目标网站:豆瓣电影
目标网址:https://movie.douban.com/subject/30166972/comments?status=P
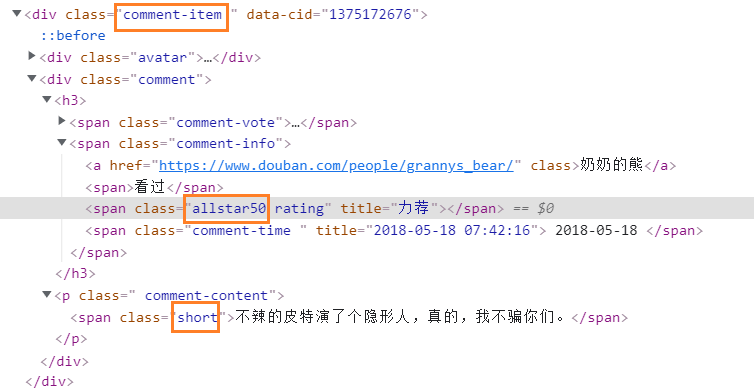
目标数据:(1)评价 (2)日期 (3)评论 (4)评论点赞

任务要求:
(1)使用urllib或requests库实现该网站网页源代码的获取,并将源代码进行保存;
(2)自主选择re、bs4、lxml中的一种解析方法对保存的的源代码读取并进行解析,成功找到目标数据所在的特定标签,进行网页结构的解析;
(3)定义函数,将获取的目标数据保存到csv文件中。
(4)使用框架式结构,通过参数传递实现整个特定数据的爬取。
数据爬取
-
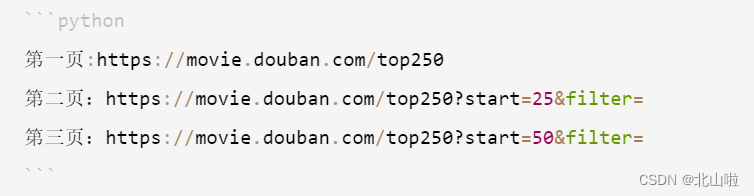
链接端口分析,确定爬取页数

-
获取页面

-
分析页面,爬取信息

-
保存数据


-
代码整合
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import bs4
import csv
import re
import time
import randomdef getHTMLText(url):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'}try:r = requests.get(url, headers=headers)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept RequestException as e:print('error', e)def fillUnivList(all_info,url):soup = BeautifulSoup(url, 'html.parser')for i in range(20):commentlist = soup.find_all('span',class_ = 'short')votes = soup.find_all('span',class_ = "votes")time = soup.find_all('span',class_ = "comment-time")score = soup.find_all('span', class_ = re.compile('(.*) rating'))m = '\d{4}-\d{2}-\d{2}'try:match = re.compile(m).match(score[i]['title'])except IndexError:breakif match is not None:time = scorescore = ["null"]else:passall_dict = { }all_dict["commentlist"] = commentlist[i].textall_dict["votes"] = votes[i].textall_dict["time"] = time[i].textall_dict["score"] = score[i]['title']all_info.append(all_dict)return all_infodef printHtml_text(data):for ii in data:value_list = list(ii.values())with open (r'D:\qq.txt','a',encoding ='utf-8') as f:f.write(str(value_list)+'\n')def printHtml_csv(data):with open('D:\data.csv','w',encoding = 'utf-8-sig',newline = '') as csvfile:fieldnames=['评价','日期','评论','评论点赞']writer=csv.DictWriter(csvfile,fieldnames=fieldnames)writer.writeheader()for a in data:i = list(a.values())writer.writerow({'评价':i[3],'日期':i[2],'评论':i[0],'评论点赞':i[1]})def main():all_info = []for i in range(0,200,20):urls = ['https://movie.douban.com/subject/30166972/comments?start='+str(i)+'&limit=20&sort=new_score&status=P']for url in urls:
# print(i)time.sleep(round(random.uniform(3, 5), 2))html = getHTMLText(url)data = fillUnivList(all_info,html)printHtml_text(data)printHtml_csv(data)main()- 数据展示


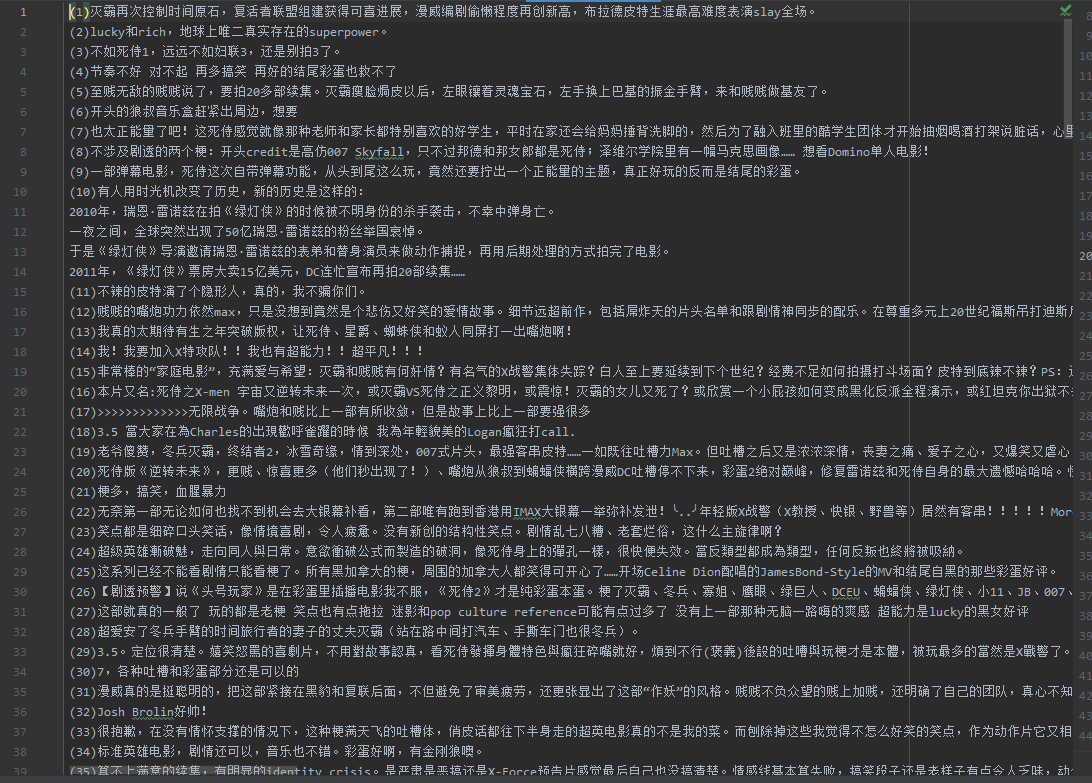
数据分析
-
制作词云

-
效果图

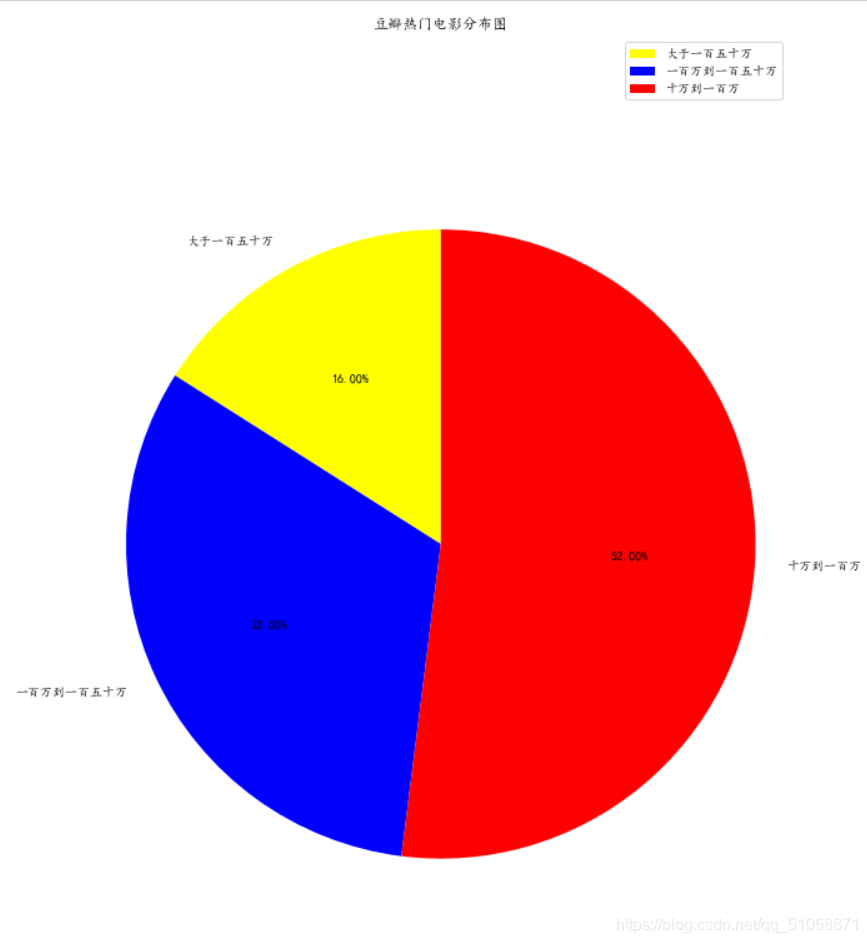
数据已经爬取出来了,可以使用Bar, Pie做一些效果图,自行发挥就好哈哈哈