文章目录
- CryptDB: Protecting Confidentiality with Encrypted Query Processing
- 1.cryptDB概述(背景)
- 2.CryptDB方案
- ①面对威胁1
- ☆大致系统框架
- ☆SQL-aware Encryption
- ☆Adjustable Query-based Encryption
- ☆其他DBMS功能
- ②面对威胁2
- ☆向共享数据提供访问控制策略
- ☆keychain
CryptDB: Protecting Confidentiality with Encrypted Query Processing
1.cryptDB概述(背景)
在线应用程序易受敏感信息被盗的影响,因为:
①攻击者可以利用软件漏洞来访问私人数据;
②好奇或恶意的管理员可能捕获和泄漏数据。
面对以上两种威胁,有下面两种解决方案:
一种减少服务器入侵造成的损害的方法是加密敏感数据,并在客户端上运行所有的计算(由应用程序进行),然而,即使这种方法是可行的,不少对我们比较重要的应用程序或者支持数据库查询的网站都不适合这种方法计算大量的数据,而且将我们现有的服务器端应用程序转换为这种形式也是困难的。
另一种方法是考虑理论解决方案,例如全同态加密,它允许服务器在加密数据上计算任意函数,而只有客户端看到解密数据。然而,全同态加密方案仍然是昂贵的数量级,并不切合实际。但是, 如果我们只是要求部分的加密操作, 而不是想对加密数据进行任意的操作, 是不是有复杂度低的算法, 可以满足实际系统的需求呢? Cryptdb就是基于这种思想提出的, 对于数据库来说, 常见的操作不多, 如果只是支持一部分的加密操作, 复杂度是可以接受的。
基于此,论文中提出了CryptDB,它为SQL数据库支持的应用程序在面对这些攻击时提供了实用且可证明的机密性。它的工作原理是使用一组高效的SQL感知加密方案对加密数据执行SQL查询。CryptDB还可以将加密密钥链接到用户密码,以便只能使用有权访问该数据的用户之一的密码来解密数据项。因此,数据库管理员永远无法访问解密的数据,即使所有服务器都受到威胁,攻击者也无法解密任何未登录用户的数据。
优势:
对来自生产 MySQL 服务器的 1.26 亿条 SQL 查询的跟踪分析表明,CryptDB 可以支持对跟踪中看到的 128,840 列中的 99.5% 的加密数据进行操作。我们的评估表明,与未修改的 MySQL 相比,CryptDB 的开销较低,将 phpBB(一个网络论坛应用程序)的吞吐量降低了 14.5%,将来自 TPCC 的查询的吞吐量降低了 26%。将加密密钥链接到用户密码需要 11-13 个独特的模式注释来保护 20 多个敏感字段和 2-7 行源代码更改,用于三个多用户 Web 应用程序。
2.CryptDB方案
①面对威胁1
☆大致系统框架
cryptDB主要解决了两个威胁:
①好奇或恶意的数据库管理员(DBA)试图通过窥探DBMS服务器学习隐私数据(例如,健康记录,财务报表,个人信息),这种情况,CryptDB可以防止DBA学习隐私数据;
②攻击者完全控制应用和DBMS服务器,这种情况CryptDB不能为已登陆到应用的用户提供保证,但仍能保证未登录的用户数据机密性。
对于解决这两个威胁面临着两个挑战:
①尽量减少泄漏到DBMS服务器的保密信息,及有效执行各种查询的能力。目前在加密数据上执行计算的方法不是太慢了就是无法提供足够的机密性。另一方面,用一个强壮高效的密码系统(如AES)加密数据,会阻止DBMS服务器执行很多SQL查询,如查询“sales”部门中的雇员人数,或工资高于$60,000的雇员人数。在这种情况下,唯一可行的解决方案是给DBMS服务器解密密钥,但这也将使攻击者可以访问所有数据。
②当攻击者控制了除DBMS数据库外的应用服务器时,尽量减少数据的泄漏。因为在加密数据上做任意计算是不切实际的,所以应用程序必须能够解密数据。难点在于确保被攻击的应用只能获得有限的解密数据。不成熟的解决方案是,为每个用户分配一个不同的数据库加密密钥,它们的数据不适用于共享数据的应用程序,如公告板和会议评审站。
CryptDB解决这些挑战的三个思路:
①首先是在加密数据上执行SQL查询。CryptDB加密每个数据项,并在一定程度上允许DBMS在转换后的数据上执行操作。CryptDB的高效得益于其主要使用对称密钥加密,避免了全同态加密,并运行于未修改的数据库管理系统软件上(通过使用自定义函数)。
②第二个技术是可调整的基于查询的加密。一些加密方案会泄漏数据的更多信息给DBMS服务器,但其需要处理某些查询。为避免对DBMS数据库泄漏加密数据的所有可能,CryptDB根据运行时所观察到的查询,对所有给定数据项仔细地调整了SQL感知的加密方案。为了实现高效的调整操作,CryptDB使用onion加密。onion是一个抽象的说法,是在数据库中彼此紧密地存储多个密文,避免昂贵的重新加密。
③第三个想法是连接加密密钥与用户密码,这样任意数据项仅能当用户访问它时,通过与用户密码连接的的密钥解密。因此,即使DBMS及应用程序已经被完全控制,如果没有用户登陆应用程序,或者说如果攻击者不知道用户密码时,其就不能解密用户数据。为了构建能够保证应用程序数据的隐私性及分享策略的连接密钥,CryptDB允许开发者在应用程序的SQL模式上提供策略注释,指定哪些用户可以访问数据项。
核心技术:
-
在加密数据上进行SQL操作
-
基于请求的可变的加密
-
将加密密钥与用户的口令关联
本文提出了CryptDB,引入了一个中间系统代理来实现在加密数据库上查询计算数据,如图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TWaxkrPI-1680505735749)(C:\Users\20376\AppData\Roaming\Typora\typora-user-images\image-20230330105806275.png)]](https://img-blog.csdnimg.cn/9c78b6e5dc58481ba57b774b44d9eb5c.png)
Cryptdb系统可以分为三个部分: Client, MySQL-Proxy, 以及MySQL-SERVER. 其主要逻辑实现在MySQL-Proxy,对于MySQL-SERVER则是通过UDF来完成一些辅助的功能。
CryptDB使DBMS服务器能够对加密数据执行SQL查询,就像对明文数据执行相同的查询一样。不需要更改现有应用程序。用于加密查询的DBMS的查询计划通常与用于原始查询的相同,除了构成查询的运算符(例如选择、投影、连接、聚合和排序)是对密文执行的,并且在某些情况下使用修改的运算符。
CryptDB的代理存储秘密主密钥MK、数据库模式和所有列的当前加密层。DBMS服务器看到匿名模式(其中表和列名被不透明标识符替换),加密的用户数据和CryptDB使用的一些辅助表。CryptDB还为服务器配备了特定于CryptDB的用户定义函数(UDF),使服务器能够为某些操作计算密文。
也就是说,MySQL-Proxy能够获取用户发送的SQL请求,并进行中间的处理,然后将处理以后的请求发送给MySQL-SERVER.。请求在服务器上执行完成以后,结果也会经过MySQL-Proxy的处理,然后返回给客户端。
所以 Cryptdb的基本思想是,:在MySQL-Proxy处对用户的SQL的关键字段请求进行加密,并且依然保证SQL语句的语法要求,然后发送给MySQL-SERVER,处理完成以后,MySQL-SERVER返回加密的数据给MySQL-PROXY,在Proxy处解密,然后返回给客户端。
这段话听起来有点绕,在这里我的理解是这样的:
假设我们有如下的一张数据表:
| Name | Age | Grades |
|---|---|---|
| 苏依庄 | 18 | 85 |
| 陈昊 | 18 | 87 |
| 丁益剑 | 18 | 88 |
通过加密,我们获得了如下的等价表格(这里的密文是我胡乱打的):
| abc123 | cgb541 | 12iuy |
|---|---|---|
| (✪ω✪) | U•ェ•*U | (Θ3Θ) |
| ू・ω・` ) | (●—●) | <*))>>=< |
| o(´^`)o | ⊙(・◇・)? | ヾ(⌐ ■_■) |
那么,存储在DBMS里面的是加密之后的数据。对于这样一张加密以后的数据表, 即使别人获取了数据库内容, 在没有密钥的情况下也不能知道里面的数据是什么。
那么,用户在查询数据的时候是这样的一个过程:比如用户现在需要所有成绩大于86的学生的信息,
我们有如下的原始查询语句:
SELECT * from student where Grade > 86;
这个语句由客户端发出,首先到达MySQL-Proxy,由于数据已经被加密了,所以如果这个语句直接发到数据库(DBMS)上执行,,是不能返回正确的结果的,,在MySQL-Proxy处,,首先要进行处理.。观察上面的表格,我们发现87加密以后的结果是: <*))>>=<,而Grades加密之后的结果变成了12iuy。 所以,在MySQL-Proxy处, 对SQL语句进行处理, 将87进行加密,加密以后的SQL语句就变成了:
SELECT * from student where 12iuy> ><*))>>=<)
这样, MySQL-SERVER会执行修改以后的SQL语句,并且返回加密后的结果给MYSQL-Proxy,MySQL-Proxy获得加密以后的结果,解密,然后返回给客户端。
总之,CryptDB查询处理包括四个步骤:
①应用程序发出查询,并由代理服务器拦截并重写:使表名和列名匿名,并用最适合的加密方案加密(用密钥MK)查询中的常量。
②代理服务器检查DBMS服务器是否应该在执行查询之前给密钥调整加密层,如果调整,在DBMS服务器上执行一个UPDATE,就要调用UDF来调整相应的列的加密层。
③代理服务器将加密的查询转发到DBMS服务器,使用标准SQL(因为聚集或关键字搜索,偶尔调用UDF)。
④DBMS服务器返回查询结果(加密的),代理服务器解密并返回给应用程序。
☆SQL-aware Encryption
CryptDB针对不同类型的字段会有不同的加密方案,CryptDB中称之为SQL感知加密(SQL-aware Encryption)。
以下论文中给出的proxy采用的几种加密算法:
①随机性加密(RND):即使是两个相同的明文,也可以映射到不同的密文上面(这是概率性的)。这种方法可以用来抵抗自适应选择明文攻击,在cryptDB中具有最高的安全性,但是缺点就是很难在密文上进行一些操作。实现方法有AES等。
②确定性加密(DET):DET的安全性会相对弱一点,相同的明文映射到相同的密文中(也就是明文和密文是一一对应的),所以可以很方便地对密文进行操作,例如相同值查询等,但是对于不同的表,相同的列,使用的密钥不一定相同。此加密层允许服务器执行相等性检查,也就是说它用字段相等性、连接相等性、GROUP BY、COUNT、DISTINCT等执行选择。在加密方案中,DET是一个伪随机置换,采用AES加密方案中的CMC模式,也就是两轮CBC,可以看作是一轮正向一轮反向,对于较小的值会被填充到64bit,对于较大的值会被填充到128bit。
③保序加密(OPE):OPE允许根据它们的加密值建立数据元素之间的顺序关系,并不会泄漏数据本身。对于任意密钥K,如果 x<y,则OPEK(x) < OPEYK(y)。因此,如果一个列用OPE加密,给定加密常量 OPEK(c1)和OPEK(c2) ,服务器可以执行对(c1,c2)的范围查询。服务器也可以执行ORDER BY,MIN,MAX,SORT等。OPE加密方案相对于DET,保密性变弱了,因为OPE泄露了数据的顺序,其安全性就等价于保持顺序的随机映射。
④同态加密(HOM):HOM是一种安全的概率加密方案(IND-CPA安全),允许服务器在加密数据上执行计算,最终结果由代理服务器解密。全同态加密很慢,而同态加密在一些操作上效率很高。为支持求和,实现了Paillier加密系统:将两个加密的值相乘,结果是加密值的总和,HOMK(x)·HOMK(y)=HOMK(x+y),其中执行的乘法是模上一些公钥值。为执行SUM,代理服务器将SUM(求和)替换为调用UDF执行同态加密的列的Paillier乘法。同态加密也可用于通过DBMS返回的合计和个数来计算平均值的过程,也可以用来设置自增值(例如SET id=id+1)。
⑤关键字搜索(SEARCH):**SEARCH用于在加密文本上执行搜索操作,如MySQL中的LIKE操作。**对于需要SEARCH的列,用标准分隔符将文本分割成关键字(或使用由模式开发指定的特殊关键字提取函数)。之后,删除重复的关键字,随机排列关键字位置,然后用Song等人的方案加密每个关键字,将每个关键字都填充到相同长度。SEARCH的安全性与RND接近:不论某个关键字在多个行中是否有重复,加密方案都不会泄漏给DBMS服务器,但是它泄漏了用SEARCH加密的关键字的数量,攻击者可以估计不同或重复的关键字数量(例如,通过比较相同数据的SEARCH和RND的密文)。
⑥Join (JOIN and OPE-JOIN)。这种加密可以支持join运算,包括范围join以及等值join(自然连接)。因为在DET中,相同的列,在不同的表中可以用不同的密钥来加密,所以相同的值在不同的表加密后的值不一样。所以此类算法就是为了使加密后的列表能正确地进行连接。
JOIN-ADJ是一种对输入确定性的函数(就是相同的明文对应的一定是相同的JOIN-ADJ值),同时也是可调整的利用密钥加密之后的hash值(意思是这个hash值由对应的加密算法生成,而且带有可调整的附加属性的)。
因此利用了JOIN-ADJ的JOIN加密方案由如下所示:
J O I N ( v ) = J O I N − A D J ( v ) ∣ ∣ D E T ( v ) JOIN(v) =JOIN-ADJ(v) || DET(v) JOIN(v)=JOIN−ADJ(v)∣∣DET(v)
(这里的||符号起到连接字符串的作用)
在这个结构之下,CryptDB通过比较JOIN-ADJ(v)来实现比较属性名是否相同,通过解密DET(v)来获取被加密的属性值。
当每次proxy悉知了有新的JOIN操作到来,它会向DBMS传递一个密钥使得DBMS可以调整两个列之间的JOIN-ADJ值,使得他们的JOIN-ADJ值趋于一致(就是变成一样的)(当然必须明文要是相同的才行)。一旦他们经过了调整,之后对于这两个列的JOIN操作就无需再次调整他们的JOIN-ADJ值了,因为他们会将这个值保留,直到需要作出改变为止。
显然,这里提到的JOIN操作是具有可传递性的,AB、AC可以实现JOIN,那么BC同样可以。这样ABC形成了一个所谓的“可传递组”的概念。论文中作者对于可以实现JOIN操作的列对的管理是这样实现的:(表名+列名),使得所有在“可传递组”中的列能共享同样的join-base。
CryptDB通过选择两列中字母表顺序第一的列来作为基准,是为了防止发散,通过多次join之后,最后可以达到一个稳定的,有共同join-base的状态,这样就形成一个transition组,比较像算法中的迭代法。(没有看懂什么意思)
对于范围连接,由于OPE方案中缺乏结构,因此难以构造类似的动态重新调整方案。CryptDB要求应用程序提前声明将参与连接的列对,以便将匹配的密钥用于这些列的层OPE-JOIN;否则,对于OPE-JOIN层的所有列将使用相同的密钥。幸运的是,范围连接很少见;在我们的任何示例应用程序中都没有使用它们。
☆Adjustable Query-based Encryption
CryptDB中很重要一个设计是可调的基于查询的加密,其可动态调整DBMS服务器上的加密层。CryptDB针对不同类型数据采用不同的加密策略,例如,如果应用程序没有发出比较列中的数据项或对列进行排序的查询,则应该使用RND对列进行加密。对于需要相等性检查但不需要不等性检查的列,DET就足够了。然而,查询集并不总是预先已知的。因此,我们需要一个自适应方案,动态调整加密策略。
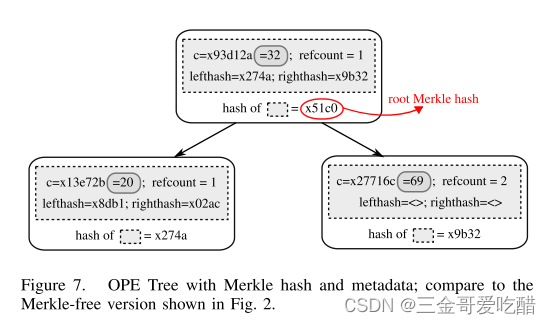
论文的方案是将每个数据项加密在一个或多个洋葱(onion)中:即,如下面两幅图所示,每个值都以越来越强的加密层进行修饰。每个洋葱头的每一层都启用了某些类型的功能。例如,诸如RND和HOM的最外层提供最大安全性,而诸如OPE的内层提供更多功能。
OPE算法可以支持大小比较,DET算法可以支持两个数是否想等的比较,HOM可以支持加法。但是没有一种算法可以同时支持多种操作, 所以依然是上面的表格, 如果我们需要同时支持加法和大小比较的操作, 就必须另外想办法处理. 在论文中提出的方法是多洋葱模型, 简单来说, 就是对于GPA这列数据, 用不同的算法存储多次, 需要哪种操作, 就选择哪种算法加密的列进行处理.
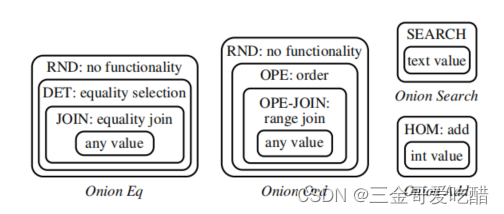

上面的onion图展示了在最原始的情况下,数据被加密的情况。每向外一层都代表了更高程度的加密。同样的基于性能的考虑,为不同的数据类型准备几种不同的洋葱丝有必要的。例如:对于string类型add操作是没有意义的,对于integer来说search操作也是毫无效果的。
如图所示,原始的Employees表有两列:上面的四个层次化的洋葱模型,分别可以支持不同的加密操作。其中Onion Eq支持相等比较的操作,Onion Ord支持大小比较,Onion Add支持加法,而Onion Search 支持LIKE的搜索。所以为了支持不同的操作,原始的列ID被存储成了四列,一个洋葱存一列。这样,要对ID进行加法操作,就转换成对加密表的C1-Add列进行操作,要对ID列进行排序操作,则转换成对C1-Ord列进行操作,这个转化就是通过MySQL-Proxy来完成。由于ID是整数,不需要支持search 操作,所以也就没有进行存储。
还有一个问题,就是为什么要多层次的加密? 这主要是为了保证数据的安全性,同时保证能够支持加密操作,是一种折中的设计。一开始所有的洋葱都是处于RND层次,也就是加密等级最高的层次。在这个层次,没有DET和OPE的性质,不能支持相应的操作。如果某一次用户需要OPE或者DET的行为,就对这一列数据进行解密,解密到DET或者OPE的层次,然后再进行处理。这个剥洋葱的过程,可以由MySQL-SERVER来完成,因为这种解密不会暴露明文给服务器。
所以, 对于上述的表格, 如果我们执行如下的插入语句:
INSERT INTO Employees values(1,"zhangfei");
则会根据洋葱模型扩展成:
INSERT INTO Employees values(C1-IV,C1-EQ,C1-ORD,C1-ADD,C2-IV,C2-EQ,C2-ORD,C2-SEARCH);
每个字段都是经过层次化的加密的。但是在Cryptdb的最新实现中,SEARCH层并没有被实现。
对于每个洋葱的每个层,代理使用相同的密钥来加密同一列中的值,并且跨表、列、洋葱和洋葱层使用不同的密钥。对列中的所有值使用相同的密钥允许代理对列执行操作,而不必为将要操作的每一行计算单独的键。跨列使用不同的密钥可以防止服务器学习任何其他信息。所有这些密钥都从主密钥MK导出。例如,对于表t、列c、洋葱o和加密层l,代理使用密钥:
K t , c , o , l = P R P M K ( t a b l e t , c o l u m n c , o n i o n o , l a y e r l ) Kt,c,o,l = PRPMK(table t, column c, onion o, layer l) Kt,c,o,l=PRPMK(tablet,columnc,oniono,layerl)
其中PRP是伪随机置换(例如,AES)。
假设一个场景,用户向查询名字为Alice的用户的信息,从客户端发送了一条SQL请求:
SELECT * FROM Student WHERE sname='Alice';
这需要将Name的加密降低到层DET。要执行此查询,为了将表1中的列2的洋葱Ord解密到层OPE,代理使用DECRYPT RND UDF向服务器发出以下查询(CryptDB使用在DBMS服务器上运行的UDF实现洋葱层解密):
UPDATE Table1 SET C2-Ord = DECRYPT RND(K, C2-Ord, C2-IV)
其中c2就对应着name字段,代理再执行
SELECT C1-Eq, C1-IV FROM Table1 WHERE C2-Eq = x7..d
其中c1对应着ID这一列,并且其中x7…d是具有密钥KT1,C2,Eq,JOIN和KT1,C2,Eq,DET的“Alice”的Eq洋葱加密。
当代理从应用程序接收SQL查询时,它会确定是否需要删除加密层(剥洋葱)。给定在服务器上执行查询所需的列c上的谓词P,代理首先确定计算c上的P所需的洋葱层。如果c的加密尚未在允许P的洋葱层处,则代理通过向服务器发送对应的洋葱密钥来剥离洋葱层以允许c上的P。代理从不解密通过最不安全的加密洋葱层的数据。
其中K是从等式(1)计算的适当密钥。同时,代理更新其自身的内部状态,以记住Table 1中的列C2-Ord现在位于DBMS中的OPE层。每个列的解密都应包含在一个事务中,以避免客户端访问要调整的列时出现一致性问题。其中洋葱解密(剥洋葱)完全由DBMS服务器执行。在稳定状态下,不需要服务器端解密,因为洋葱解密只在列上请求新的计算类时发生(剥好的记录下来以后就直接用了,不用再剥了)。这个属性揭示了为什么CryptDB的开销在稳定状态下是适度的。
注意:DBMS服务器用基于UDF的算子替换一些运算符。例如,SUM和+必须被替换为密文中执行HOM加的UDF的一个调用。等于和排序运算符(如=和<)不需要这些替换,并且可以在密文上直接被DET和OPE应用。
代理服务器转换完查询后,就将查询发送给DBMS服务器,接收查询的结果(包括加密的数据),使用相关的洋葱密钥解密结果,并将解密后的结果发送给应用程序。
☆其他DBMS功能
大多数其他DBMS机制,如事务和索引,在加密数据上使用CryptDB的工作方式与在明文上的工作方式相同,无需修改:
-
对于事务,代理沿着所有开始、COMMIT和ABORT查询传递给DBMS。由于许多SQL运算符在NULL上的行为与在非NULL值上的行为不同,因此CryptDB将NULL值暴露给DBMS而不加密。
-
CryptDB目前不支持存储过程,尽管某些存储过程可以通过以与CryptDB的代理重写SQL语句相同的方式重写其代码来支持。
-
DBMS为加密数据建立索引的方式与为明文建立索引的方式相同。目前,如果应用程序请求列上的索引,代理会要求DBMS服务器在该列的DET、JOIN、OPE或OPE-JOIN洋葱层(如果它们被公开的话)上构建索引,但不会为RND、HOM或SEARCH构建索引。
②面对威胁2
当proxy和application端也会受到攻击的时候,需要保证泄露的数据尽可能少。
第四章在一个论坛网站phpBB的模型上讨论了这个问题——如何在数据库陷入险境的时候,减轻收到的数据损失,phpBB模型是这样保证这一点的:
1.私人之间传递的信息是对他人隔离的。
2.某个论坛中发表的言论信息只有属于该论坛的人才能看见。
在CryptDB中,提供了以下机制来解决威胁2:
1.在SQL查询的层次就需要获取对于共享信息的权限控制策略。(因此要在建表的时候声明principles)【4.1】
2.减少敌方能够获取的信息量(key chaining)【4.2】
☆向共享数据提供访问控制策略
CryptDB通过ENC_FOR以及SPEAK_FOR语句提供注释的功能,实现了对共享数据的访问权限进行限制。这一过程形成的keychain保证了当系统受到攻击的时候,只有登陆中的用户的数据会被泄露,未登陆的用户的数据不会被泄露。
软件开发人员通过对CryptDB中数据库模式结构的定义,来指定在SQL查询这个层次上的策略。
策略的注解:
策略的注解是指:为了在SQL查询级别表达数据库支持的应用程序的数据隐私策略,应用程序开发人员可以通过为数据项的任何子集指定哪个主体可以访问它来在CryptDB中注释数据库的模式。
开发人员会指定每一个数据实例其对应的principle是什么:Principle是一个实体,例如一个用户或者一个小组,利用他们可以很好的对权限进行定义。
CryptDB使用的是自己定义的principal而不是现成的DBMS的principles。因为现成的principle提供的定义细粒度不够,不足以满足开发的需求。其二CryptDB在principle之间需要实现显式的特权授予(SPECK_FOR),这也是现有的DBMS principle不能够提供的。(注:特权的意思其实就是能够对数据进行解密操作)
注解需要以下3步:
Step1:
定义principle types:利用PRINCTYPE关键字定义。每一个principle都是某个principle type的实例(就类似C++里面变量和变量类型的概念)
一共有两种principle类型:external和internal(注:除了external就是internal了)。
External:这种principle代表了那些端用户(end user),这些端用户通过显式的使用密码得到自己的权利。
Internal:这种principle的特权是可以被external的principle获取的,但是只能通过显式的声明来实现授予。
也就是说,对于external principal,需要提供密码给proxy,才能得到相应principal的权限。而internal principal获得权限需要在系统中对其进行授权。
Step2:
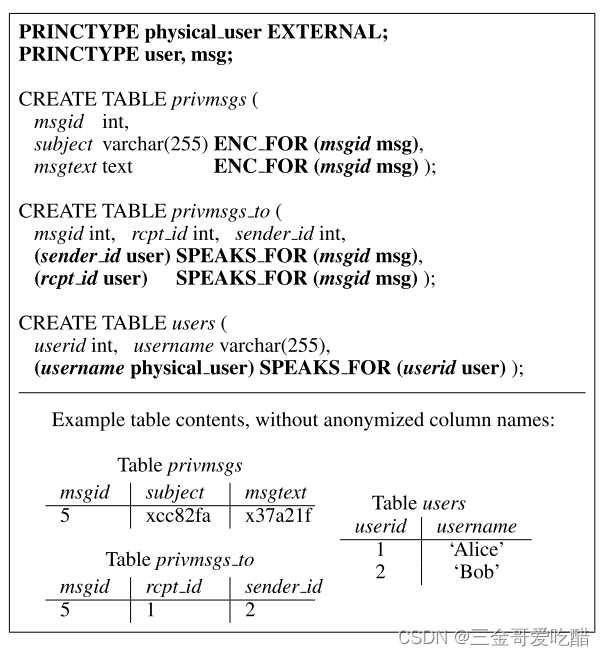
显式的定义每一列是否包含有敏感的信息,同时也定义哪些principle拥有获取这些敏感信息的权利。使用ENC_FOR来实现这样的操作。如下图中的表privmsgs中,只有principle 5可以解密msgtext x37a21f。
Step3:
可以利用SPEAK_FOR定义授权的规则。语法:(a x) SPEAKS_FOR (b y)的意思就是x类的a principle声明了自己拥有y类b principle的特权。其实对着表来看的话就是a这个属性获取了b这个属性的特权。比如在上图中,1和2都可以拥有5的特权
注意:通用语法(a x) SPEAKS_FOR (b y)中,b这个属性只能待在声明所在的这张表里面,但是a就不一样了,a可以待在别的表里面。
☆keychain
在上述向共享数据提供访问控制策略的过程中,keychain保证了当系统受到攻击的时候,只有登陆中的用户的数据会被泄露,未登陆的用户的数据不会被泄露。
系统为每个principal都随机生成一个key,假如某个principle A给另外一个principle B授权了,就是B speaks for A,那么A的key将会用B的key加密然后存储到数据库中的access_keys表格中。
敏感区域的数据是和前面的onion使用同样的方式加密的,区别在于这里是每一个实例都会被单独加密,而不是整一列使用同样的秘钥加密。
每个principle实例的key是由对称秘钥和公钥加密的公私钥对组成的。公钥加密开销比较大,因此普通情况下principle都是用对称密钥加密的。可是也有特殊情况,一旦涉及到有的principle没有登录,这时候别的principle都是没有办法获知没有登录的principle的对称密钥的,所以利用公钥加密的方法,把明文用公钥加密传给对方,等到对方上线的时候使用私钥解密即可。
CryptDB为每一个external principle派发一个随机key,并且把key用相应用户的密码加密后,放在external_keys表里面,这样当用户改变密码的时候,私密数据key可以不用改变,只需要在external_keys表中对相应的principal的key用用户的新密码进行重新加密。
当external主体登陆进系统之后,系统会把该用户名以及密码放在一个表cryptdb_active中,密码用于解密相应主体的key以读取相关数据。Proxy会把这个表读进内存里面,server端不会得到这个表,并且proxy拦截一切对该表的访问。如果用户没有登陆,就不会出现在此表中,意味着即使proxy受到攻击,表里面的内容泄露了,未登录用户的数据大部分(可能会出现处于同一个principal的人登陆之后泄露数据的情况)不会被泄露,因为密码不在表上面,这样保证了未登录用户的数据。
但是有一些特例,例如管理员之类的可访问数据比较大(权限很高),很容易会造成大量数据的泄露,所以管理员账号不能随便记录在cryptdb_active表里面,如果管理员要以普通身份登陆的时候,就需要另外分离出一个有相应权限限制的账号,写入cryptdb_active表中,这样可以在大部分时间里防止大量数据的泄露。
CryptDB使用两种语句对敏感数据进行注释:
(1)在表格中对表项用ENC_FOR语句对数据进行注释实现对数据的访问控制:A ENC_FOR B(A是数据,B是主体),意味着只有主体B可以访问数据A,ENC_FOR的实现原理是用主体B的key对数据A进行加密。
(2)利用SPEAK_FOR语句对表格进行注释,给一个主体授予另一个主体的权限。这种做法的格式为(a x) SEPAK_FOR (b y),其中x和y为主体类型,a和b是主体。意思是x类型的主体a有y类型的主体b的权限,b能访问的内容,a也有权限访问。
SPEAK_FOR的实现原理是用主体a的key对主体b的key进行加密,当需要访问相应数据的时候,可以通过主体a的key对主体b的key进行解密,然后通过主体b的key对相应数据进行访问。当主体A通过SPEAK_FOR语句与主体B相连的时候,主体B的key会用主体A的key加密,然后放在一个特殊的表access_key表上面。但是数据的加密在共享数据双方都在线的情况下采用对称密钥(加密和解密的密钥相同)进行加密,而当某一个主体没有登陆进系统的时候,无法得到该主体的symmetric key,所以这个时候会采用公钥加密数据并保存,当主体再次登录的时候使用自己的私钥进行解密,获得数据。多个SPEAK_FOR就形成一条key chain,要找某个数据的时候,只需要顺着key chain,从用户密码,一直找到要找的数据为止。
每当敌方想要通过更改SPEAKS_FOR来窥探隐私信息的时候,CryptDB的机制告诉我们,需要对access_keys表格进行相应的更改,想要更改这个表格必须获得被授权principle的key,这就意味着只有这个principle登录的时候,敌方才能获取相应的key从而对这个principle的私密信息进行窥探。
以上便是我对这篇论文的理解,如有错误还请批评指正,欢迎大家一起学习。