前言:
这里主要针对图像数据进行预处理.定义了一个 class Pokemon(Dataset) 类,实现
图像数据集加载,划分的基本方法.
目录:
- 整体框架
- __init__
- load_images
- save_csv
- divide_data
- __len__
- denormalize
- __getitem__
- main
- ImageFolder
一 整体框架
我们需要创建一个自定义的数据集类,该类必须继承自Dataset类,
重点实现以下三个方法:
__init__
__len__()
__getitem__()
二 __init__
实现了图像数据集的加载
根据mode 进行划分
def __init__(self, root, resize, mode,fileName):#初始化函数super(Pokemon, self).__init__()self.root = rootself.resize = resizeself.name2label ={}#遍历目录path = os.path.join(root)#用子目录文件夹名字作为分类keyfor name in sorted(os.listdir(path)):subDir = os.path.join(root, name)if not os.path.isdir(subDir):continueelse:self.name2label[name] = len(self.name2label.keys())csv_path = os.path.join(self.root, fileName)print("\n csv_path: ",csv_path)if not os.path.exists(csv_path):images = self.load_images()self.save_csv(fileName, images)self.images, self.labels = self.load_csv(fileName)self.divide_data(mode)三 load_images
加载指定目录下面的图片,
把图片路径保存到列表里面
def load_images(self):images =[]for name in self.name2label.keys():#pokeon\\newtwoo\\00001.png#返回所有匹配的文件路径列表。它只有一个参数pathname,定义了文件路径匹配规则,这里可以是绝对路径,也可以是相对路径。下面是使用glob.glob的例子:pngPath = os.path.join(self.root, name,'*.png')jpgPath = os.path.join(self.root, name,'*.jpg')jpegPath = os.path.join(self.root, name,'*.jpeg')png = glob.glob(pngPath)jpg =glob.glob(jpgPath)jpeg = glob.glob(jpegPath)images +=jpgimages +=jpegimages +=pngprint("\n images ",len(images))random.shuffle(images)return images四 save_csv
图片路径,标签保存到csv 文件里面
#image, labeldef save_csv(self, fileName, images):path = os.path.join(self.root, fileName)csvfile = open(path,mode='w',newline='')writer = csv.writer(csvfile)for img in images:name = img.split(os.sep)[-2]label = self.name2label[name]writer.writerow([img, label])csvfile.close()四 load_csv
加载 csv 文件
def load_csv(self, fileName):path = os.path.join(self.root, fileName)csvfile = open(path,mode='r',newline='')reader = csv.reader(csvfile)images =[]labels =[]for row in reader:img, label = rowlabel = int(label)images.append(img)labels.append(label)m = len(images)n = len(labels)print("\n number images: %d number labels: %d"%(m,n))return images,labels五 divide_data
数据集划分
训练集: 60%
验证集: 20%
测试机:20%
def divide_data(self,mode):N = len(self.images)if 'train' == mode: #0->60%start = 0end = int(0.6*N)elif 'val' == mode:#60%->80%start = int(0.6*N)end = int(0.8*N)else:#80%->100%start = int(0.8*N)end = Nself.images = self.images[start:end]self.labels = self.labels[start:end]m = len(self.images )print("\n number divide images: %d "%(m))六 __len__
返回数据集大小
def __len__(self):#总的数据N = len(self.images)return N七 denormalize
图像数据 标准后,当需要显示原图片的时候,需要反标准化
def denormalize(self,x_hat):#x_hat =(x-mean)/std#x = x_hat*std+mean#x: [c,h,w]#mean: [3]=>[3,1,1]mean=[0.485, 0.456, 0.406]std=[0.229, 0.224, 0.225]mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)std = torch.tensor(std).unsqueeze(1).unsqueeze(1)x =x_hat*std+meanreturn x八 __getitem__
根据指定的索引获取对应的图片,以及标签值
def __getitem__(self, index):#返回当前index 对应的图片数据#self.images, self.labels#idx ~[0,N]img_path = self.images[index] #图片路径label = self.labels[index] #图片标签#print("\n img_path",img_path)tf = transforms.Compose([ lambda x:Image.open(x).convert('RGB'),transforms.Resize((int(self.resize*1.25) , int(self.resize*1.25))), transforms.RandomRotation(15), transforms.ToTensor(),transforms.CenterCrop(self.resize),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])img = tf(img_path)label = torch.tensor(label)#print("\n index ",index, "\t img ",img.shape,"\t label ",label)return img, label九 main
1 先定义一个class Pokemon(Dataset): 类,并实现上面的方法
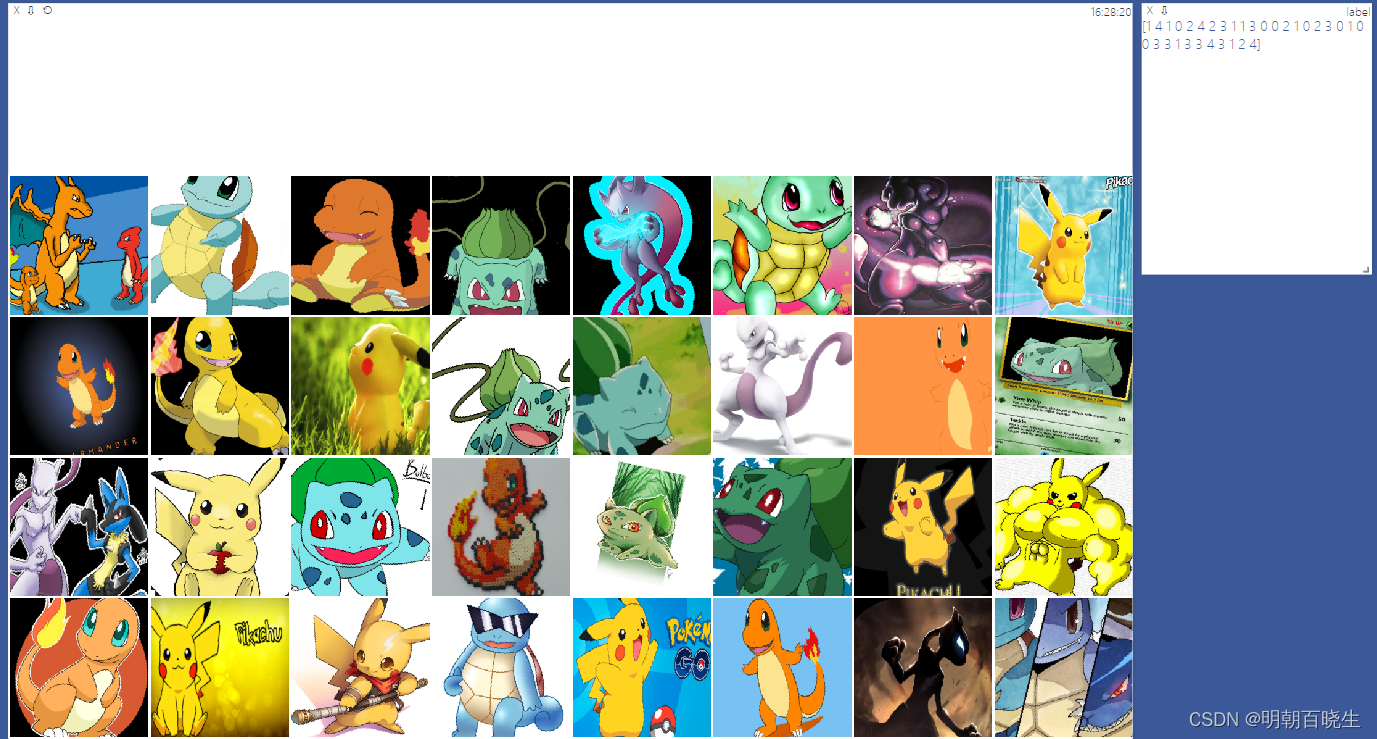
2 数据集的迭代加载,以及通过visdom 工具加载显示
def main():root ='pokemon'resize =224mode = 'test' #数据集分为三种 tain,val,testcsvfile ='data.csv'db = Pokemon(root, resize, mode,csvfile)viz = visdom.Visdom()# datetime转字符串time.time() #显示当前的时间戳curtime = time.strftime('%H:%M:%S') #结构化输出当前的时间BATCH_SIZE = 32loader = DataLoader(dataset = db, batch_size = BATCH_SIZE,shuffle = True)for step, (batchX, batchY) in enumerate(loader):print( '| Step: ', step, '| batch x: ',batchX.shape, '| batch y: ', batchY.shape)viz.images(db.denormalize(batchX),nrow=8, win='batchX',opts=dict(title=curtime))viz.text(str(batchY.numpy()),win='batchY',opts=dict(title='label'))time.sleep(10)if __name__ == "__main__" :main()十 ImageFolder
自己的图像数据集如果有规律的话,可以直接用PyTorch API 函数实现 Pokemon
类的功能

from torchvision.datasets import ImageFolder
from torchvision import transformsimgMean =[0.485, 0.456, 0.406]
imgStd = [0.229, 0.224, 0.225]
normalize=transforms.Normalize(mean=imgMean,std=imgStd)
transform=transforms.Compose([transforms.RandomCrop(180),transforms.RandomHorizontalFlip(),transforms.ToTensor(), #将图片转换为Tensor,归一化至[0,1]normalize
])dataset=ImageFolder('./data/train',transform=transform)
参考:
torchvision.datasets.ImageFolder使用详解_☞源仔的博客-CSDN博客
课时102 自定义数据集实战-5_哔哩哔哩_bilibili

![[足式机器人]Part3机构运动微分几何学分析与综合Ch03-1 空间约束曲线与约束曲面微分几何学——【读书笔记】](https://img-blog.csdnimg.cn/303488597c624fe0b2cb55cbc3532adc.png)