
- ICLR 2022
- Shaked Brody(Technion), Eran Yahav(Technion)Uri Alon(Language Technologies InstituteCarnegie Mellon University)
- 论文地址
本文介绍的论文《HOW ATTENTIVE ARE GRAPH ATTENTION NETWORKS?》。
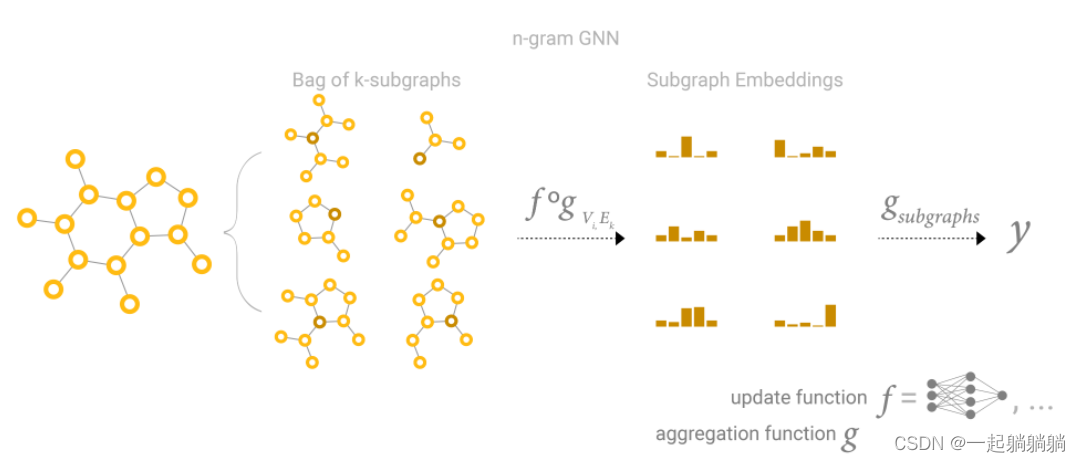
作者改进了GAT网络在图数据上的注意力的局限性,提出了GATv2模型将原始的静态注意力调整成动态注意力机制,并在许多开源数据验证了改进后模型的有效性。
| 🍁 一、背景 🍁 |
图注意力网络GATs是目前较为流行的GNN架构,在GAT中每个节点可以看成一个查询向量Q,该节点的邻居可以看成键向量K,然后基于Q和K计算对应的注意力分数,也可以说成是权重系数,然后利用该权重对该节点的邻居进行加权求和聚合操作,作为该节点新的表示向量。
但是这篇文章作者发现GAT计算的注意力表示能力非常有限,注意力得分排名不受查询节点的影响,作者将这种注意力定义为静态注意力。
静态注意力:
- 对于一组key向量,使用不同的查询向量query计算注意力分数时,得到的注意力分数大小相对不变,也就是任何节点q进行查询时,都对某个节点的注意力分数最大。
- F是一个注意力系数计算函数族,对于任意 f ∈ F f\in F f∈F,任意 q i ∈ Q q_i\in Q qi∈Q,存在 k j ∈ K k_j\in K kj∈K,使得 f ( q i , k j ) ≥ f ( q i , k e l s e ) f(q_i,k_j)\geq f(q_i,k_{else}) f(qi,kj)≥f(qi,kelse)
动态注意力:
- 那么动态注意力就是与静态相反,使用不同的q查询时,得到的注意力分数会相对变化。
- F是一个注意力系数计算函数族,对于任意 q i ∈ Q q_i\in Q qi∈Q,任意 k a n y ∈ K k_any\in K kany∈K,存在 f ∈ F f \in F f∈F,使得 f ( q i , k a n y ) ≥ f ( q i , k e l s e ) f(q_i, k_{any}) \geq f(q_i,k_{else}) f(qi,kany)≥f(qi,kelse)

由上面图可以看出,第一幅图就是静态注意力,第二幅图是动态注意力。
第一幅图中每个查询节点q对【k0,k1…k9】计算注意力分数时,都是k8的注意力分数最大,也就是无论q是什么,k8的贡献都是相对最大的,为了解决这个问题,作者提出了GATv2来使用动态注意力。
| 🍁 二、模型方法 🍁 |
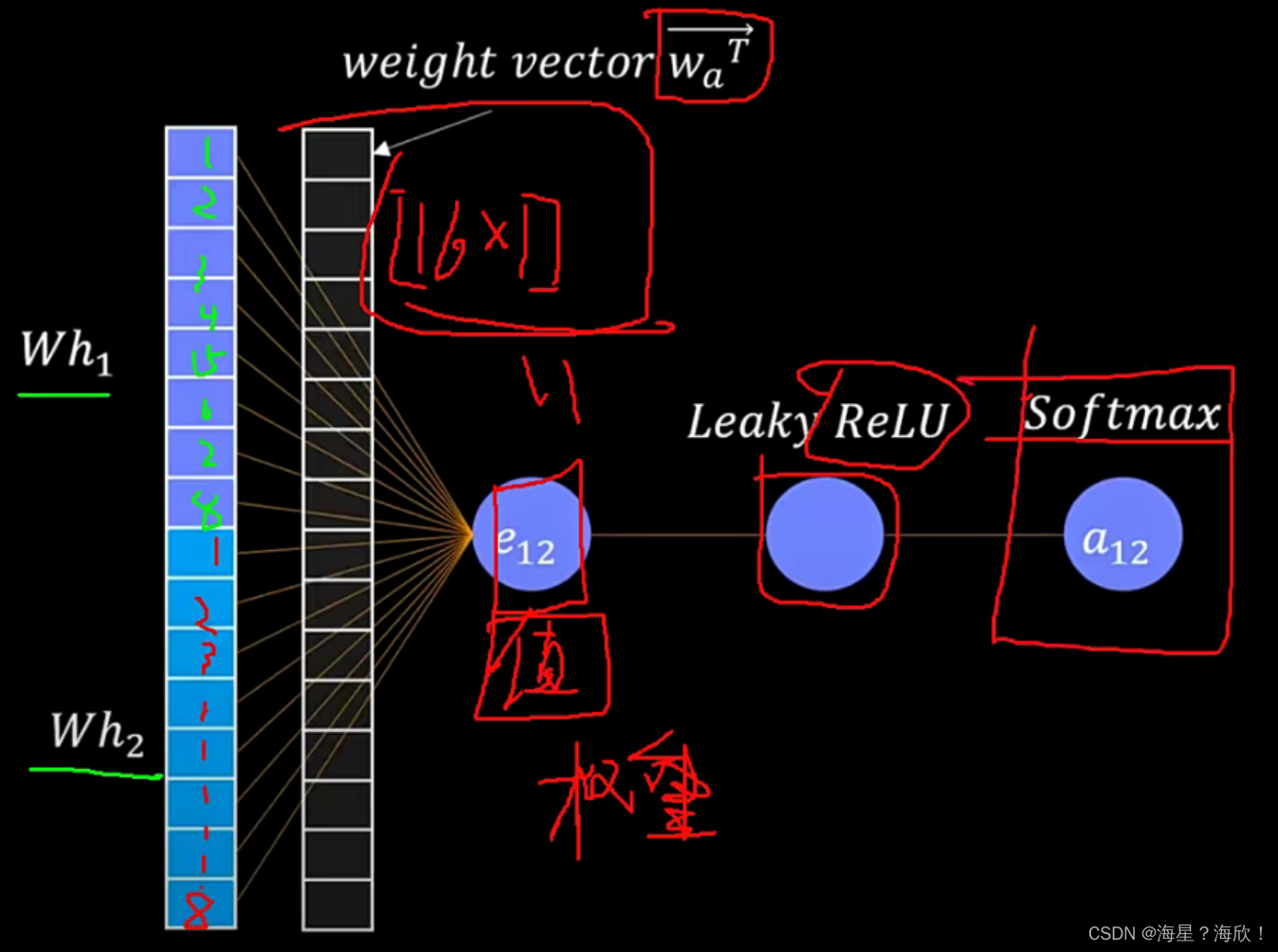
作者的改进措施很简单,就是修改了GAT中的计算顺序。
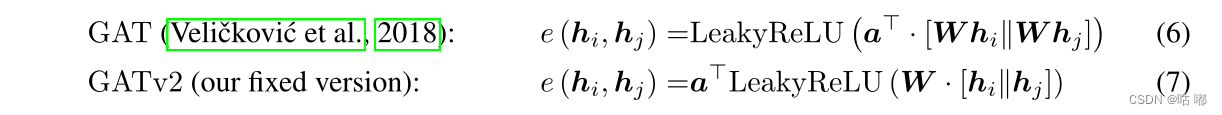
在GAT中,是分别将节点特征使用 W W W 进行映射到新的空间,然后将新的向量进行拼接,然后使用 α \alpha α 进行内积操作,最后使用 L e a k y R e L U LeakyReLU LeakyReLU 激活函数进行激活,随后使用 s o f t m a x softmax softmax 操作进行归一化。
在GATv2中,作者是先将节点特征向量进行拼接,然后使用 W W W 进行映射,然后使用激活函数进行激活,最后使用 α \alpha α 做内积操作计算得分。
GATv2网络操作:

GAT网络操作

| 🍁 三、实验结果 🍁 |
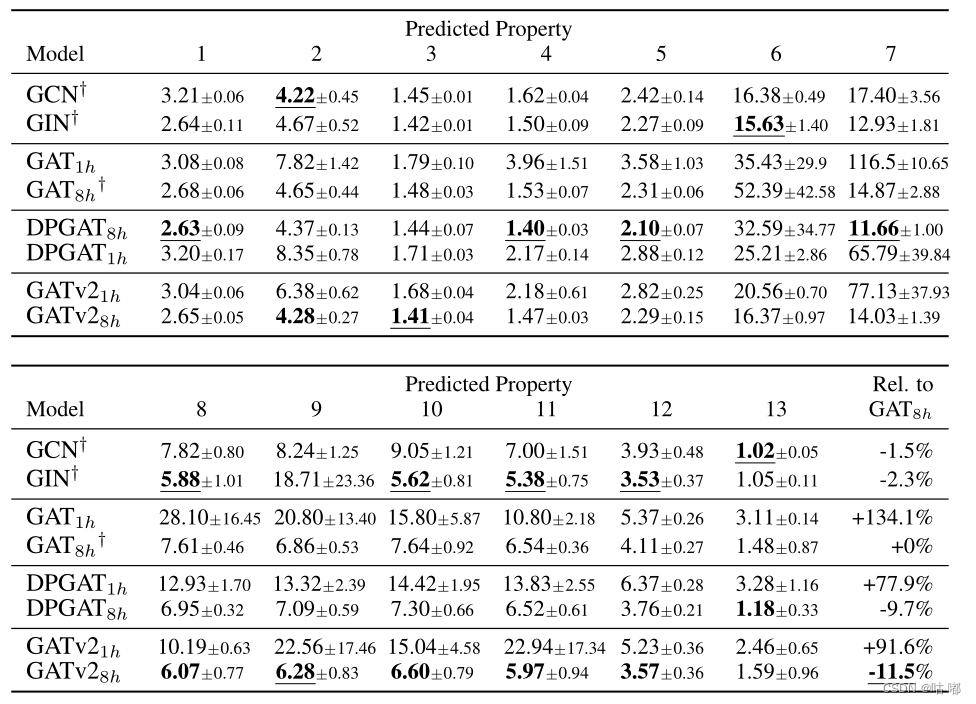
作者使用一个简单的综合问题证明了GA T的弱点,即GAT甚至无法拟合简易数据,但很容易通过GATv2解决。其次,发现GATv2对边缘噪声更为鲁棒,因为它的动态注意力机制允许它衰减有噪声边缘,而GAT的性能随着噪声的增加而严重降低。最后,在12个基准测试中比较了GAT和GATv2。
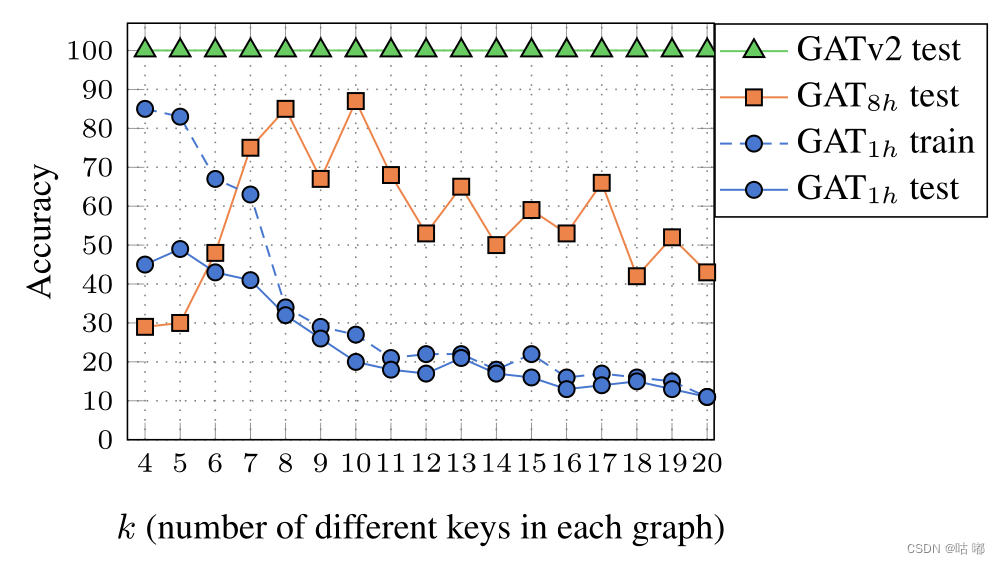
引入多头注意力的作用是稳定学习过程,然而上图显示,增加头部的数量严格地提高了训练的准确性,从而提高了表现力。因此,遗传算法依赖于具有多个注意力头部。相比之下,即使是单个GATv2头也比多头GAT具有更好的通用性。
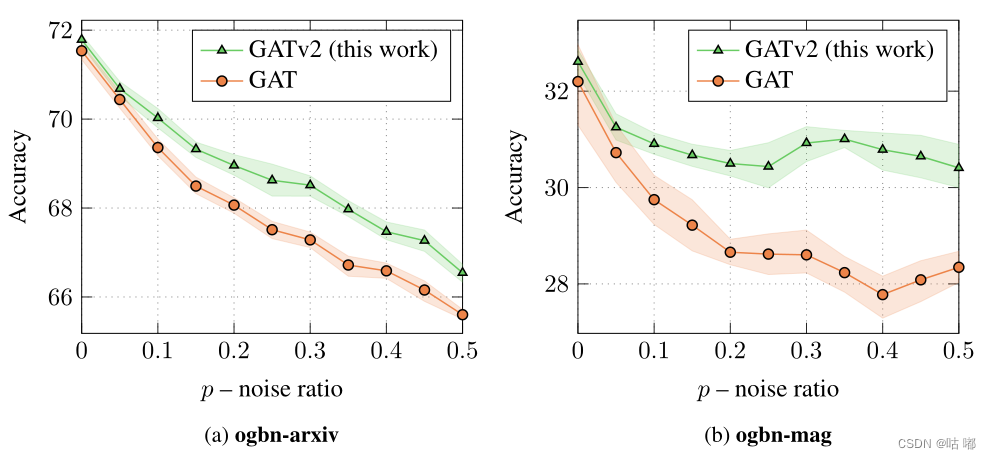
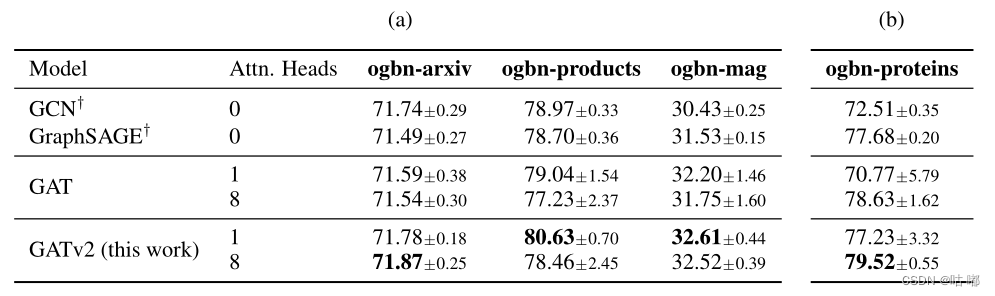
作者又进一步比较了OGB的四个节点预测数据集上的GATv2、GAT和其他GNN。
| 🍁 四、总结 🍁 |
在本文中,作者发现广泛的图注意力网络不计算动态注意力。相反,GAT的标准定义和实现中的注意力机制只是静态的:对于任何查询,其邻居得分相对于每个节点得分都是单调的。因此,GAT甚至不能表达简单的对齐问题。
为了解决这一局限性,该作者引入了一个简单的修复方法,并提出了GATv2:通过修改GAT中的操作顺序,GATv2实现了一个通用的近似注意力函数,因此比GAT更强大。



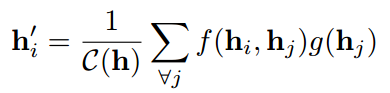



![[四格漫画] 第523话 电脑的买法](https://img-blog.csdn.net/20161004110842142?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
