这次的爬虫我们来看url携带多个参数的页面爬取

打开豆瓣电影排行榜官网,这里我选择了喜剧类型,发现只要将鼠标下滚翻到该页面最底部,滚轮就会重新跳到中间,相当于浏览器又发送了请求,重新加载一个页面,对应打开该网页的开发者模式,可以看到是get请求,并且携带多个参数,所以需要继续声明一个字典对其进行封装。



import requests
import json
get_url='https://movie.douban.com/j/chart/top_list'
#原来的URL是https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=0&limit=20携带参数,但凡有参数都要进行封装,将问号后面的参数都封装到字典里,
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
}
param={'type': '24','interval_id': '100:90','action':'','start': '1', # 从库中的第几部电影去取'limit': '20' # 一次性取出的电影数量
}
response=requests.get(url=get_url,params=param,headers=headers)
list_data=response.json()
fp=open('./douban_movie.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
print('over!')
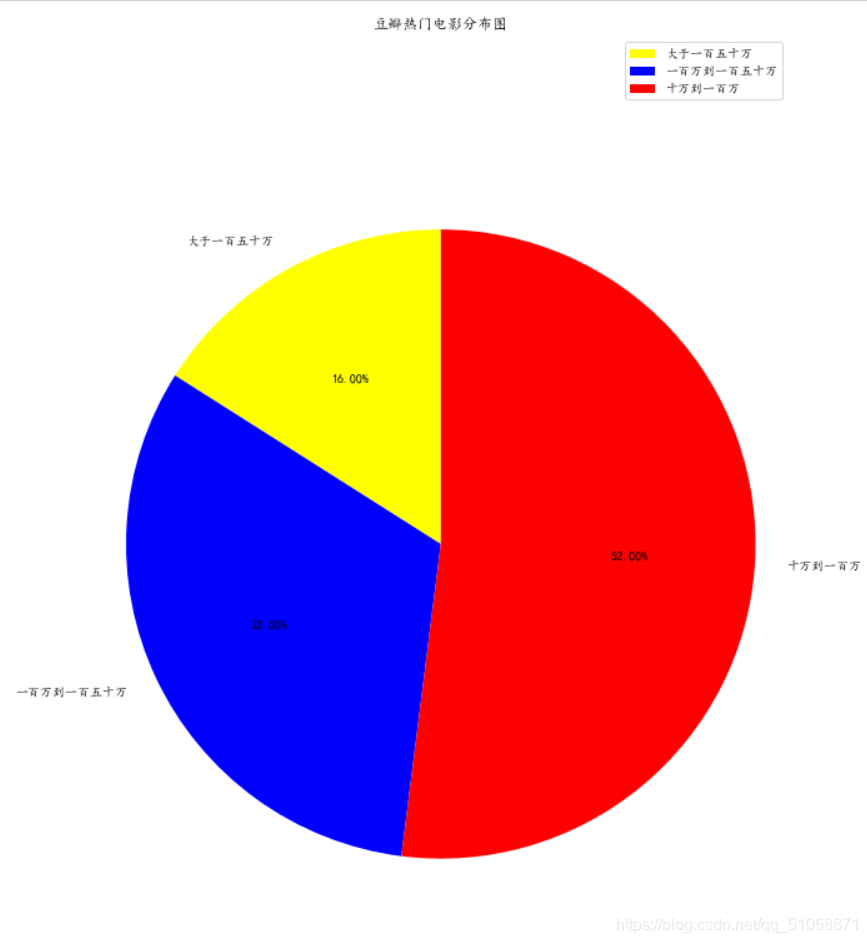
爬取结果