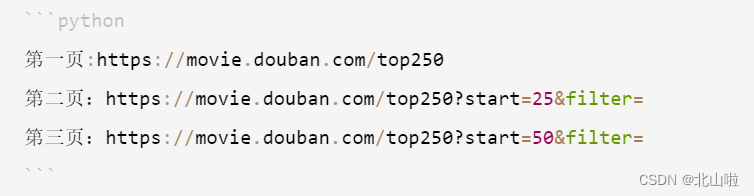
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 """ 4 一个简单的Python爬虫, 用于抓取豆瓣电影Top前100的电影的名称 5 Anthor: Andrew Liu 6 Version: 0.0.1 7 Date: 2014-12-04 8 Language: Python2.7.8 9 Editor: Sublime Text2 10 Operate: 具体操作请看README.md介绍 11 """ 12 import string 13 import re 14 import urllib2 15 16 class DouBanSpider(object) : 17 """类的简要说明 18 本类主要用于抓取豆瓣前100的电影名称 19 20 Attributes: 21 page: 用于表示当前所处的抓取页面 22 cur_url: 用于表示当前争取抓取页面的url 23 datas: 存储处理好的抓取到的电影名称 24 _top_num: 用于记录当前的top号码 25 """ 26 27 def __init__(self) : 28 self.page = 1 29 self.cur_url = "http://movie.douban.com/top250?start={page}&filter=&type=" 30 self.datas = [] 31 self._top_num = 1 32 print "豆瓣电影爬虫准备就绪, 准备爬取数据..." 33 34 def get_page(self, cur_page) : 35 """ 36 根据当前页码爬取网页HTML 37 Args: 38 cur_page: 表示当前所抓取的网站页码 39 Returns: 40 返回抓取到整个页面的HTML(unicode编码) 41 Raises: 42 URLError:url引发的异常 43 """ 44 url = self.cur_url 45 try : 46 my_page = urllib2.urlopen(url.format(page = (cur_page - 1) * 25)).read().decode("utf-8") 47 except urllib2.URLError, e : 48 if hasattr(e, "code"): 49 print "The server couldn't fulfill the request." 50 print "Error code: %s" % e.code 51 elif hasattr(e, "reason"): 52 print "We failed to reach a server. Please check your url and read the Reason" 53 print "Reason: %s" % e.reason 54 return my_page 55 56 def find_title(self, my_page) : 57 """ 58 通过返回的整个网页HTML, 正则匹配前100的电影名称 59 60 Args: 61 my_page: 传入页面的HTML文本用于正则匹配 62 """ 63 temp_data = [] 64 movie_items = re.findall(r'<span.*?class="title">(.*?)</span>', my_page, re.S) 65 for index, item in enumerate(movie_items) : 66 if item.find(" ") == -1 : 67 temp_data.append("Top" + str(self._top_num) + " " + item) 68 self._top_num += 1 69 self.datas.extend(temp_data) 70 71 def start_spider(self) : 72 """ 73 爬虫入口, 并控制爬虫抓取页面的范围 74 """ 75 while self.page <= 4 : 76 my_page = self.get_page(self.page) 77 self.find_title(my_page) 78 self.page += 1 79 80 def main() : 81 print """ 82 ############################### 83 一个简单的豆瓣电影前100爬虫 84 Author: Andrew_liu 85 Version: 0.0.1 86 Date: 2014-12-04 87 ############################### 88 """ 89 my_spider = DouBanSpider() 90 my_spider.start_spider() 91 for item in my_spider.datas : 92 print item 93 print "豆瓣爬虫爬取结束..." 94 95 if __name__ == '__main__': 96 main()
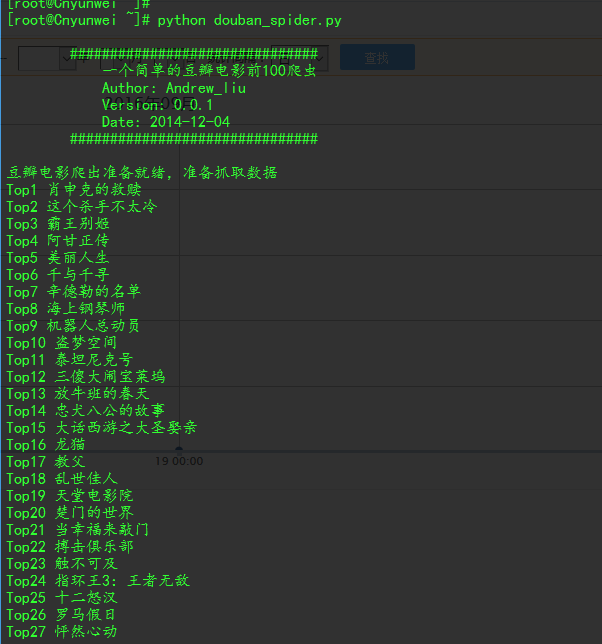
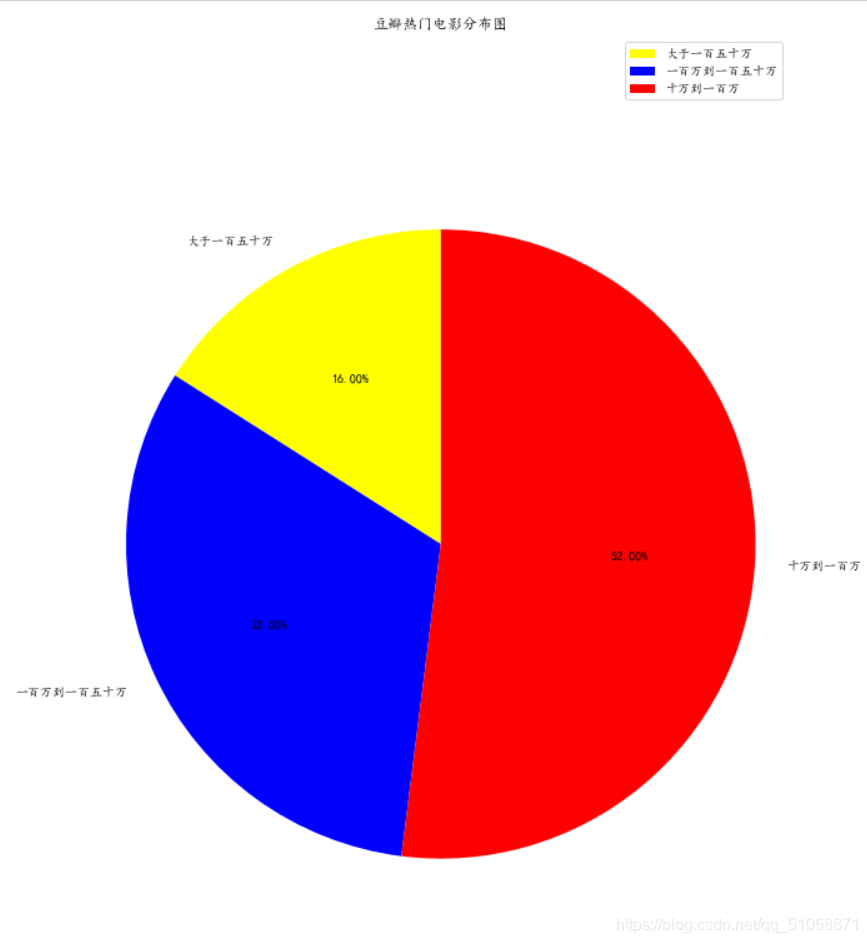
运行的结果: