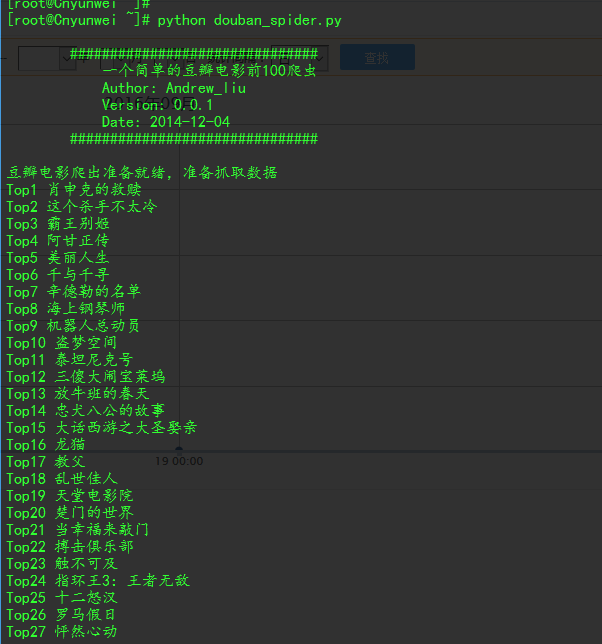
思路:
从豆瓣上抓取数据【主要是评分,只是那个人数的百分比和最终评分,不过够用了】
一、收集数据
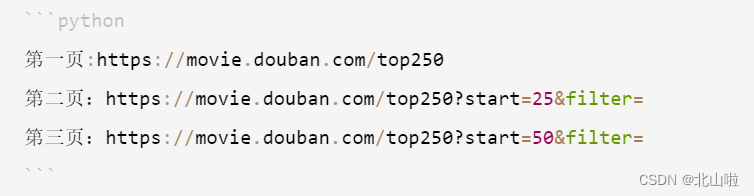
起始URL:https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0
【注,爬取的对象是使用json传输数据的,就是传输json字符串的那种啦,学过一点web基础,但不是很懂,别喷我喔,留言我会改正说法的啦】
首先就是先爬取单页嘛,然后找到规律然后根据需要循环爬取一定数量的数据,当然了期间要加一些反反爬的措施。(这里用到了timeout,verify=False关闭证书验证,headers,还有就是IP代理池【中间的时候用了一下,后来发现根本用不着】)
然后注意还需要一些异常处理。之后就是把结果值返回,然后添加到一个列表里面,可以使用pandas的Dataframe或者numpy的array规范数据,或者使用字典然后存储到json文件也好【不过我这个不太熟】,最后存储写入文件即可。
大家都是有点基础的啦,那我就直接贴代码了,基础不行的请先学习爬虫的基础知识。
注释在代码中:
# -*- coding: utf-8 -*-
# @Time : 2019/6/12 19:00
# @Author :
# @File : GetMovie.pyimport requests
import logging
import json
from lxml import etree
import pandas as pd'''
获取数据分析所需的字段内容
抓取字段:影片名,最终评分,五星、四星、三星、二星、一星
抓取的startURL:
'''class Movie:def __init__(self):self.PROXY_POOL_URL = 'http://localhost:5000/get'self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}# self.proxys = {}def get_proxy(self):#代理池 未启用try:response = requests.get(self.PROXY_POOL_URL)if response.status_code == 200:return {'http':response.text,'https':response.text}#proxies=Movie.get_proxy(self)except ConnectionError:return Nonedef getUrl(self,upLimit):logging.captureWarnings(True) #关闭多余的警告信息for i in range(0, upLimit, 20):#确定起始URLurls = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start={}'.format(i)try:responses = requests.get(urls,headers=self.headers,timeout=5,verify=False) # verify=False,不验证证书if responses.status_code == 200:#如果起始URL响应正常,打印一下信息print('成功连接: ', urls)responsesDict = json.loads(responses.text)for dicts in responsesDict['data']:url = dicts['url']try:response = requests.get(url, headers=self.headers, timeout=5, verify=False)response.encoding = 'utf-8'if response.status_code == 200: #对是否有正常的响应 加入判断#如果url响应正常打印如下信息print("子网页链接成功: ", url, ' 链接状态 :', response.status_code, '正在等待解析.....')html = etree.HTML(response.text)#使用xpath进行解析movie_Name_Year = html.xpath('//*[@id="content"]/h1/span/text()')movie_Score = html.xpath('//*[@id="interest_sectl"]//div[@class="rating_self clearfix"]/strong/text()')movie_Star = html.xpath('//*[@id="interest_sectl"]//div[@class="ratings-on-weight"]/div[@class="item"]/span[@class="rating_per"]/text()')item = [movie_Name_Year[0], movie_Score[0], movie_Star[0], movie_Star[1], movie_Star[2],movie_Star[3], movie_Star[4]]print('解析成功!')# 名字 电影评分 五星 四星 三星 二星 一星yield itemelse:passexcept:#url没有正常响应print("子网链接失败: ",url)else:passexcept:#起始URL没有返回正常响应print('当前urls: ', urls, ' 未响应!')def saveFile(self):datas = [] #所有数据将加入这里for item in Movie.getUrl(self,1200):datas.append(item) #添加数据到datas列表dataColums = ['影片名', '最终评分', '五星', '四星', '三星', '二星', '一星']#将数据转成Dataframefiles = pd.DataFrame(columns=dataColums, data=datas)files.to_csv(r'E:\DemoMain\课程考核接单\data.csv',index=None) #=保存到文件#成功保存到文件后,打印输出done!提示print("done!")def main(self):Movie.saveFile(self)if __name__ == '__main__':M = Movie()M.main()
二、建模分析
【菜鸟上路,勿喷,嘻。欢迎大佬们一起讨论和学习】
思路:
1.观察数据:数据除"影片名"外,为数值型,也就是参与模型构建的数据是数值型,标签"最终评分"也为数值型,而且无明显类别界限。
2.由1可知,这是一个监督问题【所有数据都有标签以及标签值】,而且这不是一个分类问题。
3.特征字段有多个,多特征问题
5.考虑选取线性规划模型进行问题的探究
6.进行模型的评估:根据预测值以及真实值之间的关系(或者对比)来确定模型的预测精度
7.建议以及改进想法:
(1)增大数据量
(2)模型参数调优
(3)更换模型以及模型之间的组合
(4)进行特征的高级筛选处理
解决matplotlib中文显示问题
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
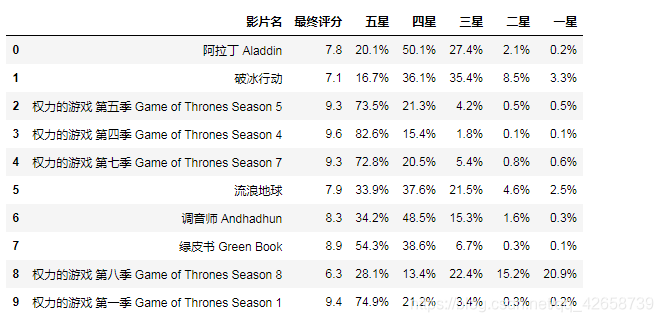
常规操作,先查看一下前十条数据
df = pd.read_csv('data.csv')
print(len(df))
df.head(10)
检测缺失值 false无
df.isnull().any()

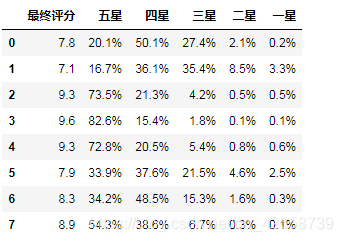
选取数据列以便 提供数据进行训练
datas = df.iloc[:,1:]
datas.head(8)
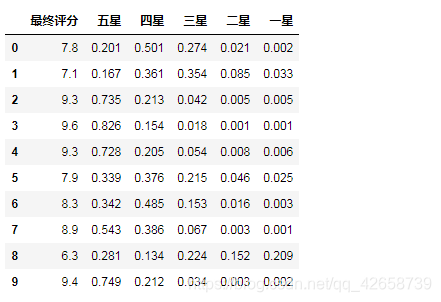
把数据处理一下:
for columns in datas.iloc[:,1:].columns:datas[columns] = datas[columns].str.strip("%").astype(float)/100
datas['最终评分'] = datas['最终评分'].astype(float)
datas.head(10)
转换成数组,方便操作以及个人习惯
datasArray2 = datas.values
构建模型:
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(datasArray2[:,1:],datasArray2[:,:1],test_size=0.25, random_state=0)# 对训练集进行训练
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)# 对测试集进行预测
y_predict2= lr.predict(X_test)
rmse = np.sqrt(metrics.mean_squared_error(y_test, y_predict2)) #均方根误差
print('RMSE:',rmse)

所以此模型准确率:98.2% 【1-rmse】
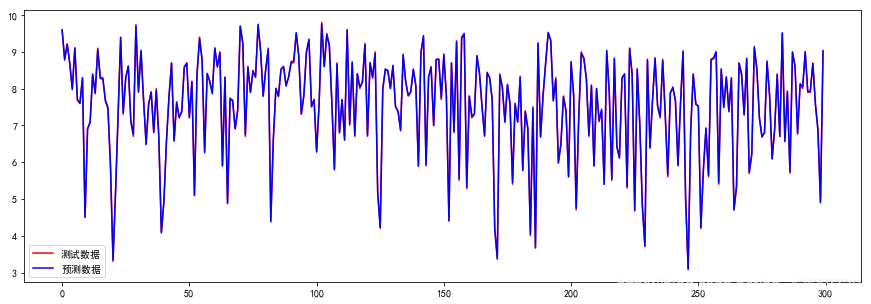
观察图形:
plt.figure(figsize=(15,5))
plt.plot(range(len(y_test)), y_test, 'r', label='测试数据')
plt.plot(range(len(y_test)), y_predict2, 'b', label='预测数据')
plt.legend()
查看回归系数【其实相当于权重系数】
查看常数值

也就是说,这个模型的表达式:
Y = 6.20437848 * x1+4.20811423*x2+2.20227207*x3+0.23005196*x4-1.80063617*x5+3.79333172
简单检验一下模型:
checkLabel = 6.7
checkArray = np.array([[0.091,0.330,0.442,0.110,0.028]])
y_predict_check= lr.predict(checkArray)
y_predict_check #查看y_predict_check的值
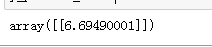
大致接近 标签值6.7,还行。
其实用线性模型的目的是因为其简单和数据类型的局限,我的猜测是:那个评分模型肯定不是那么简单的,可能还会有一些用户评论的情感分析和其他的东西在里面。
欢迎加入QQ群一起学习和交流,只为学习和交流:275259334
或者直接扫码加入: