出一个新型的CNN架构OSVOS,用于处理视频物体分割问题,即对视频中的每一帧图像分成两类:前景(foreground)和背景(background),前景需要检测出的物体。OSVOS的全称为One-Shot Video Object Segmentation,即一次视频物体分割。如下图所示,OSVOS只需输入视频的第一帧图像中物体的掩模(masks)(红色位置),就可以识别中该视频接下来的每一帧中物体的掩模(masks)(绿色位置)。
③OSVOS的架构分三个部分:(1)在ImageNet中做预训练的一个基础网络(base network),离线训练的,用于区分前景对象;(2)在DAVIS数据集上训练的一个分割网络(parent network),离线训练的;(3)在视频单个帧中对特定的目标对象的分割示例进行微调网络(test network),使网络迅速聚焦于该目标,在线训练。 ④在OSVOS架构中,Parent Network按Foreground Branch(前景分支)、Contour Branch(轮廓分支,用于检测目标轮廓,当前图像中的全部轮廓)和Boundary Snapping(用于改善边界定位)分为三步。如下图所示,Foreground Branch和Contour Branch使用完全相同的网络架构,但使用不同的损失函数,以分别达到目标分割和轮廓勾勒的效果,最后Boundary Snapping将前两步的结果结合,得到更准确的物体分割结果。在PASCAL-Context数据集上训练,该数据集为图像的整个场景提供轮廓注释。
文章内容: ①离线训练部分的细节:VGG作为基础网络,二元分类的像素交叉熵损失函数(The pixel-wise cross-entropy loss for binary classification),其允许对不平衡的二进制任务进行训练。base network在ImageNet中预训练,parent network在DAVIS上训练,用SGD,参数设置为0.9,50000次训练,数据增强:镜像和放大,learning rate:10-8 ②在线训练部分的细节:用第一帧对parent network做微调。 ③All resources of this paper can be found at www.vision.ee.ethz.ch/˜cvlsegmentation/osvos/
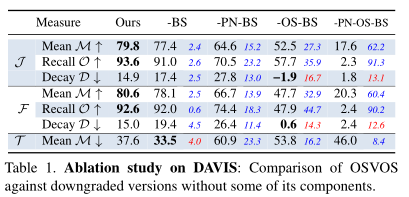
实验结果: 没有边界捕捉的原始方法(-BS),没有在DAVIS上预训练the parent network,没有在特定序列上执行一次性学习(one-shot)(-OS)。
表1证明了,预训练以及one-shot起重要作用。
errors主要来自false negative,而边缘捕获(boundary snapping)主要用于降低false negative。(说明boundary snapping的作用)
表2是与当前较先进的技术的对比。
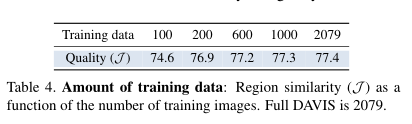
表4是训练数据对Quality(J)的影响
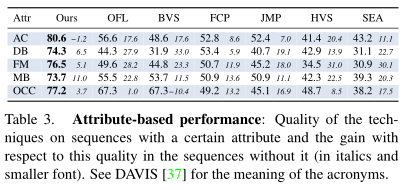
图6是在各个种类上的各种方法的识别率。
表5表示注释的图像数量对质量的影响。
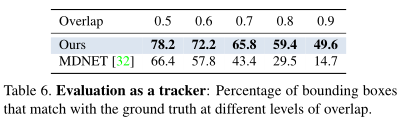
表6表示不同重叠级别匹配地面真实情况的边框的百分比。
图9中(a)是原本注释的,结果是(b)在第88帧和第46帧增加两帧的注释,结果是(f),OSVOS可以学习出两个骆驼的区别。
| |